hadoop3.1.0集群搭建
一.环境配置
jdk1.8
centos7
二.环境搭建
1.安装jdk
这个不用怎么说了吧,可以直接yum安装或者自己下载tar包。yum安装不用配置javahome,但是需要知道javahome位置,因为hadoop是java项目,运行需要jdk环境。通过yum安装查找javahome如下:
$whereis javac javac: /usr/bin/javac /usr/share/man/man1/javac.1.gz
可以看出结果是两个目录 用ll命令查看这两个目录详情
$ll /usr/bin/javac lrwxrwxrwx. 1 root root 23 8月 7 14:03 /usr/bin/javac -> /etc/alternatives/javac
这个是个软连接 指向/etc/alternatives/javac 继续对这个目录ll直至不在出现软连接为止
$ll /etc/alternatives/javac lrwxrwxrwx. 1 root root 70 8月 7 14:03 /etc/alternatives/javac -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/bin/javac
$ ll /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/bin/javac
-rwxr-xr-x. 1 root root 7424 7月 24 00:34 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/bin/javac
$ ll /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
总用量 50780
drwxr-xr-x. 2 root root 4096 8月 7 14:03 bin
drwxr-xr-x. 10 root root 134 8月 7 14:03 demo
drwxr-xr-x. 3 root root 132 8月 7 14:03 include
drwxr-xr-x. 4 root root 28 8月 7 14:03 jre
drwxr-xr-x. 3 root root 144 8月 7 14:03 lib
drwxr-xr-x. 11 root root 162 8月 7 14:03 sample
-rw-r--r--. 1 root root 51993150 7月 23 23:59 src.zip
drwxr-xr-x. 2 root root 204 8月 7 14:03 tapset
看出来这个文件夹就是jdk的安装路径了。
2 centos7 linux用户之间免登陆
a)分别在机器上创建相同的用户,设置密码
b)在a机器上运行ssh-keygen命令生成公钥私钥

c)将a中的公钥id_dsa.pub烤到b机器上,并查看是否有authorized_keys这个文件,如果有追加id_dsa.pub内容在authorized_keys文件中,没有则创建,并将它的权限修改为600(chmod 600 authorized_keys)
d)b中ssh测试是否能,免密连接
a连b亦是同理
3.安装hadoop
前置准备 三台机器ip,主机名分别为
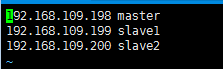
将三台机器/etc/hosts都修改为这种,ip主机名根据实际而定
a) 下载网站,选择合适的版本 http://mirror.bit.edu.cn/apache/hadoop/common/

b)下载好以后解压 tar -zxvf 安装包
c)配置 core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml 这四个文件hadoop安装包 etc/hadoop/目录下
core文件主要用于配置namenode地址和tmp文件地址
$ vim etc/hadoop/core-site.xml <configuration> <!-- 指定HDFS老大(namenode)的通信地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储路径 --> <property> <name>hadoop.tmp.dir</name> <value>/workhome/hadoop-3.1.0/data/tmp</value> </property> </configuration>
hdfs用于设置namenode datanode,hdfs备份份数 默认是3
dfs.permissionsdfs权限是否打开 ,通过idea远程操作的时候提示没有权限访问不了 因此设置为false 默认值是true
$ vim etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.name.dir</name> <value>/workhome/hadoop-3.1.0/hdfs/name</value> <description>namenode上存储hdfs名字空间元数据 </description> </property> <property> <name>dfs.data.dir</name> <value>/workhome/hadoop-3.1.0/hdfs/data</value> <description>datanode上数据块的物理存储位置</description> </property> <!-- 设置hdfs副本数量 --> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
mapred设置mapreduce
$ vim etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>mapred.job.tracker</name> <value>http://master:9001</value> </property> </configuration>
$ vim etc/hadoop/yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration>
修改 etc/hadoop/hadoop-env.sh 添加java安装路径
$ vim etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
配置hadoop环境变量
$ vim /etc/profile export HADOOP_HOME=/workhome/hadoop-3.1.0 export PATH=$PATH:$HADOOP_HOME/bin
然后将master这个hadoop完整的复制到其他机器即可
最后在master etc/hadoop下新增workers 将slave机器添加进去 ,以后要是扩展节点 也应该添加到这个里面

e)初始化:
hadoop namenode -format
f) 启动
只需启动master的
hadoop安装路径/sbin/start-all.sh
查看:jps命令 用来查看启动了的java服务
master

slave1

slave2

只需查看到master上有namenode slave上有datanode就代表成功。
g)关闭 /sbin/stop-all.sh脚本
四.遇到的问题以及解决方案
扩展一台机器,重启服务没有datanode
解决方案:清除 core-site.xml中配置的tmp文件夹 以及hdfs-site.xml中配置的datanode和namenode的文件夹 重新格式化namenode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号