Coursera机器学习week4 笔记
Neural Networks: Representation
Non-linear hypotheses
我们之前学到的,无论是线性回归还是逻辑回归都有一个缺点,当特征太多时,计算负荷会非常的大。
如下:
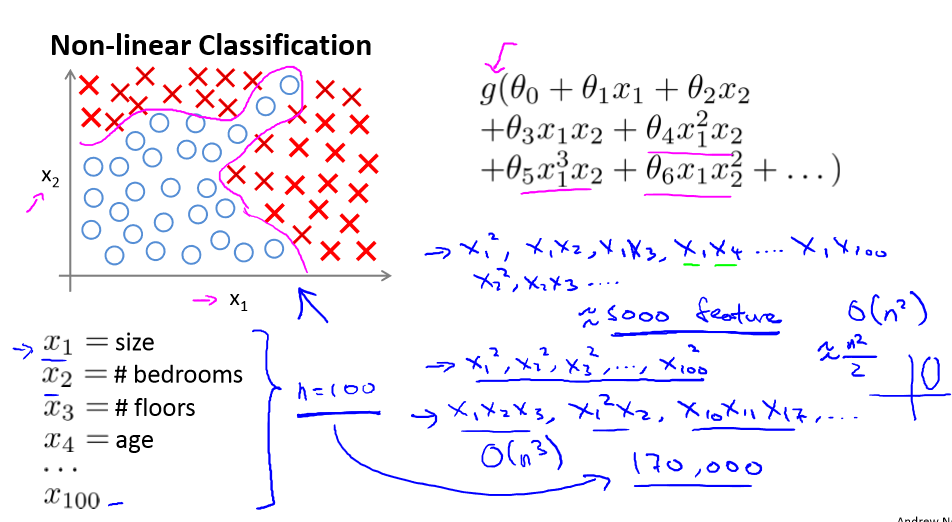
只有x1和x2,但运用多次项进行预测时,我们的方程可以很好的预测。使用非线性的多项式能够帮助我们建立更好的分类模型。
例如我们有很多的特征,100个变量,用这100个特征构建一个非线性的多项式模型,结果将是非常大的特征组合,即使我们只才有两两特征的组合(x1x2+x1x3+x1x4+...+x2x3+x2x4+...x99x100),也会有解决5000个组合而成的特征,对于一般的逻辑回归特征是太多了。
例如:
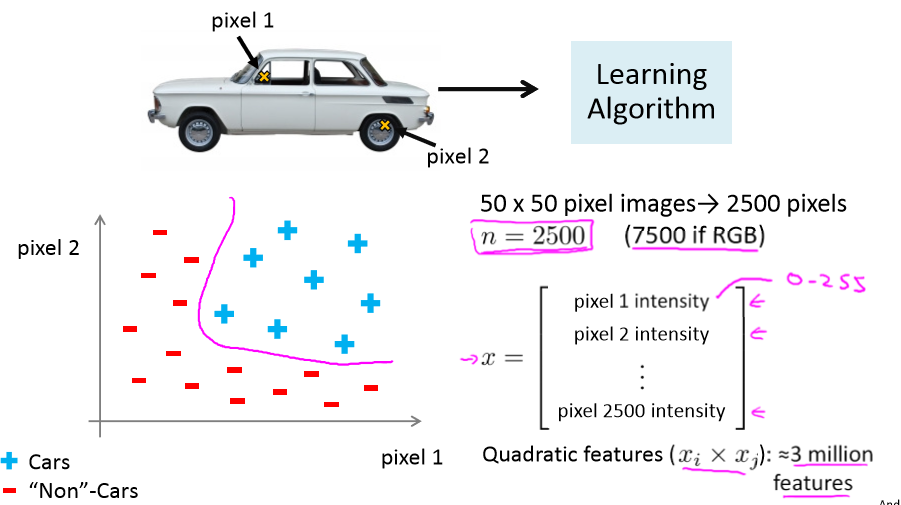
一张图片,即使是50*50的图片,也有解决2500个特征,如果进行两两特征组合构成一个多项式模型,就约有25002/2的特征组合(接近3百万个),在大一点的图片特征就更多了,计算负荷会非常的大。
Neurons and the brain

神经网络兴起于二十世纪八九十年代,应用得非常广泛,但由于各种原因,在90年代的后期应用逐渐减少。最近,神经网络又东山再起了。
其中一个原因是神经网络是计算量偏大的算法,而现在计算机的运行速度变快很多,才足以真正运行起大规模的神经网络。
例如我们的听觉和视觉:
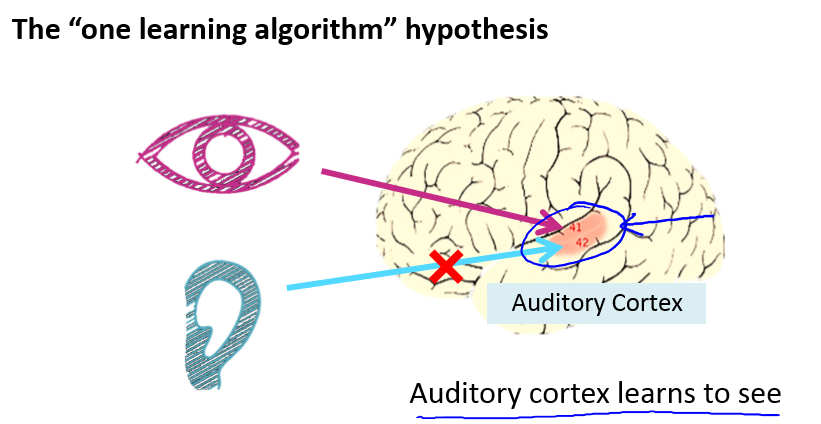
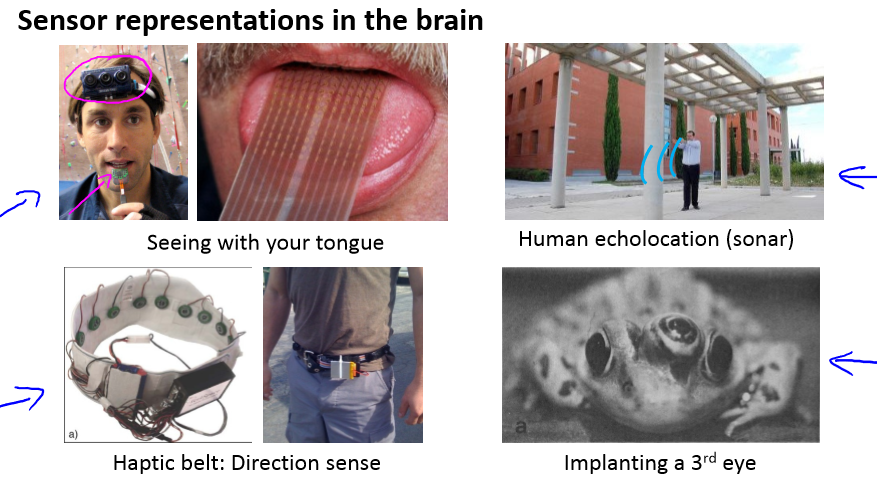
还有各种各样的例子:
Model representation I
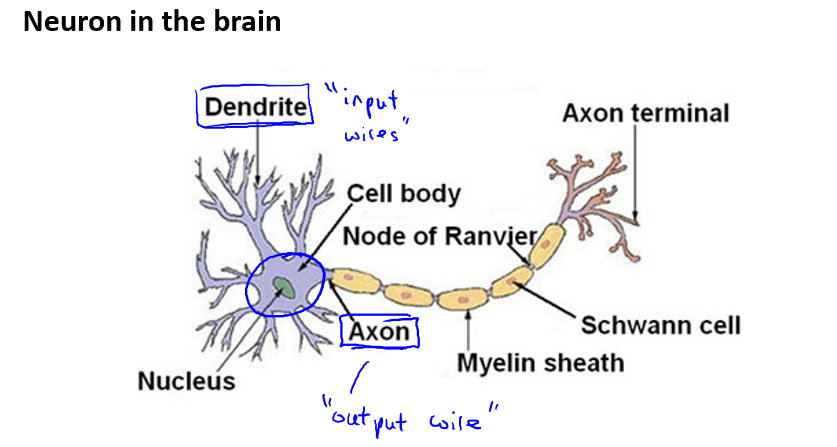
在人的大脑中,每一个神经元都可以被认为是一个处理单元/神经核(processing unit/ Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)
神经网络是大量神经元相互连接并通过电脉来交流的一个网络。
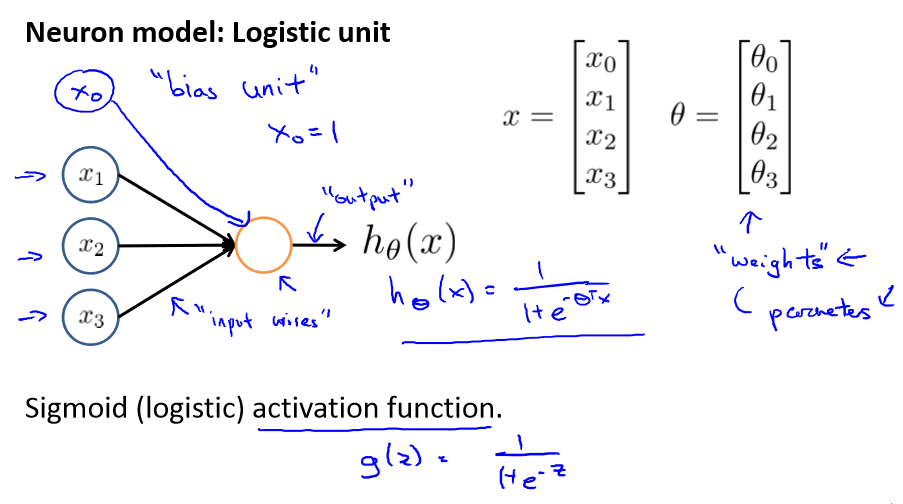
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输
出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。
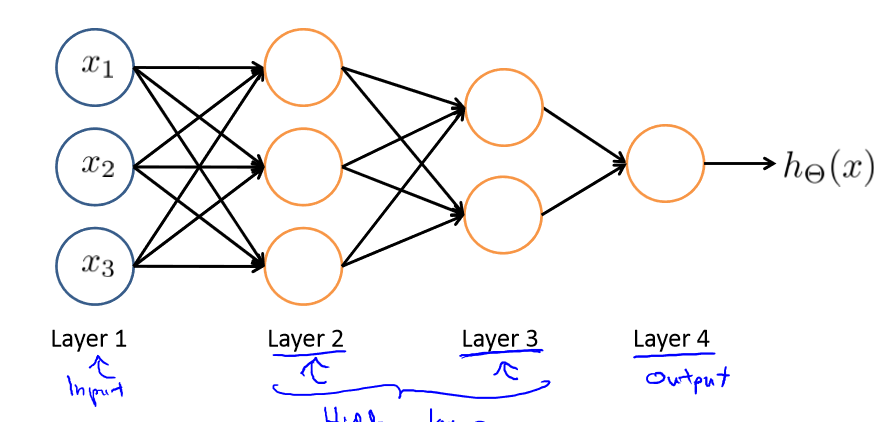
神经网络也可以有隐藏层:
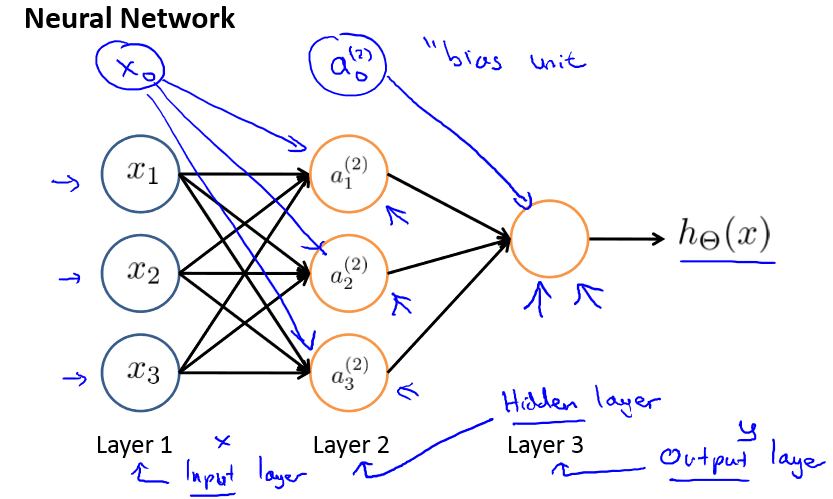
其中x1,x2,x3是输入单元,我们把原始数据输入给它们,a1,a2,a3是中间单元,它们负责将数据进行处理,然后呈递到下一层。最后是输出单元,它负责计算h(x).
符号定义:

每一层的输出变量都是下一层的输入变量,第一层为输入层,最后一层为输出层,中间的为隐藏层,每一层都有一个偏差单元。

这样通过计算最终就可以得到hθ(x)的值。一般情况下每一层都要多加入一个变量。
我们把这样从左往右的算法称为前向传播算法(FORWARD PROPAGATION)
Model representation II
利用向量化的方法会使得计算更为简便。以上面的神经网络为例,计算第二层的值:
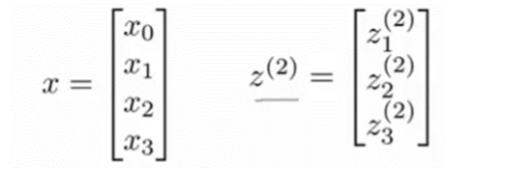
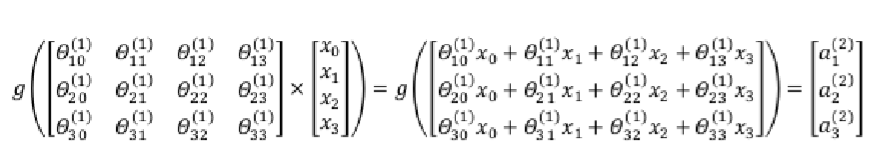
我们令z(2) = θ(1)x,则a(2) = g(z(2)),计算后添加a(2)0 = 1。
同样令z(2) =θ(1)a(2) ,则hθ(x) = a(3) = g(z(3))。
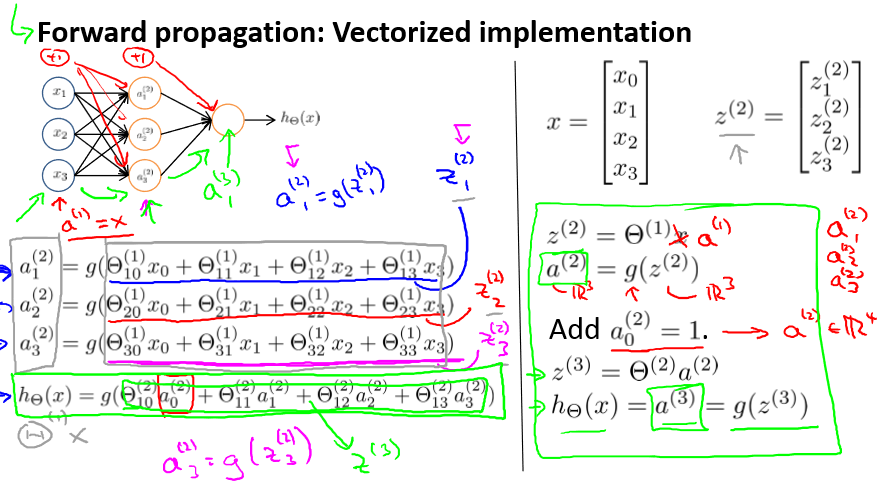
多层的也类似:
由上一层输出值当作下一层输入值进行计算得到输出值给下一层。
Examples and intuitions I
以XOR(异或)为例:
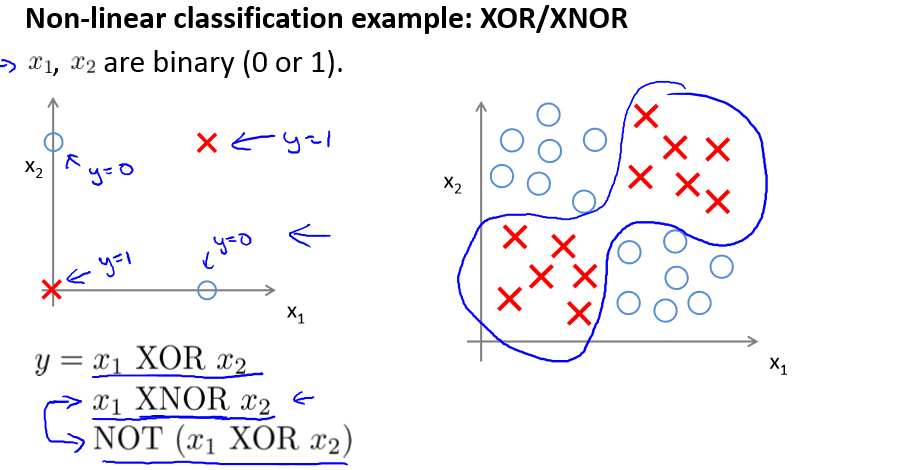
当x1 = x2 时 y = 1 ,或者 y = 0
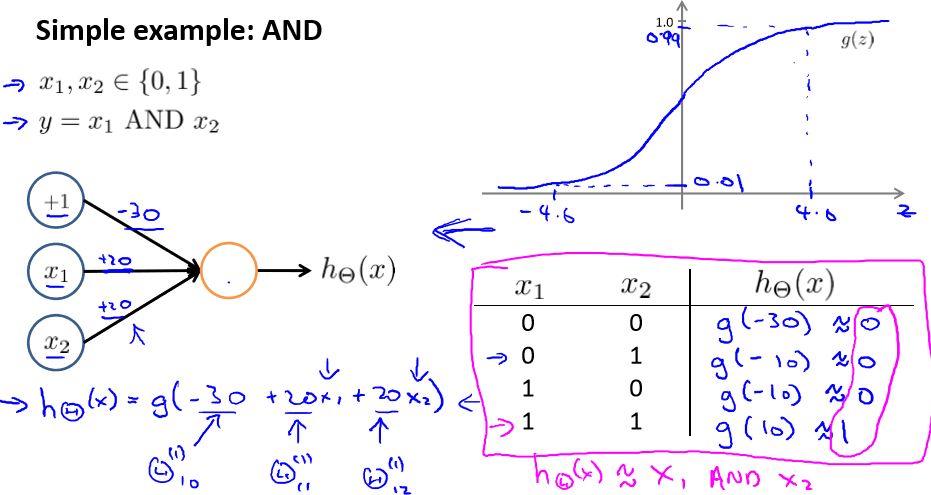
上面是“与”(AND)运算,输入层由两个变量x1和x2组成,再加上一个1,权重分别是-30,20,20。
那么hθ(x) = a1 = g(z(1)) = g(-30+20x1+20x2),将x1,x2的值代入进去,得到的值正好和“与”运算相符

再比如“或”(OR)运算,权重可以设为-10,20,20这三个,得出的结果会和“或”运算相符。
Examples and intuitions II
之前介绍了“或”和“与”,下面介绍下“非”运算,这个更简单些,只需要一个变量。

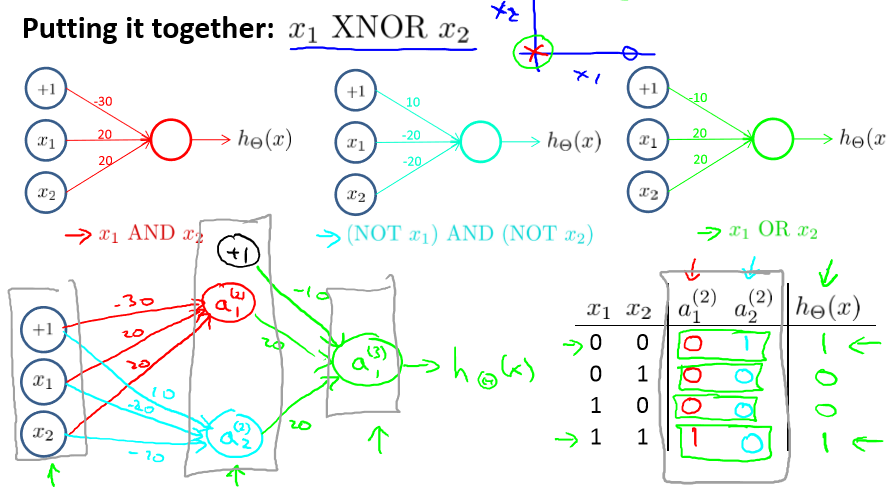
有了“或”、“与”和“非”,现在就可以计算“同或门”运算了。
由于x1 XNOR x2 = (x1 and x2 ) or ((not x1) and (not x2))
所以我们可以先计算 (x1 and x2 ) 为 a1,(not x1) and (not x2) 为 a2. 然后在计算a1 or a2 得到答案
过程如下:
Multiclass Classification
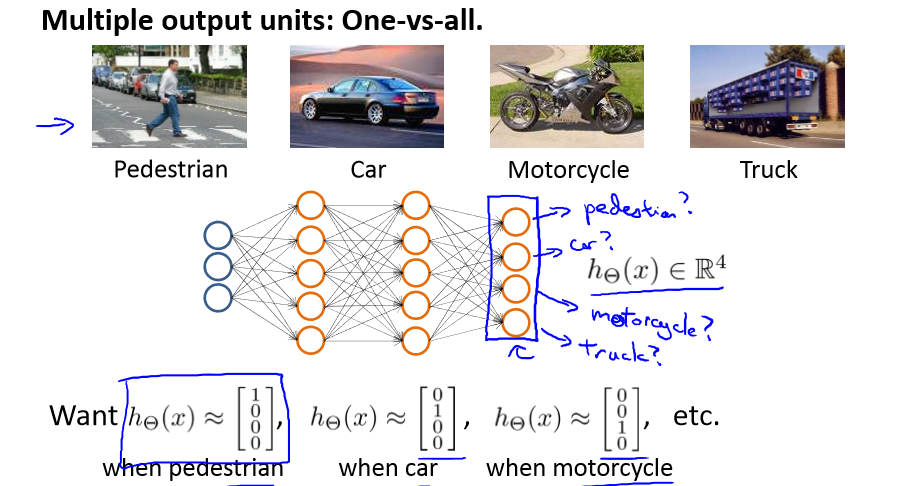
有时候我们有不止两种分类,也就是y = 2, 3, 4, 5..... 那么这种情况怎么办呢?
如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有 4 个值。
例如,第一个值为 1 或 0 用于预测是否是行人,第二个值用于判断是否为汽车。
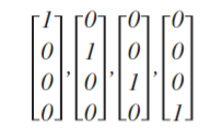
那么[1; 0; 0; 0]可以表示路人,[0; 1; 0; 0] 可以表示汽车 等等。
输入情况就有四种了: