
一起来学习XPATH,来看看除了正则表达式我们还能怎么抓取数据
参考学习的网站链接http://www.w3school.com.cn/xpath/xpath_intro.asp
首先理清楚一些常识
以此为例
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
参照HTML的格式其实很多都只是换了一下名字而已还是很好上手的
节点(Node)
<bookstore> (文档节点) <author>J K. Rowling</author> (元素节点) lang="en" (属性节点)
基本值(或称原子值,Atomic value)
J K. Rowling "en"
项目(Item)
项目是基本值或者节点。
然后是节点关系,父、子、同胞、先辈、后代,可以和树的知识一起理解
在语法上面基本上和正则一样,多练多记,实在记不住就要多查了




接下来介绍一下轴,用于定义当前节点的节点集

轴的作用就像集合,一次性锁定一大片元素、属性,aoe的伤害啊哈哈哈
在位置路径表达上面,最前面有/就是绝对,没有就是相对

再来看看步,这个就有点像c语言里面的类和对象的赶脚了
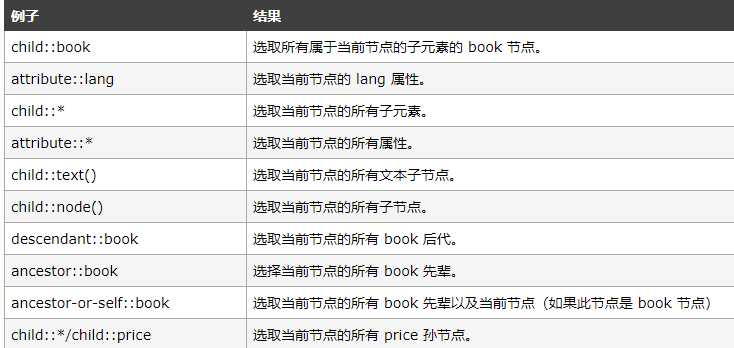
那么运算符都是通用的也就不介绍了,注意到是除法用div其他基本相同
基本上这里就足够日常的一些使用和查询了
关于它的函数部分一般爬虫也用不到,但为了方便大家也列一下
http://www.w3school.com.cn/xpath/xpath_functions.asp
最后就扔上实例的链接,按需查看,下期见嘻嘻
http://www.w3school.com.cn/xpath/xpath_examples.asp
风雨兼程,前程可待!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号