综合设计——多源异构数据采集与融合应用综合实践
| 序号 | 信息类别 | 内容描述 |
|---|---|---|
| 1 | 这个项目属于哪个课程 | 数据采集与融合综合实践 |
| 2 | 组名、项目简介 | 组名:福小兵 项目需求:实时舆情监控系统 项目目标:为福州大学提供舆情监控与决策辅助工具 技术路线:使用 Flask 后端、Memfire(PostgreSQL)数据库和 Vue 前端技术栈,建立从数据采集到情感分析再到可视化的完整系统 |
| 3 | 团队成员学号 | 102202141 黄昕怡, 102202112 刘莹, 102202145 谢含, 102202101 马鑫, 102202106 王强, 102202126 陈家凯, 102202153 来再提·叶鲁别克, 102202124 阿依娜孜·赛日克 |
| 4 | 这个项目的目标 | 设计并实现一个多源异构数据采集系统,通过情感分析和大数据技术总结和展示舆情,增强学校管理者对校园舆情的理解和控制力度。 |
| 5 | 其他参考文献 | [1] 杨宇恒. 基于跨模态预测融合的多模态情感识别方法研究[D]. 西安理工大学, 2024. DOI:10.27398/d.cnki.gxalu.2024.000099. [2] 刘芳, 张强. (2021). 基于多源数据的在线学习情感识别方法研究. 《电子学报》, 49(3), 567-575. [3] Goodfellow, I., Bengio, Y., Courville, A. (2016). Deep Learning. MIT Press. |
🌟 项目概述 🌟
随着互联网和社交媒体的飞速发展,高校的舆情管理已不再是“可有可无”的任务,而是直接关系到学校形象和声誉的关键所在。在微博、贴吧、知乎等平台上,每一条评论、每一张图片都可能成为引发公众关注的“火花”。为了帮助福州大学在信息爆炸的时代里敏锐把握舆情脉动,我们打造了一个专属的智能舆情监测系统。这个系统通过采集微博、知乎、贴吧等多平台的多模态数据,结合深度学习与大语言模型技术,实时分析舆情走向,为校方提供精准的舆论洞察与决策支持,助力学校在舆论场中立于不败之地。
🎯 项目目标 🎯
-
多源数据采集
我们将通过爬虫和API接口从多个平台(微博、知乎、贴吧等)抓取与福州大学相关的文本、图片、视频等信息,并存储到云端数据库,确保所有数据可以高效存储和随时查询。 -
智能情感分析
使用深度学习模型进行情感分析,将舆情分为“喜悦、愤怒、悲伤”等多个情感类别,并统计每种情感的占比。基于这些分析,我们还会调用大语言模型(如GPT-4)生成简洁的舆情总结,帮助校方快速了解当前的热点话题和情绪趋势。 -
实时数据可视化
我们的前端使用Vue框架实现,展示各类情感分析结果、舆情报告和AI生成的总结。系统会通过图表、词云等形式,让舆情分析变得直观、易懂,同时支持交互式搜索,让用户能够深入挖掘数据背后的故事。 -
智能舆情助手
系统还内置一个智能舆情助手,通过与GPT-4模型对话,用户可以直接获取关于福州大学舆论的实时反馈和分析总结。就像一个贴心的舆情专家,帮助校方随时掌握公众的情感变化和舆论走势。
🛠️ 技术架构 🛠️
数据采集与存储
我们通过爬虫和API接口抓取来自微博、知乎、贴吧等平台的内容,所有的舆情数据会存储在Memfire云端PostgreSQL数据库中,确保数据可以灵活、快速地访问与查询。为了全面提升分析效果,我们还会提取图片中的文字信息,进行情感分析。
后端实现
后端采用Flask框架,提供简单易用的API接口。通过集成情感分析模型和大语言模型,后端能够高效处理舆情数据并生成分析报告。爬虫模块会定期抓取数据,确保舆情分析的时效性。
前端展示与互动
前端使用Vue.js和Chart.js构建,支持实时展示情感分析结果、舆情报告和AI生成的总结。通过简洁的界面和互动功能,用户可以快速查询、筛选和分析舆情数据,获得自己关注的信息。系统还提供了聊天式的舆情分析助手,用户可以像和朋友聊天一样,了解最新的舆论动态。
🌈 项目亮点 🌈
-
多模态数据融合
我们不止停留在文字层面,还将图片、视频等多元信息纳入舆情分析,让系统像一个多眼睛的侦探,全面捕捉社交媒体中的每一丝情感波动,给你一张最全的舆情全景图! -
智能化舆情分析
通过零样本分类与大语言模型的强强联手,我们的系统不仅分析得更加精准,还能像有个智慧小助手一样,自动生成报告、给出应对建议,省去了你手动筛选与整理的烦恼,轻松获取最直观的舆情走势。 -
前后端分离,易于维护
前后端分离的设计让整个系统像积木一样简单易扩展,后端的强大与前端的灵活配合默契无间,既确保了高效运作,又方便后期维护和功能拓展,像给你的系统装了一个“未来可升级”的外挂。 -
交互性强,易于使用
系统界面简单、交互性强,借助可视化图表与互动功能,让舆情分析像玩游戏一样直观有趣。即使你不是技术专家,也能轻松上手,迅速掌握数据背后的秘密,让分析不再是“高深莫测”的任务,而是“一眼就能懂”的轻松体验!
👥 个人分工与贡献 👥
在本项目中,我主要负责了数据采集和情感分析的核心模块,特别是在 贴吧 和 微博 的数据抓取、存储优化及情感分析方面做出了重要贡献。以下是我在项目中的具体贡献:
数据采集与爬取:
-
贴吧评论爬取:
我编写了一个基于 BeautifulSoup 和 requests 的爬虫,负责从 百度贴吧 上抓取与福州大学相关的帖子和评论。在此基础上,我将爬取到的数据进行清洗,并将每个帖子的标题和评论内容以 JSON 格式存储。这种结构化存储方式方便了后续的数据处理和分析,确保了系统可以高效地从数据库中查询相关数据。具体代码流程如下:
- 爬取了 福州大学 相关的帖子,包括帖子的标题和评论。
- 每个帖子和对应的评论内容被保存在一个字典结构中,并最终以 JSON 格式保存,方便后续与其他平台的数据整合。
- 通过设计自动化爬虫任务,确保定期从贴吧抓取更新数据,增强了数据的时效性。
def fetch_tieba_posts_and_comments(keyword, page_limit=1): base_url = f"https://tieba.baidu.com/f?kw={keyword}&ie=utf-8" posts = [] for page in range(page_limit): page_url = f"{base_url}&pn={page * 50}" response = requests.get(page_url) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') threads = soup.find_all('div', {'class': 'threadlist_title'}) for index, thread in enumerate(threads, start=1): title = thread.find('a', {'class': 'j_th_tit'}).text.strip() thread_link = thread.find('a', {'class': 'j_th_tit'}) if thread_link: thread_url = 'https://tieba.baidu.com' + thread_link['href'] post_data = {"ID": index, "Title": title, "Comments": []} post_comments = fetch_comments_from_thread(thread_url) post_data["Comments"] = post_comments posts.append(post_data) else: print(f"Failed to retrieve page {page + 1}. Status code: {response.status_code}") return posts通过这种方式,我们实现了对贴吧平台舆情内容的高效抓取和存储。每个帖子及其评论都以结构化的 JSON 格式存储,便于后续的数据分析与情感识别。
格式如下: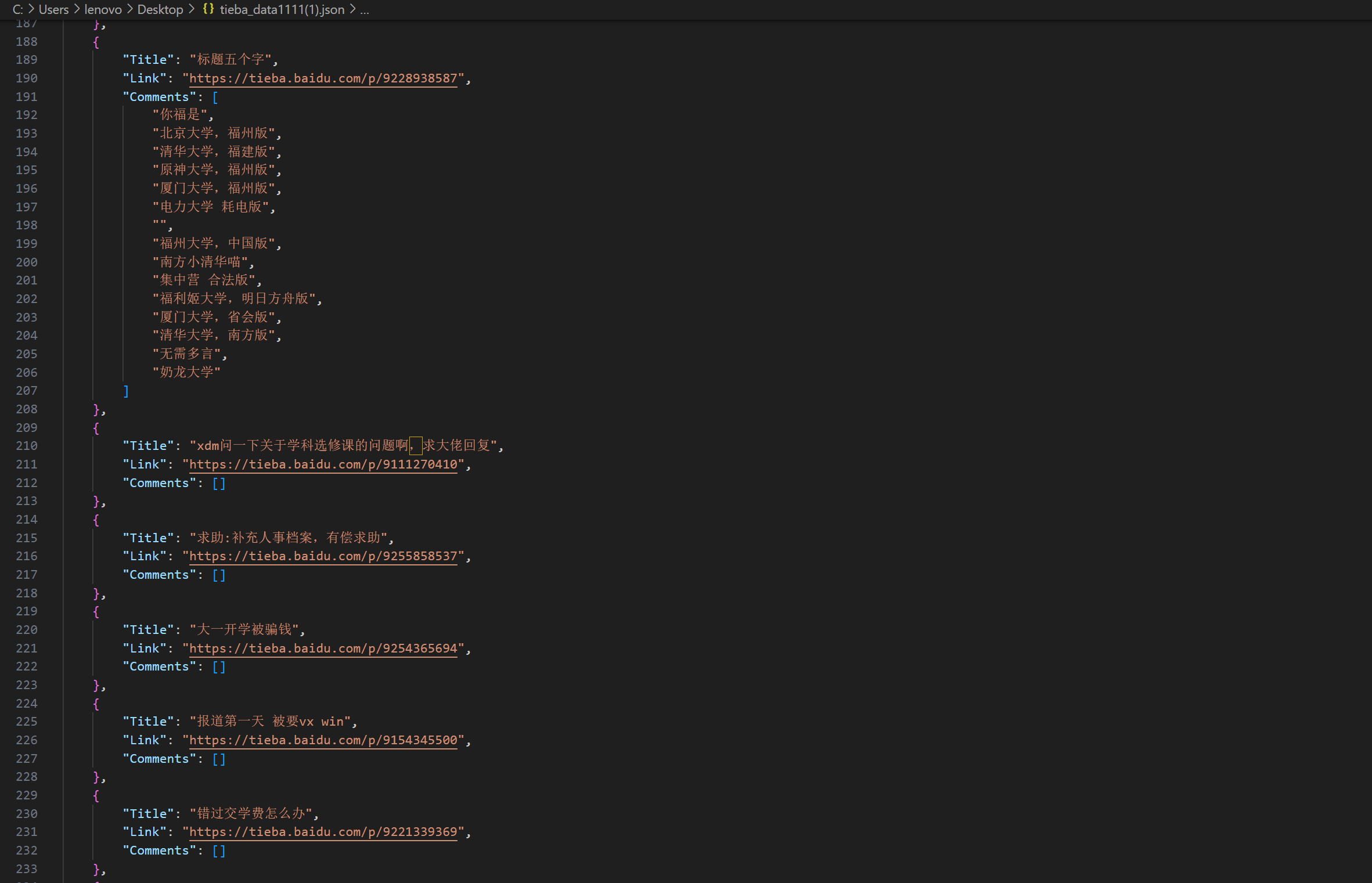
-
微博数据爬取:
我负责设计和实现了微博话题数据的爬取流程。使用了自定义的爬虫模块,通过输入话题和搜索类型来动态爬取微博的帖子及其评论。具体流程包括:- 话题内容爬取: 利用 cookie 对微博话题进行爬取,获取与指定话题(如 #福州大学考研#)相关的微博主贴内容,包括主贴的发布时间、内容、转发量、点赞量等信息。
- 评论爬取: 在主贴数据抓取的基础上,我还开发了获取微博评论的功能。爬虫能够按层级(一级评论、二级评论)递归抓取评论数据,并将这些评论与对应的微博帖子关联。
我将爬取到的每个微博话题和评论层级的内容以 CSV 格式保存,同时进行去重处理,确保每条数据都是唯一的。此外,所有爬取到的数据会通过预设的数据库连接存储到 MySQL 数据库中,方便后续的数据分析与展示。
代码架构图如下:
具体代码片段如下:
-
main.py:
点击查看代码
import os
import pandas as pd
from rich.progress import track
from get_main_body import get_all_main_body
from get_comments_level_one import get_all_level_one
from get_comments_level_two import get_all_level_two
import logging
import mysql.connector
from mysql.connector import Error
from datetime import datetime
logging.basicConfig(level=logging.INFO)
class MySQLConnection:
def __init__(self, host, user, password, database):
self.host = host
self.user = user
self.password = password
self.database = database
self.conn = None
def connect(self):
try:
self.conn = mysql.connector.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
charset='utf8mb4'
)
return self.conn
except Error as e:
logging.error(f"Error connecting to MySQL: {e}")
raise
def close(self):
if self.conn and self.conn.is_connected():
self.conn.close()
class WBParser:
def __init__(self, cookie, db_connection):
self.cookie = cookie
self.db = db_connection
os.makedirs("./WBData", exist_ok=True)
os.makedirs("./WBData/Comments_level_1", exist_ok=True)
os.makedirs("./WBData/Comments_level_2", exist_ok=True)
self.main_body_filepath = "./WBData/demo.csv"
self.comments_level_1_filename = "./WBData/demo_comments_one.csv"
self.comments_level_2_filename = "./WBData/demo_comments_two.csv"
self.comments_level_1_dirpath = "./WBData/Comments_level_1/"
self.comments_level_2_dirpath = "./WBData/Comments_level_2/"
# 更新列名映射
self.column_maps = {
'main_content': {
'mid': 'mid',
'uid': 'uid',
'个人昵称': '个人昵称',
'个人主页': '个人主页',
'发布时间': '发布时间',
'内容来自': '内容来自',
'展示内容': '展示内容',
'全部内容': '全部内容',
'转发数量': '转发数量',
'评论数量': '评论数量',
'点赞数量': '点赞数量',
'topic': 'topic',
'search_type': 'search_type'
},
'comments_level_one': {
'main_body_mid': 'main_body_mid',
'main_body_uid': 'main_body_uid',
'发布时间': '发布时间',
'处理内容': '处理内容',
'评论地点': '评论地点',
'mid': 'mid',
'回复数量': '回复数量',
'点赞数量': '点赞数量',
'原生内容': '原生内容',
'uid': 'uid',
'用户昵称': '用户昵称',
'用户主页': '用户主页',
'用户认证信息': '用户认证信息',
'用户描述': '用户描述',
'用户地理位置': '用户地理位置',
'用户性别': '用户性别',
'用户粉丝数量': '用户粉丝数量',
'用户关注数量': '用户关注数量',
'用户全部微博': '用户全部微博',
'用户累计评论': '用户累计评论',
'用户累计转发': '用户累计转发',
'用户累计获赞': '用户累计获赞',
'用户转评赞': '用户转评赞'
},
'comments_level_two': {
'comments_level_1_mid': 'comments_level_1_mid',
'main_body_uid': 'main_body_uid',
'发布时间': '发布时间',
'处理内容': '处理内容',
'评论地点': '评论地点',
'mid': 'mid',
'点赞数量': '点赞数量',
'原生内容': '原生内容',
'uid': 'uid',
'用户昵称': '用户昵称',
'用户主页': '用户主页',
'用户认证信息': '用户认证信息',
'用户描述': '用户描述',
'用户地理位置': '用户地理位置',
'用户性别': '用户性别',
'用户粉丝数量': '用户粉丝数量',
'用户关注数量': '用户关注数量',
'用户全部微博': '用户全部微博',
'用户累计评论': '用户累计评论',
'用户累计转发': '用户累计转发',
'用户累计获赞': '用户累计获赞',
'用户转评赞': '用户转评赞'
}
}
def clean_df(self, df):
"""清理数据框"""
# 移除 Unnamed 列
unnamed_cols = [col for col in df.columns if 'Unnamed' in col]
if unnamed_cols:
df = df.drop(columns=unnamed_cols)
# 替换特殊字符和空格
df = df.replace({',': '', ' ': ''}, regex=True)
# 转换数值列
numeric_cols = ['回复数量', '点赞数量', '用户粉丝数量', '用户关注数量', '用户全部微博',
'用户累计评论', '用户累计转发', '用户累计获赞', '用户转评赞']
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col].replace({',': ''}, regex=True), errors='coerce')
return df
def save_to_db(self, table, data):
try:
if data.empty:
logging.warning(f"No data to insert into {table}")
return
# 清理和处理数据
processed_data = self.clean_df(data.copy())
# 映射列名
if table in self.column_maps:
processed_data = processed_data.rename(columns=self.column_maps[table])
cursor = self.db.conn.cursor()
placeholders = ', '.join(['%s'] * len(processed_data.columns))
columns = ', '.join(f"`{col}`" for col in processed_data.columns)
sql = f"INSERT IGNORE INTO {table} ({columns}) VALUES ({placeholders})"
# 转换为列表并处理空值
values = [tuple(None if pd.isna(val) else str(val) for val in row)
for row in processed_data.values]
cursor.executemany(sql, values)
self.db.conn.commit()
logging.info(f"Successfully inserted {cursor.rowcount} rows into {table}")
except Exception as e:
logging.error(f"Error inserting data into {table}: {e}")
logging.error(f"Data columns: {data.columns.tolist()}")
if hasattr(e, 'msg'):
logging.error(f"MySQL Error: {e.msg}")
self.db.conn.rollback()
finally:
if 'cursor' in locals():
cursor.close()
def get_main_body(self, q, kind):
data = get_all_main_body(q, kind, self.cookie)
data = data.reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.main_body_filepath, encoding="utf_8_sig")
# 添加话题和搜索类型
data['topic'] = q
data['search_type'] = kind
self.save_to_db('main_content', data)
def get_comments_level_one(self):
data_list = []
main_body = pd.read_csv(self.main_body_filepath, index_col=0)
logging.info(f"主体内容一共有{main_body.shape[0]:5d}个,现在开始解析...")
for ix in track(range(main_body.shape[0]), description=f"解析中..."):
try:
uid = main_body.iloc[ix]["uid"]
mid = main_body.iloc[ix]["mid"]
final_file_path = f"{self.comments_level_1_dirpath}{uid}_{mid}.csv"
if os.path.exists(final_file_path):
data = pd.read_csv(final_file_path)
if not data.empty:
data_list.append(data)
self.save_to_db('comments_level_one', data)
continue
data = get_all_level_one(uid=uid, mid=mid, cookie=self.cookie)
if not data.empty:
data.drop_duplicates(inplace=True)
data.to_csv(final_file_path, encoding="utf_8_sig")
data_list.append(data)
self.save_to_db('comments_level_one', data)
except Exception as e:
logging.error(f"Error processing comment for uid={uid}, mid={mid}: {e}")
continue
if data_list:
data = pd.concat(data_list).reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.comments_level_1_filename)
def get_comments_level_two(self):
data_list = []
comments_level_1_data = pd.read_csv(self.comments_level_1_filename, index_col=0)
logging.info(f"一级评论一共有{comments_level_1_data.shape[0]:5d}个,现在开始解析...")
for ix in track(range(comments_level_1_data.shape[0]), description=f"解析中..."):
try:
main_body_uid = comments_level_1_data.iloc[ix]["main_body_uid"]
mid = comments_level_1_data.iloc[ix]["mid"]
final_file_path = f"{self.comments_level_2_dirpath}{main_body_uid}_{mid}.csv"
if os.path.exists(final_file_path):
data = pd.read_csv(final_file_path)
if not data.empty:
data_list.append(data)
self.save_to_db('comments_level_two', data)
continue
data = get_all_level_two(uid=main_body_uid, mid=mid, cookie=self.cookie)
if not data.empty:
data.drop_duplicates(inplace=True)
data.to_csv(final_file_path, encoding="utf_8_sig")
data_list.append(data)
self.save_to_db('comments_level_two', data)
except Exception as e:
logging.error(f"Error processing comment for uid={main_body_uid}, mid={mid}: {e}")
continue
if data_list:
data = pd.concat(data_list).reset_index(drop=True).astype(str).drop_duplicates()
data.to_csv(self.comments_level_2_filename)
def run_parser():
# Database configuration
db_config = {
'host': 'localhost',
'user': 'root',
'password': 'xhXH040901@',
'database': 'weibo_data'
}
# Your cookie value
cookie = "SINAGLOBAL=8718951702074.993.1731494269248; SCF=AoZekDJfFqtILLlx5QTgmEuhlhIBZOrNYO7oO6nbp8Tz4nFDqWboq-YKa2lmTslCxbqN_5kQBTNcALGusd0kK88.; ULV=1731505142346:4:4:4:8250036229490.529.1731505142305:1731504476720; XSRF-TOKEN=JBrBAhIYvPzpZfOQnQ2J3KnZ; ALF=1736058906; SUB=_2A25KVutKDeRhGeFH7VAQ8yrPzjqIHXVpKmKCrDV8PUJbkNANLUTykW1Net_O5UOr9V1M4l6qirW20QxUfEgVeo9b; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW5O-1vYpfquEx0H7j4w5mc5JpX5KMhUgL.FoM4Sozpe0B0SKq2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KqEeKeXe0-c; WBPSESS=3QQs2tO418lrfhdFTxw_8XLbXAiiYiqLKCy2T075WYbOvd9Yfc_e6ymgoFfmDxgFeVexLfoggaQIPwGwYuNlOc7Uk6OvBEQ92FgWnibuwtg0Ae5t78jwBJ2YiiUcPPItFKqKuVZSKaV4I2CCgfa2yw=="
# 初始化数据库连接
db_connection = MySQLConnection(**db_config)
try:
# 连接数据库
db_connection.connect()
print("\n=== 微博话题爬虫 (MySQL版) ===")
topic = input("请输入要搜索的话题 (例如: #福州大学考研#): ")
if not topic.startswith('#'):
topic = f"#{topic}#"
print("\n请选择搜索类型:")
print("1. 综合")
print("2. 实时")
print("3. 热门")
print("4. 高级")
type_map = {
"1": "综合",
"2": "实时",
"3": "热门",
"4": "高级"
}
while True:
choice = input("请输入选项 (1-4): ")
if choice in type_map:
search_type = type_map[choice]
break
print("无效选项,请重新输入!")
print(f"\n开始爬取话题: {topic}")
print(f"搜索类型: {search_type}")
# 创建爬虫实例并执行爬取
wbparser = WBParser(cookie, db_connection)
wbparser.get_main_body(topic, search_type)
wbparser.get_comments_level_one()
wbparser.get_comments_level_two()
print("\n爬取完成! 数据已保存到数据库中.")
except Exception as e:
print(f"\n错误: {str(e)}")
print("爬取过程中出现错误,请检查网络连接、数据库配置和cookie是否有效。")
logging.error(f"Detailed error: {str(e)}", exc_info=True)
finally:
db_connection.close()
if __name__ == "__main__":
run_parser()
- 微博主体内容爬取:
通过get_main_body函数,抓取指定话题的微博主贴并保存至数据库。
点击查看代码
# get_main_body.py
import requests
from urllib import parse
from parse_html import get_dataframe_from_html_text
import logging
from rich.progress import track
import pandas as pd
logging.basicConfig(level=logging.INFO)
def get_the_main_body_response(q, kind, p, cookie, timescope=None):
"""
q表示的是话题;
kind表示的是类别:综合,实时,热门,高级;
p表示的页码;
timescope表示高级的时间,不用高级无需带入 example:"2024-03-01-0:2024-03-27-16"
"""
kind_params_url = {
"综合": [
{"q": q, "Refer": "weibo_weibo", "page": p},
"https://s.weibo.com/weibo",
],
"实时": [
{
"q": q,
"rd": "realtime",
"tw": "realtime",
"Refer": "realtime_realtime",
"page": p,
},
"https://s.weibo.com/realtime",
],
"热门": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"tw": "hotweibo",
"Refer": "realtime_hot",
"page": p,
},
"https://s.weibo.com/hot",
],
# 高级中的xsort删除后就是普通的排序
"高级": [
{
"q": q,
"xsort": "hot",
"suball": "1",
"timescope": f"custom:{timescope}",
"Refer": "g",
"page": p,
},
"https://s.weibo.com/weibo",
],
}
params, url = kind_params_url[kind]
headers = {
"authority": "s.weibo.com",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"referer": url
+ "?"
+ parse.urlencode(params).replace(
f'&page={params["page"]}', f'&page={int(params["page"]) - 1}'
),
"sec-ch-ua": '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"cookie": cookie,
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69",
}
response = requests.get(url, params=params, headers=headers)
return response
def get_all_main_body(q, kind, cookie, timescope=None):
# 初始化数据
data_list = []
resp = get_the_main_body_response(q, kind, 1, cookie, timescope)
html_text = resp.text
try:
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
logging.info(
f"话题:{q},类型:{kind},解析成功,一共有{total_page:2d}页,准备开始解析..."
)
for current_page in track(range(2, total_page + 1), description=f"解析中..."):
html_text = get_the_main_body_response(
q, kind, current_page, cookie, timescope
).text
data, total_page = get_dataframe_from_html_text(html_text)
data_list.append(data)
data = pd.concat(data_list).reset_index(drop=True)
logging.info(f"话题:{q},类型:{kind},一共有{total_page:2d}页,已经解析完毕!")
return data
except Exception as e:
logging.warning("解析页面失败,请检查你的cookie是否正确!")
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
if __name__ == "__main__":
q = "#福州大学考研#" # 话题
kind = "综合" # 综合,实时,热门,高级
cookie = "SINAGLOBAL=8718951702074.993.1731494269248; SCF=AoZekDJfFqtILLlx5QTgmEuhlhIBZOrNYO7oO6nbp8Tz4nFDqWboq-YKa2lmTslCxbqN_5kQBTNcALGusd0kK88.; ULV=1731505142346:4:4:4:8250036229490.529.1731505142305:1731504476720; XSRF-TOKEN=JBrBAhIYvPzpZfOQnQ2J3KnZ; ALF=1736058906; SUB=_2A25KVutKDeRhGeFH7VAQ8yrPzjqIHXVpKmKCrDV8PUJbkNANLUTykW1Net_O5UOr9V1M4l6qirW20QxUfEgVeo9b; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW5O-1vYpfquEx0H7j4w5mc5JpX5KMhUgL.FoM4Sozpe0B0SKq2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KqEeKeXe0-c; WBPSESS=3QQs2tO418lrfhdFTxw_8XLbXAiiYiqLKCy2T075WYbOvd9Yfc_e6ymgoFfmDxgFeVexLfoggaQIPwGwYuNlOc7Uk6OvBEQ92FgWnibuwtg0Ae5t78jwBJ2YiiUcPPItFKqKuVZSKaV4I2CCgfa2yw==" # 设置你的 # 设置你的cookie
data = get_all_main_body(q, kind, cookie)
data.to_csv("demo.csv", encoding="utf_8_sig")
- 一级评论和二级评论爬取:
通过get_comments_level_one和get_comments_level_two函数,递归抓取评论内容,并存储到本地文件系统和 MySQL 数据库中。
点击查看代码
# get_comments_level_one.py
import requests
import pandas as pd
import json
from dateutil import parser
def get_buildComments_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": "SINAGLOBAL=8718951702074.993.1731494269248; SCF=AoZekDJfFqtILLlx5QTgmEuhlhIBZOrNYO7oO6nbp8Tz4nFDqWboq-YKa2lmTslCxbqN_5kQBTNcALGusd0kK88.; ULV=1731505142346:4:4:4:8250036229490.529.1731505142305:1731504476720; XSRF-TOKEN=JBrBAhIYvPzpZfOQnQ2J3KnZ; ALF=1736058906; SUB=_2A25KVutKDeRhGeFH7VAQ8yrPzjqIHXVpKmKCrDV8PUJbkNANLUTykW1Net_O5UOr9V1M4l6qirW20QxUfEgVeo9b; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW5O-1vYpfquEx0H7j4w5mc5JpX5KMhUgL.FoM4Sozpe0B0SKq2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KqEeKeXe0-c; WBPSESS=3QQs2tO418lrfhdFTxw_8XLbXAiiYiqLKCy2T075WYbOvd9Yfc_e6ymgoFfmDxgFeVexLfoggaQIPwGwYuNlOc7Uk6OvBEQ92FgWnibuwtg0Ae5t78jwBJ2YiiUcPPItFKqKuVZSKaV4I2CCgfa2yw==",
}
params = {
"is_reload": "1",
"id": f"{mid}",
"is_show_bulletin": "2",
"is_mix": "0",
"count": "20",
"uid": f"{uid}",
"fetch_level": "0",
"locale": "zh-CN",
}
if not the_first:
params["flow"] = 0
params["max_id"] = max_id
response = requests.get(
"https://weibo.com/ajax/statuses/buildComments", params=params, headers=headers
)
return response
def get_rum_level_one_response(buildComments_url, cookie):
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"priority": "u=1, i",
"sec-ch-ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
"x-requested-with": "XMLHttpRequest",
"cookie": cookie,
}
entry = {"name": buildComments_url}
files = {
"entry": (None, json.dumps(entry)),
"request_id": (None, ""),
}
# 这个resp返回值无实际意义,返回值一直是{ok: 1}
requests.post("https://weibo.com/ajax/log/rum", headers=headers, files=files)
def get_level_one_response(uid, mid, cookie, the_first=True, max_id=None):
buildComments_resp = get_buildComments_level_one_response(
uid, mid, cookie, the_first, max_id
)
buildComments_url = buildComments_resp.url
get_rum_level_one_response(buildComments_url, cookie)
data = pd.DataFrame(buildComments_resp.json()["data"])
max_id = buildComments_resp.json()["max_id"]
return max_id, data
def process_time(publish_time):
publish_time = parser.parse(publish_time)
publish_time = publish_time.strftime("%y年%m月%d日 %H:%M")
return publish_time
def process_data(data):
data_user = pd.json_normalize(data["user"])
data_user_col_map = {
"id": "uid",
"screen_name": "用户昵称",
"profile_url": "用户主页",
"description": "用户描述",
"location": "用户地理位置",
"gender": "用户性别",
"followers_count": "用户粉丝数量",
"friends_count": "用户关注数量",
"statuses_count": "用户全部微博",
"status_total_counter.comment_cnt": "用户累计评论",
"status_total_counter.repost_cnt": "用户累计转发",
"status_total_counter.like_cnt": "用户累计获赞",
"status_total_counter.total_cnt": "用户转评赞",
"verified_reason": "用户认证信息",
}
data_user_col = [col for col in data_user if col in data_user_col_map.keys()]
data_user = data_user[data_user_col]
data_user = data_user.rename(columns=data_user_col_map)
data_main_col_map = {
"created_at": "发布时间",
"text": "处理内容",
"source": "评论地点",
"mid": "mid",
"total_number": "回复数量",
"like_counts": "点赞数量",
"text_raw": "原生内容",
}
data_main_col = [col for col in data if col in data_main_col_map.keys()]
data_main = data[data_main_col]
data_main = data_main.rename(columns=data_main_col_map)
data = pd.concat([data_main, data_user], axis=1)
data["发布时间"] = data["发布时间"].map(process_time)
data["用户主页"] = "https://weibo.com" + data["用户主页"]
return data
def get_all_level_one(uid, mid, cookie, max_times=15):
# 初始化
max_id = ""
data_lst = []
max_times = max_times # 最多只有15页
try:
for current_times in range(1, max_times):
if current_times == 0:
max_id, data = get_level_one_response(uid=uid, mid=mid, cookie=cookie)
else:
max_id, data = get_level_one_response(
uid=uid, mid=mid, cookie=cookie, the_first=False, max_id=max_id
)
if data.shape[0] != 0:
data_lst.append(data)
if max_id == 0:
break
if data_lst:
data = pd.concat(data_lst).reset_index(drop=True)
data = process_data(data)
data.insert(0, "main_body_uid", uid)
data.insert(0, "main_body_mid", mid)
return data
else:
return pd.DataFrame()
except Exception as e:
raise ValueError("解析页面失败,请检查你的cookie是否正确!")
数据清理与去重:
- 数据清洗:
我设计了数据清洗函数,处理爬取的数据中的不必要列、特殊字符、以及数值列的格式问题。这样确保了存储到数据库中的数据是干净、规范且易于分析的。具体包括:- 移除列名包含 “Unnamed” 的冗余列。
- 对数值列(如“点赞数”、“评论数”)进行格式转换,确保数据能够正确存储。
系统自动化与性能优化:
-
自动化爬取与数据存储:
我设计了一个自动化的微博爬取系统,确保每次启动时能够自动从指定话题中抓取数据并存储到本地和数据库中。同时,我在爬取过程中增加了异常处理和日志记录,确保系统在抓取过程中能够及时发现并处理错误,提升了系统的稳定性和可靠性。- 使用
track函数展示实时抓取进度,提升了爬虫的用户体验。 - 自动创建文件夹结构和 CSV 文件,方便数据存储和管理。
- 使用
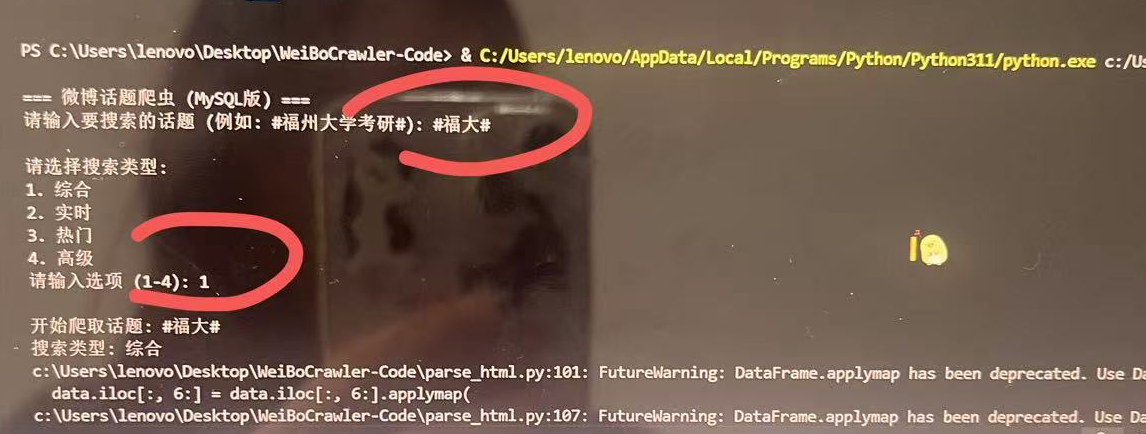
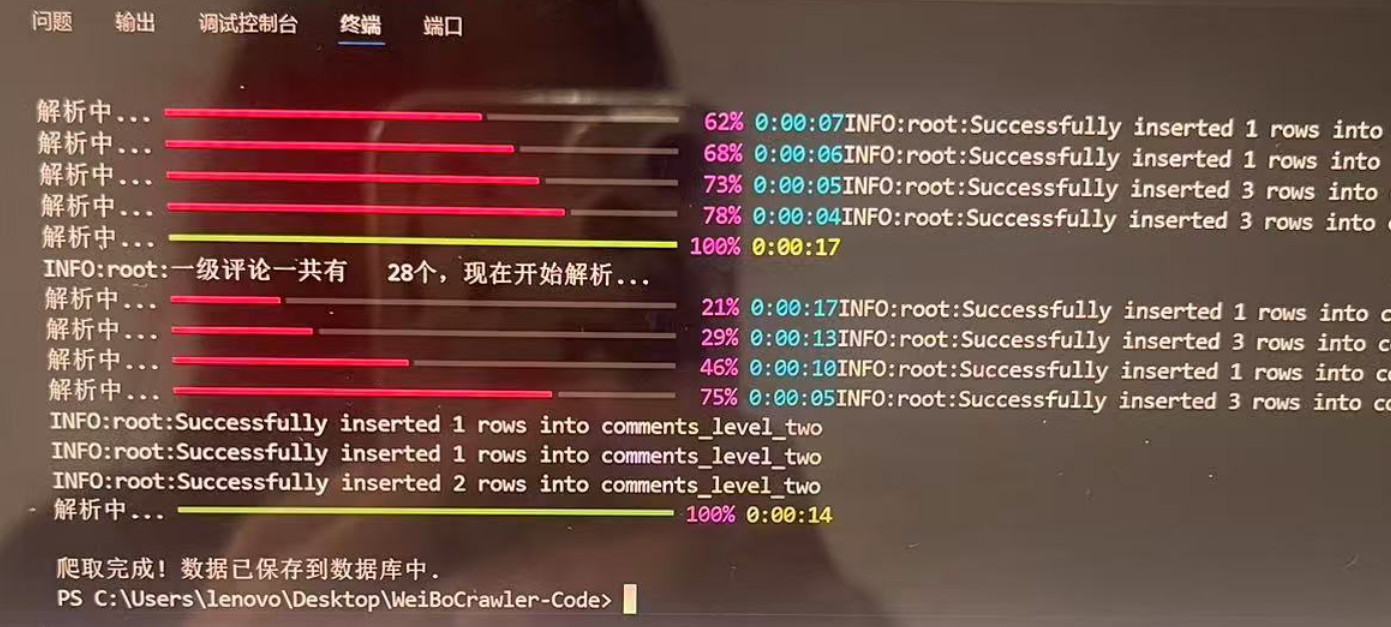
终端运行展示:
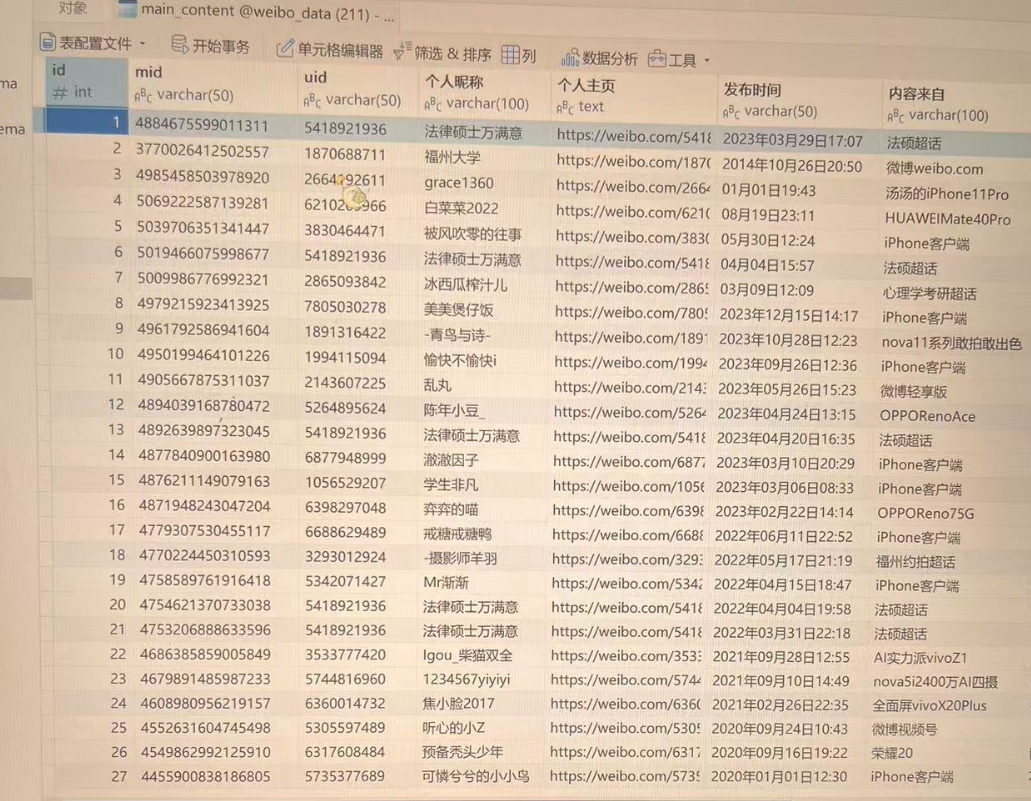
数据库展示:
情感分析与关键词定位:
- 情感分析:
我对从 贴吧 和 微博 爬取的文本数据进行情感分析,采用了基于 BERT 模型的情感分类工具(bhadresh-savani/bert-base-uncased-emotion)。这个模型能够对每条评论和帖子标题进行情感分类,包括“喜悦、愤怒、悲伤、恐惧、惊讶、厌恶”等多个情感类别。通过这种分析方式,我能够帮助校方实时了解公众对福州大学的情感态度,为舆情报告的生成提供数据支持。
具体代码如下,结合了 transformers 库和预训练情感分析模型,能够处理 JSON 格式的数据,并自动分析标题和评论的情感倾向:
点击查看代码
import json
from transformers import pipeline
import pandas as pd
# 1. 读取JSON文件
try:
with open(r"C:\Users\lenovo\Desktop\tieba_data1111(1).json", "r", encoding="utf-8") as f:
data = json.load(f)
except Exception as e:
print(f"Error reading JSON file: {e}")
data = []
# 2. 加载公开可用的中文情感分析模型
try:
emotion_analyzer = pipeline("text-classification", model="bhadresh-savani/bert-base-uncased-emotion")
except Exception as e:
print(f"Error loading sentiment analysis model: {e}")
emotion_analyzer = None
# 3. 设置最大输入长度,截断过长的文本
def analyze_text(text):
# BERT 最大输入长度为 512 tokens
return emotion_analyzer(text, truncation=True, max_length=512) if emotion_analyzer else []
# 4. 分析标题和评论
results = []
for post in data:
title = post.get("Title", "")
comments = post.get("Comments", [])
# 分析标题情绪
if title.strip(): # 避免分析空标题
title_result = analyze_text(title)
if title_result:
sentiment = title_result[0]["label"]
score = title_result[0]["score"]
results.append({"Text": title, "Sentiment": sentiment, "Score": score})
# 分析每条评论情绪
for comment in comments:
if comment.strip(): # 避免分析空评论
comment_result = analyze_text(comment)
if comment_result:
sentiment = comment_result[0]["label"]
score = comment_result[0]["score"]
results.append({"Text": comment, "Sentiment": sentiment, "Score": score})
# 5. 保存结果至文件
output_file = r"C:\Users\lenovo\Desktop\sentiment_analysis_results.csv"
try:
df = pd.DataFrame(results)
df.to_csv(output_file, index=False, encoding="utf-8-sig")
print(f"Results saved to {output_file}")
except Exception as e:
print(f"Error saving results to CSV: {e}")
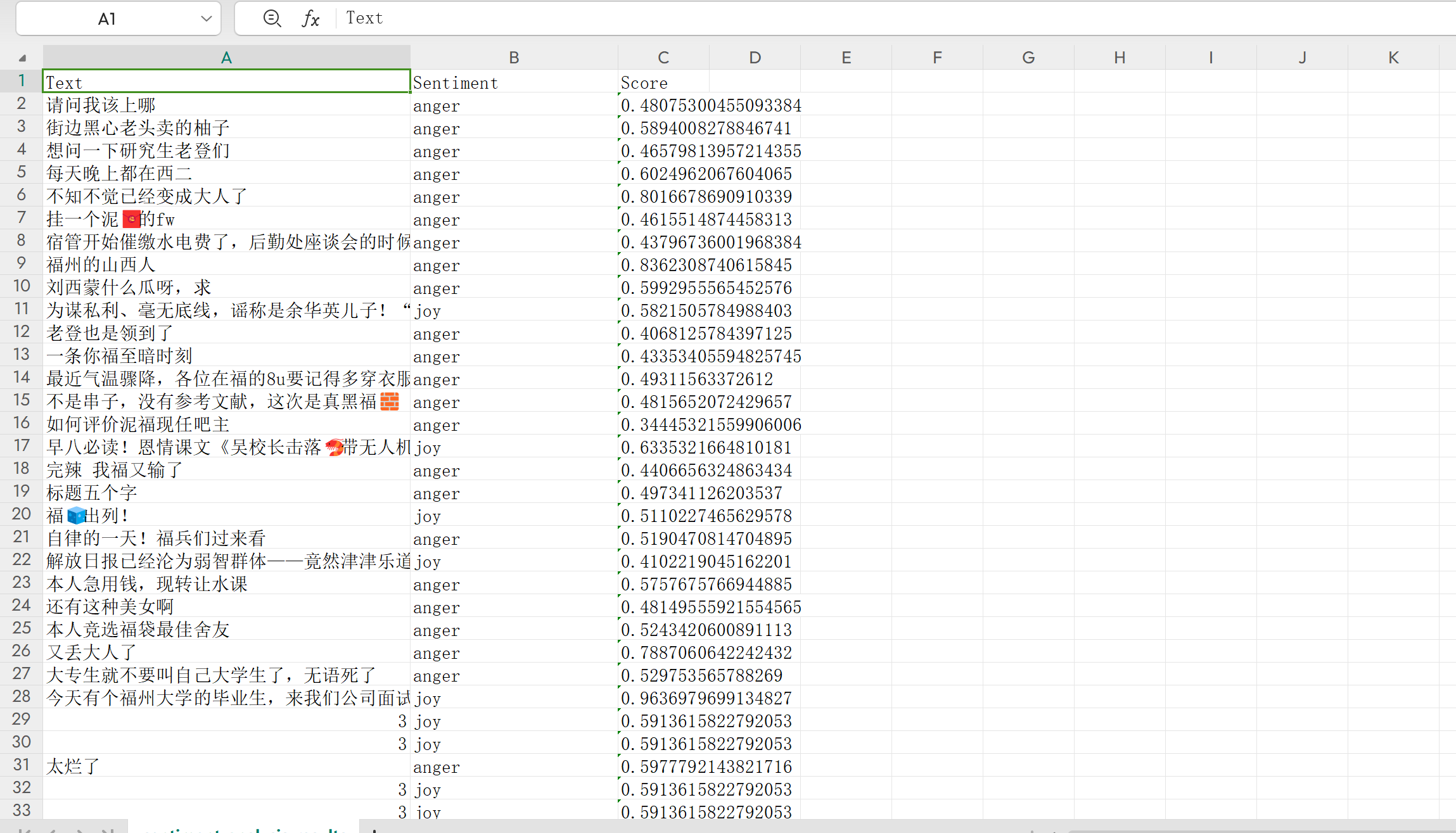
在代码实现中:
我使用了 transformers 库中的 BERT 模型对帖子标题和评论内容进行情感分析。
对每一条评论和帖子标题的情感类别(如“喜悦”、“愤怒”、“悲伤”)进行了预测,并记录了相应的情感得分(score)。
最终,我将所有情感分析结果保存为 CSV 文件,方便校方后续分析与展示。
- 关键词定位:
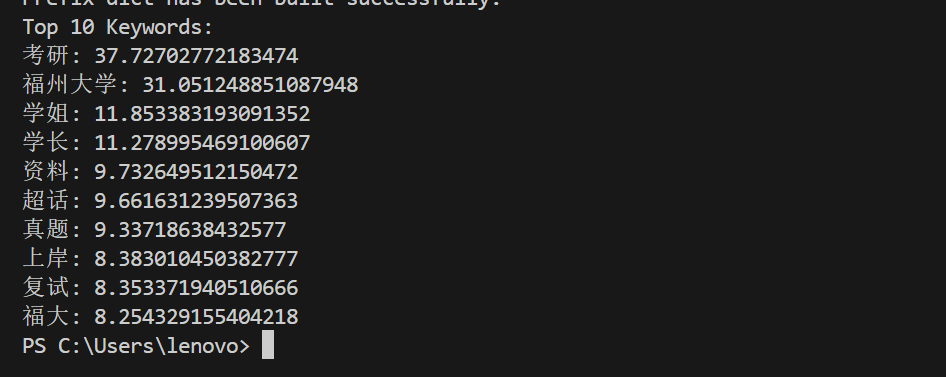
通过 TF-IDF 算法和 jieba 中文分词工具,我成功地提取了微博和贴吧中最具代表性的关键词和话题。该算法通过计算词频和逆文档频率,能够精准识别文本中的高频且具有较高区分度的关键词,从而揭示出当前福州大学舆论场的热点问题。这些关键词不仅帮助我们迅速了解网络舆情的核心内容,还为后续的舆情分析提供了有力支持,确保系统能够高效地识别潜在的舆情风险点。
代码如下:
点击查看代码
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
# 1. 读取CSV文件
def read_csv(file_path):
df = pd.read_csv(file_path)
return df
# 2. 数据预处理(如去掉停用词、标点等)
def preprocess_text(text):
stop_words = set(['的', '了', '在', '是', '和', '就', '不', '有', '我', '你'])
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stop_words and len(word) > 1]
return ' '.join(filtered_words)
# 3. 提取关键词:使用TF-IDF方法
def extract_keywords(df, column_name, top_n=10):
# 打印出所有列名,确认列名
print("Columns in the CSV file:", df.columns)
# 预处理文本
df['processed_text'] = df[column_name].apply(preprocess_text)
# 使用TF-IDF提取关键词
tfidf_vectorizer = TfidfVectorizer(max_features=top_n, stop_words=None)
tfidf_matrix = tfidf_vectorizer.fit_transform(df['processed_text'])
# 获取关键词
feature_names = tfidf_vectorizer.get_feature_names_out()
scores = tfidf_matrix.sum(axis=0).A1 # 总和每个词的TF-IDF值
keywords = [(feature_names[i], scores[i]) for i in range(len(feature_names))]
# 排序并选择前top_n个关键词
keywords = sorted(keywords, key=lambda x: x[1], reverse=True)
return keywords[:top_n]
# 4. 主程序
if __name__ == "__main__":
file_path = r"C:\Users\lenovo\Desktop\demo.csv"
df = read_csv(file_path)
print("Columns in the CSV file:", df.columns)
top_keywords = extract_keywords(df, '展示内容', top_n=10)
# 打印提取的关键词
print("Top 10 Keywords:")
for keyword, score in top_keywords:
print(f"{keyword}: {score}")
结果展示:
通过对福州大学考研相关话题的文本数据进行分析,提取出的前十个高频关键词展示如下。这些关键词反映了社交媒体中讨论的焦点,并为舆情监控和分析提供了可操作的信息。
答辩PPT的制作:
- 成果展示与答辩准备:
在项目完成后,我参与了答辩PPT的制作,整理并展示了我们福卫兵的最终成果。

🌟 项目展望 🌟
随着社交媒体对舆情的影响日益加深,福州大学的舆情监测系统将不仅是一个实时数据分析平台,更将成为一个全面智能化的舆论预警工具。未来,我们计划进一步扩展系统的功能,结合更多AI技术与多平台数据源,打破传统的舆情监控方式,提前识别潜在风险,精准预测舆论走势。
-
舆情溯源与传播路径分析
未来的系统将能够追溯舆情事件的起源,分析其在社交媒体上的传播路径。通过识别信息源和影响力人物,我们可以更清晰地看到舆论的扩散过程,帮助校方快速应对并精准干预。 -
多语言支持与国际化扩展
随着学校的国际化步伐加快,系统将支持多语言舆情监测,尤其是在海外社交平台的舆论动态,帮助学校及时了解来自全球范围的舆情影响,做出更加科学的国际化决策。 -
情感预测与危机管理
除了实时情感分析,我们将引入情感预测模块,提前识别潜在的情绪波动趋势,及时提醒校方关注即将出现的舆论危机。通过模拟不同情境下的舆情变化,校方能够更好地进行危机管理和应对策略的制定。 -
智能推荐与策略优化
系统将根据分析结果,结合AI算法,自动为校方推荐应对策略,甚至在必要时给出调整宣传方向、优化社交媒体内容的建议,帮助学校提升舆论管理的效果和效率。
通过这些扩展和优化,福州大学的舆情监测系统将不再仅仅是一个“监控工具”,而是一个智慧决策平台,助力学校在复杂的舆情环境中做出更精准的判断与应对,为学校的形象和声誉保驾护航。
项目总结与感谢 🌟
项目总结:📊
这次舆情监控系统的开发让我收获了很多,也遇到了不少挑战。作为项目的一员,我的主要任务是负责数据采集与融合。整个过程让我更加深入地了解了如何从多个平台(如微博、知乎、贴吧等)抓取数据,并通过合理的方式进行清洗和融合,最终形成可用的数据集。
在数据采集的过程中,我不仅要应对不同平台的反爬虫机制,还需要对抓取到的数据进行预处理。尤其是在处理不同格式的数据时,我深刻体会到数据清洗的重要性。虽然中间遇到了一些技术难题,但通过反复调试和思考,最终都逐步解决了,这让我在技术能力上有了很大的提升。
数据采集与融合的收获 📚
-
数据采集的技巧:
学会了如何通过爬虫技术抓取不同平台的数据,这不仅仅是一个技术操作,更让我意识到每一条数据背后都有其独特的价值和意义。不同平台上的数据格式差异让我更清楚地认识到数据多样性对项目的影响,也让我明白了如何快速高效地抓取并处理这些数据。 -
多源数据的融合:
在项目中,我负责将来自不同平台的数据进行整合,这项工作不仅要求我有较强的技术能力,还需要在处理数据时保持足够的细致。如何将这些数据统一格式,去除无关信息并确保数据准确性,是我在项目中学习到的重要一环。每当看到数据成功融合并形成有意义的信息时,都会有一种成就感。 -
技术的整合与应用:
数据融合并非只是简单地将数据堆叠在一起,更重要的是理解每个数据来源的特点,并通过合适的方式进行整合。这项技能不仅仅是技术操作的提升,更让我更加注重数据的质量与可用性。在解决这些问题时,我不仅学到了如何应对技术难题,也提升了自己在团队协作中的应变能力。
对课程的感悟 💭
这门《数据采集与融合技术实践》课程让我从技术操作中学到了很多,也让我对数据的价值有了更深刻的理解。从数据的抓取到清洗,再到最后的融合分析,整个过程充满了探索与挑战,也让我意识到数据背后的重要性。课程不仅加深了我对数据处理的技术理解,也让我更清晰地认识到在实际项目中如何将这些技术应用于实践。
通过这门课程,我收获了很多实用的技能,也让我对未来在数据分析领域的学习和工作充满了期待。
特别感谢 💖
-
对自己的分工感恩:
感谢自己在数据采集与融合环节的坚持与努力。在这个过程中,我遇到了一些技术难题,但每一次调整和改进都让我更接近解决问题的答案。通过不断摸索,我最终成功地将来自不同平台的数据抓取并高效融合,顺利推动了项目的进展。 -
感谢团队的支持与合作:
非常感谢福卫兵团队中的每一位成员,他们的创意思维与不断坚持让我深感敬佩。我们每个人都在各自的岗位上付出了大量的心血,特别是在面对技术挑战时,团队成员们的帮助和智慧让我倍感温暖。正是大家的共同努力与无私协作,才能让项目在充满挑战的过程中得以顺利推进。🤝💪
3.特别感谢与我一起负责爬取数据的小伙伴 61:
也要特别感谢与我一起负责数据爬取的“61”同学,感谢你在整个数据抓取过程中与我并肩作战!你的技术支持和耐心帮助让我在遇到难题时能迅速找到解决方法。我们共同攻克了一个个技术难关,也因此收获了更多的默契与信任。🌈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号