[过程记录]Centos7 下 Hadoop分布式集群搭建
过程如下:
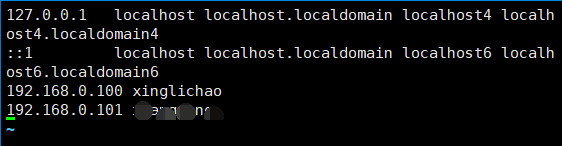
配置hosts
vim /etc/hosts
格式:
ip hostname
ip hostname
设置免密登陆
首先:每台主机使用ssh命令连接其余主机
ssh 用户名@主机名
提示是否连接:输入yes
提示输入密码:输入被请求连接主机的密码
成功过后
就会在本机的~目录下生成 .ssh文件夹
然后在master的主机上进入 ~/.ssh 目录
执行:
ssh-keygen -t rsa
回车回车再回车
得到 id_rsa id_rsa.pub 两个文件
复制一份 id_rsa.pub
cp id_rsa.pub authorized_keys
修改权限
修改.ssh权限
chmod -R 700 .ssh
修改quthorized_keys权限
chmod 600 authorized_keys
尝试ssh连接本机
ssh root@xinglichao

成功免密登陆
然后将 authorized_keys 分发到其他主机
scp ~/.ssh/authorized_keys root@****:~/.ssh
同样尝试ssh连接其余主机,全部可以免密登陆

下载好hadoop并解压到指定文件夹下

master以及其余主机上配置 /etc/profile
首先找到java的安装路径
[root@xinglichao-centos ~]# which java /usr/bin/java [root@xinglichao-centos ~]# ls -lrt /usr/bin/java lrwxrwxrwx. 1 root root 22 9月 25 18:42 /usr/bin/java -> /etc/alternatives/java [root@xinglichao-centos ~]# ls -lrt /etc/alternatives/java lrwxrwxrwx. 1 root root 71 9月 25 18:42 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java

然后编辑profile
vim /etc/profile
添加JAVA_HOME以及HADOOP_HOME

source一下使配置文件生效
source /etc/profile
master上修改hadoop的配置文件:hadoop-env.sh
vim /usr/apache/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
增加内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
export HADOOP_HOME=/usr/apache/hadoop-2.7.5

测试hadoop
hadoop
master上修改hadoop中的slaves文件,指定为另外主机名(此处不贴截图了)
vim /etc/hadoop/hadoop-2.7.5/etc/hadoop/slaves
master主机创建name节点文件夹,slaves节点创建data文件夹
master: mkdir -p hadoop/hadoop-2.7.5/node/dfs/name slaves: mkdir -p hadoop/hadoop-2.7.5/node/dfs/data
master中修改与hadoop-env.sh同文件夹下的core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://xinglichao:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.7.5/node</value> </property> </configuration>
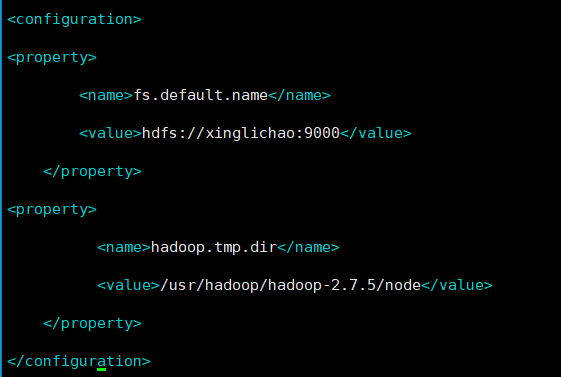
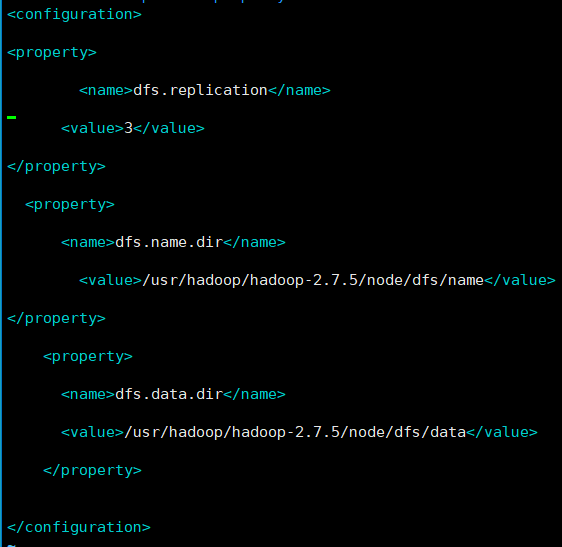
master中修改与hadoop-env.sh同文件夹下的修改hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/hadoop/hadoop-2.7.5/node/dfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/hadoop/hadoop-2.7.5/node/dfs/data</value> </property> </configuration>
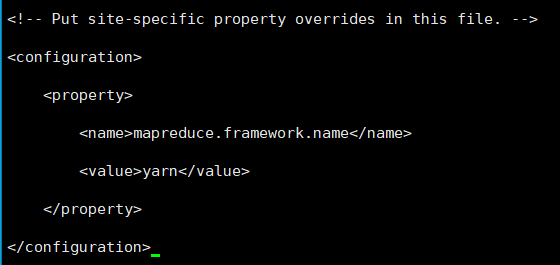
复制mapred-site.xml.template一份为mapred-site.xml,并修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
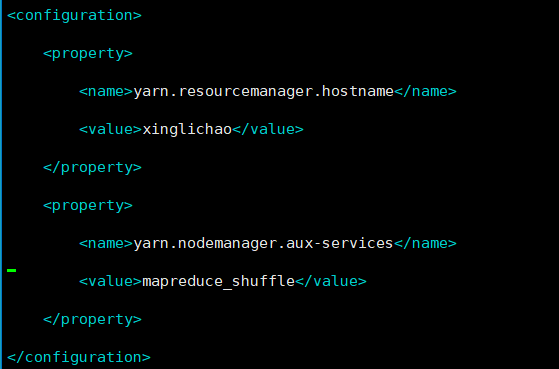
master中修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>xinglichao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
分发hadoop到其他slaves主机
scp -r /etc/hadoop/hadoop-2.7.5 root@****:/etc/hadoop/
在master上格式化文件系统
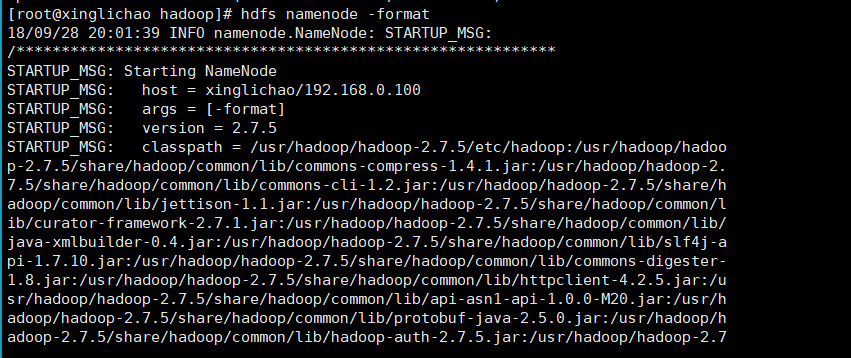
hdfs namenode -format
此时出现问题:找不到java
/usr/hadoop/hadoop-2.7.5/bin/hdfs:行304: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/bin/java: 没有那个文件或目录
再查看下java的安装路径
发现:原来是在上一路径下的jre文件夹下
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java
修改hadoop中hadoop-env.sh
在JAVA_HOME后添加 /jre (注:此处的路径与上面的不同,理由在下面)

另外:
当我执行 jps命令查看节点运行状态时发现jps不是内部命令,于是更新了java
yum install java-1.8.0-openjdk-devel.x86_64
上图的路径是已经配置了新版本的java路径后的文件
再次格式化文件系统:hdfs namenode -formate
jps一下,至此算是成功了

后续的使用就是创建工程文件夹,上传文件到HDFS,写MapReduce,执行代码(参考:hadoop单机伪分布式与真分布式系统下运行MR代码)
本节完......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号