数据采集第四次作业
数据采集实践第四次作业
目录
🌟 码云链接:作业4 · xh102202145/crawl_project
作业①:定向爬取沪深 A 股股票信息
1.1 实验要求
使用 Selenium 框架结合 MySQL 数据库存储技术,爬取东方财富网(沪深 A 股股票信息)的股票数据,包括股票代码、名称、最新报价、涨跌幅、成交量等信息,并将数据存储到 MySQL 数据库中。
1.2 实验思路
- 项目搭建:使用 Selenium 和 MySQL 创建项目,搭建 Selenium 环境,模拟浏览器操作。
- 数据爬取:通过模拟用户操作,动态加载数据,并使用 Selenium 查找 HTML 元素抓取股票信息。
- 数据存储:将抓取的股票信息存储到 MySQL 数据库中,设计合理的表结构。
- 数据输出:通过 MySQL 查询输出爬取的数据。
1.3 主要代码块
点击查看代码
# MySQL 配置
db_config = {
'host': 'localhost',
'user': 'root',
'password': 'xhXH040901@',
'database': 'xiehan'
}
# 连接到 MySQL 数据库
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
# 创建数据表,如果表不存在的话
cursor.execute("""
CREATE TABLE IF NOT EXISTS hs_a_stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(20),
bStockName VARCHAR(100),
latestPrice DECIMAL(10, 2),
changePercent DECIMAL(10, 2),
changeAmount DECIMAL(10, 2),
volume VARCHAR(50),
amount VARCHAR(50),
amplitude DECIMAL(10, 2),
highest DECIMAL(10, 2),
lowest DECIMAL(10, 2),
opening DECIMAL(10, 2),
lastClosing DECIMAL(10, 2)
)
""")
cursor.execute("""
CREATE TABLE IF NOT EXISTS sh_a_stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(20),
bStockName VARCHAR(100),
latestPrice DECIMAL(10, 2),
changePercent DECIMAL(10, 2),
changeAmount DECIMAL(10, 2),
volume VARCHAR(50),
amount VARCHAR(50),
amplitude DECIMAL(10, 2),
highest DECIMAL(10, 2),
lowest DECIMAL(10, 2),
opening DECIMAL(10, 2),
lastClosing DECIMAL(10, 2)
)
""")
cursor.execute("""
CREATE TABLE IF NOT EXISTS sz_a_stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(20),
bStockName VARCHAR(100),
latestPrice DECIMAL(10, 2),
changePercent DECIMAL(10, 2),
changeAmount DECIMAL(10, 2),
volume VARCHAR(50),
amount VARCHAR(50),
amplitude DECIMAL(10, 2),
highest DECIMAL(10, 2),
lowest DECIMAL(10, 2),
opening DECIMAL(10, 2),
lastClosing DECIMAL(10, 2)
)
""")
# 启动浏览器
driver = webdriver.Chrome()
# 网站链接
urls = [
"http://quote.eastmoney.com/center/gridlist.html#hs_a_board", # 沪深A股
"http://quote.eastmoney.com/center/gridlist.html#sh_a_board", # 上证A股
"http://quote.eastmoney.com/center/gridlist.html#sz_a_board" # 深证A股
]
# 表格名称
table_names = ['hs_a_stocks', 'sh_a_stocks', 'sz_a_stocks']
# 遍历三个网站,分别抓取数据并插入到不同的表格
for url, table_name in zip(urls, table_names):
driver.get(url)
# 等待表格加载完成
WebDriverWait(driver, 60).until(
EC.presence_of_element_located((By.ID, "table_wrapper-table"))
)
# 获取所有的表格行
rows = driver.find_elements(By.CSS_SELECTOR, "#table_wrapper-table tbody tr")
# 遍历每一行,提取数据并存储到 MySQL 数据库
for row in rows:
columns = row.find_elements(By.TAG_NAME, "td")
if len(columns) > 1:
stock_code = columns[1].text.strip()
stock_name = columns[2].text.strip()
latest_price = columns[4].text.strip()
change_percent = columns[5].text.strip().replace('%', '')
change_amount = columns[6].text.strip()
volume = columns[7].text.strip()
amount = columns[8].text.strip()
amplitude = columns[9].text.strip().replace('%', '')
highest = columns[10].text.strip()
lowest = columns[11].text.strip()
opening = columns[12].text.strip()
last_closing = columns[13].text.strip()
# 插入数据到对应的表格
cursor.execute(f"""
INSERT INTO {table_name} (bStockNo, bStockName, latestPrice, changePercent, changeAmount, volume, amount, amplitude, highest, lowest, opening, lastClosing)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (stock_code, stock_name, latest_price, change_percent, change_amount, volume, amount, amplitude, highest, lowest, opening, last_closing))
# 提交事务
conn.commit()
# 关闭数据库连接
cursor.close()
conn.close()
# 关闭浏览器
driver.quit()
print("数据抓取并存储完成!")
1.4 运行结果
股票信息成功抓取并存储到 MySQL 数据库中。通过查询数据库,确认信息已正确存储。
三个表如下:
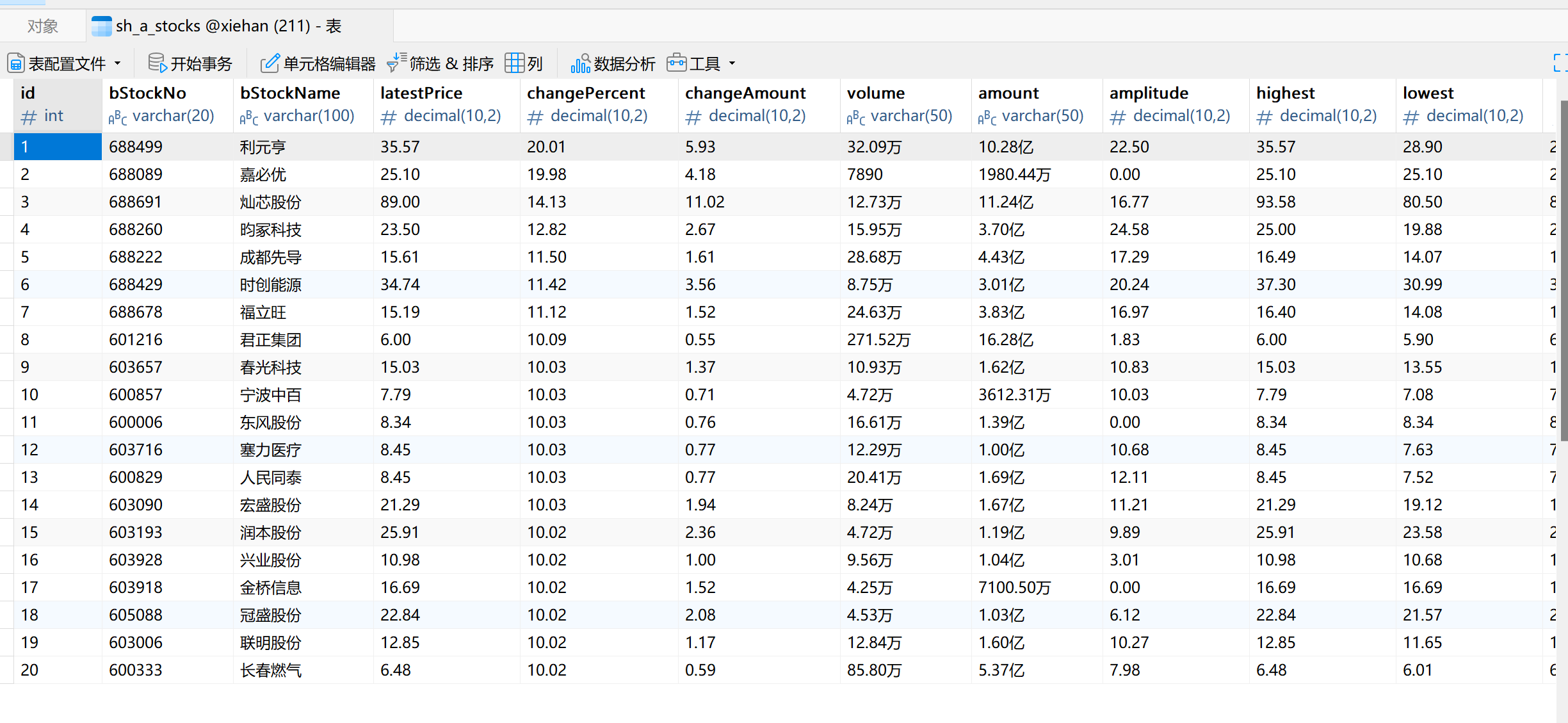
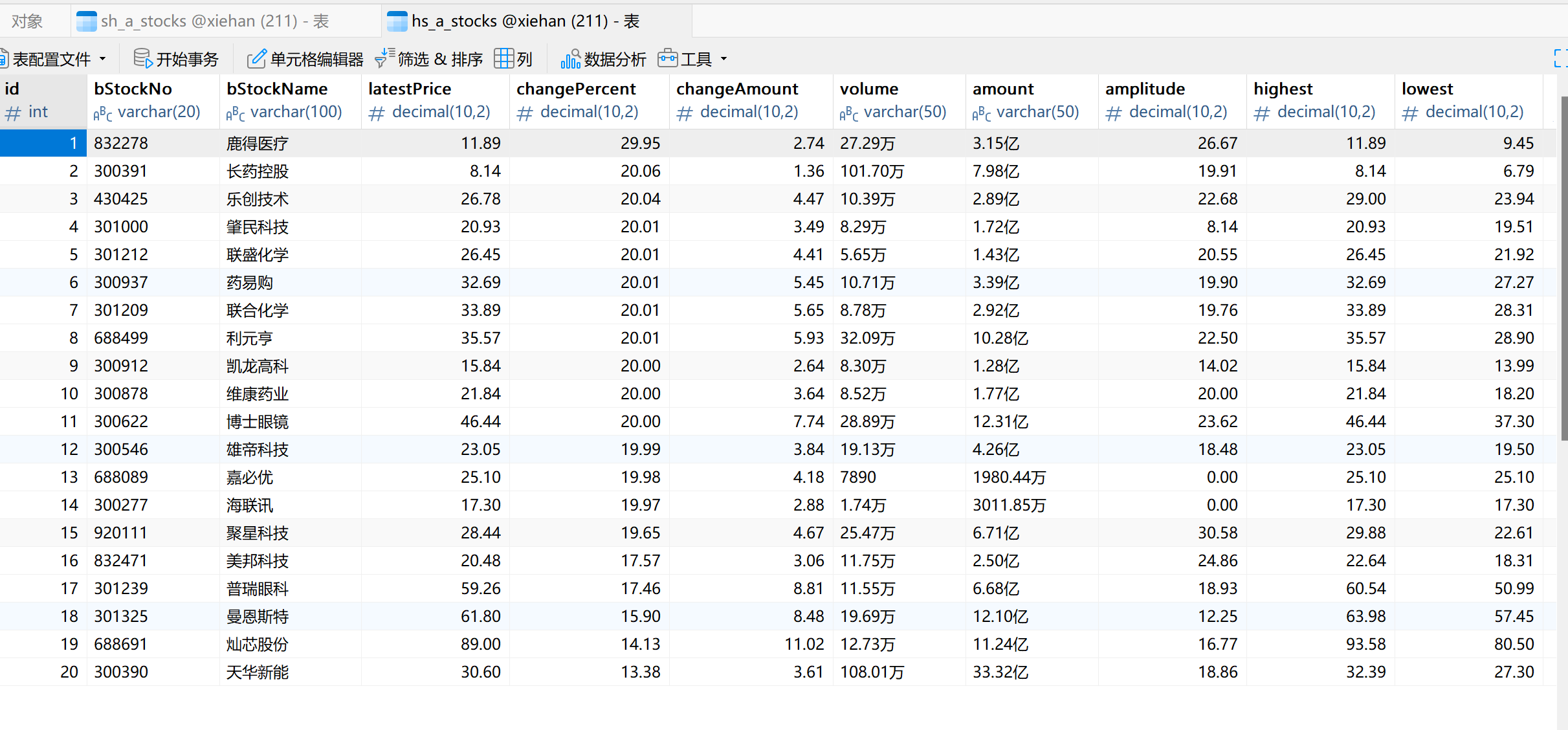
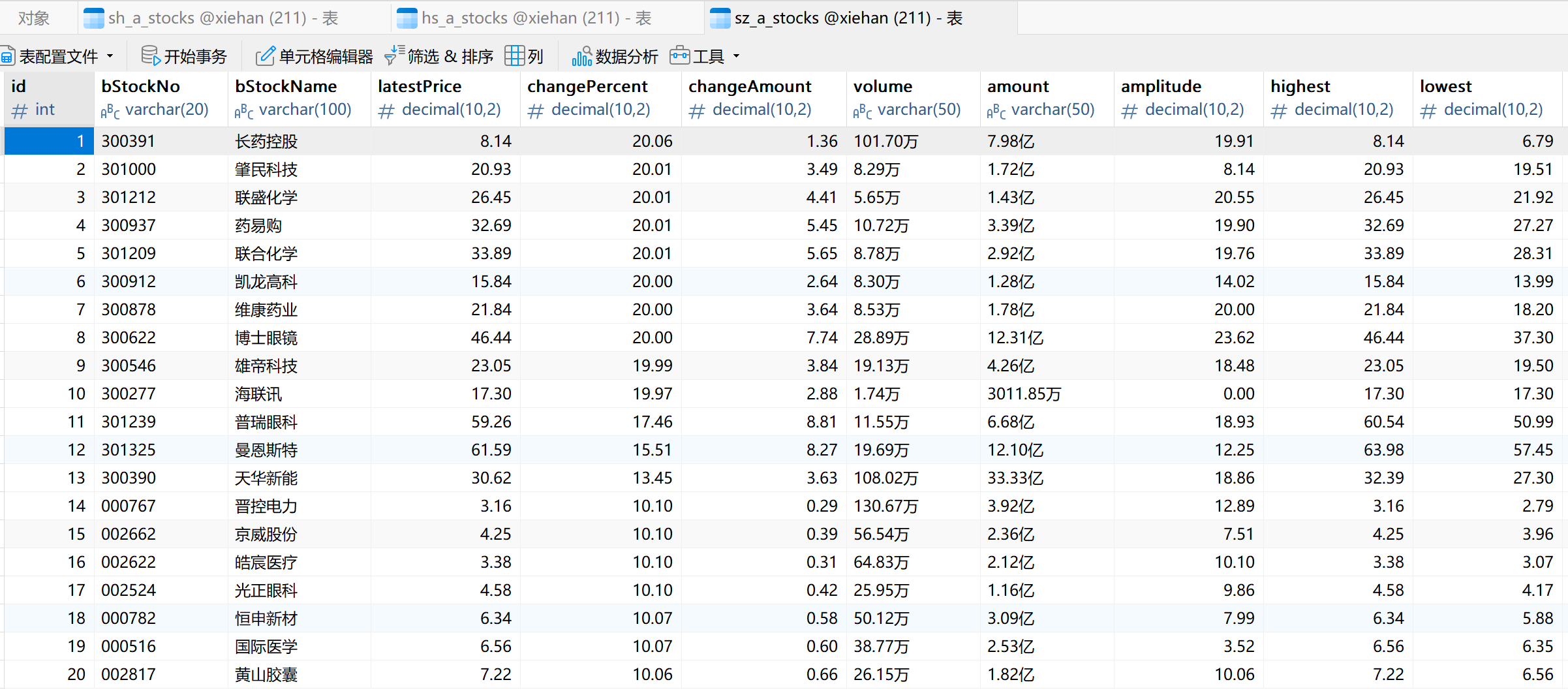
存储格式如下:
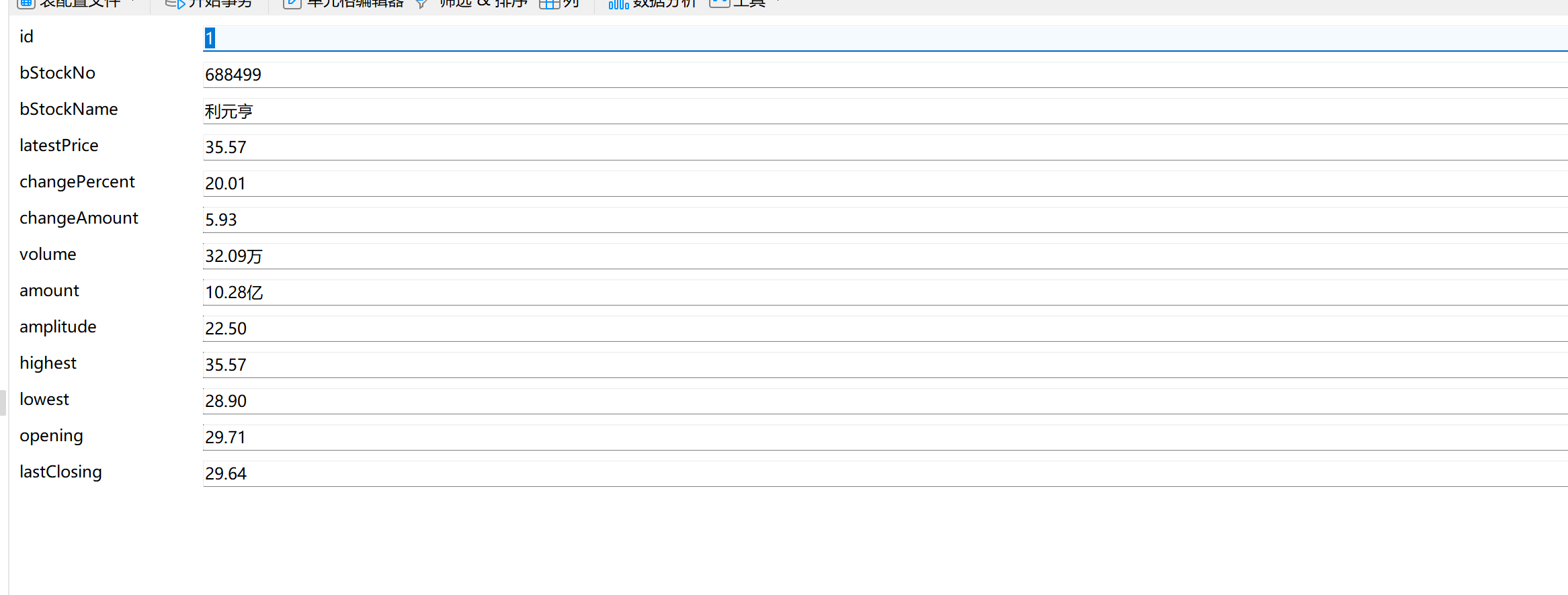
1.5 心得体会
通过本次作业,我掌握了使用 Selenium 查找 HTML 元素、模拟用户操作、等待 AJAX 网页数据加载等技巧。同时,也实践了如何将数据存储到 MySQL 数据库中。该技能为爬取动态加载页面的数据奠定了基础。
附录
Gitee 文件夹链接:作业4-第一题
作业②:定向爬取中国 MOOC 网课程信息
2.1 实验要求
使用 Selenium 框架爬取中国 MOOC 网(https://www.icourse163.org)的课程信息,包括课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介等内容,并将数据存储到 MySQL 数据库中。
2.2 实验思路
- 项目搭建:使用 Selenium 环境进行爬取,模拟用户登录并获取课程信息。
- 数据爬取:通过模拟登录,抓取课程页面的相关数据。
- 数据存储:将抓取的数据存储到 MySQL 数据库中,并设计合理的表结构。
- 数据输出:使用 SQL 查询输出爬取的数据。
2.3 主要代码块
点击查看代码
class CourseScraper:
def __init__(self, db_config, username, password):
self.db_config = db_config
self.username = username
self.password = password
self.conn = self.connect_to_db()
self.cursor = self.conn.cursor()
def connect_to_db(self):
"""连接数据库并返回连接对象"""
return mysql.connector.connect(
host=self.db_config["host"],
user=self.db_config["user"],
password=self.db_config["password"],
database=self.db_config["database"]
)
def close_db(self):
"""提交并关闭数据库连接"""
self.conn.commit()
self.cursor.close()
self.conn.close()
def login(self, driver):
"""登录平台"""
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))).click()
iframe = WebDriverWait(driver, 10).until(EC.presence_of_element_located(
(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')))
driver.switch_to.frame(iframe)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(self.username)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(self.password)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
def fetch_course_info(self, driver, index):
"""获取课程信息"""
course_info = driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{index+1}]/div/div[3]/div[1]').text.split("\n")
driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{index+1}]').click()
driver.switch_to.window(driver.window_handles[-1])
# 获取其他信息
team_elements = driver.find_elements(By.XPATH, '//*[@class="f-fc3"]')
course_info.append(','.join([t.text for t in team_elements]))
count = driver.find_element(By.XPATH, '//*[@class="count"]').text if driver.find_elements(By.XPATH, '//*[@class="count"]') else "已有0人参加"
course_info.append(count[2:-3])
date = driver.find_element(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text if driver.find_elements(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]') else "无"
course_info.append(date)
brief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
course_info.append(brief)
return course_info
def insert_course_to_db(self, course_info):
"""插入数据到数据库"""
sql = """
INSERT INTO big_data_and_ai_courses (cCourse, cCollege, cTeacher, cInstructor, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, course_info)
def scrape_courses(self, driver, pages=3, courses_per_page=20):
"""抓取课程并插入数据库"""
for page in range(pages):
for index in range(courses_per_page):
try:
course_info = self.fetch_course_info(driver, index)
self.insert_course_to_db(tuple(course_info))
driver.close()
driver.switch_to.window(driver.window_handles[-1])
except Exception as e:
print(f"抓取课程时发生错误: {e}")
driver.close()
driver.switch_to.window(driver.window_handles[-1])
# 翻页操作
try:
next_page_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[5]')))
next_page_button.click()
time.sleep(2)
except Exception as e:
print(f"翻页时发生错误: {e}")
break
def main():
db_config = {
"host": "localhost",
"user": "root",
"password": os.getenv("DB_PASSWORD", "default_password"),
"database": "xiehan"
}
username = "18750736901"
password = "xhxhxh040901"
# 启动浏览器
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
driver.get("https://www.icourse163.org/")
scraper = CourseScraper(db_config, username, password)
# 登录
scraper.login(driver)
time.sleep(5)
driver.switch_to.default_content()
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="privacy-ok"]'))).click()
# 进入课程页面
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[1]/div[5]/span[2]/a[1]'))).click()
driver.switch_to.window(driver.window_handles[-1])
# 抓取课程数据
scraper.scrape_courses(driver)
# 提交数据库修改并关闭连接
scraper.close_db()
# 关闭浏览器
driver.quit()
if __name__ == "__main__":
main()
2.4 运行结果
课程信息成功抓取并存储到 MySQL 数据库中。通过查询数据库,确认信息已正确存储。
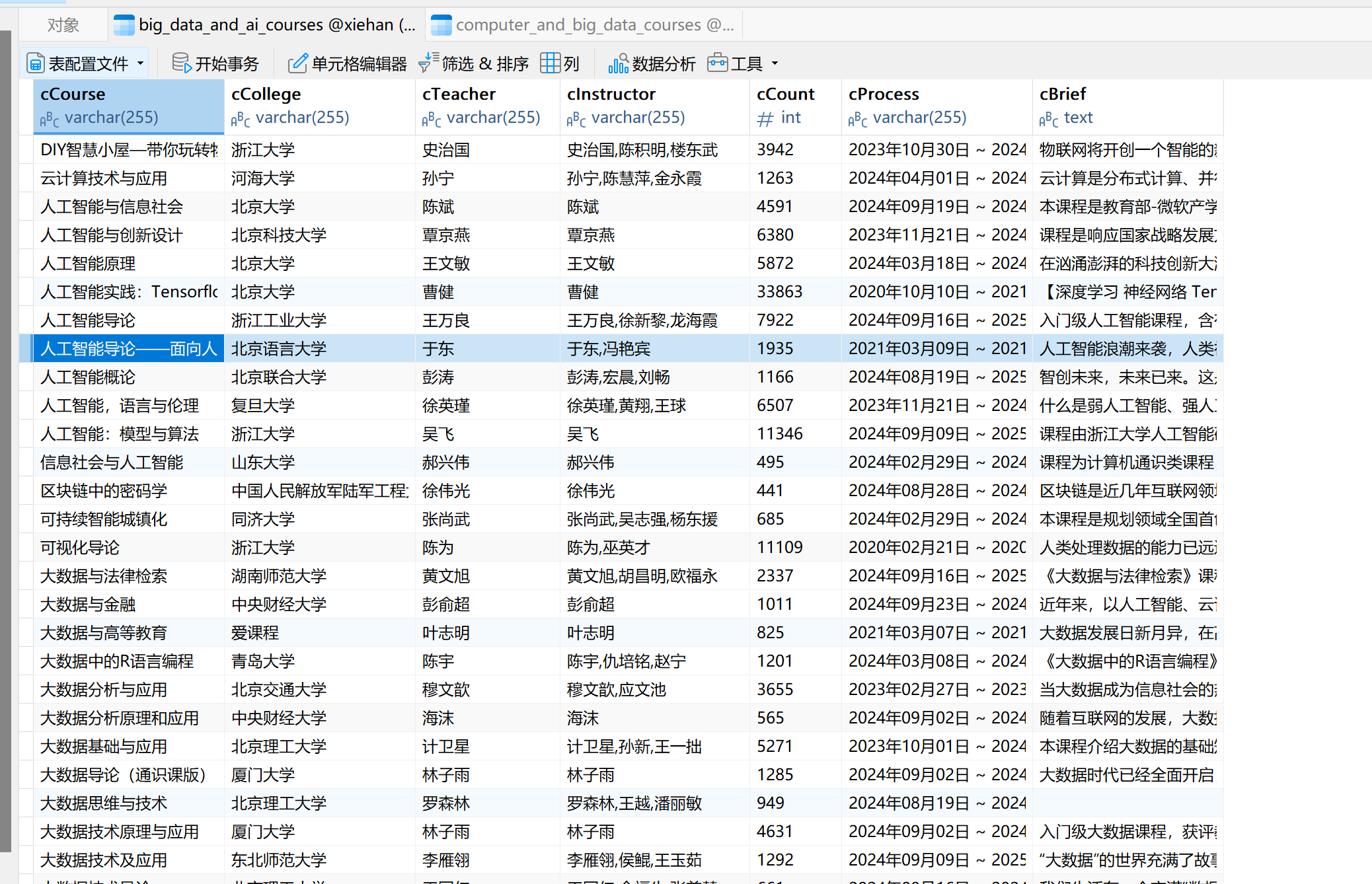
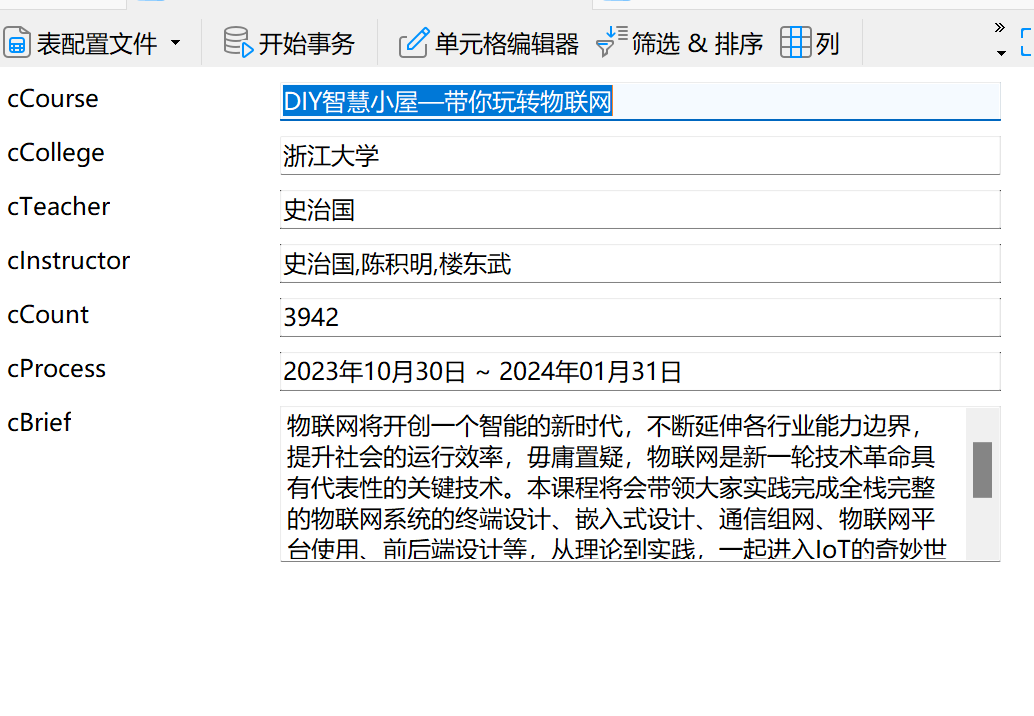
2.5 心得体会
在实现这个爬虫项目的过程中,最困难的部分是处理动态加载的网页内容。尤其是在登录后,课程信息是通过 Ajax 异步加载的,导致抓取过程中常常遇到页面元素未加载完全的情况。为了解决这个问题,我使用了 Selenium 的 WebDriverWait 和 expected_conditions 来确保每个页面元素在操作之前已经加载完成。虽然这种方式提高了程序的稳定性,但依然需要在一些复杂页面的交互中反复调试,确保每一步操作都能够顺利执行。
附录
Gitee 文件夹链接:作业4-第二题
作业③:大数据实时分析处理实验报告
一、华为云环境准备
任务一:申请弹性公网IP

任务二:开通MapReduce服务
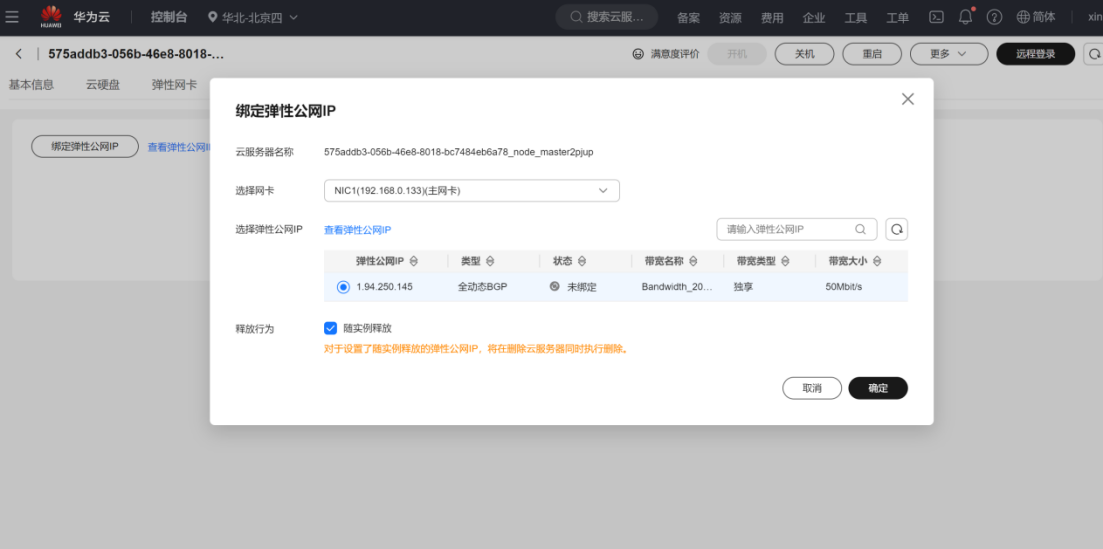
任务三:绑定弹性公网IP
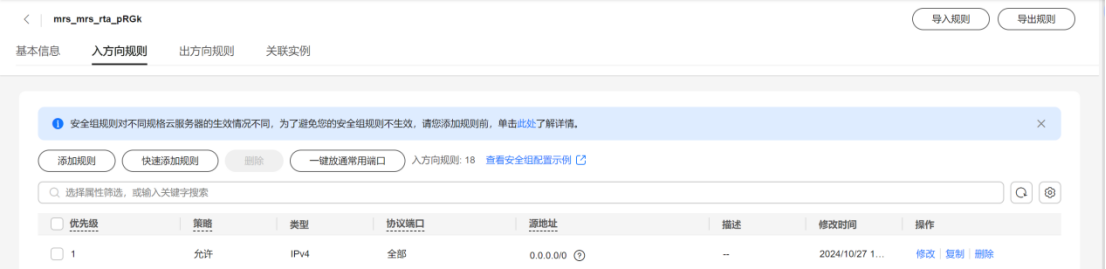
任务四:添加安全组规则
- 进入“安全组”管理,选择需要添加规则的安全组。
- 添加入站和出站规则,确保允许MapReduce、Kafka和Flume所需端口的通信。
二、大数据实时分析开发实战
任务一:Python脚本生成测试数据
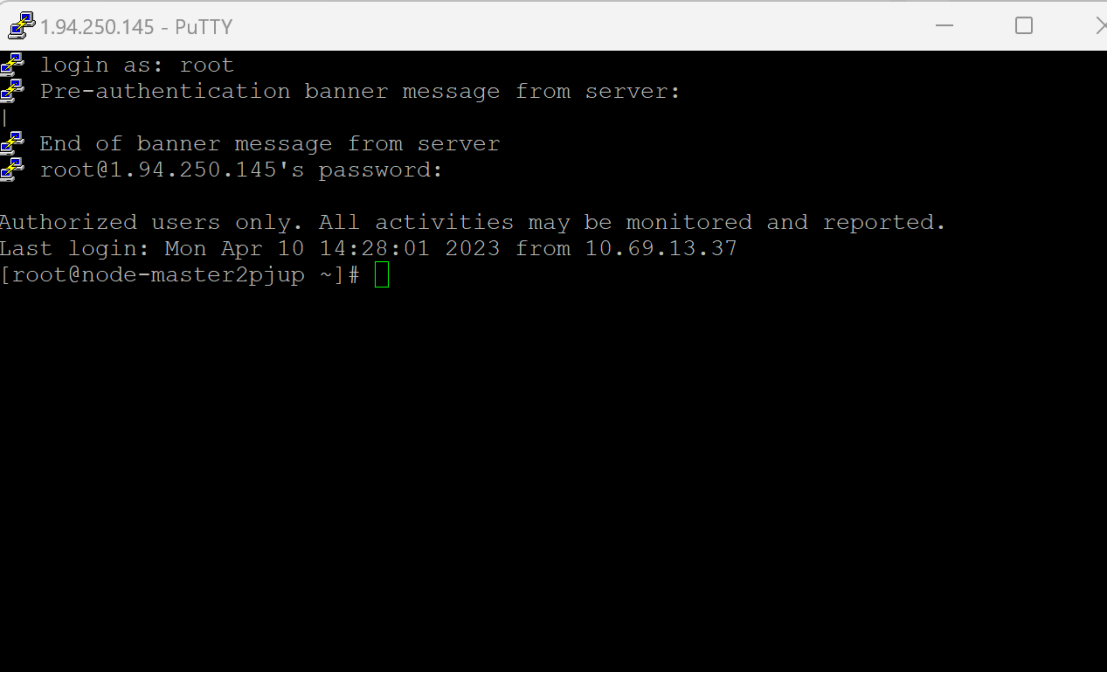
步骤1:登录MRS的Master节点服务器
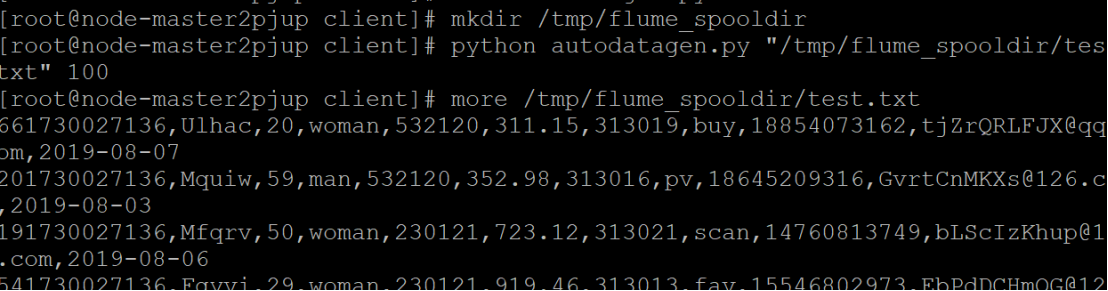
步骤2:编写Python脚本
-
在Master节点上编写Python脚本,生成测试数据。

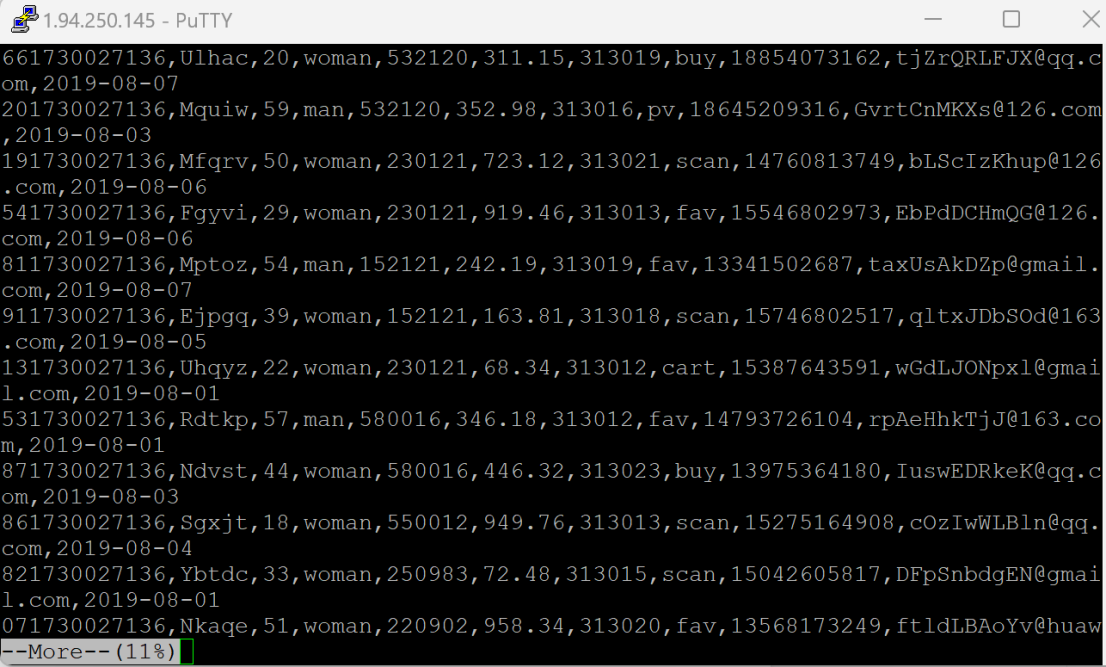
-
使用
more命令查看生成的数据,确保数据正确生成。
任务二:下载安装并配置Kafka
步骤1:前往MRS集群概览页面
- 在MRS集群概览页面,点击“前往Manager”进入MRS集群管理界面。
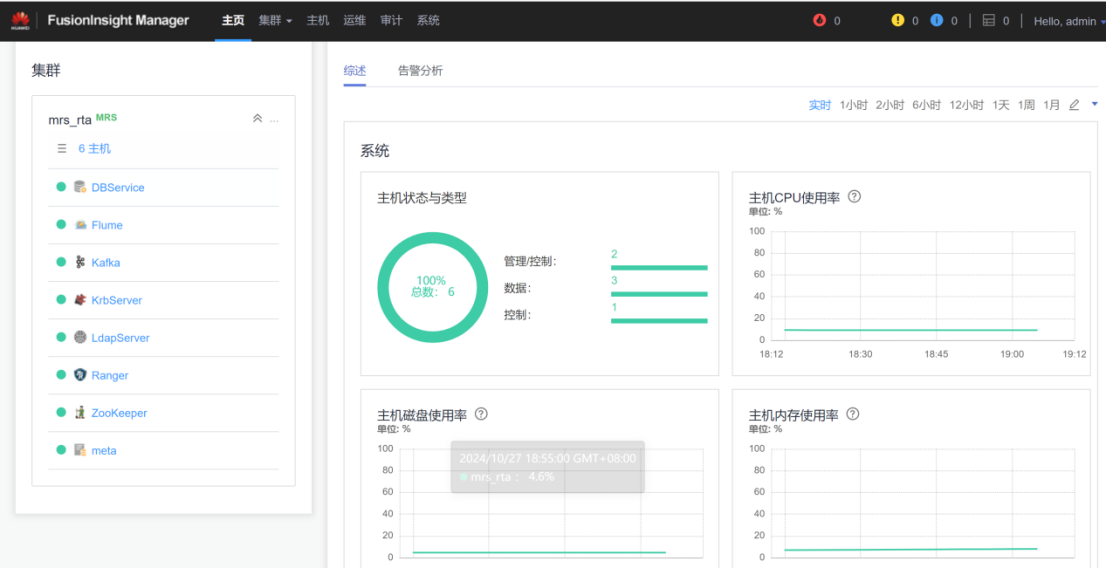
登录MRS集群管理界面
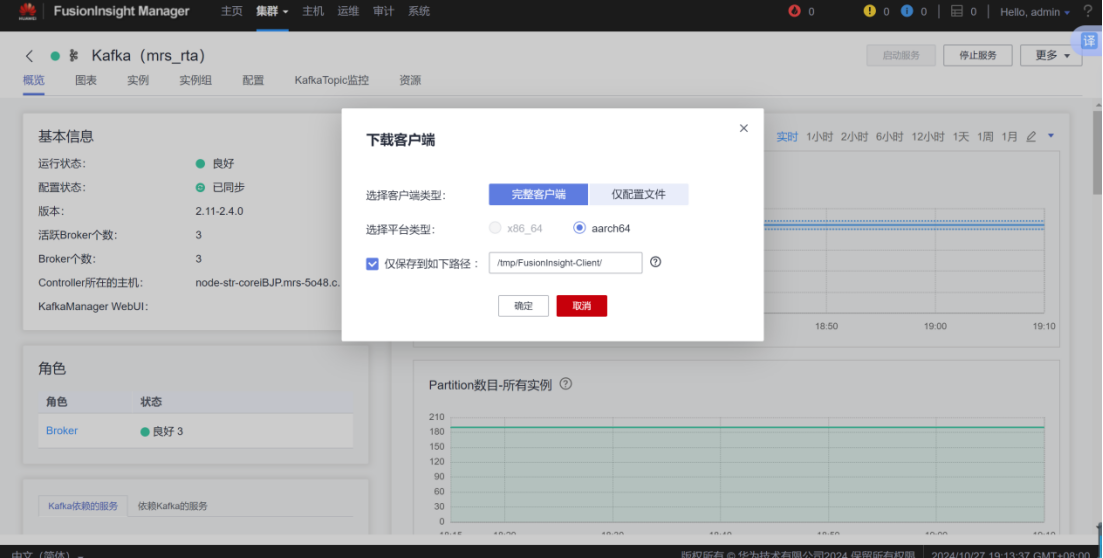
步骤2:下载Kafka客户端
-
下载Kafka客户端的安装包。
-
校验下载的客户端文件包,确保文件完整。

解压与校验:
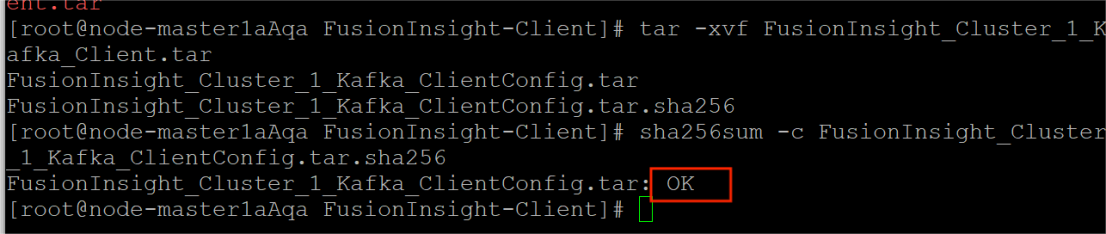
界面显示如上信息,表明文件包校验成功。
步骤3:解压并安装Kafka
- 解压Kafka客户端安装包。
安装Kafka运行环境
查看解压后文件。
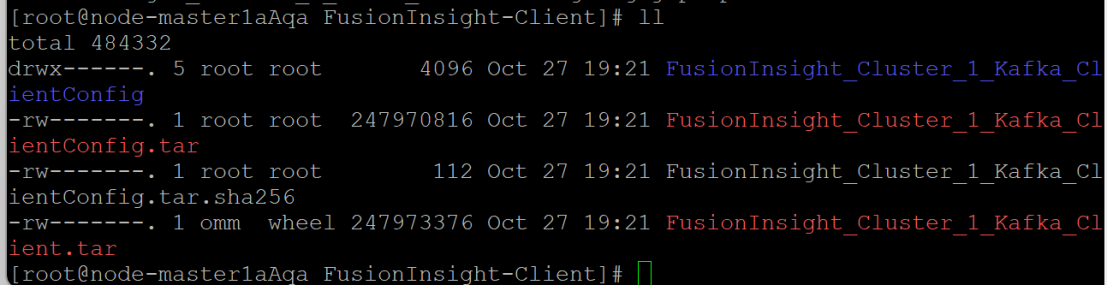
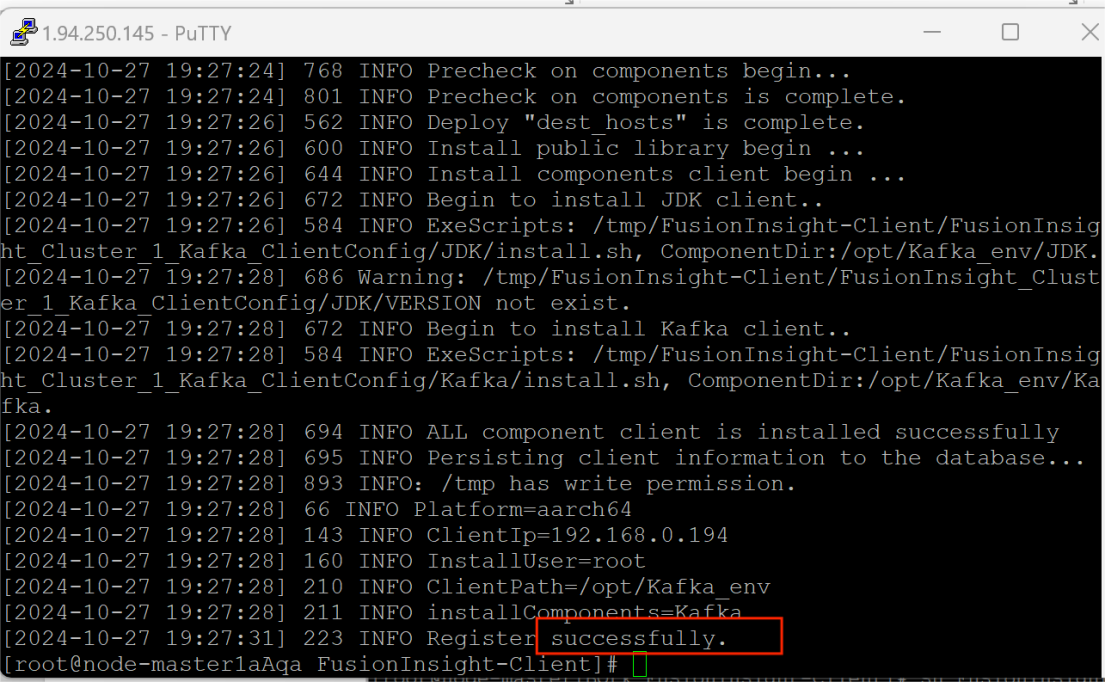
显示安装成功
2. 安装Kafka运行环境,配置环境变量,并将Kafka安装到指定目录(/opt/KafkaClient)。

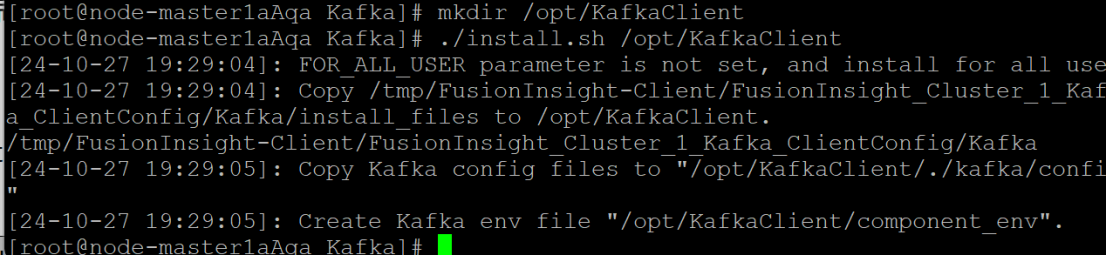
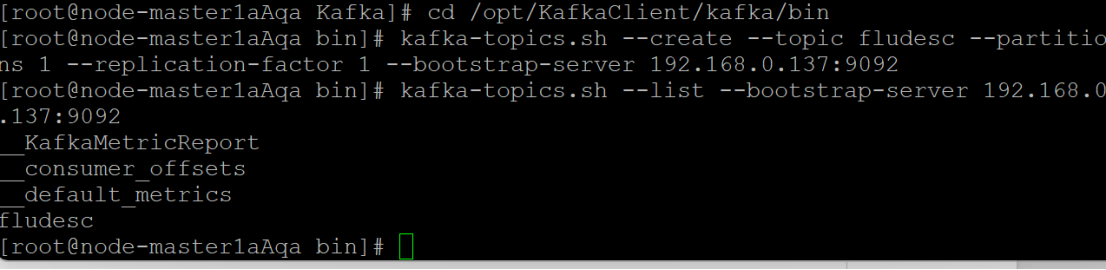
步骤4:在Kafka中创建Topic
- 创建一个新的Kafka Topic,用于消息传递。
- 查看Topic信息,确保创建成功。
任务三:安装Flume客户端
步骤1:下载并校验Flume客户端
- 下载Flume客户端安装包并进行校验,确保文件包完整。
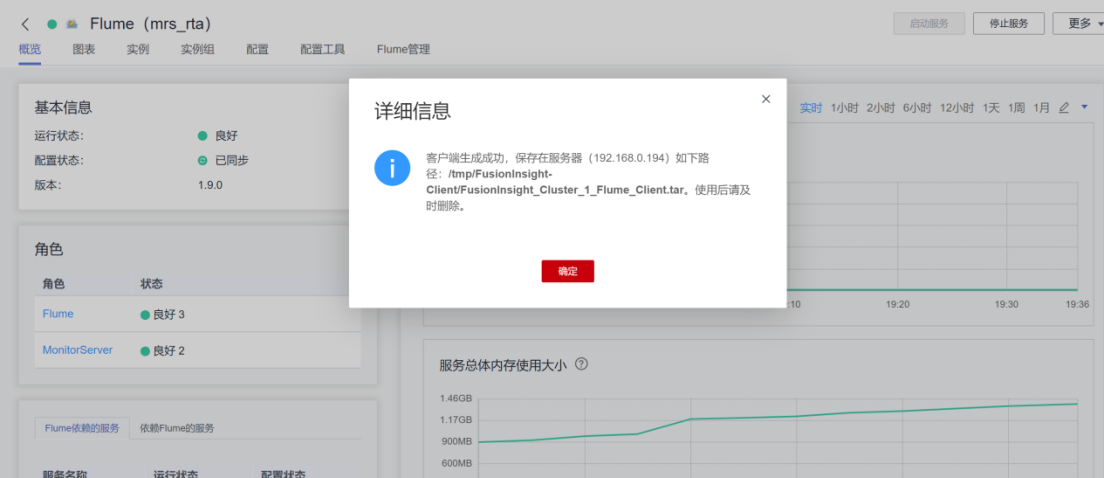
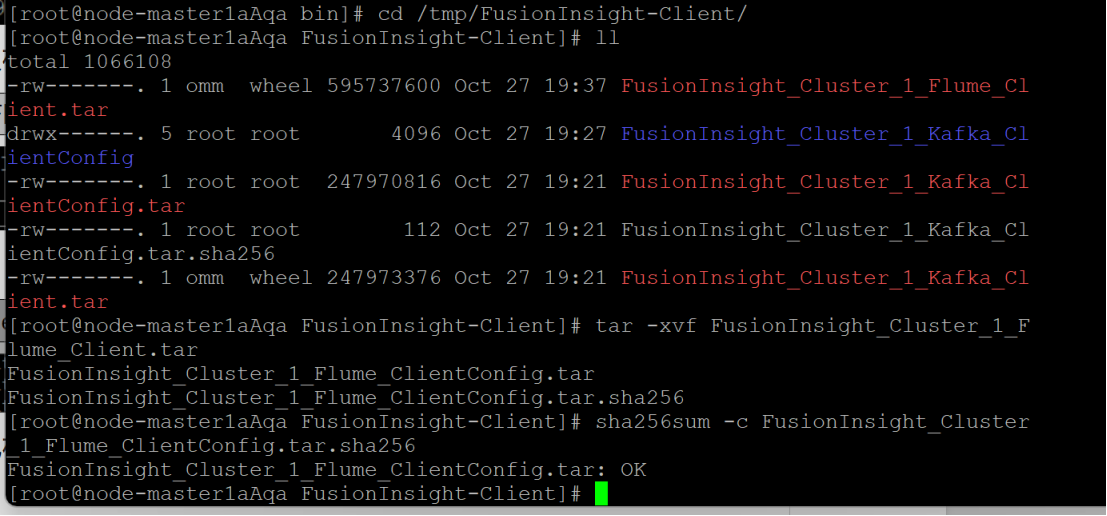
界面显示如上信息,表明文件包校验成功。
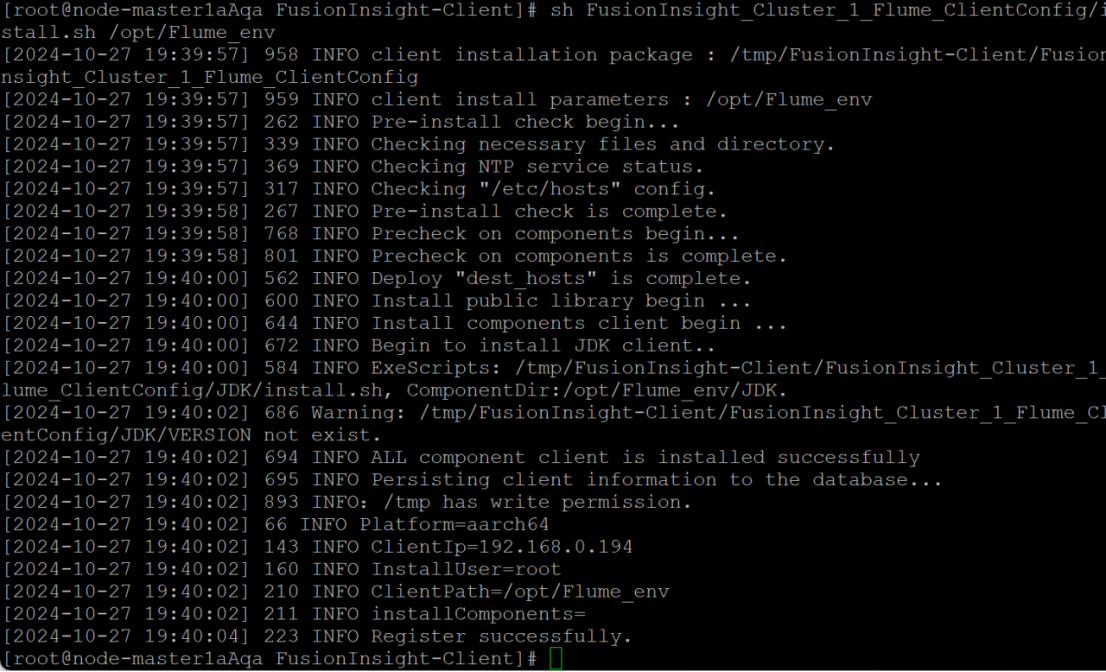
步骤2:安装Flume运行环境
-
解压并安装Flume客户端,配置环境变量。

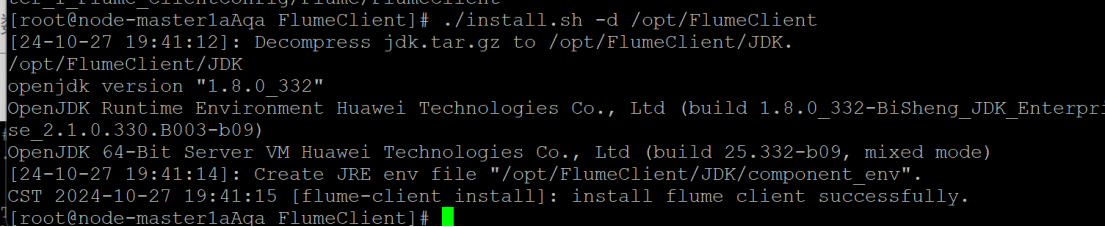
-
安装完成后重启Flume服务。

任务四:配置Flume采集数据
步骤1:修改Flume配置文件
- 修改Flume配置文件,设置数据来源为Kafka,目标为HDFS。

步骤2:创建消费者消费Kafka中的数据
-
配置Flume消费者,从Kafka Topic中消费数据。
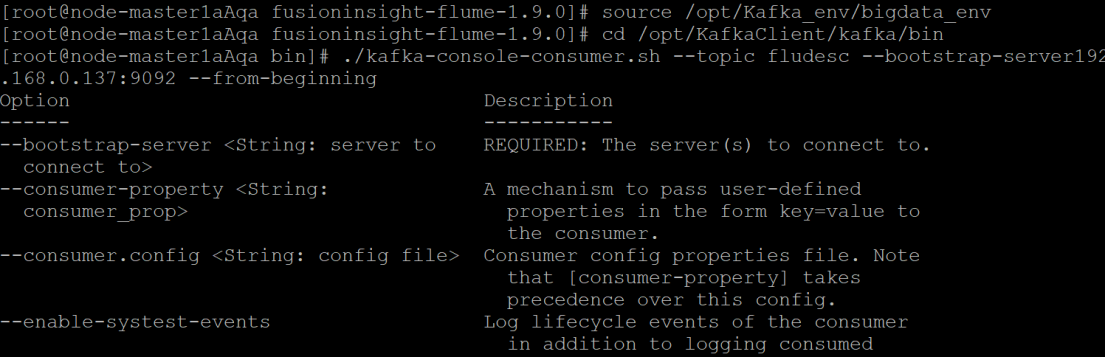

-
启动Flume并验证数据是否成功采集。
查看原窗口,可以看到已经消费出了数据:
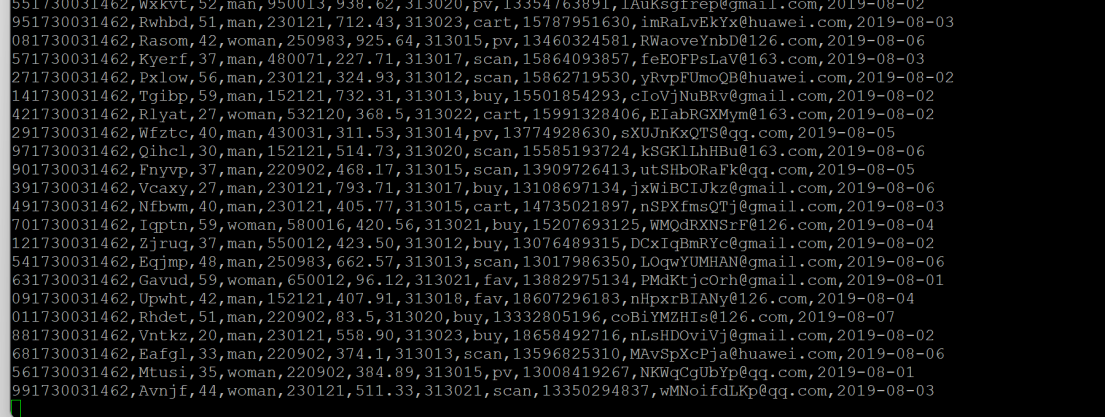
有数据产生,表明Flume到Kafka目前是打通的。
结果截图
- 测试完毕后,在新窗口输入
exit关闭消费者窗口。 - 在原窗口输入
Ctrl+c退出Flume进程。

结论
通过本实验,成功完成了华为云环境的配置,搭建了MapReduce、Kafka和Flume的环境,并实现了数据采集与分析的基本功能。实验结果符合预期,数据流从Flume到Kafka的传输与采集工作顺利完成。
3.5 心得体会
通过本次实验,我掌握了如何使用 Xshell 配置大数据服务,并完成了 Flume 日志采集的配置。掌握 Kafka、Flume 等工具的使用,提升了我在大数据实时分析处理领域的技能。
总结
本次作业涉及 Selenium 的使用、MySQL 数据存储、大数据服务配置等多个方面,提升了我的数据爬取、存储以及大数据处理能力。通过实验,我更深入理解了如何在动态网页上抓取数据、模拟用户登录、配置 Kafka 和 Flume 等工具,为日后在数据采集与处理方面的工作积累了宝贵经验。
附录
Gitee 文件夹链接:作业4-作业文件
😊 感谢阅读!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号