[笔记]
#【python】避免变量与模块重名
在做时间序列分析的时,由于import time
在编码时又会遇到时间变量,于是就习惯性定义了time这个变量,此时如果再在变量后使用time模块(比如:time.time())
就会报time没有此方法之类的错误,此类问题还是需要注意下
解决办法:
1、注意变量名的定义
2、导入模块时可以import time as tm
#【python】一个py调用另一个py import模块的问题
有one.py 和 two.py two.py调用one.py中的函数:
在two.py 中impo one
如果one中直接定义了某方法func,可以直接使用 one.func进行调用
注意问题:
在one中import的模块,two无法直接使用
也就是说one中导入的模块已经“名花有主”,比如one中impo time,two中impot one 在two中使用(如time.time())
此时会报没有这个模块,原因是导入one时不会将one中导入的模块直接导入two中,two中要使用需要重新导入 或者 使用 one.time.time()
#【python / Mysql】将字符串写入Mysql时遇到含有 ' 的问题
在向Mysql中写入字符串时,遇到了含有 ‘ 写入失败的错误:
字符串的单引号又会作为字符串的截止符号从而使得sql语句产生错误
此时要将单引号转换为双引号 str.replace("'", "\"")
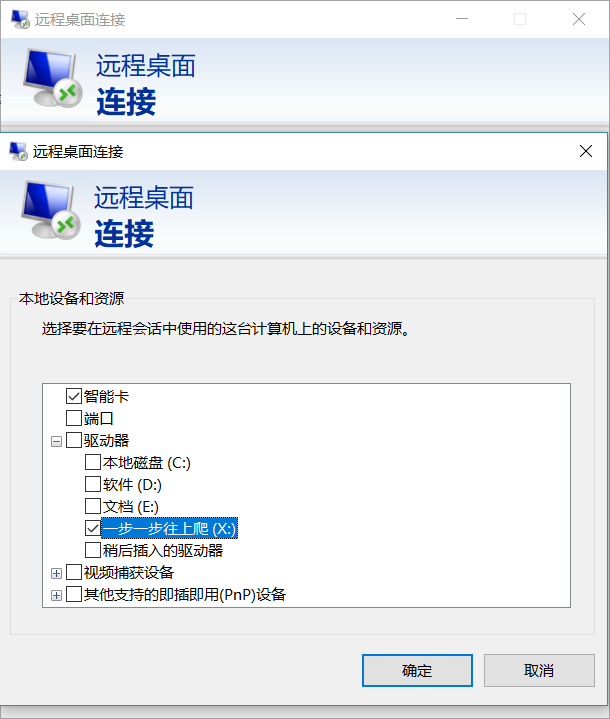
#【连接远程桌面】文件无法拖拽
登陆时设置共享盘
#【RAMA模型】报错:ValueError: Insufficient degrees of freedom to estimate

查看数据
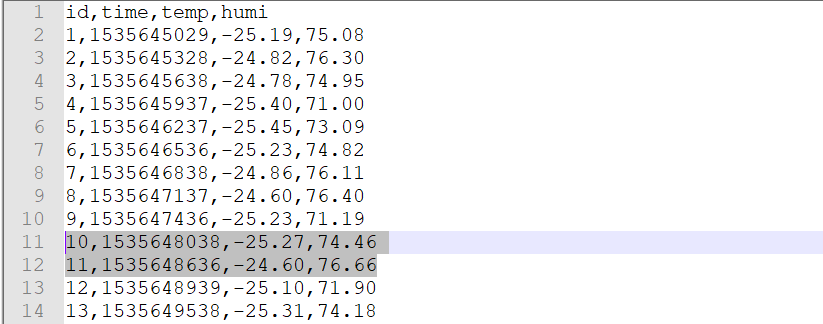
此错误的原因:RAMA模型应该需要足够的训练数据来拟合模型
经过实验:缺失值前至少要有16组训练数据
可以将预测方法加在try模块内
try:
result = predict_temp_humi(text, 300)
except:
result = ["insufficient training data before missing values"]
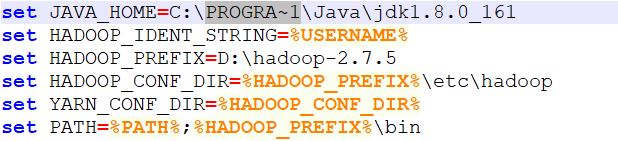
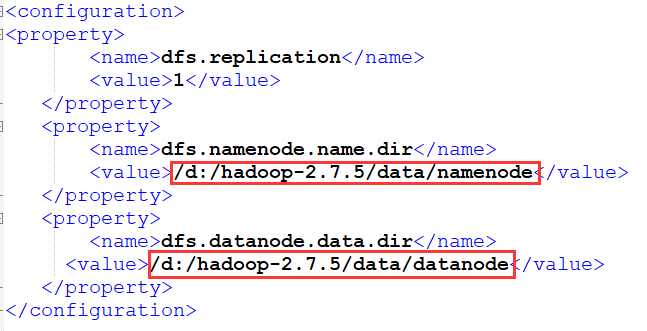
#【windows安装hadoop】出现Error: JAVA_HOME is incorrectly set. Please update D:\hadoop-2.7.5\conf\hadoop-env.cmd 错误

问题原因:Program Files中含有空格

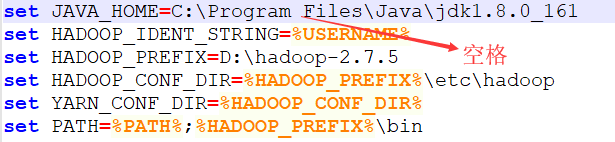
解决办法:PROGRA~1 代替 Program Files
#【eclipse4.8安装pydev】安装到中途失败
网上查阅资料,有说是可能被和谐了,还有就是版本对应问题
使用 http://www.pydev.org/updates 安装最新版失败
尝试使用 http://www.pydev.org/update_sites/4.5.5 安装旧版本,依旧失败
最后终于找到说明文档 http://www.pydev.org/download.html
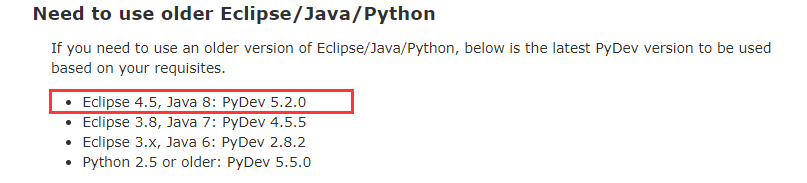
使用 http://www.pydev.org/update_sites/5.2.0 安装 果然成功了
#【hadoop启动Datanode】运行start-all.cmd发现启动Datanode失败
原因:多次格式化hdfs文件系统(hdfs namenode -format执行多次)
解决办法:删除hdfs-site.xml文件中配置的路径,重新执行hdfs namenode -format 仅一次
#【Centos下hadoop命令行运行jar包】卡在 [main] INFO org.apache.hadoop.mapreduce.Job - Running job: job_1539046307249_0010
[root@xinglichao hadoop]# hadoop jar wordcount.jar wordcount hdfs://xinglichao:9000/in hdfs://xinglichao:9000/ooout hdfs://xinglichao:9000/inhdfs://xinglichao:9000/ooout 18/10/11 19:50:37 INFO client.RMProxy: Connecting to ResourceManager at xinglichao/192.168.0.100:8032 0 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at xinglichao/192.168.0.100:8032 18/10/11 19:50:37 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 171 [main] WARN org.apache.hadoop.mapreduce.JobResourceUploader - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/10/11 19:50:37 INFO input.FileInputFormat: Total input paths to process : 1 364 [main] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 18/10/11 19:50:37 INFO mapreduce.JobSubmitter: number of splits:1 464 [main] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:1 18/10/11 19:50:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1539046307249_0010 588 [main] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1539046307249_0010 18/10/11 19:50:37 INFO impl.YarnClientImpl: Submitted application application_1539046307249_0010 678 [main] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1539046307249_0010 18/10/11 19:50:37 INFO mapreduce.Job: The url to track the job: http://xinglichao:8088/proxy/application_1539046307249_0010/ 696 [main] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://xinglichao:8088/proxy/application_1539046307249_0010/ 18/10/11 19:50:37 INFO mapreduce.Job: Running job: job_1539046307249_0010 697 [main] INFO org.apache.hadoop.mapreduce.Job - Running job: job_1539046307249_0010
日志
java.lang.Exception: Unknown container. Container either has not started or has already completed or doesn't belong to this node at all.

但是在eclipse下却可以成功执行
问题终于解决:
在子节点的一台机器的hosts文件中它自己的IP和主机名没有配置正确

这里配置的是101
而现在这台机器的IP已经变成了102(在搭建环境的过程中改变过网络连接,之前配置的hosts竟然忘记了修改)

注:分布式计算依赖与多台机器的通信,所以有好多问题可能都是由于什么ip呀hosts等网络配置不正确所导致的
而且由于是分布式,计算机不止一台,需要特别注意配置修改的同步更新,不然问题出现了真的很难找
#【RAMA模型】对于所有值相同的情况不适用
数据样式:

在构造模型时无法成功

尝试画此数据的时间序列的ACF与PACF图(这里想到偏自相关会出问题)
f = plt.figure(facecolor='white') ax1 = f.add_subplot(211) plot_acf(timeseries, lags=18, ax=ax1) ax2 = f.add_subplot(212) plot_pacf(timeseries, lags=18, ax=ax2) plt.show()
报错
Traceback (most recent call last): File "X:\eclipse\ramadebug\rama.py", line 139, in <module> result_only_lost, result, total_missed_value_num = predict("", det_time) File "X:\eclipse\ramadebug\rama.py", line 124, in predict result_only_lost, result, total_missed_value_num = predict_temp_humi(content, det_time) File "X:\eclipse\ramadebug\rama.py", line 106, in predict_temp_humi give_me_value(result_only_lost, result_list, time_list_seq, temp_list_seq, humi_list_seq, missed_value_num, det_time) File "X:\eclipse\ramadebug\rama.py", line 52, in give_me_value model_humi = proper_model(dta_humi, 9) File "X:\eclipse\ramadebug\rama.py", line 22, in proper_model plot_pacf(timeseries, lags=18, ax=ax2) File "D:\python36\lib\site-packages\statsmodels\graphics\tsaplots.py", line 223, in plot_pacf acf_x, confint = pacf(x, nlags=nlags, alpha=alpha, method=method) File "D:\python36\lib\site-packages\statsmodels\tsa\stattools.py", line 601, in pacf ret = pacf_yw(x, nlags=nlags, method='unbiased') File "D:\python36\lib\site-packages\statsmodels\tsa\stattools.py", line 520, in pacf_yw pacf.append(yule_walker(x, k, method=method)[0][-1]) File "D:\python36\lib\site-packages\statsmodels\regression\linear_model.py", line 1278, in yule_walker rho = np.linalg.solve(R, r[1:]) File "D:\python36\lib\site-packages\numpy\linalg\linalg.py", line 390, in solve r = gufunc(a, b, signature=signature, extobj=extobj) File "D:\python36\lib\site-packages\numpy\linalg\linalg.py", line 89, in _raise_linalgerror_singular raise LinAlgError("Singular matrix") numpy.linalg.linalg.LinAlgError: Singular matrix
问题的原因浮出水面:在模型构造是会构造矩阵,由于序列全为同一值,导致在中间过程中构造矩阵出现奇异矩阵(无法求逆等原因),构造模型时参数无法求解,失败
ps:话说回来,全部是一个值,还需要构造这样的复杂的模型来预测么
#【基于hadoop的spark环境】启动Worker失败
[root@xinglichao sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-xinglichao.out zhangpeng: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-*********.out zhangpeng: failed to launch: nice -n 0 /usr/spark/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 --port 7078 spark://xinglichao:7077 zhangpeng: at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:989) zhangpeng: at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:254) zhangpeng: at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:364) zhangpeng: at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:163) zhangpeng: at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:403) zhangpeng: at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:463) zhangpeng: at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858) zhangpeng: at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138) zhangpeng: at java.lang.Thread.run(Thread.java:748) zhangpeng: 2018-10-23 17:39:55 INFO ShutdownHookManager:54 - Shutdown hook called zhangpeng: full log in /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-*********.out
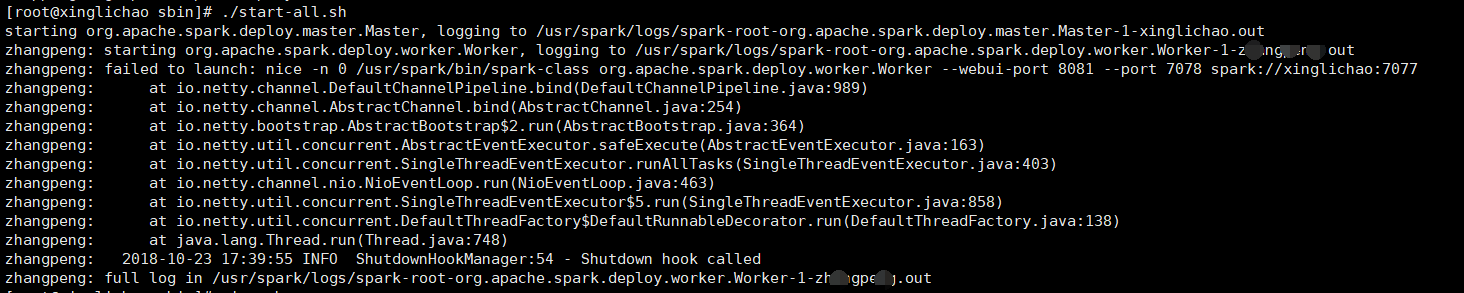
问题出现在Worker节点的hosts没有配置正确
(就是因为这个问题,我终于找到了前面的hadoop的问题)
#【eclipse中采用git插件上传项目到github】失败
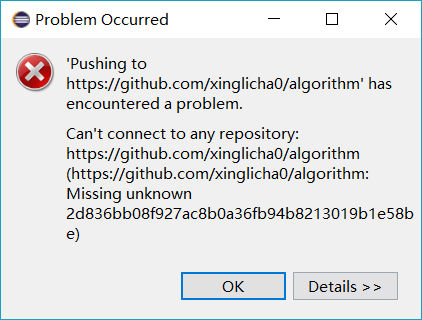
可能原因:
- 网络不好
- git服务器的问题
- git本地仓库创建存在异常
#【eclipse中使用Maven生成Jar包】需要jdk环境,jre会报错
[INFO] Scanning for projects... [INFO] [INFO] ---------------< com.helloworld.xlc:helloworld-app-xlc >---------------- [INFO] Building helloworld-app-xlc 0.0.1-SNAPSHOT [INFO] --------------------------------[ jar ]--------------------------------- [INFO] Downloading from : https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-jar-plugin/2.4/maven-jar-plugin-2.4.pom [INFO] Downloaded from : https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-jar-plugin/2.4/maven-jar-plugin-2.4.pom (5.8 kB at 4.5 kB/s) [INFO] Downloading from : https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-install-plugin/2.4/maven-install-plugin-2.4.pom [INFO] Downloaded from : https://repo.maven.apache.org/maven2/org/apache/maven/plugins/maven-install-plugin/2.4/maven-install-plugin-2.4.pom (6.4 kB at 16 kB/s) [INFO] [INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ helloworld-app-xlc --- [INFO] Using 'UTF-8' encoding to copy filtered resources. [INFO] skip non existing resourceDirectory X:\eclipseworkspace\maven\helloworld-app-xlc\src\main\resources [INFO] [INFO] --- maven-compiler-plugin:3.1:compile (default-compile) @ helloworld-app-xlc --- [INFO] Changes detected - recompiling the module! [INFO] Compiling 1 source file to X:\eclipseworkspace\maven\helloworld-app-xlc\target\classes [INFO] ------------------------------------------------------------- [ERROR] COMPILATION ERROR : [INFO] ------------------------------------------------------------- [ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK? [INFO] 1 error [INFO] ------------------------------------------------------------- [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 2.857 s [INFO] Finished at: 2018-10-25T17:16:43+08:00 [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project helloworld-app-xlc: Compilation failure [ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK? [ERROR] -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
解决办法:
下载并安装jdk https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
配置环境为JDK
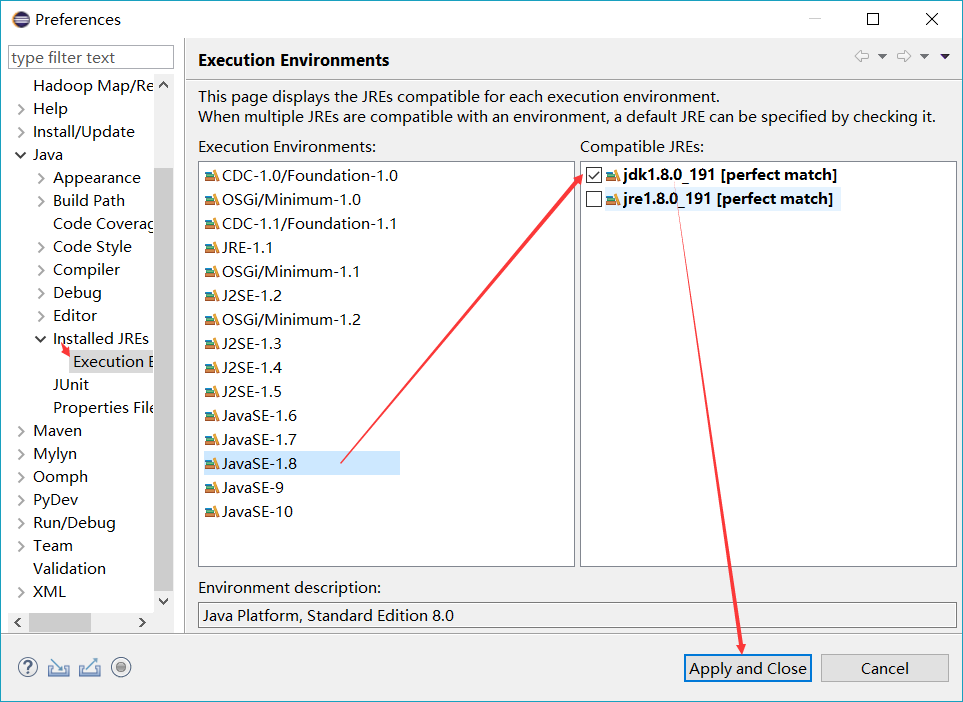
成功执行
#【Windows10安装mysql】版本8.0图形界面失败
在最后一步的时候出现

目前没找到原因
还想学习使用mysql,选择5.7ZIP版本,手动配置也比较简单 参考:https://www.cnblogs.com/xsmile/p/7753984.html
#【被Eclipse坑的好惨】正确修改项目内的配置文件后项目仍报之前的错误
使用hibernate连接数据库,并依据创建的多个类映射成多个表时,已经正确修改配置文件但仍然报之前的错误,比如
测试的时候我在hibernate.cfg.xml文件内注释掉了User,然后又恢复成取消注释的情况
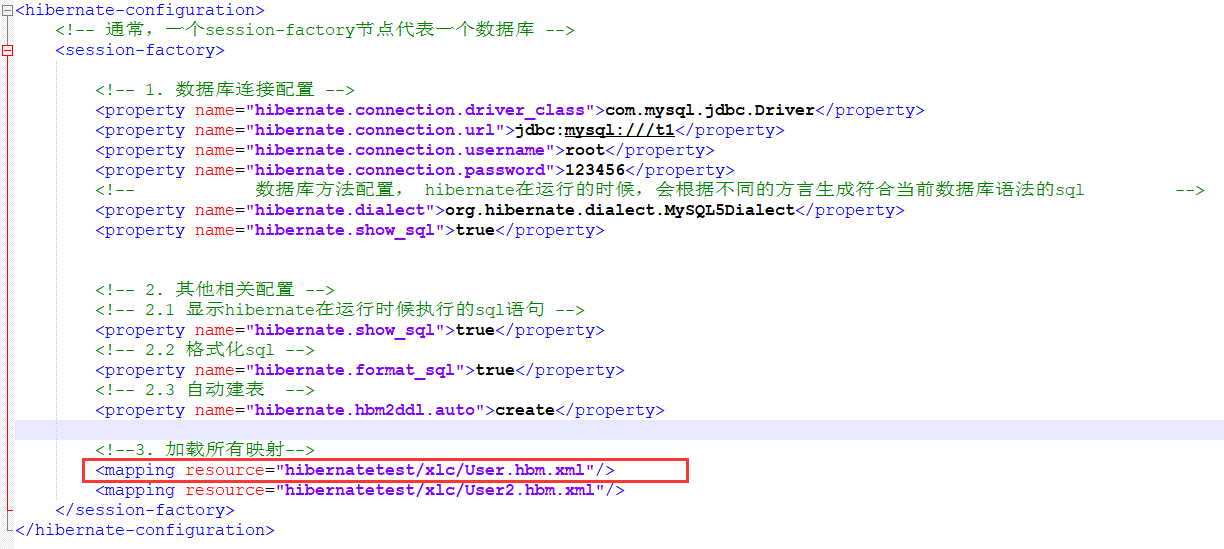
此时,在Eclipse中直接启动项目,很可能就还报错误,比如还会报找不到User

解决办法是在是又简单又暴力,直接刷新一下整个项目再次启动就OK了
启发:常刷新常保存常备份
#【低级错误】安装MySQL时配置my.ini文件存放位置错误
下载的免安装的MySQL时需要配置my.ini(没有需要新建一个)
当把它放在bin目录下后,依然可以启动MySQL,而且还高兴的做了实验,但是当我发现存入中文是乱码(一堆?)的时候找到原因说要配置编码

打开my.ini文件发现编码格式在安装的时候已经配置了,为什么没生效
原因:
my.ini应该存放在MySQL的根目录下
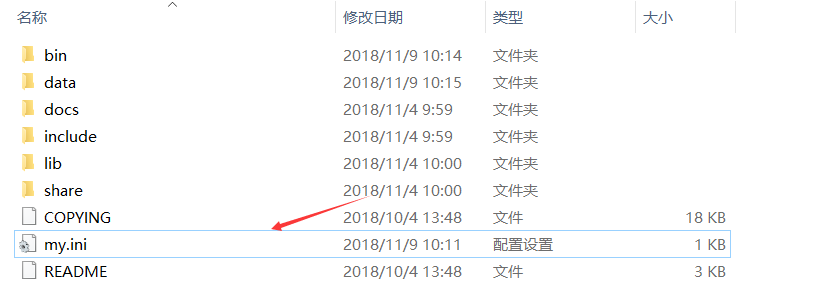
再附上前后查看的编码:
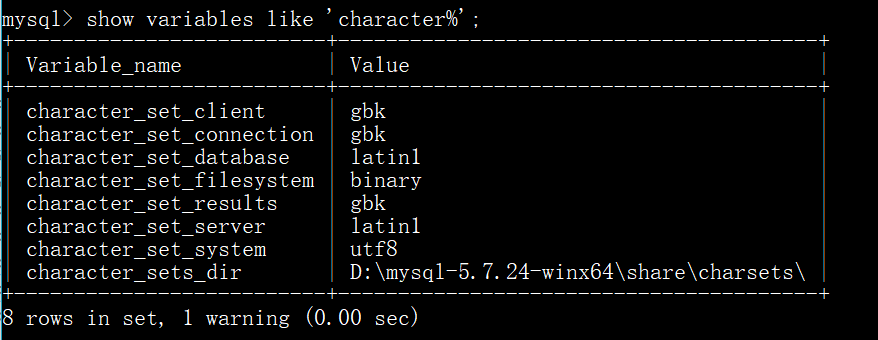

再次测试

#【SpringBoot】获取到List转json格式失败
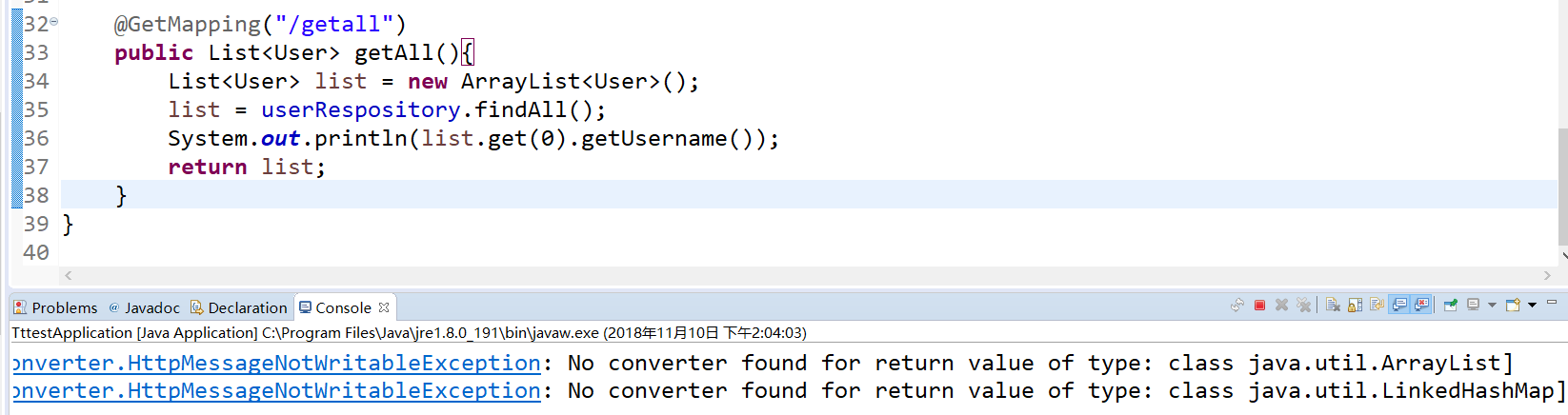
2018-11-10 14:22:38.116 WARN 7080 --- [nio-8080-exec-2] .w.s.m.s.DefaultHandlerExceptionResolver : Resolved [org.springframework.http.converter.HttpMessageNotWritableException: No converter found for return value of type: class java.util.ArrayList]
2018-11-10 14:22:38.132 WARN 7080 --- [nio-8080-exec-2] .w.s.m.s.DefaultHandlerExceptionResolver : Resolved [org.springframework.http.converter.HttpMessageNotWritableException: No converter found for return value of type: class java.util.LinkedHashMap]
仍没解决
#【Spring Boot】实例类中@Column大小写问题
@Column(name="labelSize") private int labelSize;
此时labelSize与label_size是对应的而不会忽略大小写创建字段labelsize
#【服务器配置网络】局域网内其他机器ping不通本机
排查问题办法:
1、本机ping网关,通
2、问题基本确定为路由问题
3、查看路由,发现存在虚拟网卡占用
4、删除不用的虚拟网卡
# virsh net-list#查看是否有连接相关虚拟设备
# virsh net-destroy default
# virsh net-undefine default
# systemctl restart libvirtd.service
#【Centos安装MySQL8】授权访问
进入mysql数据库内查看用户信息

此时允许访问的是本机localhost
使用
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
报错
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IDENTIFIED BY '密码' WITH GRANT OPTION' at line 1
还有直接这样
GRANT ALL ON *.* TO 'root'@'%';
报错
ERROR 1410 (42000): You are not allowed to create a user with GRANT
还有这样
alter user set user.host='%' where user.user='root';
报错
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'set user.host='%' where user.user='root'' at line 1
最后解决办法
update user set host='%' where user='root';

再
mysql> GRANT ALL ON *.* TO 'root'@'%'; Query OK, 0 rows affected (0.02 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.01 sec)
测试成功,在我的计算上使用Workbench连接到服务器的数据库,还测试了新建test库
#【Cnetos7中MySQL】修改datadir到指定路径出现错
过程:
首先停止MySQL服务
然后在/home下新建一个mysqldata的文件夹,将默认的 /var/lib/mysql拷贝到/home/mysqldata/
再修改mysqldata所属用户和用户组
chmod -R mysql:mysql /home/mysqldata
最后重启服务报错,查看日志大概意思是权限的问题
2018-11-22T09:35:23.743536Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details). 2018-11-22T09:35:23.744205Z 0 [Warning] Can't create test file /home/mysqldata/mysql/Server-003.lower-test 2018-11-22T09:35:23.744269Z 0 [Note] /usr/sbin/mysqld (mysqld 5.7.24) starting as process 65803 ... 2018-11-22T09:35:23.749696Z 0 [Warning] Can't create test file /home/mysqldata/mysql/Server-003.lower-test 2018-11-22T09:35:23.749739Z 0 [Warning] Can't create test file /home/mysqldata/mysql/Server-003.lower-test 2018-11-22T09:35:23.752117Z 0 [Note] InnoDB: PUNCH HOLE support available 2018-11-22T09:35:23.752171Z 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 2018-11-22T09:35:23.752180Z 0 [Note] InnoDB: Uses event mutexes 2018-11-22T09:35:23.752188Z 0 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier 2018-11-22T09:35:23.752196Z 0 [Note] InnoDB: Compressed tables use zlib 1.2.11 2018-11-22T09:35:23.752207Z 0 [Note] InnoDB: Using Linux native AIO 2018-11-22T09:35:23.752679Z 0 [Note] InnoDB: Number of pools: 1 2018-11-22T09:35:23.752858Z 0 [Note] InnoDB: Using CPU crc32 instructions 2018-11-22T09:35:23.755786Z 0 [Note] InnoDB: Initializing buffer pool, total size = 128M, instances = 1, chunk size = 128M 2018-11-22T09:35:23.774206Z 0 [Note] InnoDB: Completed initialization of buffer pool 2018-11-22T09:35:23.777251Z 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority(). 2018-11-22T09:35:23.789532Z 0 [Note] InnoDB: Highest supported file format is Barracuda. 2018-11-22T09:35:23.798894Z 0 [Note] InnoDB: Creating shared tablespace for temporary tables 2018-11-22T09:35:23.798989Z 0 [ERROR] InnoDB: Operating system error number 13 in a file operation. 2018-11-22T09:35:23.799001Z 0 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory. 2018-11-22T09:35:23.799011Z 0 [ERROR] InnoDB: Operating system error number 13 in a file operation. 2018-11-22T09:35:23.799020Z 0 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory. 2018-11-22T09:35:23.799032Z 0 [ERROR] InnoDB: Cannot open datafile './ibtmp1' 2018-11-22T09:35:23.799042Z 0 [ERROR] InnoDB: Unable to create the shared innodb_temporary 2018-11-22T09:35:23.799057Z 0 [ERROR] InnoDB: Plugin initialization aborted with error Cannot open a file 2018-11-22T09:35:24.400949Z 0 [ERROR] Plugin 'InnoDB' init function returned error. 2018-11-22T09:35:24.400994Z 0 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed. 2018-11-22T09:35:24.401011Z 0 [ERROR] Failed to initialize builtin plugins. 2018-11-22T09:35:24.401025Z 0 [ERROR] Aborting
尝试网上众多方法,未解决
屈服,后续准备拆卸此安装,编译源码来将其安装到指定路径
#【桌面版centos桌面卡住】
进入shell使用命令
killall -9 gnome-shell
#【安装好hadoop与zookeeper再安装kafka】启动时报异常
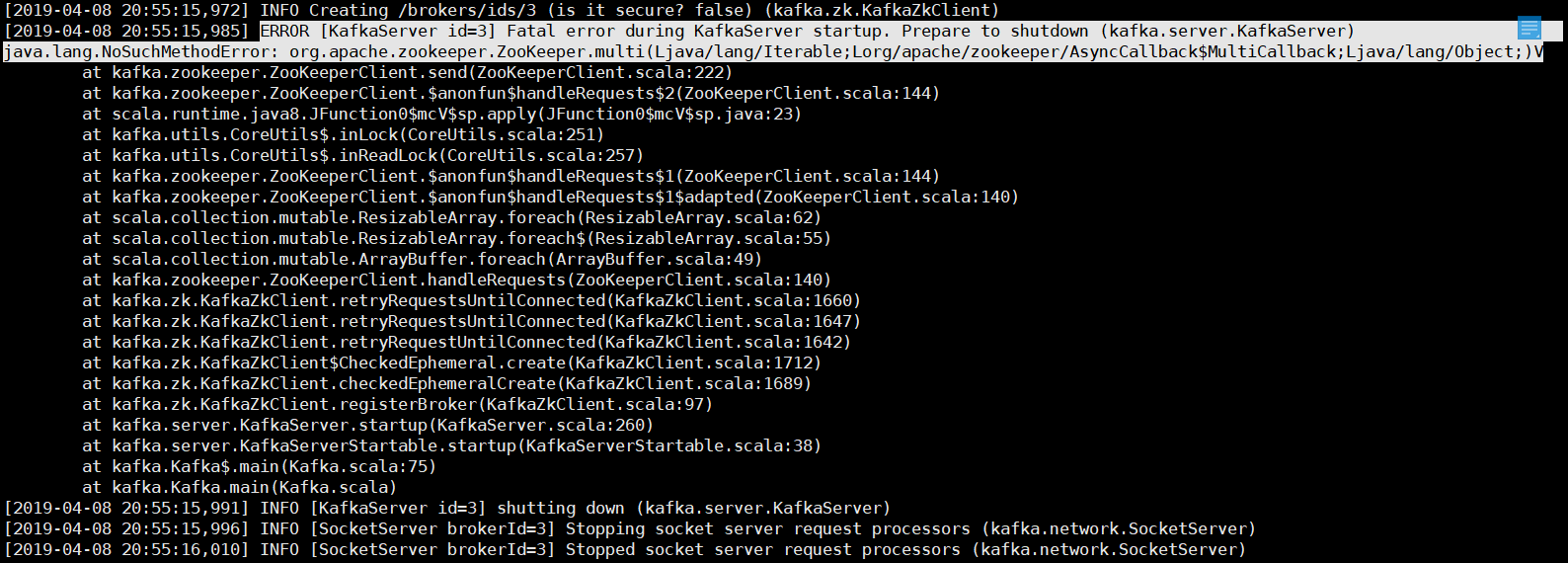
发现是NoSuchMethodError错误,找到上面输出的CLASSPATH,看到了好多hadoop的jar包路径,于是怀疑是jar包冲突
之所以在这里会有hadoop的classpath原因是我为了可以编译hadoop的MapReduce的代码,将hadoop的jar包配置在 etc/profile文件内
导致kafka根据系统配置文件找到了hadoop的lib目录,于是当zookeeper内的jar包和hadoop的jar名相同时,发生了冲突,从而导致此问题
解决办法:
将/etc/profile下的export的hadoop的classpath删除掉,此时kafka就可以正常启动
那么我还要再编译hadoop的MapReduce怎么办呢,我的解决方案是新建一个hadoop用户,将删除的classpath配置在此用户的~/bashrc文件下
然后在就可以在hadoop用户下编译打包,在root下使用上传运行
#【】
#【】
#【】
#【】
#【】
#【】
#【】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号