

音频特征提取——常用音频特征
作者:桂。
时间:2017-05-05 21:45:07
链接:http://www.cnblogs.com/xingshansi/p/6815217.html

前言
主要总结一下常用的音频特征,并给出具体的理论分析及代码。
一、过零率
过零率的表达式为:

其中N为一帧的长度,n为对应的帧数,按帧处理。
理论分析:过零率体现的是信号过零点的次数,体现的是频率特性。因为需要过零点,所以信号处理之前需要中心化处理。
code(zcr1即为过零率):
1 2 3 4 5 6 7 8 | for i=1:fn z=X(:,i); % 取得一帧数据 for j=1: (wlen- 1) ; % 在一帧内寻找过零点 if z(j)* z(j+1)< 0 % 判断是否为过零点 zcr1(i)=zcr1(i)+1; % 是过零点,记录1次 end endend |
二、短时能量
短时能量的表达式为:
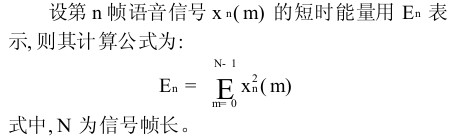
理论分析:短时能量体现的是信号在不同时刻的强弱程度。
code:
1 2 3 4 5 | for i=1 : fn u=X(:,i); % 取出一帧 u2=u.*u; % 求出能量 En(i)=sum(u2); % 对一帧累加求和end |
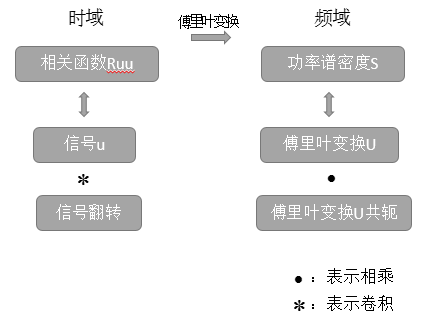
三、短时自相关函数
短时自相关函数定义式为:

理论分析:学过信号处理的都应该知道,信号A与信号B翻转的卷积,就是二者的相关函数。其中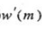 是因为分帧的时候,加了窗函数截断,w代表窗函数。
是因为分帧的时候,加了窗函数截断,w代表窗函数。
code:假设一帧截断的信号
1 | r = xcorr(signal); |
这与直接利用卷积的方式等价:
给出卷积的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 | function output_signal=my_direct_convolution(input_signal,impulse_response)% Input:% input_signal: the input signal% impulse_response: the impulse response% Output:% output_signal:the convolution resultN=length(input_signal);%define length of signalK=length(impulse_response);%define length of impulse responseoutput_signal=zeros(N+K-1,1);%initializing the output vectorxp=[zeros(K-1,1);input_signal;zeros(K-1,1)];for i=1:N+K-1 output_signal(i)=xp(i+K-1:-1:i)'*impulse_response;end |
卷积也可以借助FFT快速实现。
调用卷积的函数:
1 | r1 = my_direct_convolution(signal,signal(end:-1:1)); |
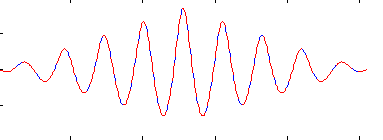
图中可以看出r与r1完全等价:
四、短时*均幅度差
假设x是加窗截断后的信号,短时*均幅度差定义:
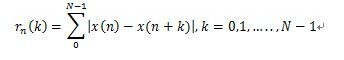
理论分析:音频具有周期特性,*稳噪声情况下利用短时*均幅度差可以更好地观察周期特性。
code:
取一帧信号,计算短时*均幅度差:
1 2 3 4 | u = X(:,i) %取一帧信号for k = 1:wlen amdvec(k) = sum(abs(u(k:end)-u(1:end-k+1)));%求每个样点的幅度差再累加end |
前面四个都是信号的时域分析,音频信号更多是在时频域分析(可借助tftb-0.2工具包分析)。
常用的有STFT(短时傅里叶变换)、小波变换、ST、W-V变换,以线性调频信号为例:
左图最下面为合成信号,右图为四种变换对合成信号进行的时频分析。
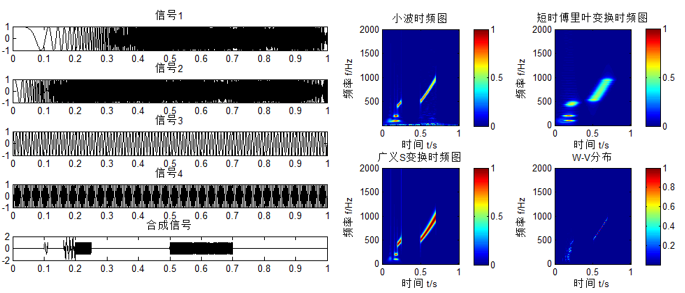
这里只分析利用短时傅里叶变换(Short time fourier transform, STFT)的情形。
又因为实数的傅里叶变换共轭对称,有时也仅仅分析频域的一半信息即可。
为什么要进行STFT呢,原因按我的理解可能有两点:
- 传统FFT只能看到信号频率的特性,时域信号只能观察时域特性,都是一维的情况,如果二维联合观察?这个时候STFT就可以实现;
- 语音是非*稳信号,比如求相关矩阵,理论上是E{.}求取均值的形式,通常无法得出概率密度,往往有数据*似:
这个式子能够*似相关矩阵,有两个前提条件:a)信号*稳,这样才能保证统计特性一致;b)遍历性,这个时候才能保证统计没有以偏概全。
但语音信号是非*稳信号,直接求取相关矩阵理论上没有意义,其他统计信息也有类似的特性。但语音变化缓慢,可以认为是短时*稳,即在短的时间内(如20~30ms)是*稳的,这个时候*稳+遍历性的假设,就可以让我们借助观测数据估计统计信息。这个短时*稳的划分就是信号分帧。进一步:分帧信号分别FFT,就是STFT。
信号分帧的code:
1 2 3 4 5 | Nframe = floor( (length(x) - wlen) / nstep) + 1; for k = 1:Nframe idx = (1:wlen) + (k-1) * nstep; x_frame = x(idx); end |
加窗截断分帧的示意图:
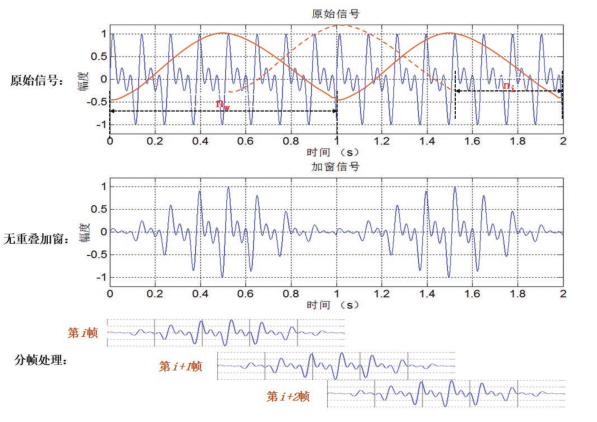
为什么要有帧移量?即帧与帧之间有部分重叠?从上面中间图可以看出,加窗阶段后相邻两帧在端点处变化较大,对于变化较大的情况一般思路就是*滑,比如进行插值处理,其实帧移的操作就是插值呀。
五、语谱图(基于FFT)
有时FFT也换成DCT实现,FFT延展与DCT是等价的,就不一一列出了。只分析FFT情况。
基于FFT语谱图的定义:
就是分帧,对每一帧信号FFT
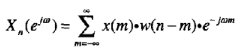
然后求绝对值/*方。
理论分析:
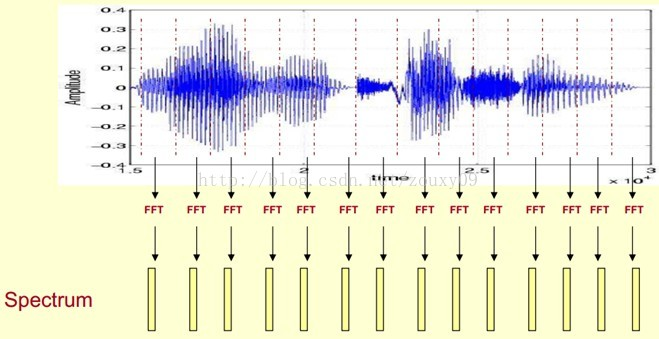
给出示意图,语音分帧→每一帧分别FFT→求取FFT之后的幅度/能量,这些数值都是正值,类似图像的像素点,显示出来就是语谱图。
语谱图code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | function d=FrequencyCal(x,nw,ni)n=nw; %帧长h=ni; %帧移量s0=length(x);win=hamming(n)'; %加窗,hamming为例c=1;ncols=1+fix((s0-n)/h); %分帧,并计算帧数d=zeros((1+n/2),ncols);for b=0:h:(s0-n) u=win.*x((b+1):(b+n)); t=fft(u); d(:,c)=t(1:(1+n/2))'; c=c+1;end |
读取语音调用语谱图code:
1 2 3 4 5 6 7 8 9 10 11 | [signal,fsc] = wavread('tone4.wav');nw=512;ni=nw/4;d=FrequencyCal(signal',nw,ni);tt=[0:ni:(length(signal)-nw)]/fsc;ff=[0:(nw/2)]*fsc/nw*2;% imagesc(tt,ff,20*log10(abs(d)));imagesc(tt,ff,abs(d).^2);xlabel('Time(s)');ylabel('Frequency(Hz)')title('语谱图')axis xy |
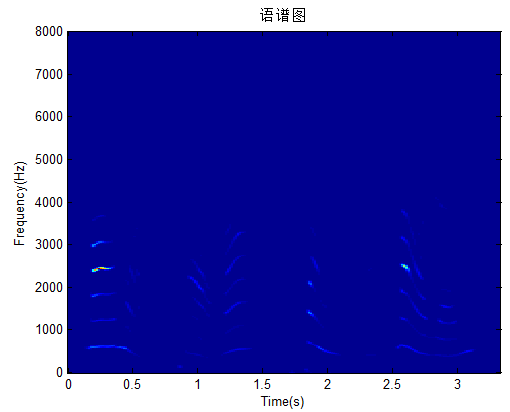
常用对数谱,修改上面的一句code即可:
1 2 | imagesc(tt,ff,20*log10(abs(d)));% imagesc(tt,ff,abs(d).^2); |
效果图:
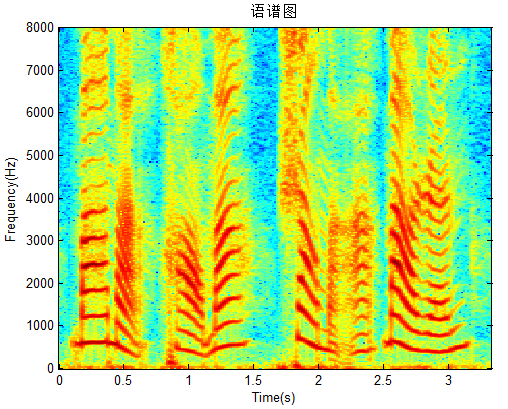
有时对数中添加常数项;
1 | imagesc(tt,ff,20*log10(C+abs(d))); |
效果图:
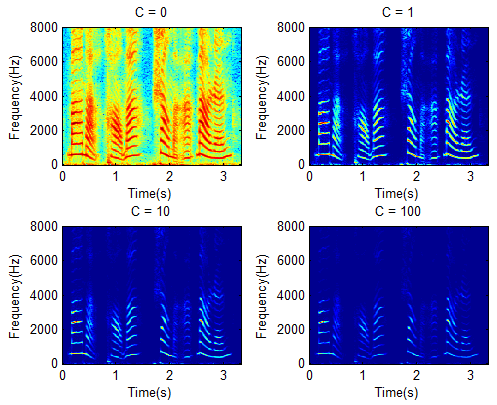
六、短时功率谱密度
先来看看功率谱定义:
![]()
可见对于有限的信号,功率谱之所以可以估计,是基于两点假设:1)信号*稳; 2)随机信号具有遍历性
A-功率谱密度
1)周期图法
已知N个采样点的信号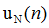 ,对其进行傅里叶变换:
,对其进行傅里叶变换:

进一步得到功率谱密度:
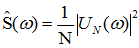
按照上文分析相关函数的思路,给出一个分析:
就是信号u的相关函数就是u卷积上u的翻转,而相关函数与功率谱密度是互为傅里叶变换。u对应傅里叶变换U,u的翻转对应U的共轭,时域的卷积对应频域的相乘,就得到了功率谱估计的表达式,同样代码实现依然可以借助上文分析相关函数的特性加以分析。
对应code,其中my_direct_convolution仍然调用上面的函数:
1 2 3 4 5 6 7 8 9 10 11 12 | fs = 1000;%采样率f0 = 30;%信号频率t = 0:1/fs:1;x = sin(2*pi*f0*t);lenx = length(x)subplot 121plot(t,x,'k');title('时域信号')subplot 122Prr = abs(fft(my_direct_convolution(x',x(end:-1:1)')))/lenx;plot((0:fs)/2,Prr(1:length(Pxx)),'r--');xlabel('Frequency(Hz)') |
效果图中可以看出信号30Hz可以明显从功率谱图观察:
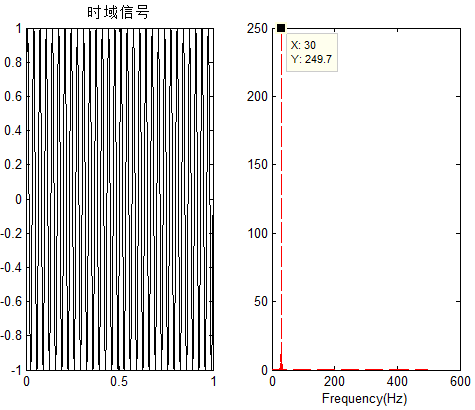
可以看出:功率谱密度与相关函数对应,而相关函数是统计信息,按前文提到的,它是建立在信号*稳的假设之上。如果信号不够*稳呢?周期图法的思路显然是不适用的,Welch就是对这一问题的改进。
2)*均周期图法(Welch)
与周期图谱求功率谱密度不同,Welch不再从整个时间段考虑,而是做了三点改进:
- 截断,将这个信号分成多个片段
- 加窗:因为截断,截断就要泄露,通常都选择加窗处理
- 重叠:截断之后,为了防止相邻两段差异过大,通常插值*滑处理,也就是取重叠
给出Welch定义,每一段的功率:
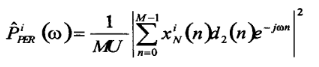
其中![]() ,d2(n)是窗函数,M是每一段的长度,假设总长度为L,则Welch*均功率谱密度为:
,d2(n)是窗函数,M是每一段的长度,假设总长度为L,则Welch*均功率谱密度为:
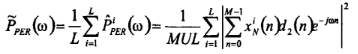
简单来理解就是:分段的每一段用周期图法得到功率谱密度,然后加权*均,不再细说了。
B-短时功率谱密度
按前面分析,周期图法针对的是*稳信号,而Welch虽然考虑了非*稳的特性,但分段的数量通常较小,每一段的长度较大,对音频信号而言,这也是不够的。音频信号可以看作短时间的*似*稳(如一帧信号),对每一帧利用周期图法分析,这个就是短时功率谱密度的思路。通常为了防止一帧的信号不够*稳,每一帧也可以进一步利用Welch方法处理。
对应code,分帧、Welch都是上面的思路,直接调用了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | function [Pxx] = pwelch_2(x, nwind, noverlap, w_nwind, w_noverlap, nfft)% 计算短时功率谱密度函数% x是信号,nwind是每帧长度,noverlap是每帧重叠的样点数% w_nwind是每段的窗函数,或相应的段长,% w_noverlap是每段之间的重叠的样点数,nfft是FFT的长度x=x(:);inc=nwind-noverlap; % 计算帧移X=enframe(x,nwind,inc)'; % 分帧frameNum=size(X,2); % 计算帧数%用pwelch函数对每帧计算功率谱密度函数for k=1 : frameNum Pxx(:,k)=pwelch(X(:,k),w_nwind,w_noverlap,nfft);end |
七、谱熵
谱熵的定义,首先对每一帧信号的频谱绝对值归一化:
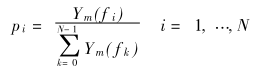
这样就得到了概率密度,进而求取熵:
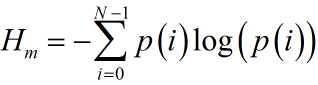
理论分析:熵体现的是不确定性,例如抛骰子一无所知,每一面的概率都是1/6,信息量最大,也就是熵最大。如果知道商家做了手脚,抛出3的概率大,这个时候我们已经有一定的信息量,抛骰子本身的信息量就少了,熵也就变小。对于信号,如果是白噪声,频谱类似均匀分布,熵就大一些;如果是语音信号,分布不均匀,熵就小一些,利用这个性质也可以得到一个粗糙的VAD(有话帧检测)。谱熵有许多的改进思路,滤波取特定频段、设定概率密度上限、子带*滑谱熵,自带*滑通常利用拉格朗日*滑因子,这是因为防止某一段子带没有信号,这个时候的概率密度就没有意义了,这个思路在利用统计信息估计概率密度时经常用到,比如朴素贝叶斯就用到这个思路。
谱熵code:
1 2 3 4 5 6 7 | for i=1:fn Sp = abs(fft(y(:,i))); % FFT变换取幅值 Sp = Sp(1:wlen/2+1); % 只取正频率部分 Ep=Sp.*Sp; % 求出能量 prob = Ep/(sum(Ep)); % 计算每条谱线的概率密度 H(i) = -sum(prob.*log(prob+eps)); % 计算谱熵end |
八、基频
基频:也就是基频周期。人在发音时,声带振动产生浊音(voiced),没有声带振动产生清音(Unvoiced)。浊音的发音过程是:来自肺部的气流冲击声门,造成声门的一张一合,形成一系列准周期的气流脉冲,经过声道(含口腔、鼻腔)的谐振及唇齿的辐射形成最终的语音信号。故浊音波形呈现一定的准周期性。所谓基音周期,就是对这种准周期而言的,它反映了声门相邻两次开闭之间的时间间隔或开闭的频率。常用的发声模型:
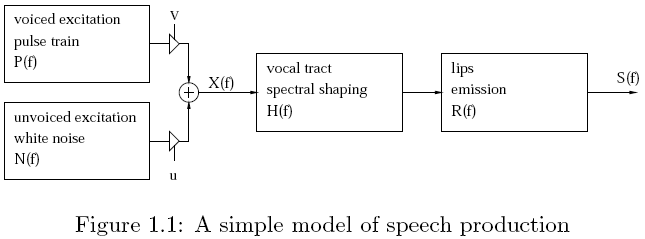
基音提取常用的方法有:倒谱法、短时自相关法、短时*均幅度差法、LPC法,这里借用上面的短时自相关法,说一说基频提取思路。
自相关函数:
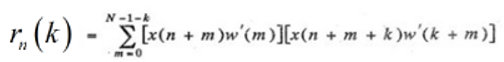
通常进行归一化处理,因为r(0)最大,
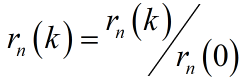
得到归一化相关函数时候,归一化的相关函数第一个峰值为k = 0,第二个峰值理论上应该对应基频的位置,因为自相关函数对称,通常取一半分析即可。
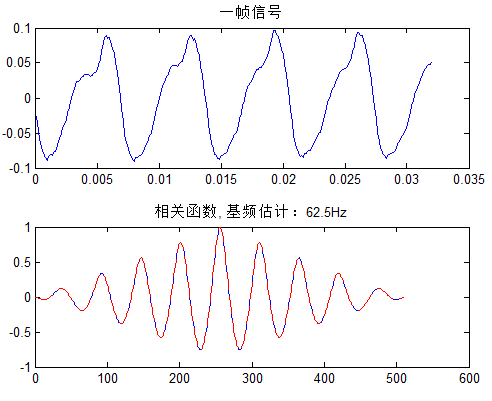
取一帧信号为例,整个说话段要配合有话帧检测(VAD技术,这里不提了)自相关法估计基频code:
1 2 3 4 5 6 7 8 9 10 11 12 13 | [x, fs] = wavread('1.wav');nw = 256;signal = x(16001:(16000+nw),1);%取一帧信号%相关函数计算r = my_direct_convolution(signal,signal(end:-1:1)); %利用卷积计算相关函数r = r/(signal'*signal);%相关函数归一化rhalf = r(nw:end); % 取延迟量为正值的部分%提取基音,假设介于50~600Hz之间lmin = round((50/fs)*nw);lmax = round((600/fs)*nw);[tmax,tloc] = max(rhalf(lmin:lmax)); % 在Pmin~Pmax范围内寻找最大值pos = lmin+tloc-1; % 给出对应最大值的延迟量pitch = pos/nw*fs %估计得基频 |
卷积还是调用上面的函数。波形的短时周期还是比较明显的,给出一帧信号:
九、共振峰
首先给出共振峰定义:当声门处准周期脉冲激励进入声道时会引起共振特性,产生一组共振频率,这一组共振频率称为共振峰频率或简称共振峰。
共振峰参数包括共振峰频率和频带的宽度,它是区别不同韵母的重要参数,由于共振峰包含在语音的频谱包络中,因此共振峰参数的提取关键是估计自然语音的频谱包络,并认为谱包括的极大值就是共振峰,通常认为共振峰数量不超过4个。发声模型:
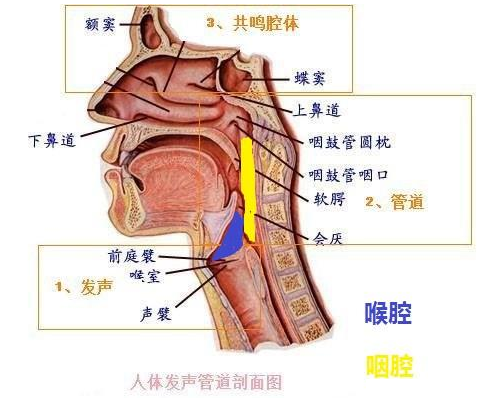
对这个模型抽象,通常有声管模型、声道模型两个思路,以声道模型为例:认为信号经过与声道的卷积,得到最终发出的声音。声道就是系统H。
共振峰的求解思路非常多,这里给出一个基于LPC内插的例子。
如果表达这个系统响应H呢?一个基本的思路就是利用全极点求取:
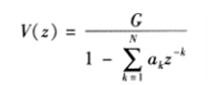
从按照时域里信号与声道卷积的思路,频域就是信号与声道相乘,所以声道就是包络:
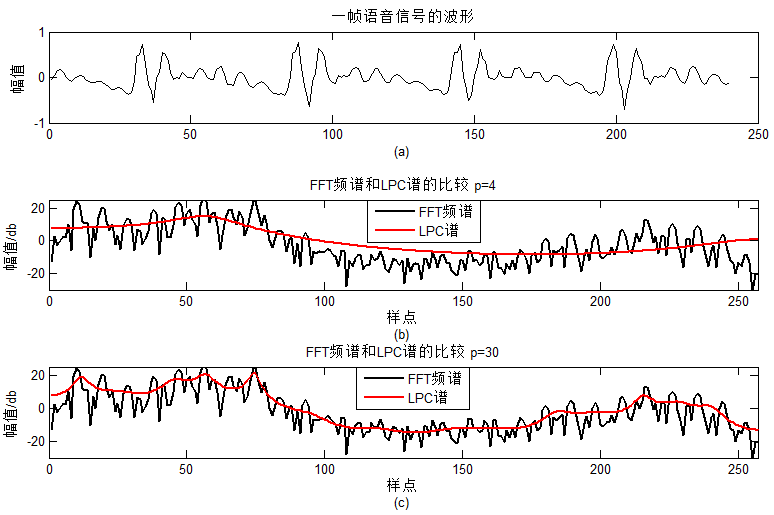
利用线性预测系数(LPC)并选择适当阶数,可以得到声道模型H。LPC之前有分析过,可以点击这里。
其实利用LPC得出的包络,找到四个峰值,就已经完成了共振峰的估计。为了更精确地利用LPC求取共振峰有,两种常用思路:抛物线内插法、求根法,这里以内插法为例。其实就是一个插值的思路,如图
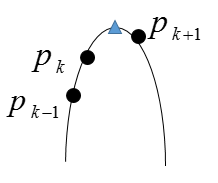
为了估计峰值,取p(k-1)、p(k)、p(k+1)哪一个点都是不合适的,插值构造抛物线,找出峰值就更精确了。
LPC内插法code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | [x,fs]=wavread(fle); % 读入一帧语音信号 u=filter([1 -.99],1,x); % 预加重wlen=length(u); % 帧长p=12; % LPC阶数a=lpc(u,p); % 求出LPC系数U=lpcar2pf(a,255); % 由LPC系数求出频谱曲线freq=(0:256)*fs/512; % 频率刻度df=fs/512; % 频率分辨率U_log=10*log10(U); % 功率谱分贝值[Loc,Val]=findpeaks(U); % 在U中寻找峰值ll=length(Loc); % 有几个峰值%抛物线内插修正for k=1 : ll m=Loc(k); % 设置m-1,m和m+1 m1=m-1; m2=m+1; p=Val(k); % 设置P(m-1),P(m)和P(m+1) p1=U(m1); p2=U(m2); aa=(p1+p2)/2-p; bb=(p2-p1)/2; cc=p; dm=-bb/2/aa; pp=-bb*bb/4/aa+cc; m_new=m+dm; bf=-sqrt(bb*bb-4*aa*(cc-pp/2))/aa; F(k)=(m_new-1)*df; Bw(k)=bf*df; end |
为了更好地估计声道,这里用了预加重,因为类似电磁波等信号,波信号传播过程中高频分量衰减更大,所以需要对高频进行一定程度的提升,这个操作叫做:预加重。
对应的效果图:
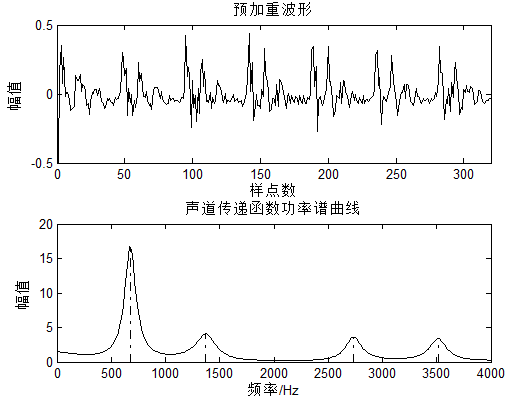
求解的共振峰频率(Hz):676.15 1372.53 2734.15 3513.69,基音周期与共振峰不是一回事啊!有时为了表征声道特性,也可以直接利用LPC系数作为特征,而不必求取共振峰。
梅尔倒谱系数(MFCC)打算单拎出来写了,涉及的概念有点多,其他特征用到再补充吧,上一篇文章也提到了很多音频特征的概念。
参考:
- 宋知用《MATLAB在语音信号分析与合成中的应用》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决