自然语言处理---用隐马尔科夫模型(HMM)实现词性标注---1998年1月份人民日报语料---learn---test---evaluation---Demo---java实现
先放上一张Demo的测试图
- 测试的句子及每个分词的词性标注为: 目前/t 这/rzv 条/q 高速公路/n 之间/f 的/ude1 路段/n 已/d 紧急/a 封闭/v 。/w

需要基础知识
- HMM模型(隐马尔可夫模型)
- 模型的定义
隐马尔科夫模型(hidden Markov model)是关于时序的概率模型,是最简单的动态贝叶斯网络
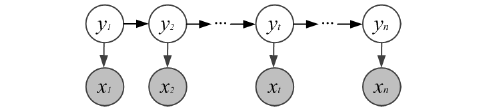

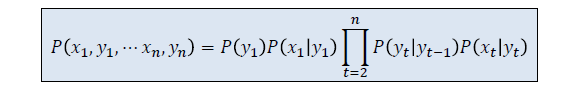
- 模型的参数
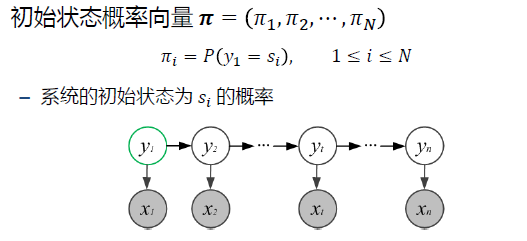
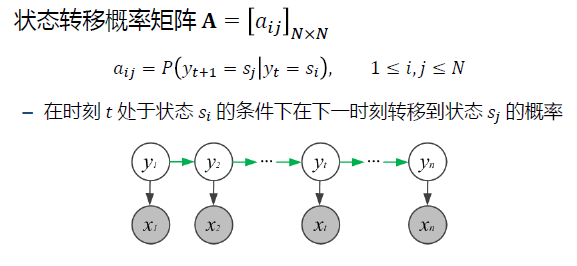
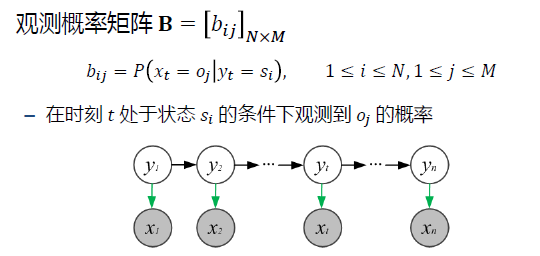
HMM模型由Pi、A、B 唯一决定 Pi、A、B 成为HMM模型的三要素
- HMM用在词性标注问题
- 对于下面这句话可以用HMM进行建模
目前/t 这/rzv 条/q 高速公路/n 之间/f 的/ude1 路段/n 已/d 紧急/a 封闭/v 。/w
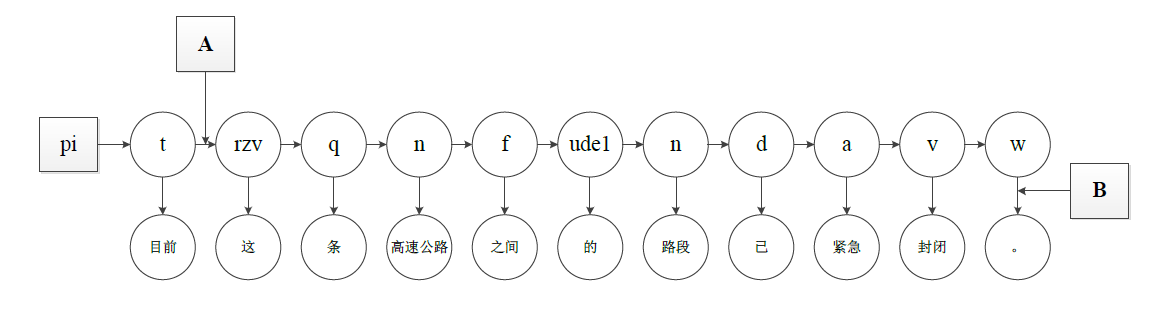
因此 可以通过训练语料来根据词性以及分词还有两者之间的关系进行统计获得三种概率
- 维特比算法
- 在给定已知分词的句子时如何进行词性标注呢
这就是HMM模型中的预测问题

此时采用维特比算法

注:对维特比算法的举例理解
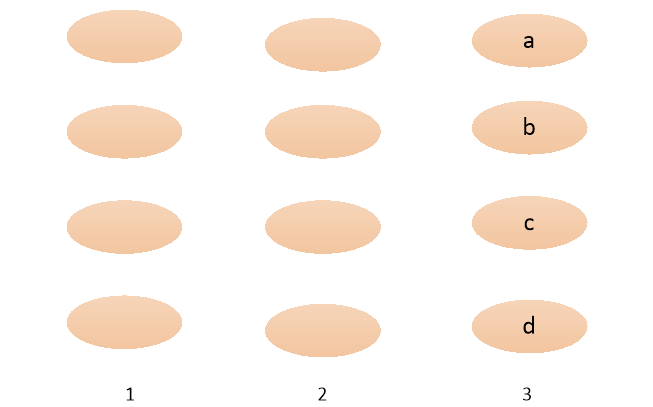
a b c d 表示的是四种状态
1 2 3 是三个观测时间节点
在t=3的时刻要计算到达此时的4种状态的所有路径,例如,到达a状态的有从t=1,t=2的4*4=16种情况,要找到概率最大的一条路径记录下来;对于其他的状态点也是这样计算下去保存最优路径。
算法中步骤3中的式子表示两个时刻的距离,每次记录的是根据之间的概率最大记住前一时刻的某一状态。
整个工程的流程
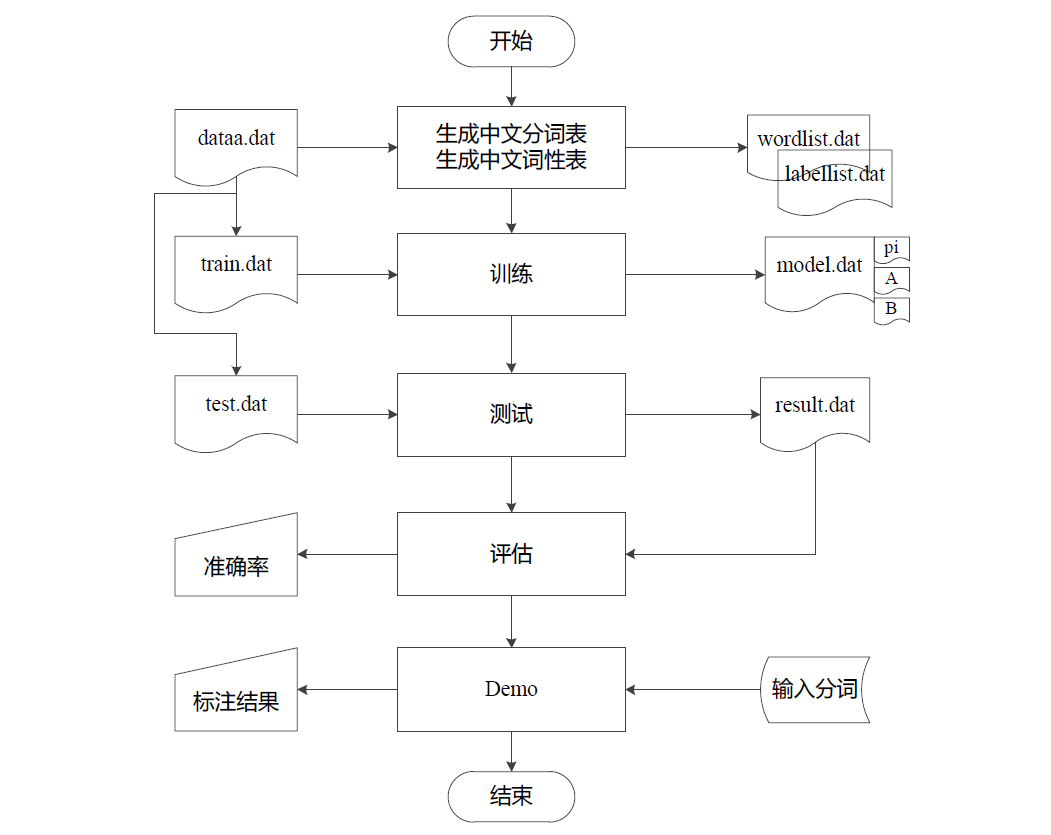
详细内容(含源代码)
- 语料情况

- 语料划分
取前面约80%作为train语料 后面约20%作为测试语料
- 创建分词表和中文词性表
public class DoIt { List<String> wordlist; List<String> labellist; public DoIt() { wordlist = new ArrayList<String>(); labellist = new ArrayList<String>(); } public int[] creatlist(String train) throws IOException{ System.out.println("----- 创建List -----"); System.out.println(".......... . . ."); File file = new File(train); int[] twonum = new int[2]; if(!file.exists()) { throw new IOException(file + "不存在!!!"); } if(!file.isFile()) { throw new IOException(file + "不是文件!!!"); } BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(file))); String str = null; while((str = br.readLine()) != null) { String[] strarray = str.split(" "); for (String substr: strarray) { String[] tempstr = substr.split("/"); if (tempstr.length == 2) { String word = tempstr[0]; String label = tempstr[1]; if(!wordlist.contains(word)) { wordlist.add(word); } if(!labellist.contains(label)) { labellist.add(label); } } } } br.close(); twonum[0] = wordlist.size(); twonum[1] = labellist.size(); listtodocument(labellist, "labellist.dat"); //写文件 listtodocument(wordlist, "wordlist.dat"); System.out.println("----- 创建List完成 -----"); return twonum; } //list 写到 文件 public void listtodocument(List<String> list, String filename) throws IOException{ PrintWriter pw = new PrintWriter(filename); for (String string: list) { pw.print(string + " "); } pw.flush(); pw.close(); } }
- 训练 得到模型的关键三个关键参数
public class DoIt { List<String> wordlist; List<String> labellist; public DoIt() { wordlist = new ArrayList<String>(); labellist = new ArrayList<String>(); } public void learn(String train, String model, int[] twonum) throws IOException{ System.out.println("----- 开始训练 -----"); //System.out.println(twonum[0] +"---------" + twonum[1]); int wordnum = twonum[0]; int labelnum = twonum[1]; double[] pi = new double[labelnum]; double[][] A = new double[labelnum][labelnum]; double[][] B = new double[labelnum][wordnum]; for (int i = 0; i < labelnum; i++) { pi[i] = 1; for (int j = 0; j < labelnum; j++) { A[i][j] = 1; } for (int k = 0; k < wordnum; k++) { B[i][k] = 1; } } File file = new File(train); if(!file.exists()) { throw new IOException(file + "不存在!!!"); } if(!file.isFile()) { throw new IOException(file + "不是文件!!!"); } BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(file))); PrintWriter pw = new PrintWriter(model); String str = null; int frontindex = -1; int rowpi = 0; while((str = br.readLine()) != null) { rowpi ++; System.out.println("--learn读取到文件的行号: " + rowpi); String[] strarray = str.split(" "); for (String substr: strarray) { String[] tempstr = substr.split("/"); if (tempstr.length == 2) { String word = tempstr[0]; String label = tempstr[1]; int wordindex = wordlist.indexOf(word); int labelindex = labellist.indexOf(label); B[labelindex][wordindex] += 1; if (frontindex != -1) { A[frontindex][labelindex] += 1; } frontindex = labelindex; } } String firstlabel = strarray[0].split("/")[1]; int firstlabelindex = labellist.indexOf(firstlabel); // System.out.println(firstlabel); pi[firstlabelindex] += 1; } System.out.println("----- 写参数到model -----"); //计算概率 写入model文件 int factor = 1000; pw.println(3); pw.println(4); pw.println(labelnum + 4); for (int i = 0; i < labelnum; i++) { pw.print(factor * pi[i] / rowpi + " "); } pw.println(); double rowsumA = 0; //pw.println("A"); for (int i = 0; i < labelnum; i++) { for (int j = 0; j < labelnum; j++) { rowsumA += A[i][j]; } for (int j = 0; j < labelnum; j++) { pw.print(factor * A[i][j] / rowsumA + " "); } rowsumA = 0; pw.println(); } double rowsumB = 0; //pw.println("B"); for (int i = 0; i < labelnum; i++) { for (int k = 0; k < wordnum; k++) { rowsumB += B[i][k]; } for (int k = 0; k < wordnum; k++) { pw.print(factor * B[i][k] / rowsumB + " "); } rowsumB = 0; pw.println(); } pw.flush(); br.close(); pw.close(); System.out.println("--- 文件写入完毕 训练完成 ---"); } //训练 写 参数 到model文件中 public void tomodel(String allfile, String train, String model) throws IOException{ //int[] twonum = creatlist(train); int[] twonum = creatlist(allfile); learn(train, model, twonum); } //训练的入口 public void pleaselearn(String filename) throws IOException{ double start = System.currentTimeMillis(); String train = filename; String model = "model.dat"; String allfile = "dataa.dat"; tomodel(allfile, train, model); double end = System.currentTimeMillis(); System.out.println("训练用时(s): " + (end - start) / 1000); } }
- 测试 读入模型的参数和测试文本进行译码操作 并将结果与源测试文件的内容以行为单位写入结果
public class tDoIt { List<String> wordlist; List<String> labellist; public tDoIt() { wordlist = new ArrayList<String>(); labellist = new ArrayList<String>(); } //进行测试 public void test(String model, String test, String result) throws IOException{ System.out.println("----- 开始测试 -----"); String[] wordd = readdocument("wordlist.dat"); for (String stri: wordd) { wordlist.add(stri); } String[] label = readdocument("labellist.dat"); for (String strii: label) { labellist.add(strii); } File filemodel = new File(model); File filetest = new File(test); if(!filemodel.exists()) { throw new IOException(filemodel + "不存在!!!"); } if(!filemodel.isFile()) { throw new IOException(filemodel + "不是文件!!!"); } if(!filetest.exists()) { throw new IOException(filetest + "不存在!!!"); } if(!filetest.isFile()) { throw new IOException(filetest + "不是文件!!!"); } BufferedReader brmodel = new BufferedReader( new InputStreamReader( new FileInputStream(filemodel))); BufferedReader brtest = new BufferedReader( new InputStreamReader( new FileInputStream(filetest))); String[] rowpi = null; String[] rowA = null; String[] rowB = null; String strmodel = null; int rownumpi = tempreadfile(filemodel)[0]; int rownumA = tempreadfile(filemodel)[1]; int rownumB = tempreadfile(filemodel)[2]; double[] pi = new double[rownumB - rownumA]; double[][] A = new double[rownumB - rownumA][]; double[][] B = new double[rownumB - rownumA][]; int j = 0, k = 0; for (int i = 0; (strmodel = brmodel.readLine()) != null; i++) { if(i >= rownumpi && i < rownumA) { rowpi = strmodel.split(" "); pi = strtodouble(rowpi); }else if (i >= rownumA && i < rownumB) { rowA = strmodel.split(" "); A[j++] = strtodouble(rowA); }else if(i >= rownumB){ rowB = strmodel.split(" "); B[k++] = strtodouble(rowB); } } StringBuilder strbd; PrintWriter pw = new PrintWriter(result); String teststr = null; int row = 1; while((teststr = brtest.readLine()) != null) { pw.println(teststr); System.out.println("--test读取到文件的行号: " + row++); String[] strarray = teststr.split(" "); strbd = new StringBuilder(); for (String substr: strarray) { String[] tempstr = substr.split("/"); if (tempstr.length == 2) { String word = tempstr[0]; strbd.append(word + " "); } } int[] labelindex = viterbi(strbd.toString(), pi, A, B); String[] strwords = strbd.toString().split(" "); for (int i = 0; i < labelindex.length; i++) { pw.print(strwords[i] + "/" + labellist.get(labelindex[i]) + " "); } pw.println(); } pw.flush(); brmodel.close(); brtest.close(); pw.close(); } // viterbi public int[] viterbi(String string, double[] pi, double[][] A, double[][] B) throws IOException{ String[] words = string.split(" "); double[][] delta = new double[words.length][pi.length]; int[][] way = new int[words.length][pi.length]; int[] labelindex = new int[words.length]; for (int i = 0; i < pi.length; i++) { delta[0][i] = pi[i] * B[i][wordlist.indexOf(words[0])]; } for (int t = 1; t < words.length; t++) { for (int i = 0; i < pi.length; i++) { for (int j = 0; j < pi.length; j++) { if(delta[t][i] < delta[t-1][j] * A[j][i] * B[i][wordlist.indexOf(words[t])]) { delta[t][i] = delta[t-1][j] * A[j][i] * B[i][wordlist.indexOf(words[t])]; way[t][i] = j; } } } } double max = delta[words.length - 1][0]; labelindex[words.length - 1] = 0; for (int i = 0; i < pi.length; i++) { if (delta[words.length - 1][i] > max) { max = delta[words.length - 1][i]; labelindex[words.length - 1] = i; } } for (int t = words.length - 2; t >= 0; t--) { labelindex[t] = way[t + 1][labelindex[t + 1]]; } return labelindex; } // 读文件到数组 public String[] readdocument(String filename) throws IOException{ BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(filename))); String[] strarray = br.readLine().split(" "); br.close(); return strarray; } //读取文件前的三个参数 public int[] tempreadfile(File file) throws IOException { int[] threenum = new int[3]; BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(file))); int i = 0; String str; while((str = br.readLine()) != null) { if(i > 2) { break; } threenum[i++] = Integer.parseInt(str); } br.close(); return threenum; } //转String 为 double类型 public double[] strtodouble(String[] strarray) { double[] dbs = new double[strarray.length]; for (int i = 0; i < strarray.length; i++) { dbs[i] = Double.valueOf(strarray[i]); } return dbs; } //测试的入口 public void pleasetest(String filename, String resultname) throws IOException{ double start = System.currentTimeMillis(); String test = filename; String model = "model.dat"; String result = resultname; test(model, test, result); double end = System.currentTimeMillis(); System.out.println("测试用时(min): " + (end - start) / 1000 / 60); } }
- 得到result.dat文件 格式如下
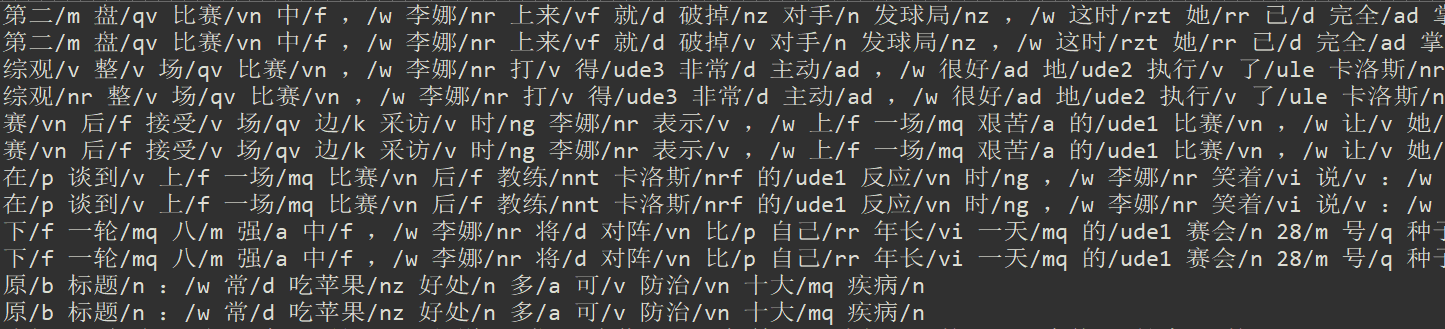
- 进行评估 读入结果文件 统计 分词个数与正确标注的分词个数 求解准确率 输出结果
public class eDoIt { public void evaluation(String filename) throws IOException{ File file = new File(filename); if (!file.exists()) { throw new IOException(file + "不存在!!!"); } if (!file.isFile()) { throw new IOException(file + "不是文件"); } BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(file))); int sum = 0; int correct = 0; String str; String[] strarray; int flag = -1; int k = 1; while(true) { str = null; strarray = new String[2]; for (int i = 0; i < 2; i++) { str = br.readLine(); if (str != null) { strarray[i] = str; }else { flag = 1; break; } } if (flag > 0) break; String[] temp1 = strarray[1].split(" "); String[] temp2 = strarray[0].split(" "); for (int i = 0; i < temp1.length; i++) { if (temp1[i].split("/").length == 2 && temp2[i].split("/").length == 2){ sum++; String[] str1 = temp1[i].split("/"); String[] str2 = temp2[i].split("/"); if (str1[1].equals(str2[1])) { correct++; } } } } double accuracy = 100.0 * correct / sum; System.out.println("总单词的个数:" + sum + "\n正确标注的单词个数:" + correct); System.out.println("准确率为:" + accuracy + "%"); br.close(); } }
- 评估结果如下

- 采用训练好的模型参数写一个进行词性标注的交互Demo
public class dDoIt { List<String> wordlist; List<String> labellist; public dDoIt() { wordlist = new ArrayList<String>(); labellist = new ArrayList<String>(); } //进行decode public void decode(String model) throws Exception{ Scanner console; System.out.println("[MADE BY XINGLICHAO]"); System.out.println("词性标注系统加载中..."); System.out.println("------------------------------------"); String[] wordd = readdocument("wordlist.dat"); for (String stri: wordd) { wordlist.add(stri); } String[] label = readdocument("labellist.dat"); for (String strii: label) { labellist.add(strii); } File filemodel = new File(model); if(!filemodel.exists()) { throw new IOException(filemodel + "不存在!!!"); } if(!filemodel.isFile()) { throw new IOException(filemodel + "不是文件!!!"); } BufferedReader brmodel = new BufferedReader( new InputStreamReader( new FileInputStream(filemodel))); String[] rowpi = null; String[] rowA = null; String[] rowB = null; String strmodel = null; int rownumpi = tempreadfile(filemodel)[0]; int rownumA = tempreadfile(filemodel)[1]; int rownumB = tempreadfile(filemodel)[2]; double[] pi = new double[rownumB - rownumA]; double[][] A = new double[rownumB - rownumA][]; double[][] B = new double[rownumB - rownumA][]; int j = 0, k = 0; for (int i = 0; (strmodel = brmodel.readLine()) != null; i++) { if(i >= rownumpi && i < rownumA) { rowpi = strmodel.split(" "); pi = strtodouble(rowpi); }else if (i >= rownumA && i < rownumB) { rowA = strmodel.split(" "); A[j++] = strtodouble(rowA); }else if(i >= rownumB){ rowB = strmodel.split(" "); B[k++] = strtodouble(rowB); } } while(true) { System.out.println("依次输入句子的各个分词并以空格分离:"); System.out.println("[结束使用 请按 0 ]"); System.out.println("------------------------------------"); console = new Scanner(System.in); try { String str = console.nextLine(); if (str.equals("0")) { brmodel.close(); console.close(); System.out.println(); System.out.println("应用结束..."); System.exit(0); } long start = System.currentTimeMillis(); int[] labelindex = viterbi(str, pi, A, B); String[] strwords = str.split(" "); System.out.println(); System.out.println("------------------------------------"); System.out.println("标注结果:"); for (int i = 0; i < labelindex.length; i++) { System.out.print(strwords[i] + "/" + labellist.get(labelindex[i]) + " "); } System.out.println(); long end = System.currentTimeMillis(); System.out.println("\n[本次标注用时 " + (end-start) + " ms]"); System.out.println("------------------------------------"); }catch(Exception e) { System.out.println("\n你的分词超出了我的能力范围!!"); System.out.println("------------------------------------"); } } } // viterbi public int[] viterbi(String string, double[] pi, double[][] A, double[][] B) throws IOException{ String[] words = string.split(" "); double[][] delta = new double[words.length][pi.length]; int[][] way = new int[words.length][pi.length]; int[] labelindex = new int[words.length]; for (int i = 0; i < pi.length; i++) { delta[0][i] = pi[i] * B[i][wordlist.indexOf(words[0])]; } for (int t = 1; t < words.length; t++) { for (int i = 0; i < pi.length; i++) { for (int j = 0; j < pi.length; j++) { if(delta[t][i] < delta[t-1][j] * A[j][i] * B[i][wordlist.indexOf(words[t])]) { delta[t][i] = delta[t-1][j] * A[j][i] * B[i][wordlist.indexOf(words[t])]; way[t][i] = j; } } } } double max = delta[words.length - 1][0]; labelindex[words.length - 1] = 0; for (int i = 0; i < pi.length; i++) { if (delta[words.length - 1][i] > max) { max = delta[words.length - 1][i]; labelindex[words.length - 1] = i; } } for (int t = words.length - 2; t >= 0; t--) { labelindex[t] = way[t + 1][labelindex[t + 1]]; } return labelindex; } // 读文件到数组 public String[] readdocument(String filename) throws IOException{ BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(filename))); String[] strarray = br.readLine().split(" "); br.close(); return strarray; } //读取文件前的三个参数 public int[] tempreadfile(File file) throws IOException { int[] threenum = new int[3]; BufferedReader br = new BufferedReader( new InputStreamReader( new FileInputStream(file))); int i = 0; String str; while((str = br.readLine()) != null) { if(i > 2) { break; } threenum[i++] = Integer.parseInt(str); } br.close(); return threenum; } //转String 为 double类型 public double[] strtodouble(String[] strarray) { double[] dbs = new double[strarray.length]; for (int i = 0; i < strarray.length; i++) { dbs[i] = Double.valueOf(strarray[i]); } return dbs; } }
- 续..........
在进行test时 标注的速度慢 由于数据较大 一次进行读取测试 时间花费太长 所以 想到将文件按行切分成多个文件 分别进行测试 最后 再将得到的结果小文件 整合成一个大文件用于评估
按行切分文件 与 合并文件 点这里
Github:https://github.com/xinglicha0/Chinese-word-tagging-system-based-on-Hmm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号