

【《TensorFlow深度学习》龙龙老师】拆书笔记
哔哩哔哩有带读https://www.bilibili.com/video/BV1AJ411i7US/?spm_id_from=333.788.videocard.2
第二章
最优化损失函数

![]() 量
量
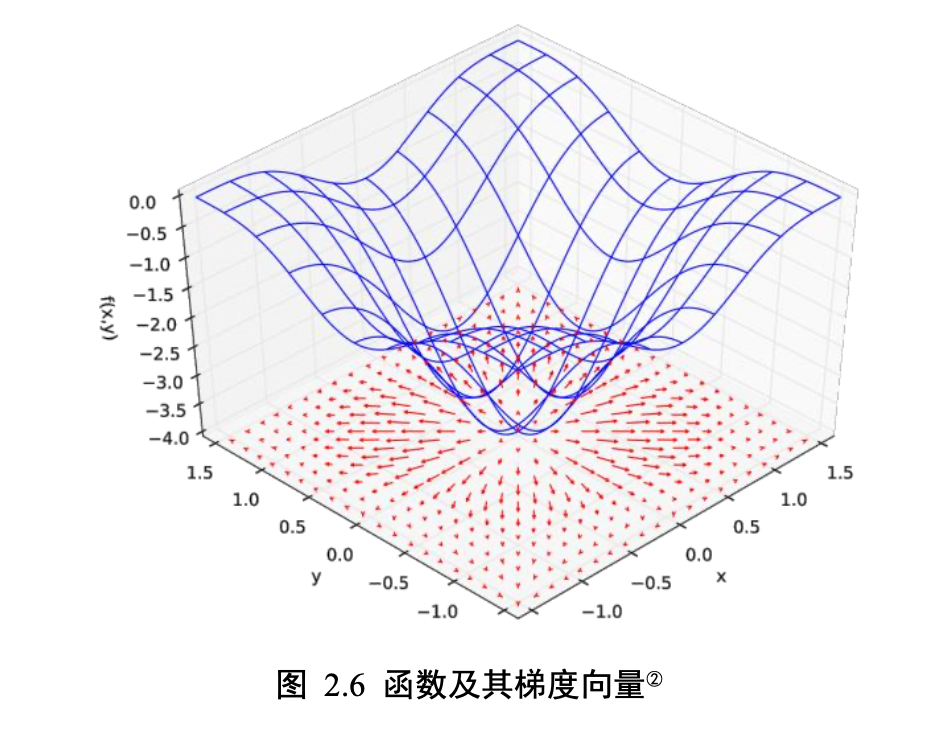

连续值预测问题是非常常见的,比如股价的走势预测、天气预报中温 度和湿度等的预测、年龄的预测、交通流量的预测等。对于预测值是连续的实数范围,或 者属于某一段连续的实数区间,我们把这种问题称为回归(Regression)问题。
第三章
分类
x = 2*tf.convert_to_tensor(x, dtype=tf.float32)/255.-1 # 转换为浮点张量,并缩放到 -1~1
【把[0,255]像素范围 归一化(Normalize)到[0,1. ]区间,再缩放到[−1,1]区间】
y = tf.convert_to_tensor(y, dtype=tf.int32) # 转换为整形张量
y = tf.one_hot(y, depth=10) # one-hot编码
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 构建数据集对象
train_dataset = train_dataset.batch(512) # 批量训练
对于分类问题的误差计算来说,更常见的是采用交叉熵(Cross Entropy)损失函数,较少采用 回归问题中介绍的均方差损失函数。

可以通过重复堆叠多次变换来增加其表达能力
# 创建一层网络,设置输出节点数为 256,激活函数类型为 ReLU
layers.Dense(256, activation='relu')

第4章 TensorFlow 基础
aa = tf.constant(1.2) # TF方式创建标量
x.numpy() # 将TF张量的数据导出为numpy数组格式
a = tf.constant('Hello, Deep Learning.') # 创建字符串
a = tf.constant(True) # 创建布尔类型标量 ⚠️TensorFlow 的布尔类型和 Python 语言的布尔类型并不等价,不能通 用
# 创建指定精度的张量 tf.constant(123456789, dtype=tf.int16)
tf.cast(a, tf.double) # 转换为高精度张量
由于梯度运算会消耗大量的 计算资源,而且会自动更新相关参数,对于不需要的优化的张量,如神经网络的输入𝑿, 不需要通过 tf.Variable 封装;相反,对于需要计算梯度并优化的张量,如神经网络层的𝑾 和𝒃,需要通过 tf.Variable 包裹以便 TensorFlow 跟踪相关梯度信息。
aa = tf.Variable(a) # 转换为 Variable 类型
tf.zeros([]),tf.ones([]) # 创建全0,全1的标量
【线性变换𝒚 = 𝑾𝒙 + 𝒃,将权值矩阵𝑾初始化为全 1 矩阵,偏置 b 初始化为全 0 向量】
tf.zeros_like(a) # 创建一个与a形状相同,但是全0的新矩阵
tf.ones_like(a) # 创建一个与a形状相同,但是全1的新矩阵
tf.fill(shape, value)可以创建全为自定义数值 value 的张量,形状由 shape 参数指定
tf.fill([2,2], 99) # 创建2行2列,元素全为99的矩阵
tf.random.normal([2,2], mean=1,stddev=2) # 创建正态分布的张量
tf.random.uniform([2,2]) # 创建采样自[0,1)均匀分布的矩阵 Out[35]:
tf.random.uniform([2,2],maxval=10) # 创建采样自[0,10)均匀分布的矩阵
tf.random.uniform([2,2],maxval=100,dtype=tf.int32)# 创建采样自[0,100)均匀分布的整型矩阵
tf.range(1,10,delta=2) # 1~10通过 tf.range(start, limit, delta=1)可以创建[start, limit),步长为 delta 的序列,不包含 limit 本身
标量最容易理解,它就是一个简单的数字,维度数为 0,shape 为 []。标量的一些典型用途是误差值的表示、各种测量指标的表示,比如准确度(Accuracy, 简称 acc),精度(Precision)和召回率(Recall)等。
向量是一种非常常见的数据载体,如在全连接层和卷积神经网络层中,偏置张量𝒃就 使用向量来表示。

矩阵也是非常常见的张量类型,比如全连接层的批量输入张量𝑿的形状为[𝑏, 𝑑in],其 中𝑏表示输入样本的个数,即 Batch Size,𝑑in表示输入特征的长度。
x = tf.random.normal([2,4]) # 2个样本,特征长度为4的张量
fc.kernel # 查看权值矩阵W
三维张量
三维的张量一个典型应用是表示序列信号,它的格式是𝑿 = [𝑏, sequence len, feature len]
𝑏表示序列信号的数量
sequence len 表示序列信号在时间维度上的采样点数或步数,
feature len 表示每个点的特征长度。

embedding=layers.Embedding(10000, 100) 通过 layers.Embedding 层将数字编码 的单词转换为长度为 100 个词向量
out = embedding(x_train) # 将数字编码的单词转换为词向量
x_train 张量的 shape 为[25000,80],
句子out张量的 shape 变为[25000,80,100],其中 100 表 示每个单词编码为长度是 100 的向量。
四维张量在卷积神经网络中应用非常广泛,它用于保存特征图(Feature maps)数据,格式一般定义为[𝑏, h, w, 𝑐]
其中𝑏表示输入样本的数量,h/ 分别表示特征图的高/宽,𝑐表示特征图的通道数,部分深 度学习框架也会使用[𝑏, 𝑐, h,w ]格式的特征图张量,例如 PyTorch。
layer = layers.Conv2D(16,kernel_size=3) # 创建卷积神经网络
out = layer(x) # 前向计算
索引
x = tf.random.normal([4,32,32,3]) # 创建4D张量,输入𝑿为 4 张32 × 32大小的彩色图片
x[0] # 程序中的第一的索引号应为0,容易混淆
x[0][1] 取第1张图片的第2行
x[0][1][2] 取第1张图片,第2行,第3列的数据
x[2][1][0][1] 取第3张图片,第2行,第1列的像素,B通道(第2个通道)颜色强度值
x[1,9,2] 取第2张图片,第10行,第3列的数据
切片
通过start: end: step切片方式可以方便地提取一段数据,其中 start 为开始读取位置的索引,end 为结束读取位置的索引(不包含 end 位),step 为采样步长。
x[1:3] 读取第 2,3 张图片
全部省略时即为::,表示从最开始读取到最末尾,步长为 1,即不跳过任何 元素。如 x[0,::]表示读取第 1 张图片的所有行,其中::表示在行维度上读取所有行,它等价 于 x[0]的写法
x[0,::] # 读取第一张图片
x[ : , 0:28:2 , 0:28:2 , : ] 表示读取所有图片、隔行采样、隔列采样,、读取所有通道数据,相当于在图片的高宽上各 缩放至原来的 50%。

x[8:0:-1] # 从8取到0,逆序,不包含0
【当step = −1时,start: end: −1表 示从 start 开始,逆序读取至 end 结束(不包含 end),索引号𝑒𝑛𝑑 ≤ 𝑠𝑡𝑎𝑟𝑡。考虑一个 0~9 的 简单序列向量,逆序取到第 1 号元素,不包含第 1 号】
x[::-1] # 逆序全部元素
x[::-2]# 逆序间隔采样
x[0, ::-2, ::-2] # 行、列逆序间隔采样【第一张,行,列】读取每张图片的所有通道,其中行按着逆序隔行采样,列按着逆序隔行采样
x[:,:,:,1] # 取G通道数据
当切片方式出现⋯符号时,⋯符号左边 的维度将自动对齐到最左边,⋯符号右边的维度将自动对齐到最右边,此时系统再自动推 断⋯符号代表的维度数量

x[0:2,...,1:] # 高宽维度全部采集 读取第1~2张图片的G/B通道数据
x[2:,...] # 高、宽、通道维度全部采集,等价于x[2:] ⚠️读取最后2张图片(此处这样写,这是因为一共就4张图片)
x[...,:2] # 所有样本,所有高、宽的前2个通道
【本质上切 片操作只有start: end: step这一种基本形式】
维度变换
当现有的数据格式不满足算 法要求时,需要通过维度变换将数据调整为正确的格式。这就是维度变换的功能。
基本的维度变换操作函数包含了改变视图 reshape、插入新维度 expand_dims,删除维 度 squeeze、交换维度 transpose、复制数据 tile 等函数。

x=tf.range(96) # 生成向量
x=tf.reshape(x,[2,4,4,3]) # 改变x的视图,获得4D张量,存储并未改变
x.ndim # 获取张量的维度数
x.shape # 获取张量的形状列表
tf.reshape(x,[2,-1]) 参数−1表示当前轴上长度需要根据张量总元素不变的法则自动推导,从而方便用户 书写
tf.reshape(x,[2,4,12])
tf.reshape(x,[2,-1,3]) 存储顺序始终没有改变
x = tf.random.uniform([28,28],maxval=10,dtype=tf.int32)
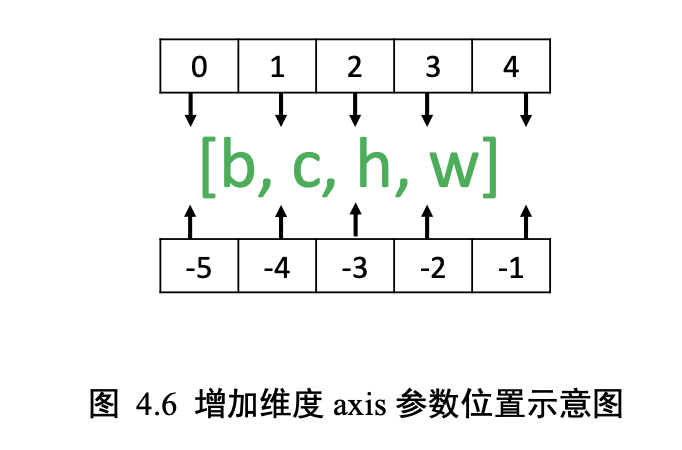
x = tf.expand_dims(x,axis=2) # axis=2 表示宽维度后面的一个维度
x = tf.expand_dims(x,axis=0) # 高维度之前插入新维度
tf.expand_dims 的 axis 为正时,表示在当前维度之前插入一个新维度;为 负时,表示当前维度之后插入一个新的维度。
删除维度
是增加维度的逆操作,与增加维度一样,删除维度只能删除长度为 1 的维 度,也不会改变张量的存储。
x = tf.squeeze(x, axis=0) # 删除图片数量维度
⚠️如果不指定维度参数 axis,即 tf.squeeze(x),那么它会默认删除所有长度为 1 的维度
建议使用 tf.squeeze()时逐一指定需要删除的维度参数,防止 TensorFlow 意外删除
交换 维度(Transpose)。
通过交换维度操作,改变了张量的存储顺序,同时也改变了张量的视 图。
使用 tf.transpose(x, perm)函数完成维度交换操作,其中参数 perm 表示新维度的顺序 List。
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,2,1,3]) # 交换维度
维度交换后,张量的存储顺序已经改变,视图也 随之改变,后续的所有操作必须基于新的存续顺序和视图进行。相对于改变视图操作,维 度交换操作的计算代价更高。
复制数据
tf.tile(x, multiples)函数完成数据在指定维度上的复制操作,multiples 分别指 定了每个维度上面的复制倍数,对应位置为 1 表明不复制,为 2 表明新长度为原来长度的 2 倍,即数据复制一份,以此类推。
b = tf.tile(b, multiples=[2,1]) # 样本维度上复制一份 ⚠️[2,1],其中2表示在 axis=0 维度复制 1 次,1表示在 axis=1 维度不复制。 可以这样理解[维度0,维度1]和[复制为当前的两倍,复制为当前一倍(即不复制])
x = tf.tile(x,multiples=[1,2]) # 列维度复制一份
x = tf.tile(x,multiples=[2,1]) # 行维度复制一份
【可以这么看,先看list里面,每一个元素的位置代表着a xi s的位置,数字代表倍数,1则不变】
Broadcasting 称为广播机制
和 tf.tile 复 制的最终效果是一样的
节省了大量计算资源, 建议在运算过程中尽可能地利用 Broadcasting 机制提高计算效率。
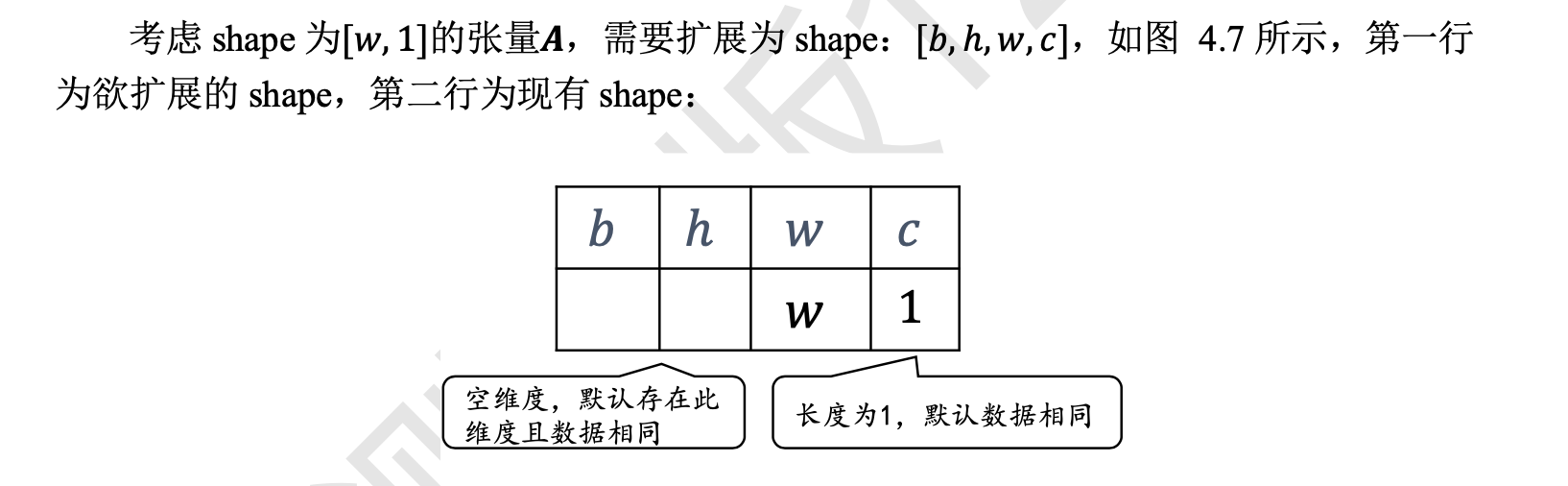
先将张量 shape 靠右对齐,然后进行普适性判断:对于长度为 1 的维 度,默认这个数据普遍适合于当前维度的其他位置;对于不存在的维度,则在增加新维度 后默认当前数据也是普适于新维度的,从而可以扩展为更多维度数、任意长度的张量形 状。
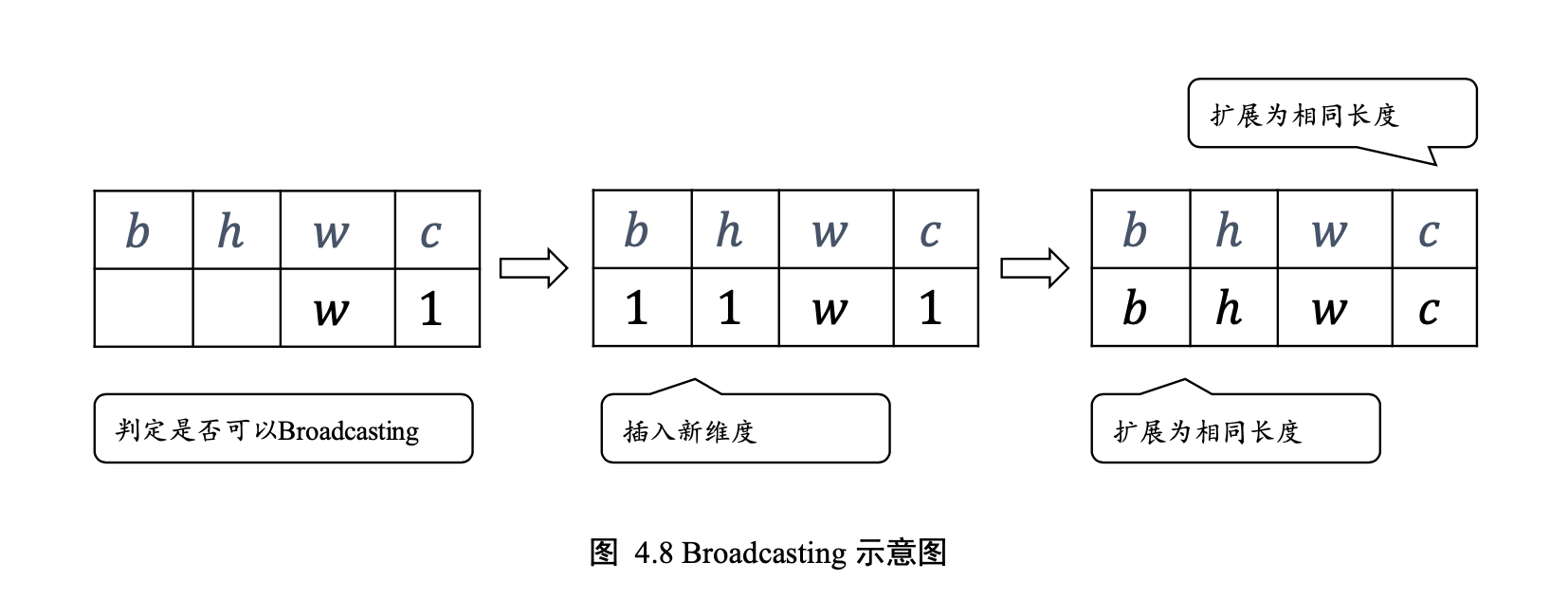
tf.broadcast_to(A, [2,32,32,3]) # 扩展为4D张量
加、减、乘、除
是最基本的数学运算,分别通过 tf.add, tf.subtract, tf.multiply, tf.divide 函数实现,TensorFlow 已经重载了+、 − 、 ∗ 、/运算符,一般推荐直接使用运算符来完成 加、减、乘、除运算。
整除和余除也是常见的运算之一,分别通过//和%运算符实现。
a//b # 整除运算
a%b # 余除运算
tf.pow(x,3) # 乘方运算
x**2 # 乘方运算符
x**(0.5) # 平方根
对于常见的平方和平方根运算,可以使用 tf.square(x)和 tf.sqrt(x)
x = tf.square(x) # 平方
tf.sqrt(x) # 平方根
通过 tf.pow(a, x)或者**运算符也可以方便地实现指数运算𝑎的𝑥次方
2**x # 指数运算
tf.exp(1.) # 自然指数运算(自然指数e𝑥)
自然对数loge X可以通过 tf.math.log(x)实现
tf.math.log(x) # 对数运算

tf.math.log(x)/tf.math.log(10.) # 换底公式
矩阵相乘运算
通过@运算符可以方便的实现矩阵相乘,还可以通过 tf.matmul(a, b)函数实现。
TensorFlow 中的 矩阵相乘可以使用批量方式,也就是张量𝑨和𝑩的维度数可以大于 2。
当张量𝑨和𝑩维度数大 于 2 时,TensorFlow 会选择𝑨和𝑩的最后两个维度进行矩阵相乘,前面所有的维度都视作 Batch 维度。【⚠️❓前面所有的维度都视作 Batch 维度】
𝑨和𝑩能够矩阵相乘的条件是,𝑨的倒数第一个维度长度(列)和𝑩 的倒数第二个维度长度(行)必须相等。
比如张量 a shape:[4,3,28,32]可以与张量 b shape:[4,3,32,2]进行矩阵相乘 【⚠️注意这里就是看32这个数字的位置上必须相同】
到现在为止,我们已经介绍了如何创建张量、对张量进行索引切片、维度变换和常见 的数学运算等操作。最后我们将利用已经学到的知识去完成三层神经网络的实现: out = 𝑅𝑒𝐿𝑈{𝑅𝑒𝐿𝑈{𝑅𝑒𝐿𝑈[𝑿@𝑾1 + 𝒃1]@𝑾2 + 𝒃2}@𝑾 + 𝒃 } 我们采用的数据集是 MNIST 手写数字图片集,输入节点数为 784,第一层的输出节点数是256,第二层的输出节点数是 128,第三层的输出节点是 10,也就是当前样本属于 10 类别 的概率。 首先创建每个非线性层的𝑾和𝒃张量参数,代码如下: # 每层的张量都需要被优化,故使用Variable类型,并使用截断的正太分布初始化权值张量 # 偏置向量初始化为0即可 # 第一层的参数 w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1)) b1 = tf.Variable(tf.zeros([256])) # 第二层的参数 w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1)) b2 = tf.Variable(tf.zeros([128])) # 第三层的参数 w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1)) b3 = tf.Variable(tf.zeros([10])) 在前向计算时,首先将 shape 为[𝑏, 28,28]的输入张量的视图调整为[𝑏, 784],即将每个 图片的矩阵数据调整为向量特征,这样才适合于网络的输入格式: 接下来完成第一个层的计算,我们这里显示地进行自动扩展操作: 用同样的方法完成第二个和第三个非线性函数层的前向计算,输出层可以不使用 ReLU 激 活函数: 将真实的标注张量𝒚转变为 One-hot 编码,并计算与 out 的均方差,代码如下: # 改变视图,[b, 28, 28] => [b, 28*28] x = tf.reshape(x, [-1, 28*28]) # 第一层计算,[b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256] h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256]) h1 = tf.nn.relu(h1) # 通过激活函数 # 第二层计算,[b, 256] => [b, 128] h2 = h1@w2 + b2 h2 = tf.nn.relu(h2) # 输出层计算,[b, 128] => [b, 10] out = h2@w3 + b3 # 计算网络输出与标签之间的均方差,mse = mean(sum(y-out)^2) # [b, 10] loss = tf.square(y_onehot - out) # 误差标量,mean: scalar loss = tf.reduce_mean(loss) 上述的前向计算过程都需要包裹在 with tf.GradientTape() as tape 上下文中,使得前向计算时 能够保存计算图信息,方便自动求导操作。 通过 tape.gradient()函数求得网络参数到梯度信息,结果保存在 grads 列表变量中,实 现如下: # 自动梯度,需要求梯度的张量有[w1, b1, w2, b2, w3, b3] grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3]) 并按照 来更新网络参数: 𝜃′ = 𝜃 − 𝜂 ∙(𝜕L/𝜕𝜃) # 梯度更新,assign_sub 将当前值减去参数值,原地更新 w1.assign_sub(lr * grads[0]) b1.assign_sub(lr * grads[1]) w2.assign_sub(lr * grads[2]) b2.assign_sub(lr * grads[3]) w3.assign_sub(lr * grads[4]) b3.assign_sub(lr * grads[5]) 其中 assign_sub()将自身减去给定的参数值,实现参数的原地(In-place)更新操作。
第5章 TensorFlow 进阶
合并
合并是指将多个张量在某个维度上合并为一个张量。
张量的合并可以使用拼接(Concatenate)和堆叠(Stack)操作实现
拼接
拼接操作并不会产生新 的维度,仅在现有的维度上合并,而堆叠会创建新维度。
通过 tf.concat(tensors, axis)函数拼接张量,其中参数 tensors 保存了所有需要合并的张量 List,axis 参数指定需要合并的维度索引。
tf.concat([a,b],axis=0) # 拼接合并成绩册
拼接合并操作可以在任意的维度上进行,唯一的约束是非合并维度的 长度必须一致。【⚠️仅允许合并的两个向量只有一个维度是不一样的】
堆叠
如果在合并数据 时,希望创建一个新的维度,则需要使用 tf.stack 操作。【⚠️这里会根据你的设定多出来一个维度】
用 tf.stack(tensors, axis)可以堆叠方式合并多个张量,通过 tensors 列表表示,参数 axis 指定新维度插入的位置,axis 的用法与 tf.expand_dims 的一致,当axis ≥ 0时,在 axis 之前插入;当axis < 0时,在 axis 之后插入新维度。
a = tf.random.normal([35,8])
b = tf.random.normal([35,8])
tf.stack([a,b],axis=0) # 堆叠合并为2个班级,班级维度插入在最前【a,b是两个向量】
tf.stack([a,b],axis=-1) # 在末尾插入班级维度
tf.stack 也需要满足张量堆叠合并条件,它需要所有待合并的张量 shape 完全一致才可 合并。
分割
合并操作的逆过程就是分割,将一个张量分拆为多个张量。
通过 tf.split(x, num_or_size_splits, axis)可以完成张量的分割操作,参数意义如下:
-
❑ x参数:待分割张量。
-
❑ num_or_size_splits参数:切割方案。当num_or_size_splits为单个数值时,如10,表 示等长切割为 10 份;当 num_or_size_splits 为 List 时,List 的每个元素表示每份的长 度,如[2,4,2,2]表示切割为 4 份,每份的长度依次是 2、4、2、2。
-
❑ axis参数:指定分割的维度索引号。 现在我们将总成绩册张量切割为 10 份,代码如下
result = tf.split(x, num_or_size_splits=10, axis=0)# 等长切割为10份
result = tf.split(x, num_or_size_splits=[4,2,2,2] ,axis=0) # 自定义长度的切割,切割为4份,返回4个张量的列表result
如果希望在某个维度上全部按长度为 1 的方式分割,还可以使用 tf.unstack(x, axis)函数。这种方式是 tf.split 的一种特殊情况,切割长度固定为 1,只需要指定切割维度 的索引号即可。
result = tf.unstack(x,axis=0) # Unstack为长度为1的张量【⚠️指定切割的那个维度会消失】
向量范数
向量范数(Vector Norm)是表征向量“长度”的一种度量方法,它可以推广到张量上。
在神经网络中,常用来表示张量的权值大小,梯度大小等。

对于矩阵和张量,同样可以利用向量范数的计算公式,等价于将矩阵和张量打平成向量后 计算。
在 TensorFlow 中,可以通过 tf.norm(x, ord)求解张量的 L1、L2、∞等范数,其中参数 ord 指定为 1、2 时计算 L1、L2 范数,指定为 np.inf 时计算∞ −范数
tf.norm(x,ord=1) # 计算L1范数
tf.norm(x,ord=2) # 计算L2范数
tf.norm(x,ord=np.inf) # 计算∞范数
最值、均值、和
通过 tf.reduce_max、tf.reduce_min、tf.reduce_mean、tf.reduce_sum 函数可以求解张量
在某个维度上的最大、最小、均值、和,也可以求全局最大、最小、均值、和信息。
tf.reduce_max(x,axis=1) # 统计概率维度上的最大值
tf.reduce_min(x,axis=1) # 统计概率维度上的最小值
tf.reduce_mean(x,axis=1) # 统计概率维度上的均值
当不指定 axis 参数时,tf.reduce_*函数会求解出全局元素的最大、最小、均值、和等 数据
tf.reduce_max(x),tf.reduce_min(x),tf.reduce_mean(x) # 统计全局的最大、最小、均值、和,返回的张量均为标量
计算样本的平均误差,此时可以通过 tf.reduce_mean 在样本数维度上计算均值
out = tf.random.normal([4,10]) # 模拟网络预测输出
y = tf.constant([1,2,2,0]) # 模拟真实标签
y = tf.one_hot(y,depth=10) # one-hot编码
loss = keras.losses.mse(y,out) # 计算每个样本的误差
loss = tf.reduce_mean(loss) # 平均误差,在样本数维度上取均值
求和函数 tf.reduce_sum(x, axis),它可以求解张量在 axis 轴上所有 特征的和
out = tf.random.normal([4,10])
tf.reduce_sum(out,axis=-1) # 求最后一个维度的和
通过 tf.argmax(x, axis)和 tf.argmin(x, axis)可以求解在 axis 轴上,x 的最大值、最小值所 在的索引号
pred = tf.argmax(out, axis=1) # 选取概率最大的位置 【out是最后的预测输出值,在axis=1是预测的那个分类的概率在第二列上面】
张量比较
通过 tf.equal(a, b)(或 tf.math.equal(a, b),两者等价)函数可以比较这 2 个张量是否相等
out = tf.equal(pred,y) # 预测值与真实值比较,返回布尔类型的张量
先将布尔类型转换为整形张量,即 True 对应 为 1,False 对应为 0,再求和其中 1 的个数,就可以得到比较结果中 True 元素的个数
out = tf.cast(out, dtype=tf.float32) # 布尔型转int型
correct = tf.reduce_sum(out) # 统计True的个数
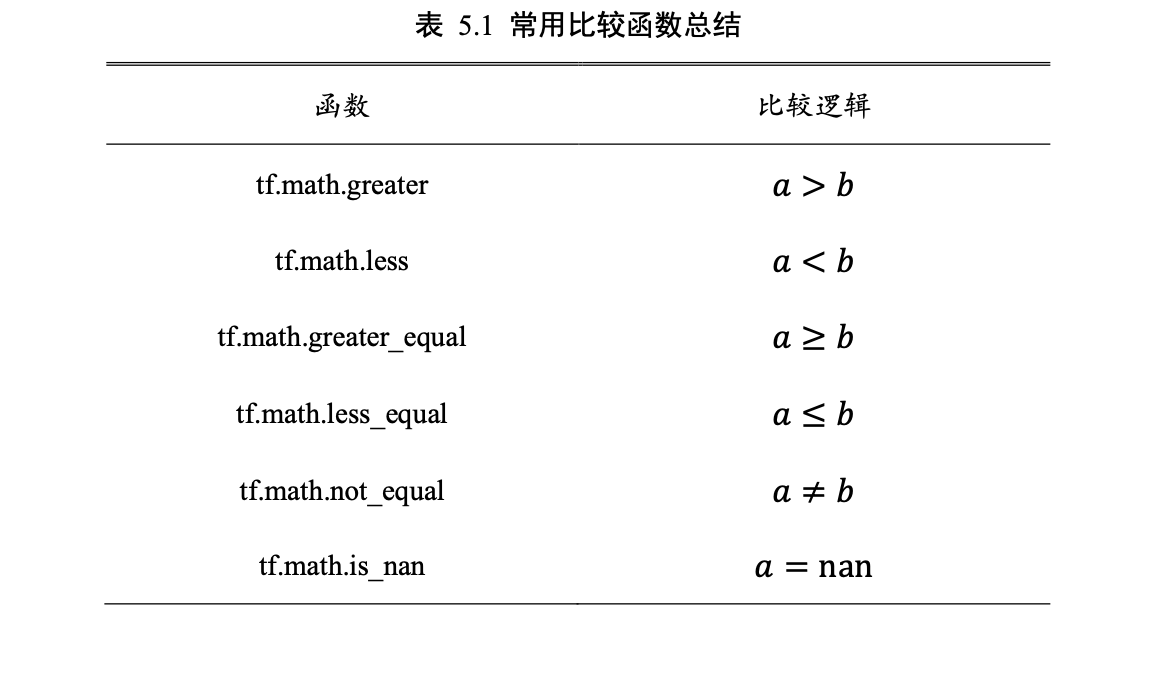
重复复制数据会破坏原有的数据结构,并不适合于此处。通常的做 法是,在需要补充长度的数据开始或结束处填充足够数量的特定数值,这些特定数值一般 代表了无效意义,例如 0,使得填充后的长度满足系统要求。
通过 tf.pad(x, paddings)函数实现,参数 paddings 是包含了多个
[Left Padding, Right Padding]的嵌套方案 List,
如[[0,0], [2,1], [1,2]]表示第一个维度不填 充,第二个维度左边(起始处)填充两个单元,右边(结束处)填充一个单元,第三个维度左边 填充一个单元,右边填充两个单元。
b = tf.pad(b, [[0,2]]) # 句子末尾填充 2 个 0
x_train = keras.preprocessing.sequence.pad_sequences(x_train,maxlen=max_review_len 【最大句子长度】,truncating='post',padding='post')
x = tf.random.normal([4,28,28,1])
tf.pad(x,[[0,0],[2,2],[2,2],[0,0]]) # 图片上下、左右各填充 2 个单元【⚠️这里是4不填充;28的前后填充两个零;28前后填充两个零;1不填充,第一个是28行,第二个是28列,所以总的效果就是四周填上两圈零】
复制
tf.tile 函数除了可以对长度为 1 的维度进行复制若干份,还可以对任意长度的维度进行复制 若干份,进行复制时会根据原来的数据次序重复复制。
如 shape 为[4,32,32,3]的数据, 复制方案为 multiples=[2,3,3,1],即通道数据不复制,高和宽方向分别复制 2 份,图片数再 复制 1 份【这里的2331讲的是倍数,2就是变成原来的俩倍,1就相当于不变,3就是变成原来的三遍】
x = tf.random.normal([4,32,32,3])
tf.tile(x,[2,3,3,1]) # 数据复制
数据限幅
考虑怎么实现非线性激活函数 ReLU 的问题。它其实可以通过简单的数据限幅运算实现,限制元素的范围𝑥 ∈ [0, +∞)即可
通过 tf.maximum(x, a)实现数据的下限幅,即𝑥 ∈ [𝑎, +∞);可
以通过 tf.minimum(x, a)实现数据的上限幅,即𝑥 ∈ (−∞, 𝑎]
tf.maximum(x,2) # 下限幅到 2
tf.minimum(x,7) # 上限幅到 7
tf.minimum(tf.maximum(x,2),7) # 限幅为 2~7
tf.clip_by_value(x,2,7) # 限幅为 2~7
tf.gather
tf.gather 可以实现根据索引号收集数据的目的。
x = tf.random.uniform([4,35,8],maxval=100,dtype=tf.int32) # 成绩册张量
tf.gather(x,[0,1],axis=0) # 在班级维度收集第 1~2 号班级成绩册【现在需要收集第 1~2 个班级的成绩册,可以给定需要收集班级的索引号:[0,1],并指定班 级的维度 axis=0】
tf.gather(x,[0,3,8,11,12,26],axis=1)# 收集第 1,4,9,12,13,27 号同学成绩
tf.gather(x,[2,4],axis=2) # 第 3,5 科目的成绩
抽查第[2,3]班级的第[3,4,6,27]号同学的科目 成绩,则可以通过组合多个 tf.gather 实现
students=tf.gather(x,[1,2],axis=0) # 收集第 2,3 号班级
tf.gather(students,[2,3,5,26],axis=1) # 收集第 3,4,6,27 号同学
【⚠️ 对于axis的理解,要把握到 层 的感觉,比如axis=0就是代表了整个大的方块里面第二大的那些方块的整体,而axis=1就是刚刚那个第二大的里面的方块,也就是第三大的方块,现在把方块替换成集合或者数组就能理解了】
tf.gather_nd
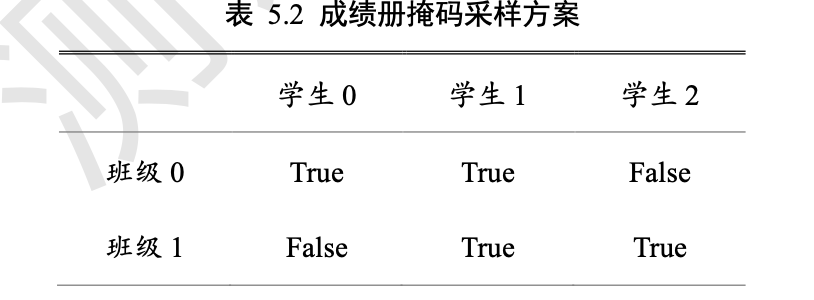
通过 tf.gather_nd 函数,可以通过指定每次采样点的多维坐标来实现采样多个点的目 的。
tf.gather_nd(x,[[0,0],[0,1],[1,1],[1,2]]) # 多维坐标采集 采样第 1 个班级的第 1~2 号学生,第 2 个班级的第 2~3 号学生
【[[0,0],[0,1],[1,1],[1,2]],理解为[[一班第一个],[一班第二个],[二班第二个],[二班第三个]]】
tf.gather_nd(x,[[1,1],[2,2],[3,3]]) 抽查第 2 个班级的第 2 个同学的所有科目,第 3 个班级的 第 3 个同学的所有科目,第 4 个班级的第 4 个同学的所有科目。
tf.gather_nd(x,[[1,1,2],[2,2,3],[3,3,4]])抽出了班级 1 的学生 1 的科目 2、班级 2 的学生 2 的科目 3、班级 3 的学 生 3 的科目 4 的成绩,共有 3 个成绩数据,结果汇总为一个 shape 为[3]的张量。
tf.boolean_mask
通过给定掩码(Mask)的方式进行采样。
tf.boolean_mask(x,mask=[True, False,False,True],axis=0) # 根据掩码方式采样班级,给出掩码和维度索引 采样第 1 和第 4 个班级的数据
【掩码的长度必须与对应维度的长度一致,如在班级维度上采样,则必须对这 4 个班级 是否采样的掩码全部指定,掩码长度为 4】
 采样第 1 个班级的第 1~2 号学生,第 2 个班级的第 2~3 号学生
采样第 1 个班级的第 1~2 号学生,第 2 个班级的第 2~3 号学生
tf.boolean_mask(x,[[True,True,False],[False,True,True]])
tf.where
通过 tf.where(cond, a, b)操作可以根据 cond 条件的真假从参数𝑨或𝑩中读取数据
𝑜𝑖 = {𝑎𝑖 cond𝑖为 True
𝑜𝑖 = {𝑏𝑖 cond𝑖为 False
a = tf.ones([3,3]) # 构造 a 为全 1 矩阵
b = tf.zeros([3,3]) # 构造 b 为全 0 矩阵
cond = tf.constant([[True,False,False],[False,True,False],[True,True,False]])# 构造采样条件
tf.where(cond,a,b) # 根据条件从 a,b 中采样
a 和 b 参数不指定,tf.where 会返回 cond 张量中所有 True 的 元素的索引坐标
tf.where(cond)
x = tf.random.normal([3,3]) # 构造 a
mask=x>0 # 比较操作,等同于 tf.math.greater()
indices=tf.where(mask) # 提取所有大于 0 的元素索引
tf.gather_nd(x,indices) # 提取正数的元素值
【⚠️where得到的是索引,要提取值还是需要用到gather】
也可以直接通过 tf.boolean_mask 获取所有正数的元 素向量:
tf.boolean_mask(x,mask) # 通过掩码提取正数的元素值
scatter_nd
通过 tf.scatter_nd(indices, updates, shape)函数可以高效地刷新张量的部分数据,但是这 个函数只能在全 0 的白板张量上面执行刷新操作,因此可能需要结合其它操作来实现现有 张量的数据刷新功能。

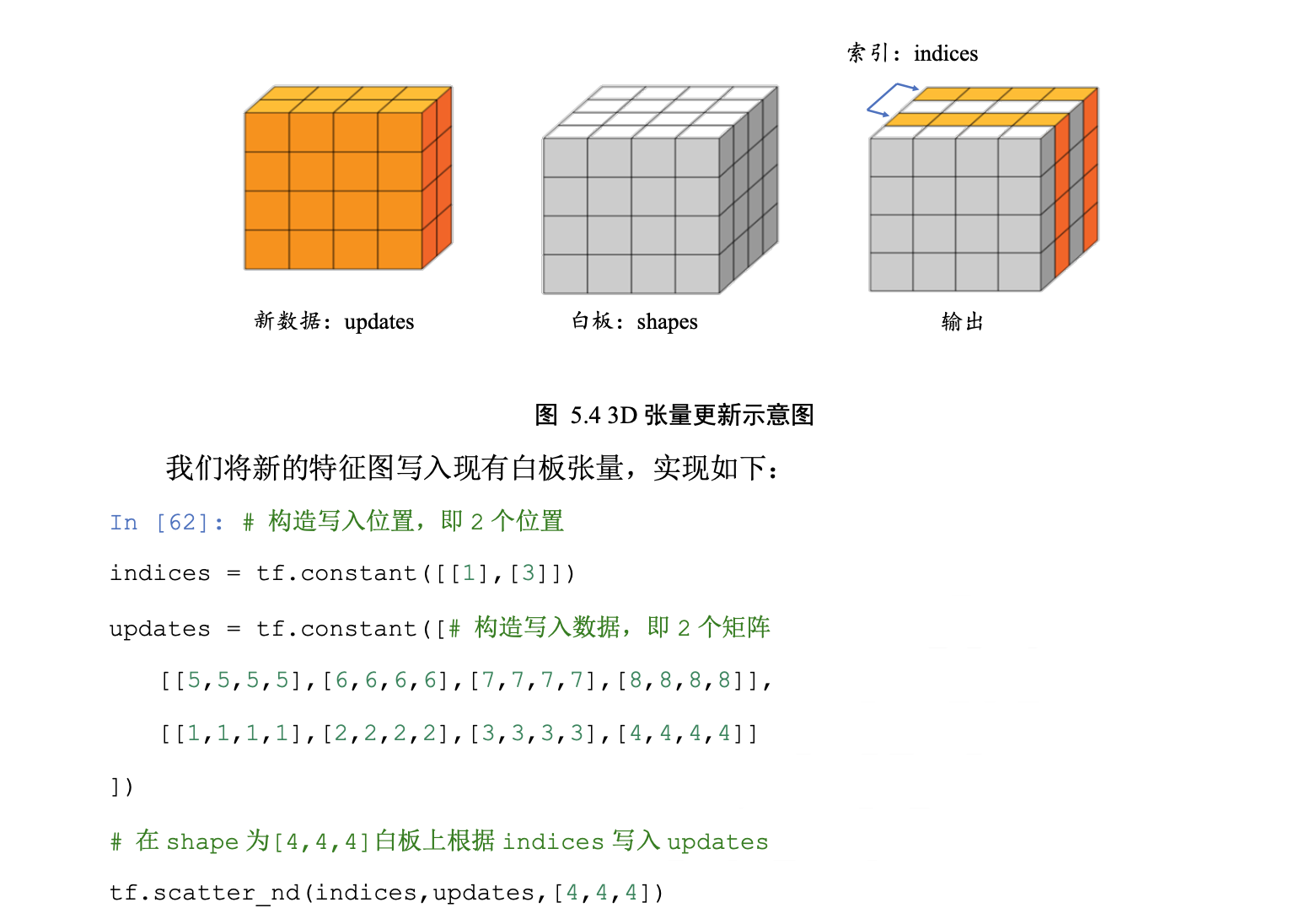
【理解为先构建了一块白板的画布,然后根据给出的位置把数据填到相应的位置上去】
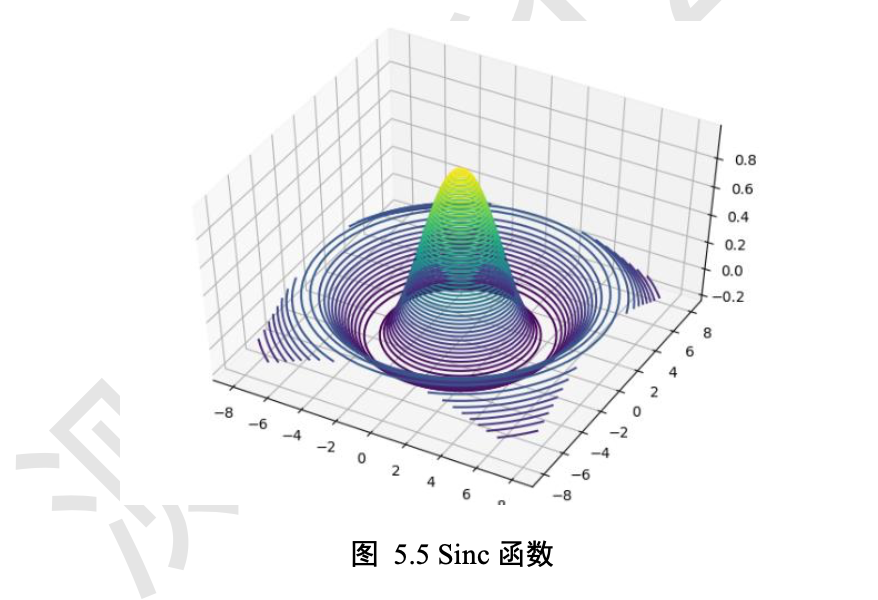
meshgrid
通过 tf.meshgrid 函数可以方便地生成二维网格的采样点坐标,方便可视化等应用场合。
x = tf.linspace(-8.,8,100) # 设置 x 轴的采样点
y = tf.linspace(-8.,8,100) # 设置 y 轴的采样点
x,y = tf.meshgrid(x,y) # 生成网格点,并内部拆分后返回
z = tf.sqrt(x**2+y**2)
z = tf.sin(z)/z # sinc函数实现
绘图
import matplotlib from matplotlib import pyplot as plt # 导入3D坐标轴支持 from mpl_toolkits.mplot3d import Axes3D fig = plt.figure() ax = Axes3D(fig) # 设置 3D 坐标轴 # 根据网格点绘制 sinc 函数 3D 曲面 ax.contour3D(x.numpy(), y.numpy(), z.numpy(), 50) plt.show()
经典数据集加载
-
通过 datasets.xxx.load_data()函数即可实现经典数据集的自动加载,其中 xxx 代表具体 的数据集名称
对于常用的经典数据集,例如:
-
❑ Boston Housing,波士顿房价趋势数据集,用于回归模型训练与测试。
-
❑ CIFAR10/100,真实图片数据集,用于图片分类任务。
-
❑ MNIST/Fashion_MNIST,手写数字图片数据集,用于图片分类任务。
-
❑ IMDB,情感分类任务数据集,用于文本分类任务。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成 Dataset 对象
train_db = tf.data.Dataset.from_tensor_slices((x, y)) # 构建 Dataset 对象
将数据转换成 Dataset 对象后,一般需要再添加一系列的数据集标准处理步骤,如随机打散、预处理、按批装载等。
随机打散
通过 Dataset.shuffle(buffer_size)工具可以设置 Dataset 对象随机打散数据之间的顺序, 防止每次训练时数据按固定顺序产生,从而使得模型尝试“记忆”住标签信息
train_db = train_db.shuffle(10000) # 随机打散样本,不会打乱样本与标签映射关系 buffer_size 参数指定缓冲池的大小,一般设置为一个较大的常数即可。
可以通过db = db. step1(). step2(). step3. ()完成所有的数据处理步骤
批训练
同时计算多个样本,我们 把这种训练方式叫做批训练,其中一个批中样本的数量叫做 Batch Size
train_db = train_db.batch(128) # 设置批训练,batch size 为 128,即一次并行计算 128 个样本的数据。
预处理
通过提供 map(func)工具函 数,可以非常方便地调用用户自定义的预处理逻辑
train_db = train_db.map(preprocess) def preprocess(x, y): # 自定义的预处理函数
循环训练
for step, (x,y) in enumerate(train_db): # 迭代数据集对象,带 step 参数
或for x,y in train_db: # 迭代数据集对象
每次返回的 x 和 y 对象即为批量样本和标签。
当对 train_db 的所有样本完 成一次迭代后,for 循环终止退出。
⚠️这样完成一个 Batch 的数据训练,叫做一个 Step;
⚠️通过 多个 step 来完成整个训练集的一次迭代,叫做一个 Epoch。
迭代多个 Epoch 才能取得较好地训练效果【epoches->steps->batch也就是先batchbatch地训练,一个step一个batch,几个batch组成几个step,几个step组成一个】
for epoch in range(20): # 训练 Epoch 数
for step, (x,y) in enumerate(train_db): # 迭代 Step 数
# training...
或 也可以通过设置 Dataset 对象,使得数据集对象内部遍历多次才会退出
train_db = train_db.repeat(20) # 数据集迭代 20 遍才终止
第6章 神经网络
感知机
𝑧 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + ⋯+ 𝑤𝑛 𝑥𝑛 + 𝑏 其中𝑏称为感知机的偏置(Bias),一维向量𝒘 = [𝑤1, 𝑤2, ... , 𝑤𝑛]称为感知机的权值(Weight),𝑧称为感知机的净活性值(Net Activation)。
【⚠️我们训练的寻找最好的w和b,xy反倒是已知的数据】不可导性
全连接层

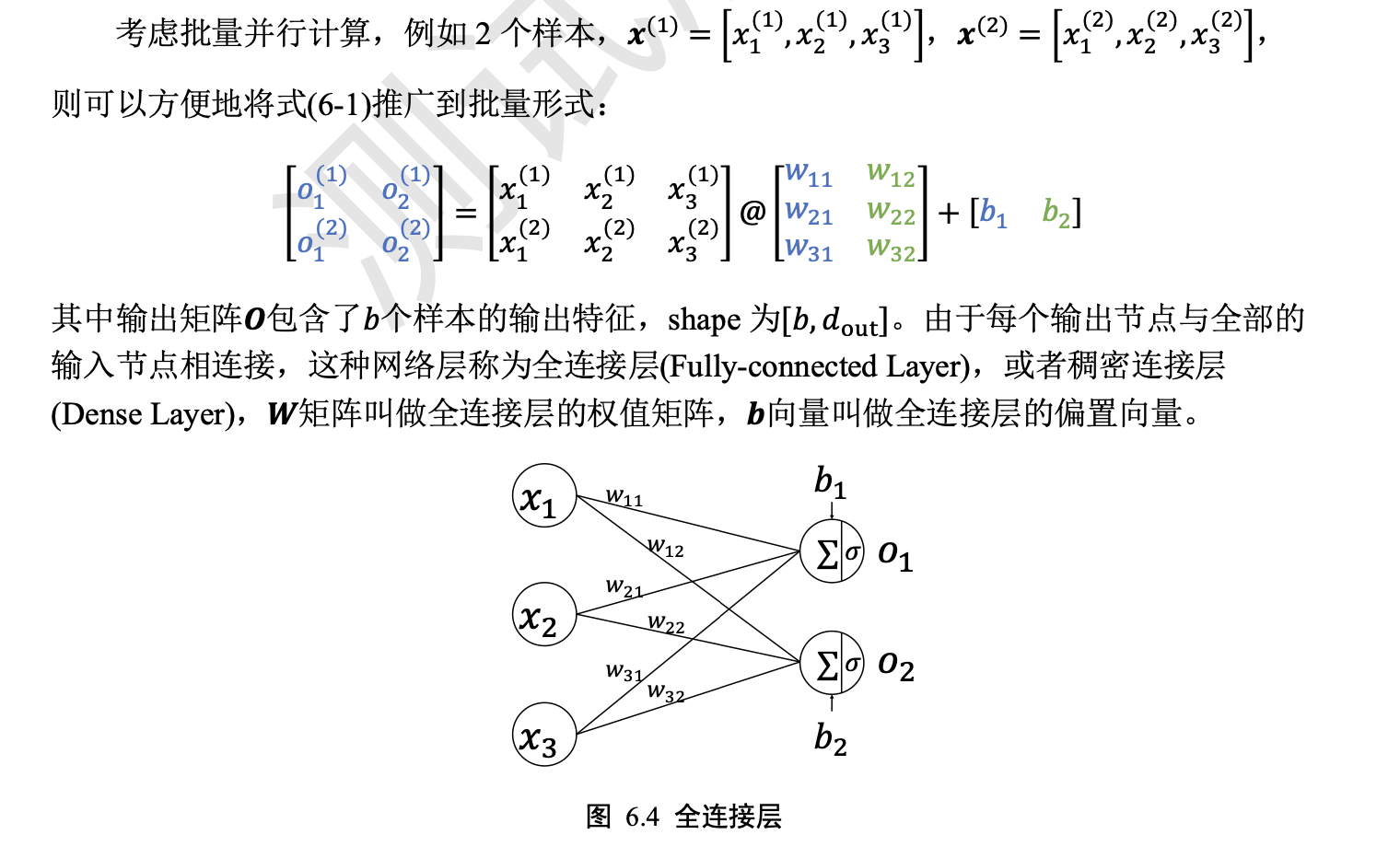
【此处直接结合着线性代数的矩阵运算来看,(m*n)x(n*k)=(m*k)】
张量方式实现【麻烦死了】
例如,创建输入𝑿 矩阵为𝑏 = 2个样本,每个样本的输入特征长度为𝑑in = 784,输出节点数为𝑑out = 256,故 定义权值矩阵𝑾的 shape 为[784,256],并采用正态分布初始化𝑾;偏置向量𝒃的 shape 定义 为[256],在计算完𝑿@𝑾后相加即可,最终全连接层的输出𝑶的 shape 为[2,256],即 2 个样 本的特征,每个特征长度为 256,代码实现如下: # 创建W,b张量 x = tf.random.normal([2,784]) w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1)) b1 = tf.Variable(tf.zeros([256])) o1 = tf.matmul(x,w1) + b1 # 线性变换 o1 = tf.nn.relu(o1) # 激活函数
层方式实现
layers.Dense(units, activation)。 通过 layer.Dense 类,只需要指定输出节点数 Units 和激活函数类型 activation 即可。
⚠️输入节点数会根据第一次运算时的输入 shape 确定,同时根据输入、输出节点数 自动创建并初始化权值张量𝑾和偏置张量𝒃,因此在新建类 Dense 实例时,并不会立即创 建权值张量𝑾和偏置张量𝒃,而是需要调用 build 函数或者直接进行一次前向计算,才能完 成网络参数的创建。
其中 activation 参数指定当前层的激活函数,可以为常见的激活函数或 自定义激活函数,也可以指定为 None,即无激活函数
x = tf.random.normal([4,28*28])
from tensorflow.keras import layers # 导入层模块
# 创建全连接层,指定输出节点数和激活函数
fc = layers.Dense(512, activation=tf.nn.relu)
h1 = fc(x) # 通过 fc 类实例完成一次全连接层的计算,返回输出张量shape=(4, 512)
fc.kernel # 获取 Dense 类的权值矩阵shape=(784, 512)
fc.bias # 获取 Dense 类的偏置向量shape=(512,)
【可以看见最后的结果是4*512,所以这里的计算应该是h1=x*kernel+bias⚠️❓𝑿@𝑾 + 𝒃中xk的顺序】
fc.trainable_variables# 返回待优化参数列表
fc.variables # 返回所有参数列表
设计全连接网络时,网络的结构配置等超参数可以按着经验法则自由设置,只需要 遵循少量的约束即可。
例如,隐藏层 1 的输入节点数需和数据的实际特征长度匹配
每层 的输入层节点数与上一层输出节点数匹配
输出层的激活函数和节点数需要根据任务的具 体设定进行设计。
【每层的 输出节点数不一定要设计为[256,128,64,10],可以自由搭配,如[256,256,64,10]或 [512,64,32,10]等都是可行的。
至于与哪一组超参数是最优的,这需要很多的领域经验知识 和大量的实验尝试,或者可以通过 AutoML 技术搜索出较优设定。】
张量方式实现【麻烦方法】
对于多层神经网络,以图 6.5 网络结构为例,需要分别定义各层的权值矩阵𝑾和偏置 向量𝒃。有多少个全连接层,则需要相应地定义数量相当的𝑾和𝒃,并且每层的参数只能用 于对应的层,不能混淆使用。图 6.5 的网络模型实现如下: 输入:[𝑏, 784] 隐藏层1:[256] 隐藏层2:[128] 隐藏层3:[64] 输出层:[𝑏, 10] # 隐藏层1张量 w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1)) b1 = tf.Variable(tf.zeros([256])) # 隐藏层2张量 w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1)) b2 = tf.Variable(tf.zeros([128])) # 隐藏层3张量 w3 = tf.Variable(tf.random.truncated_normal([128, 64], stddev=0.1)) b3 = tf.Variable(tf.zeros([64])) # 输出层张量 w4 = tf.Variable(tf.random.truncated_normal([64, 10], stddev=0.1)) b4 = tf.Variable(tf.zeros([10])) 在计算时,只需要按照网络层的顺序,将上一层的输出作为当前层的输入即可,重复 直至最后一层,并将输出层的输出作为网络的输出,代码如下: with tf.GradientTape() as tape: # 梯度记录器 # x: [b, 28*28] # 隐藏层 1 前向计算,[b, 28*28] => [b, 256] h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256]) h1 = tf.nn.relu(h1) # 隐藏层 2 前向计算,[b, 256] => [b, 128] h2 = h1@w2 + b2 h2 = tf.nn.relu(h2) # 隐藏层 3 前向计算,[b, 128] => [b, 64] h3 = h2@w3 + b3 h3 = tf.nn.relu(h3) # 输出层前向计算,[b, 64] => [b, 10] h4 = h3@w4 + b4 最后一层是否需要添加激活函数通常视具体的任务而定,这里加不加都可以。 在使用 TensorFlow 自动求导功能计算梯度时,需要将前向计算过程放置在 tf.GradientTape()环境中,从而利用 GradientTape 对象的 gradient()方法自动求解参数的梯 度,并利用 optimizers 对象更新参数。
层方式实现
# 导入常用网络层layers from tensorflow.keras import layers,Sequential fc1 = layers.Dense(256, activation=tf.nn.relu) # 隐藏层1 fc2 = layers.Dense(128, activation=tf.nn.relu) # 隐藏层2 fc3 = layers.Dense(64, activation=tf.nn.relu) # 隐藏层3 fc4 = layers.Dense(10, activation=None) # 输出层
在前向计算时,依序通过各个网络层即可,代码如下
x = tf.random.normal([4,28*28])
h1 = fc1(x) # 通过隐藏层 1 得到输出 h2 = fc2(h1) # 通过隐藏层 2 得到输出 h3 = fc3(h2) # 通过隐藏层 3 得到输出 h4 = fc4(h3) # 通过输出层得到网络输出
通过 Sequential 容器封装
# 导入Sequential容器 from tensorflow.keras import layers,Sequential # 通过Sequential容器封装为一个网络类 model = Sequential([ layers.Dense(256, activation=tf.nn.relu) , # 创建隐藏层 1 layers.Dense(128, activation=tf.nn.relu) , # 创建隐藏层 2
layers.Dense(64, activation=tf.nn.relu) , # 创建隐藏层 3 layers.Dense(10, activation=None) , # 创建输出层 ]) # 前向计算时只需要调用一次网络大类对象,即可完成所有层的按序计算: out = model(x) # 前向计算得到输出
优化目标
前向传播的最后一步就是完成误差的计算
L = 𝑔(𝑓 (𝒙),𝒚)
希望通过在训练集𝔻train上面学习到一组参数𝜃使 得训练的误差L最小
𝜃∗ = a⏟rg min 𝑔(𝑓 (𝒙), 𝒚), 𝑥 ∈ 𝔻train 𝜃
上述的最小化优化问题一般采用误差反向传播(Backward Propagation,简称 BP)算法来求解 网络参数𝜃的梯度信息,并利用梯度下降(Gradient Descent,简称 GD)算法迭代更新参数:
𝜃′ = 𝜃 − 𝜂 ∙ ∇𝜃L 𝜂为学习率。
完成的是特征的维度变换的功能
比如 4 层的 MNIST 手写数字图片识别的全连接网络,它依次完成了784 → 256 → 128 → 64 → 10的特 征降维过程。
原始的特征通常具有较高的维度,包含了很多底层特征及无用信息,通过神 经网络的层层特征变换,将较高的维度降维到较低的维度,
网络的参数量是衡量网络规模的重要指标。那么怎么计算全连接层的参数量呢?
考虑 权值矩阵𝑾,偏置向量𝒃,输入特征长度为𝑑in,输出特征长度为𝑑out的网络层,𝑾的参数 量为𝑑in ∙ 𝑑out,再加上偏置𝒃的参数,
⚠️总参数量为𝑑in ∙ 𝑑out + 𝑑out。
对于多层的全连接神经 网络,比如784 → 256 → 128 → 64 → 10,总参数量的计算表达式为:
(256 ∙ 784 + 256) +( 128 ∙ 256 + 128) + (64 ∙ 128 + 64 )+( 10 ∙ 64 + 10 )= 242762 约 242K 个参数。
激活函数
平滑可导的,适合于梯度下降算法。
Sigmoid 函数也叫 Logistic 函数
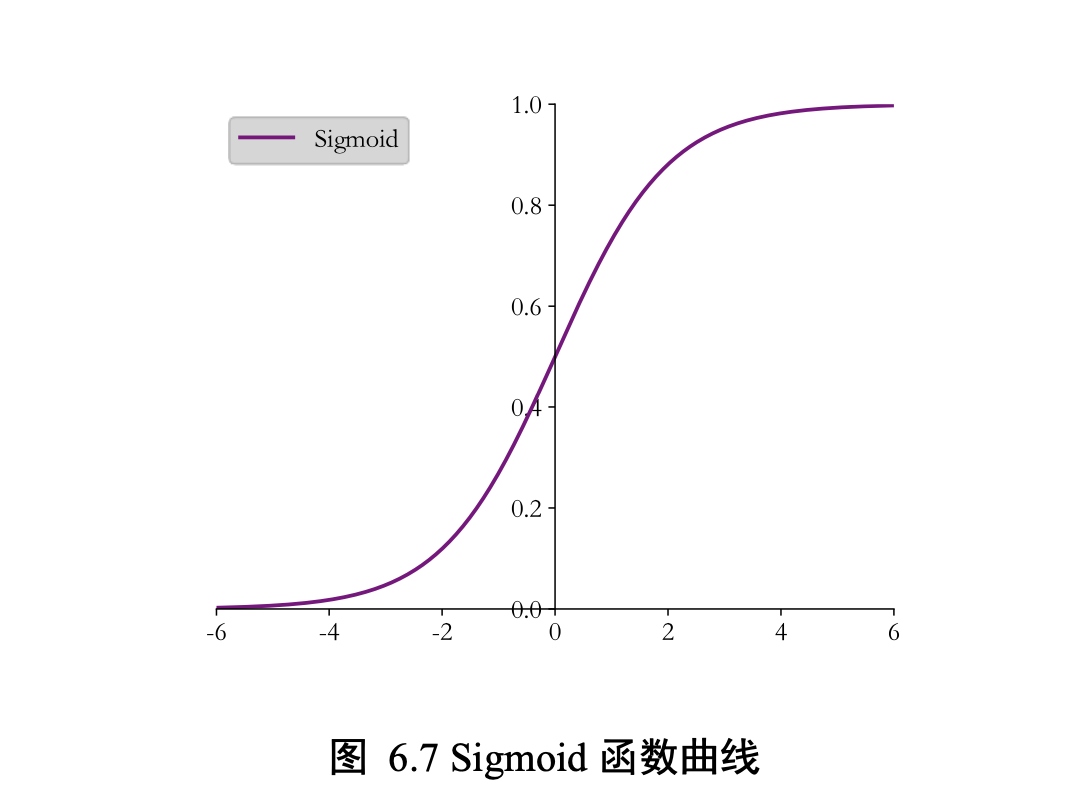
把𝑥 ∈ 𝑅的输入“压缩”到𝑥 ∈ (0,1)区间,这个区间的数值在机器学习常用来表示以下意义:
-
❑ 概率分布 (0,1)区间的输出和概率的分布范围[0,1]契合,可以通过 Sigmoid 函数将输出 转译为概率输出
-
❑ 信号强度 一般可以将 0~1 理解为某种信号的强度,如像素的颜色强度,1 代表当前通 道颜色最强,0 代表当前通道无颜色;抑或代表门控值(Gate)的强度,1 代表当前门控 全部开放,0 代表门控关闭
通过 tf.nn.sigmoid 实现 Sigmoid 函
x = tf.linspace(-6.,6.,10)
tf.nn.sigmoid(x) # 通过 Sigmoid 函数
【Sigmoid 函数在输入值较大或较小时容易出现梯度值接 近于 0 的现象,称为梯度弥散现象。出现梯度弥散现象时,网络参数长时间得不到更新, 导致训练不收敛或停滞不动的现象发生,较深层次的网络模型中更容易出现梯度弥散现 象。】
ReLU
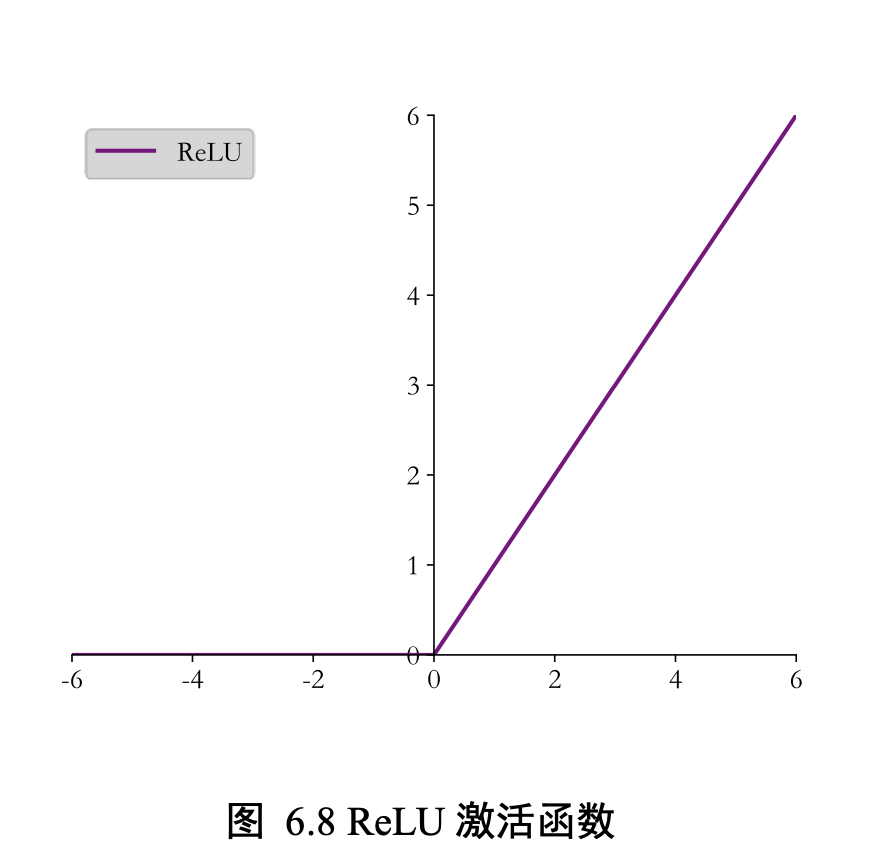
tf.nn.relu(x) # 通过 ReLU 激活函数
负数全部抑制为 0,正数得以保留。
【除了可以使用函数式接口 tf.nn.relu 实现 ReLU 函数外,还可以像 Dense 层一样将 ReLU 函数作为一个网络层添加到网络中,对应的类为 layers.ReLU()类。一般来说,激活 函数类并不是主要的网络运算层,不计入网络的层数。】
【ReLU 函数在𝑥 < 0时导数值恒为 0,也可能会造成梯度弥散现象】
LeakyReLU
通过 tf.nn.leaky_relu 实现 LeakyReLU 函数
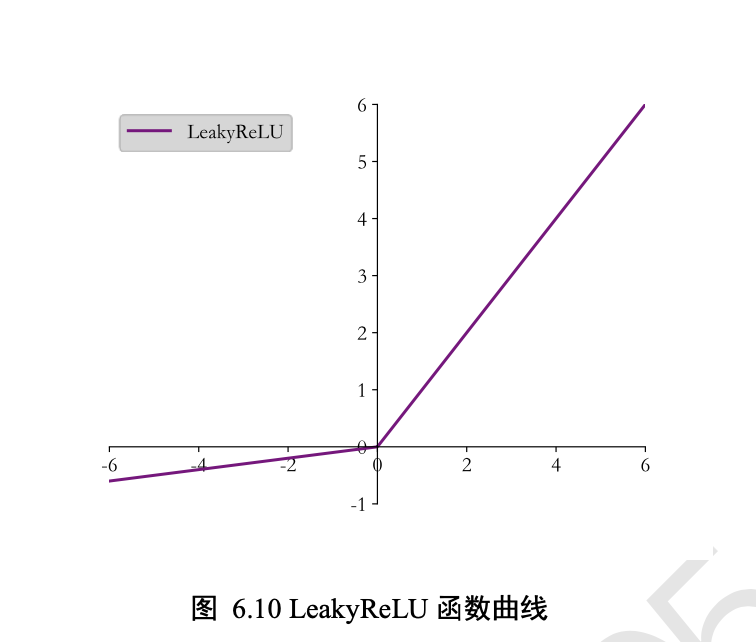
tf.nn.leaky_relu(x, alpha=0.1) # 通过 LeakyReLU 激活函数
Tanh
Tanh 函数能够将𝑥 ∈ 𝑅的输入“压缩”到(−1,1)区间= 2 ∙ sigmoid(2𝑥) − 1
tf.nn.tanh(x) # 通过 tanh 激活函数
输出层设计
普通实数空间
这一类问题比较普遍,像正弦函数曲线预测、年龄的预测、股票走势的预测等都属于 整个或者部分连续的实数空间,输出层可以不加激活函数。
误差的计算直接基于最后一层 的输出𝒐和真实值𝒚进行计算,如采用均方差误差函数度量输出值𝒐与真实值𝒚之间的距离:L = 𝑔(𝒐,𝒚)其中𝑔代表了某个具体的误差计算函数,例如 MSE 等。
[0, 1]区间
输出值属于[0, 1]区间也比较常见,比如图片的生成、二分类问题等。
需要在输出层后添 加某个合适的激活函数𝜎,其中 Sigmoid 函数刚好具有此功能。
[0,1]区间,和为 1
输出值𝑜𝑖 ∈ [0,1],且所有输出值之和为 1,这种设定以多分类问题最为常见。
输出层添加 Softmax 函数实现
不仅可以将输出值映射到[0,1]区间,还满足所有的输出值之和为 1 的特性。
tf.nn.softmax(z) # 通过 Softmax 函数
【在 Softmax 函数的数值计算过程中,容易因输入值偏大发生数值溢出现象;在计算交 叉熵时,也会出现数值溢出的问题。】
函数式接口为 tf.keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=False),其中 y_true 代表了 One-hot 编码后的真实标签,y_pred 表示网络的预测值,当 from_logits 设置为 True 时, y_pred 表示须为未经过 Softmax 函数的变量 z;当 from_logits 设置为 False 时,y_pred 表示 为经过 Softmax 函数的输出。
z = tf.random.normal([2,10]) # 构造输出层的输出
y_onehot = tf.constant([1,3]) # 构造真实值
y_onehot = tf.one_hot(y_onehot, depth=10) # one-hot编码
# 输出层未使用 Softmax 函数,故 from_logits 设置为 True
# 这样 categorical_crossentropy 函数在计算损失函数前,会先内部调用 Softmax 函数
loss = keras.losses.categorical_crossentropy(y_onehot,z,from_logits=True)
也可以利用 losses.CategoricalCrossentropy(from_logits)类方式同时实 现 Softmax 与交叉熵损失函数的计算,from_logits 参数的设置方式相同。
criteon = keras.losses.CategoricalCrossentropy(from_logits=True)
loss = criteon(y_onehot,z) # 计算损失
[-1, 1]
如果希望输出值的范围分布在(−1, 1)区间,可以简单地使用 tanh 激活函数
tf.tanh(x) # tanh激活函数
误差计算
在搭建完模型结构后,下一步就是选择合适的误差函数来计算误差。
均方差(Mean Squared Error,简称 MSE)误差函数
把输出向量和真实向量映射到笛卡尔 坐标系的两个点上,通过计算这两个点之间的欧式距离(准确地说是欧式距离的平方)来衡 量两个向量之间的差距
MSE 误差函数的值总是大于等于 0,当 MSE 函数达到最小值 0 时,输出等于真实标签, 此时神经网络的参数达到最优状态。
o = tf.random.normal([2,10]) # 构造网络输出
y_onehot = tf.constant([1,3]) # 构造真实值
y_onehot = tf.one_hot(y_onehot, depth=10)
loss = keras.losses.MSE(y_onehot, o) # 计算均方差
【⚠️MSE 函数返回的是每个样本的均方差,需要在样本维度上再次平均来获 得平均样本的均方差】
loss = tf.reduce_mean(loss) # 计算 batch 均方差
过层方式实现,对应的类为 keras.losses.MeanSquaredError()
criteon = keras.losses.MeanSquaredError() loss = criteon(y_onehot,o) # 计算 batch 均方差
交叉熵误差函数Cross Entrop
【这里面没有写,应该是用那个p ra se开头的交叉函数的损失函数】
最小化交叉熵损失函数的过程也是最大化正确类别的预测概率的过程。
熵越大,代表不确定性越大,信息量也就越大。
分类问题的 One-hot 编码的分布就是熵为 0 的典型例子。在 TensorFlow 中 间,我们可以利用 tf.math.log 来计算熵。
卷积神经网络CNN
用于图片分类的 AlexNet、VGG、GoogLeNet、ResNet、DenseNet 等,
用于目 标识别的 RCNN、Fast RCNN、Faster RCNN、Mask RCNN、YOLO、SSD 等。
循环神经网络RNN
RNN 变种LSTM 模型, Seq2Seq 模型,还有 GRU、双向 RNN
注意力(机制)网络Transformer
用于机器翻译的注意力网络模 型,如 GPT、BERT、GPT-2 等
自注意力(Self- Attention)机制构建的网络比如基于自注意力机制的 BigGAN 模型
图卷积神经网络GCN
类似于社交网 络、通信网络、蛋白质分子结构等一系列的不规则空间拓扑结构的数据
GAT,EdgeConv,DeepGCN 等。
利用全连接网络模型来完成汽车的效能指标 MPG(Mile Per Gallon,每加仑燃油英里数)的预测问题实战。


# 在线下载汽车效能数据集 dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto- mpg.data") # 利用 pandas 读取数据集,字段有效能(公里数每加仑),气缸数,排量,马力,重量 # 加速度,型号年份,产地 column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight', 'Acceleration', 'Model Year', 'Origin'] raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values = "?", comment='\t', sep=" ", skipinitialspace=True) dataset = raw_dataset.copy() # 查看部分数据 dataset.head() 原始表格中的数据可能含有空字段(缺失值)的数据项,需要清除这些记录项: 清除后,观察到数据集记录项减为 392 项。 由于 Origin 字段为类别类型数据,我们将其移除,并转换为新的 3 个字段:USA、 Europe 和 Japan,分别代表是否来自此产地: dataset.isna().sum() # 统计空白数据 dataset = dataset.dropna() # 删除空白数据项 dataset.isna().sum() # 再次统计空白数据 # 处理类别型数据,其中 origin 列代表了类别 1,2,3,分布代表产地:美国、欧洲、日本 # 先弹出(删除并返回)origin 这一列 origin = dataset.pop('Origin') # 根据 origin 列来写入新的 3 个列 dataset['USA'] = (origin == 1)*1.0 dataset['Europe'] = (origin == 2)*1.0 dataset['Japan'] = (origin == 3)*1.0 dataset.tail() # 查看新表格的后几项 按着 8:2 的比例切分数据集为训练集和测试集: 将 MPG 字段移出为标签数据: 统计训练集的各个字段数值的均值和标准差,并完成数据的标准化,通过 norm()函数 实现,代码如下: # 切分为训练集和测试集 train_dataset = dataset.sample(frac=0.8,random_state=0) test_dataset = dataset.drop(train_dataset.index) # 移动 MPG 油耗效能这一列为真实标签 Y train_labels = train_dataset.pop('MPG') test_labels = test_dataset.pop('MPG') # 查看训练集的输入 X 的统计数据 train_stats = train_dataset.describe() train_stats.pop("MPG") # 仅保留输入 X train_stats = train_stats.transpose() # 转置 # 标准化数据 def norm(x): # 减去每个字段的均值,并除以标准差 return (x - train_stats['mean']) / train_stats['std'] normed_train_data = norm(train_dataset) # 标准化训练集 normed_test_data = norm(test_dataset) # 标准化测试集 打印出训练集和测试集的大小: 利用切分的训练集数据构建数据集对象: 我们可以通过简单地统计数据集中各字段之间的两两分布来观察各个字段对 MPG 的 影响,如图 6.16 所示。可以大致观察到,其中汽车排量、重量与 MPG 的关系比较简单, 随着排量或重量的增大,汽车的 MPG 降低,能耗增加;气缸数越小,汽车能做到的最好 MPG 也越高,越可能更节能,这都是是符合我们的生活经验的。 图 6.16 特征之间的两两分布 6.8.2 创建网络 考虑到 Auto MPG 数据集规模较小,我们只创建一个 3 层的全连接网络来完成 MPG 值的预测任务。输入𝑿的特征共有 9 种,因此第一层的输入节点数为 9。第一层、第二层的 输出节点数设计为64和64,由于只有一种预测值,输出层输出节点设计为 1。考虑MPG ∈ 𝑅+,因此输出层的激活函数可以不加,也可以添加 ReLU 激活函数。 我们将网络实现为一个自定义网络类,只需要在初始化函数中创建各个子网络层,并 在前向计算函数 call 中实现自定义网络类的计算逻辑即可。自定义网络类继承自 keras.Model 基类,这也是自定义网络类的标准写法,以方便地利用 keras.Model 基类提供 的 trainable_variables、save_weights 等各种便捷功能。网络模型类实现如下: print(normed_train_data.shape,train_labels.shape) print(normed_test_data.shape, test_labels.shape) (314, 9) (314,) # 训练集共 314 行,输入特征长度为 9,标签用一个标量表示 (78, 9) (78,) # 测试集共 78 行,输入特征长度为 9,标签用一个标量表示 train_db = tf.data.Dataset.from_tensor_slices((normed_train_data.values, train_labels.values)) # 构建 Dataset 对象 train_db = train_db.shuffle(100).batch(32) # 随机打散,批量化 class Network(keras.Model): # 回归网络模型 def __init__(self): super(Network, self).__init__() # 创建3个全连接层 self.fc1 = layers.Dense(64, activation='relu') self.fc2 = layers.Dense(64, activation='relu') self.fc3 = layers.Dense(1) def call(self, inputs, training=None, mask=None): # 依次通过 3 个全连接层 x = self.fc1(inputs) x = self.fc2(x) x = self.fc3(x) return x 在完成主网络模型类的创建后,我们来实例化网络对象和创建优化器,代码如下: 接下来实现网络训练部分。通过 Epoch 和 Step 组成的双层循环训练网络,共训练 200 个 Epoch,代码如下: model = Network() # 创建网络类实例 # 通过 build 函数完成内部张量的创建,其中 4 为任意设置的 batch 数量,9 为输入特征长度 model.build(input_shape=(4, 9)) model.summary() # 打印网络信息 optimizer = tf.keras.optimizers.RMSprop(0.001) # 创建优化器,指定学习率 接下来实现网络训练部分。通过 Epoch 和 Step 组成的双层循环训练网络,共训练 200 个 Epoch for epoch in range(200): # 200个Epoch for step, (x,y) in enumerate(train_db): # 遍历一次训练集 # 梯度记录器,训练时需要使用它 with tf.GradientTape() as tape: out = model(x) # 通过网络获得输出 loss = tf.reduce_mean(losses.MSE(y, out)) # 计算 MSE mae_loss = tf.reduce_mean(losses.MAE(y, out)) # 计算 MAE if step % 10 == 0: # 间隔性地打印训练误差 print(epoch, step, float(loss)) # 计算梯度,并更新 grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables))
第7章 反向传播算法
第8章 Keras 高层接口
第9章 过拟合
第10章 卷积神经网络
第11章 循环神经网络
【【本章中的cell模式比较复杂,目前只列举 层模式 】】
序列表示方法
如果要表示𝑏件商品在 1 月到 6 月之间的价格 变化趋势,可以记为 2 维张量:
(1) (1) (1) (2) (2) (2) (𝑏) (𝑏) (𝑏)
[[𝑥1 ,𝑥2 ,⋯,𝑥6 ],[𝑥1 ,𝑥2 ,⋯,𝑥6 ],⋯,[𝑥1 ,𝑥2 ,⋯,𝑥6 ]]
其中𝑏表示商品的数量,张量 shape 为[𝑏, 6]。
Embedding 层
可以通过 layers.Embedding(𝑁vocab,𝑛)来定义一个 Word Embedding 层,其中𝑁vocab参数指定词汇数量,𝑛指定单词向量的长度
x = tf.range(10) # 生成 10 个单词的数字编码
x = tf.random.shuffle(x) # 打散
# 创建共 10 个单词,每个单词用长度为 4 的向量表示的层
net = layers.Embedding(10, 4)
out = net(x) # 获取词向量
预训练的词向量
embed_glove = load_embed('glove.6B.50d.txt')# 从预训练模型中加载词向量表
net.set_weights([embed_glove])# 直接利用预训练的词向量表初始化 Embedding 层
循环神经网络
在循环神经网络中,激活函数更多地采用 tanh 函数,并且可 以选择不使用偏执𝒃来进一步减少参数量。
状态向量 𝑡可以直接用作输出,即𝒐𝑡 = 𝑡,也 可以对 𝑡做一个简单的线性变换𝒐𝑡 = 𝑊 𝑜 𝑡后得到每个时间戳上的网络输出𝒐𝑡
SimpleRNN 与 SimpleRNNCell 的 区别在于,带 Cell 的层仅仅是完成了一个时间戳的前向运算,不带 Cell 的层一般是基于 Cell 层实现的,它在内部已经完成了多个时间戳的循环运算,
SimpleRNNCell手动参与循环神经网络内部的计算过程【这里不多做描述了,在11.4.2】
通过 SimpleRNN层高层接口可以非常方便地帮助我们实现此目的
单层循环神经网络的前向运算
layer = layers.SimpleRNN(64) # 创建状态向量长度为 64 的 SimpleRNN 层
x = tf.random.normal([4, 80, 100])
out = layer(x) # 和普通卷积网络一样,一行代码即可获得输出
out.shape Out[6]: TensorShape([4, 64])
【⚠️默认返回最 后一个时间戳上的输出。如果希望返回所有时间戳上的输出列表,可以设置 return_sequences=True 参数】
# 创建 RNN 层时,设置返回所有时间戳上的输出
layer = layers.SimpleRNN(64,return_sequences=True) out = layer(x) # 前向计算
out # 输出,⚠️自动进行了 concat 操作返回的输出张量 shape 为[4,80,64],中间维度的 80 即为时间戳维度。
多层循环神经网络,我们可以通过堆叠多个 SimpleRNN 实现
net = keras.Sequential([ # 构建 2 层 RNN 网络
layers.SimpleRNN(64, return_sequences=True), layers.SimpleRNN(64),]) ⚠️# 除最末层外,都需要返回所有时间戳的输出,用作下一层的输入
每层都需要上一层在每个时间戳上面的状态输出,因此除了最末层以外,所有的 RNN 层 都需要返回每个时间戳上面的状态输出,通过设置 return_sequences=True 来实现
RNN 情感分类问题实战
这里使用经典的 IMDB 影评数据集来完成情感分类任务。IMDB 影评数据集包含了 50000 条用户评价,评价的标签分为消极和积极,其中 IMDB 评级<5 的用户评价标注为 0,即消极;IMDB 评价>=7 的用户评价标注为 1,即积极。25000 条影评用于训练集, 25,000 条用于测试集。 通过 Keras 提供的数据集 datasets 工具即可加载 IMDB 数据集,代码如下: In [8]: batchsz = 128 # 批量大小 total_words = 10000 # 词汇表大小 N_vocab max_review_len = 80 # 句子最大长度 s,大于的句子部分将截断,小于的将填充
embedding_len = 100 # 词向量特征长度 n # 加载 IMDB 数据集,此处的数据采用数字编码,一个数字代表一个单词 (x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words) # 打印输入的形状,标签的形状 print(x_train.shape, len(x_train[0]), y_train.shape) print(x_test.shape, len(x_test[0]), y_test.shape) Out[8]:
(25000,) 218 (25000,) (25000,) 68 (25000,)
可以看到,x_train 和 x_test 是长度为 25,000 的一维数组,数组的每个元素是不定长 List, 保存了数字编码的每个句子,例如训练集的第一个句子共有 218 个单词,测试集的第一个 句子共有 68 个单词,每个句子都包含了句子起始标志 ID。
那么每个单词是如何编码为数字的呢?我们可以 In [9]: # 数字编码表 word_index = keras.datasets.imdb.get_word_index() # 打印出编码表的单词和对应的数字 for k,v in word_index.items(): print(k,v) 翻转编码表,并添加标志位的编码 ID # 前面4个ID是特殊位 word_index = {k:(v+3) for k,v in word_index.items()} word_index["<PAD>"] = 0 # 填充标志 word_index["<START>"] = 1 # 起始标志 word_index["<UNK>"] = 2 # 未知单词的标志 word_index["<UNUSED>"] = 3 # 翻转编码表 reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) 对于一个数字编码的句子,通过如下函数转换为字符串数据: def decode_review(text): return ' '.join([reverse_word_index.get(i, '?') for i in text])
句子截断功能可以通过 keras.preprocessing.sequence.pad_sequences()函 数方便实现
# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充 x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len) x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len) 截断或填充为相同长度后,通过 Dataset 类包裹成数据集对象,并添加常用的数据集处 理流程,代码如下:
⚠️ In [12]: # 构建数据集,打散,批量,并丢掉最后一个不够 batchsz 的 batch db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True) db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) db_test = db_test.batch(batchsz, drop_remainder=True) # 统计数据集属性 print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train)) print('x_test shape:', x_test.shape) Out[12]: x_train shape: (25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64) x_test shape: (25000, 80) 截断填充后的句子长度统一为 80,即设定的句子长度阈值。drop_remainder=True 参数设置丢弃掉最后一个 Batch,因为其真实的 Batch Size 可能小于预设的 Batch Siz
自定义的模型类 MyRNN,继承自 Model 基类,需要新建 Embedding 层,两个 RNN 层,分类网络层
class MyRNN(keras.Model): # Cell方式构建多层网络 def __init__(self, units): super(MyRNN, self).__init__() # [b, 64],构建Cell初始化状态向量,重复使用
self.state0 = [tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units])]
# 词向量编码 [b, 80] => [b, 80, 100] self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len) # 构建 2 个 Cell,使用 dropout 技术防止过拟合 self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
# 构建分类网络,用于将 CELL 的输出特征进行分类,2 分类 # [b, 80, 100] => [b, 64] => [b, 1] self.outlayer = layers.Dense(1) 其中词向量编码为长度𝑛 = 100,RNN 的状态向量长度h = units参数,分类网络完成 2 分 类任务,故输出节点设置为 1
前向传播逻辑如下:输入序列通过 Embedding 层完成词向量编码,循环通过两个 RNN 层,提取语义特征,取最后一层的最后时间戳的状态向量输出送入分类网络,经过 Sigmoid 激活函数后得到输出概率
def call(self, inputs, training=None):
x = inputs # [b, 80]
# 获取词向量: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# 通过 2 个 RNN CELL,[b, 80, 100] => [b, 64]
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1): # word: [b, 100]
out0, state0 = self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1, training)
# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]
x = self.outlayer(out1, training)
# 通过激活函数,p(y is pos|x)
prob = tf.sigmoid(x)
return prob
使用 Keras 的 Compile&Fit 方式训练网络,设置优化器为 Adam 优化 器,学习率为 0.001,误差函数选用 2 分类的交叉熵损失函数 BinaryCrossentropy,测试指 标采用准确率 def main(): units = 64 # RNN状态向量长度n epochs = 20 # 训练 epochs model = MyRNN(units) # 创建模型 # 装配 model.compile(optimizer = optimizers.Adam(0.001), loss = losses.BinaryCrossentropy(), metrics=['accuracy']) # 训练和验证 model.fit(db_train, epochs=epochs, validation_data=db_test) # 测试 model.evaluate(db_test) 网络固定训练 20 个 Epoch 后,在测试集上获得了 80.1%的准确率。
梯度值接近于 0 的现象叫做梯度弥散(Gradient Vanishing),把梯度值远大于 1 的 现象叫做梯度爆炸(Gradient Exploding)
第12章 自编码器
第13章 生成对抗网络
第14章 强化学习
第15章 自定义数据集
