数据采集实践第三次作业
数据采集实践第三次作业
目录
点击展开/收起
🌟 码云链接:作业3 · xh102202145/crawl_project
作业①:定向爬取网站所有图片
1.1 实验要求
使用 Scrapy 框架,分别以单线程和多线程的方式,从指定网站(如中国气象网:http://www.weather.com.cn)爬取所有图片。务必控制总页数(学号尾数2位)和总下载图片数量(尾数后3位)等限制爬取的措施。
1.2 实验思路
-
项目搭建:使用 Scrapy 创建项目,定义用于图片爬取的爬虫类。
-
限制控制:根据学号尾数设置总页数和总下载图片数量,通过在代码中传递参数和设置计数器实现。
-
单线程与多线程实现:
- 单线程:使用 Scrapy 默认配置,逐页爬取图片。
- 多线程:修改 Scrapy 的配置文件
settings.py,调整CONCURRENT_REQUESTS等参数,实现多线程并发爬取。
-
图片存储:利用 Scrapy 提供的
ImagesPipeline,实现图片的下载和存储,保存到项目的images目录下。 -
输出信息:在控制台输出下载的图片 URL,并保存运行过程的截图作为实验结果。
1.3 主要代码块
以下是爬虫的主要代码部分:
点击查看代码
import scrapy
from scrapy import Request
from myproject.items import WeatherImagesItem
class WeatherImagesSpider(scrapy.Spider):
name = 'weather_images'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
def __init__(self, total_pages=45, total_images=145, *args, **kwargs):
super(WeatherImagesSpider, self).__init__(*args, **kwargs)
self.total_pages = int(total_pages)
self.total_images = int(total_images)
self.image_count = 0
self.downloaded_urls = set()
def parse(self, response):
if self.image_count >= self.total_images:
return
# 提取页面中的所有图片 URL
img_selectors = response.xpath('//img')
for img in img_selectors:
if self.image_count >= self.total_images:
break
img_url = img.xpath('@src').get()
if not img_url:
img_url = img.xpath('@data-src').get()
if not img_url:
img_url = img.xpath('@data-original').get()
if img_url:
# 处理相对 URL
if img_url.startswith('//'):
img_url = 'http:' + img_url
elif img_url.startswith('/'):
img_url = response.urljoin(img_url)
elif not img_url.startswith('http'):
img_url = response.urljoin('/' + img_url)
# 去重
if img_url in self.downloaded_urls:
continue
self.downloaded_urls.add(img_url)
self.image_count += 1
yield WeatherImagesItem(image_urls=[img_url])
self.logger.info(f"下载图片 URL: {img_url}")
# 翻页逻辑
current_page = response.meta.get('page', 1)
if current_page < self.total_pages:
next_page = current_page + 1
next_url = f'http://www.weather.com.cn/page/{next_page}.shtml'
yield Request(url=next_url, callback=self.parse, meta={'page': next_page})
✨ 说明:
- 构造函数
__init__:接受total_pages和total_images两个参数,用于限制总页数和总下载图片数量。 - 图片提取和下载:使用 XPath 提取页面中的图片 URL,处理相对路径,避免重复下载。
- 翻页处理:根据当前页数和总页数限制,生成下一页的请求。
1.4 运行结果
单线程模式
在命令行中运行以下命令,以单线程模式启动爬虫:
scrapy crawl weather_images -a total_pages=45 -a total_images=145
多线程模式
在项目的 settings.py 文件中,设置 CONCURRENT_REQUESTS 为 16,启用多线程:
CONCURRENT_REQUESTS = 16
然后运行相同的命令启动爬虫:
scrapy crawl weather_images -a total_pages=45 -a total_images=145
运行截图
以下是运行爬虫时的控制台输出截图:
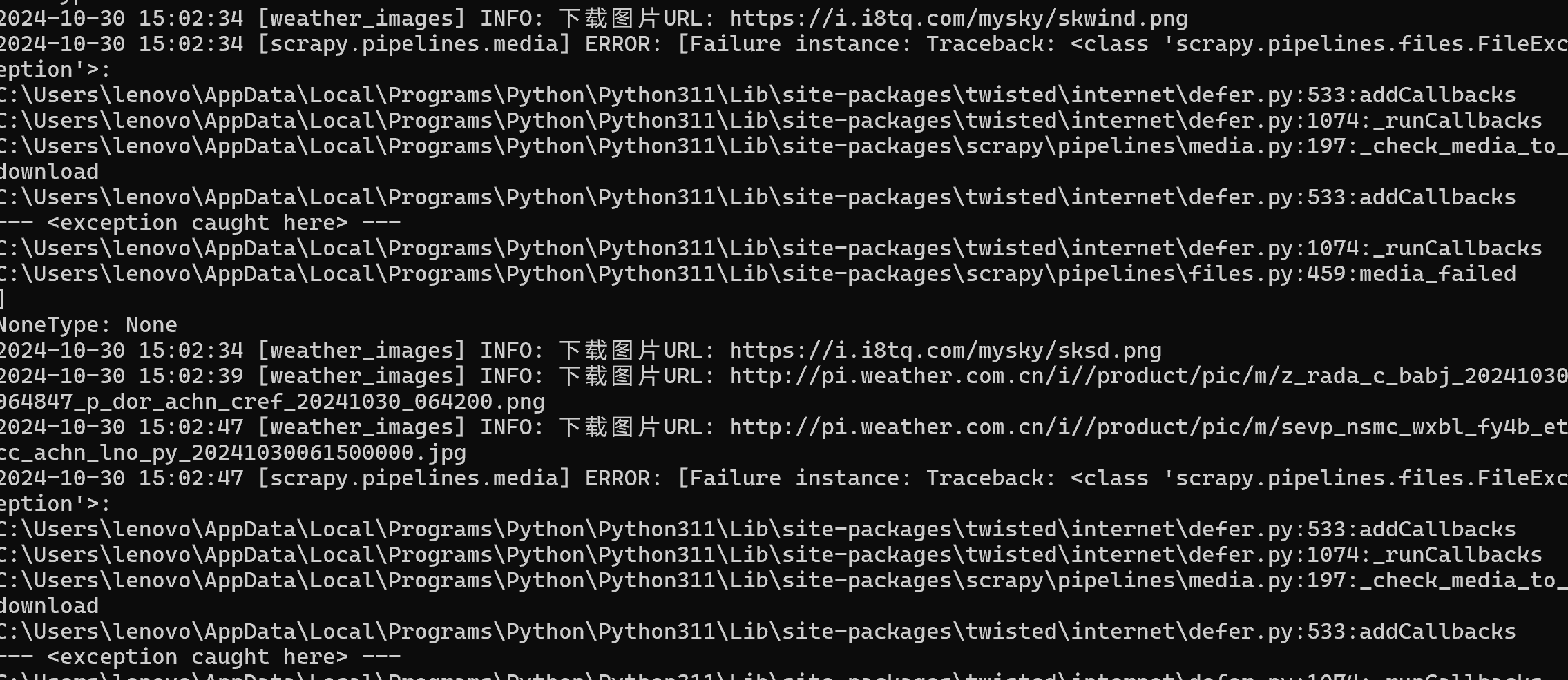
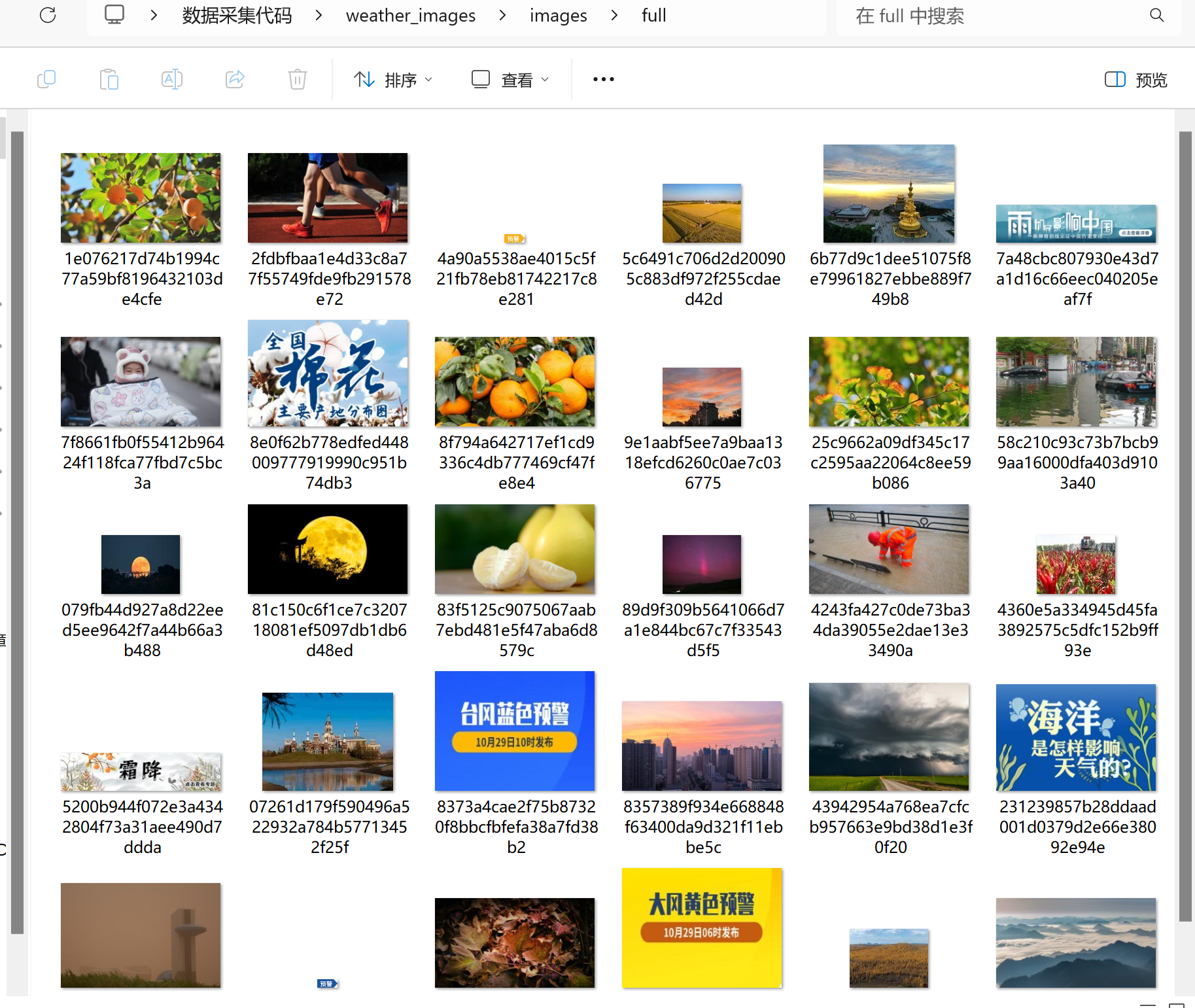
下载的图片成功存储在 images 文件夹中,部分下载的图片示例:
1.5 心得体会
通过本次实验,我对 Scrapy 框架有了更深入的了解,尤其是在定向爬取图片方面的应用。使用 Scrapy 的 ImagesPipeline,可以方便地实现图片的下载和存储,简化了爬虫的编写工作。😄
在实现单线程和多线程的过程中,我体会到了多线程对于提高爬取效率的重要性。通过调整 CONCURRENT_REQUESTS 等配置,可以显著提升爬虫的并发性能,加快图片的下载速度。但同时也要注意对目标网站的影响,避免过度请求导致服务器压力过大。🤔
此外,在控制爬取范围方面,通过在代码中设置总页数和总下载图片数量的限制,避免了过度抓取,符合爬虫的礼貌原则。这也让我意识到,编写爬虫时需要充分考虑对目标网站的友好性,遵守相关的爬取规范。👍
总体而言,本次实验让我更加熟悉了 Scrapy 框架的使用方法,以及如何高效、规范地实现网页信息的爬取。这些经验对我今后的学习和实践都有很大的帮助。💪
附录
Gitee 文件夹链接:作业3-第一题
作业②:定向爬取股票相关信息
2.1 实验要求
使用 Scrapy 框架结合 XPath 和 MySQL 数据库存储技术,从东方财富网(https://www.eastmoney.com/)爬取股票相关信息。熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法。
2.2 实验思路
-
项目搭建:
- 使用 Scrapy 创建项目。
- 定义用于存储股票信息的
Item类。 - 编写爬虫
stock_spider。
-
数据爬取:
- 分析东方财富网的股票数据页面,确定数据源 URL(例如:https://quote.eastmoney.com/center/)。
- 使用 Scrapy 的
Request方法请求数据页面。
-
数据解析:
- 使用 XPath 提取所需的股票信息字段,如股票代码、名称、最新报价、涨跌幅等。
- 在
parse方法中迭代解析股票信息。
-
数据存储:
- 配置 MySQL 数据库连接信息,包括主机、数据库名、用户名和密码。
- 定义
Pipeline,在其中将解析后的数据写入 MySQL 数据库。
-
序列化输出:
- 通过
Item和Pipeline实现数据的序列化和存储。 - 在
process_item方法中执行数据库插入操作。
- 通过
-
输出信息:
- 在数据库中查看存储的股票信息。
- 使用 SQL 或其他工具进行数据的格式化输出和验证。
2.3 主要代码块
点击查看代码
# stock_spider.py
import scrapy
from scrapy import Request
from myproject.items import StockInfoItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['eastmoney.com']
start_urls = ['https://quote.eastmoney.com/center/']
def parse(self, response):
# 提取股票信息
stocks = response.xpath('//div[@class="quote-table"]//tr')
for stock in stocks:
item = StockInfoItem()
item['stock_code'] = stock.xpath('./td[1]/text()').get()
item['stock_name'] = stock.xpath('./td[2]/text()').get()
item['latest_price'] = stock.xpath('./td[3]/text()').get()
item['change_rate'] = stock.xpath('./td[4]/text()').get()
yield item
# 处理翻页
next_page = response.xpath('//a[@class="next-page"]/@href').get()
if next_page:
yield Request(url=response.urljoin(next_page), callback=self.parse)
# pipelines.py
import mysql.connector
from scrapy.exceptions import DropItem
from myproject.settings import MYSQL_HOST, MYSQL_DATABASE, MYSQL_USER, MYSQL_PASSWORD
class StockInfoPipeline:
def open_spider(self, spider):
# 打开数据库连接
self.conn = mysql.connector.connect(
host=MYSQL_HOST,
user=MYSQL_USER,
password=MYSQL_PASSWORD,
database=MYSQL_DATABASE,
auth_plugin='mysql_native_password'
)
self.cursor = self.conn.cursor()
spider.logger.info('数据库连接已打开')
def close_spider(self, spider):
# 关闭数据库连接
self.conn.commit()
self.cursor.close()
self.conn.close()
spider.logger.info('数据库连接已关闭')
def process_item(self, item, spider):
try:
# 将数据写入数据库
self.cursor.execute(
"""
INSERT INTO stock_data (stock_code, stock_name, latest_price, change_rate)
VALUES (%s, %s, %s, %s)
""",
(item['stock_code'], item['stock_name'], item['latest_price'], item['change_rate'])
)
self.conn.commit()
spider.logger.debug(f"插入数据成功:{item['stock_code']} - {item['stock_name']}")
except mysql.connector.Error as err:
spider.logger.error(f"插入数据失败:{err}")
raise DropItem(f"插入数据失败:{err}")
return item
# items.py
import scrapy
class StockInfoItem(scrapy.Item):
stock_code = scrapy.Field()
stock_name = scrapy.Field()
latest_price = scrapy.Field()
change_rate = scrapy.Field()
# settings.py
MYSQL_HOST = 'localhost'
MYSQL_DATABASE = 'stock_db'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'password'
2.4 运行结果
终端运行截图:
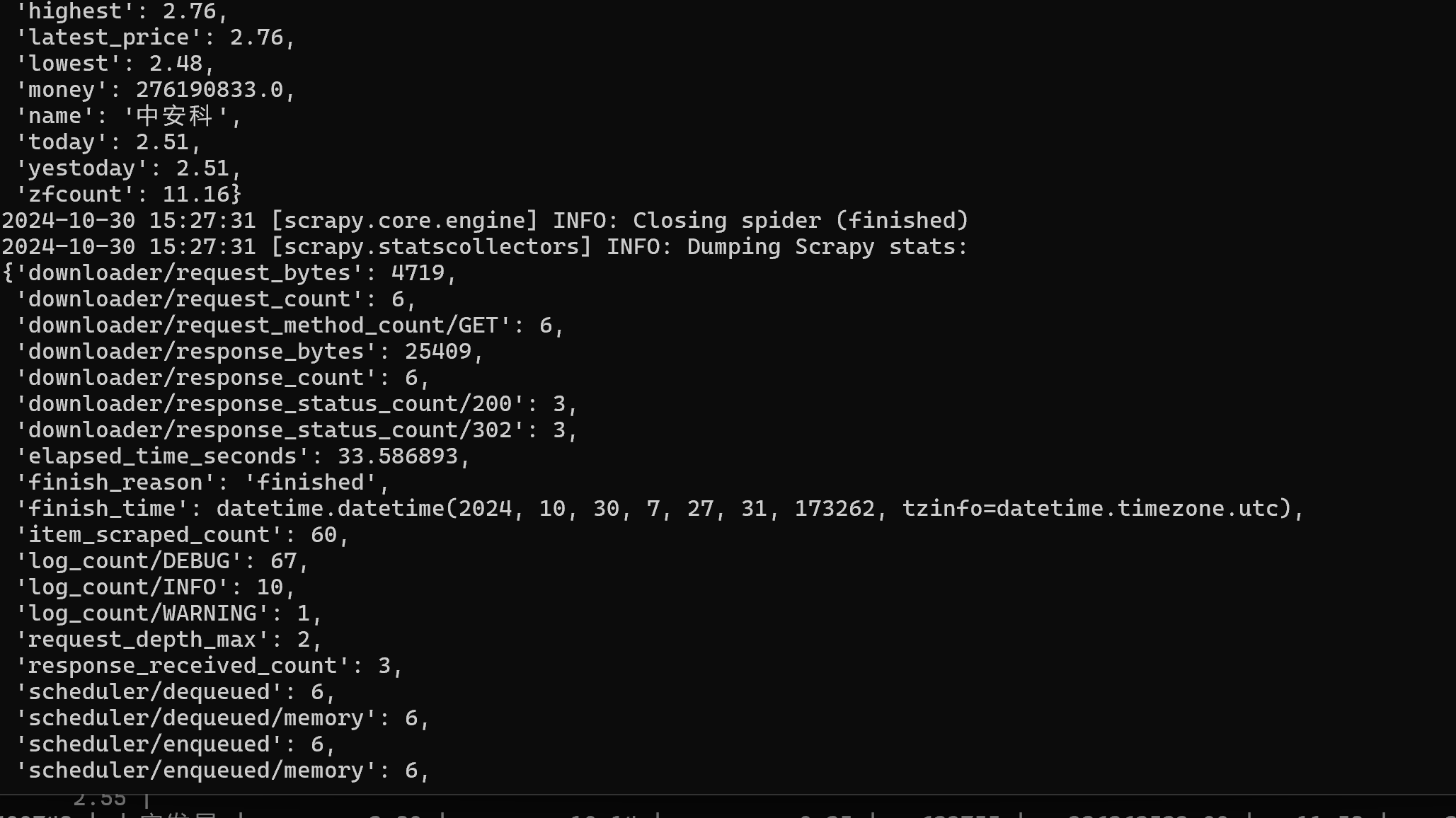
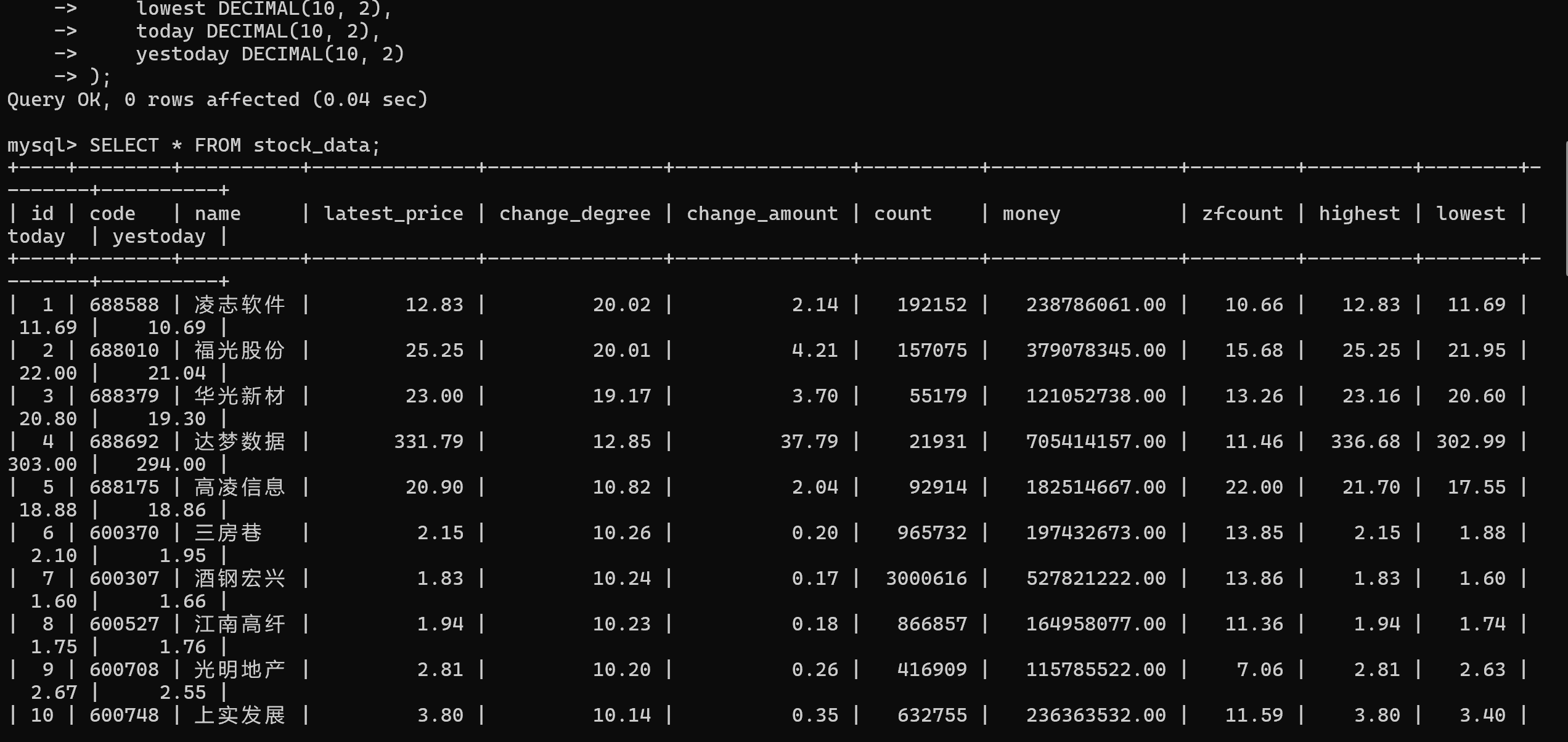
股票数据成功保存至 MySQL 数据库中,包含股票代码、公司名称、最新价格、涨跌幅等信息。🎉
2.5 心得体会
本次作业深化了我对 Scrapy 框架的理解,特别是 Item 和 Pipeline 的应用。通过结合 XPath 提取股票信息,并将数据存储到 MySQL 数据库中,实现了数据的序列化和持久化管理。在实际操作中,学会了如何配置数据库连接、创建数据表以及处理数据的序列化输出。此外,理解了 Scrapy 的异步请求机制及其在数据抓取效率上的优势。这些技能为我日后进行复杂数据爬取和处理打下了坚实的基础。💡
附录
Gitee 文件夹链接:作业3-第二题
作业③:定向爬取外汇网站数据
3.1 实验要求
使用 Scrapy 框架结合 XPath 和 MySQL 数据库存储技术,从中国银行网(https://www.boc.cn/sourcedb/whpj/)爬取外汇相关数据。熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法。
3.2 实验思路
-
项目搭建:使用 Scrapy 创建项目,定义外汇数据的
Item和爬虫。 -
数据爬取:
- 分析中国银行外汇牌价页面,确定数据源 URL。
- 使用 Scrapy 的
Request请求数据页面。
-
数据解析:
- 使用 XPath 提取所需的外汇信息字段,如货币名称、买入价、卖出价等。
-
数据存储:
- 配置 MySQL 数据库连接。
- 定义
Pipeline,将解析后的数据写入 MySQL 数据库。
-
序列化输出:通过
Item和Pipeline实现数据的序列化和存储。 -
输出信息:在数据库中查看存储的外汇信息,并进行格式化输出。
3.3 主要代码块
点击查看代码
# bank_exchange_spider.py
import scrapy
from myproject.items import CurrencyItem
class BankExchangeSpider(scrapy.Spider):
name = 'bank_exchange'
allowed_domains = ['boc.cn']
start_urls = [
"https://www.boc.cn/sourcedb/whpj/"
]
def parse(self, response):
table_rows = response.xpath('//table[@class="BOC_main publish"]/tr')
for row in table_rows[1:]:
item = CurrencyItem()
item['currency_name'] = row.xpath('./td[1]/text()').get().strip()
item['buying_rate'] = row.xpath('./td[2]/text()').get().strip()
item['cash_buying_rate'] = row.xpath('./td[3]/text()').get().strip()
item['selling_rate'] = row.xpath('./td[4]/text()').get().strip()
item['cash_selling_rate'] = row.xpath('./td[5]/text()').get().strip()
item['middle_rate'] = row.xpath('./td[6]/text()').get().strip()
item['pub_time'] = row.xpath('./td[7]/text()').get().strip()
yield item
# items.py
import scrapy
class ForexRateItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
pass
# pipelines.py
import pymysql
from scrapy.exceptions import DropItem
class MySQLPipeline:
def __init__(self, host='localhost', user='root', password='', db='xh', port=3306, charset='utf8mb4'):
self.host = host
self.user = user
self.password = password
self.db = db
self.port = port
self.charset = charset
self.connection = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
# 从配置文件中获取数据库连接参数
return cls(
host=crawler.settings.get('MYSQL_HOST', 'localhost'),
user=crawler.settings.get('MYSQL_USER', 'root'),
password=crawler.settings.get('MYSQL_PASSWORD', ''),
db=crawler.settings.get('MYSQL_DB', 'xh'),
port=crawler.settings.getint('MYSQL_PORT', 3306),
charset=crawler.settings.get('MYSQL_CHARSET', 'utf8mb4'),
)
def open_spider(self, spider):
try:
# 打开数据库连接
self.connection = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.db,
port=self.port,
charset=self.charset,
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.connection.cursor()
spider.logger.info("成功连接到数据库")
except pymysql.MySQLError as e:
spider.logger.error(f"数据库连接失败: {e}")
raise
def close_spider(self, spider):
# 关闭数据库连接
if self.cursor:
self.cursor.close()
if self.connection:
self.connection.close()
spider.logger.info("数据库连接已关闭")
def process_item(self, item, spider):
# 定义插入数据的SQL语句
insert_sql = """
INSERT INTO forex_rates (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
# 准备数据
data = (
item.get('currency'),
item.get('tbp'),
item.get('cbp'),
item.get('tsp'),
item.get('csp'),
item.get('time')
)
try:
# 执行SQL语句
self.cursor.execute(insert_sql, data)
# 提交事务
self.connection.commit()
spider.logger.debug(f"插入数据成功: {data}")
except pymysql.MySQLError as e:
# 发生错误时回滚事务
self.connection.rollback()
spider.logger.error(f"插入数据失败: {e}")
raise DropItem(f"插入数据失败: {e}")
return item
3.4 运行结果
终端运行截图:
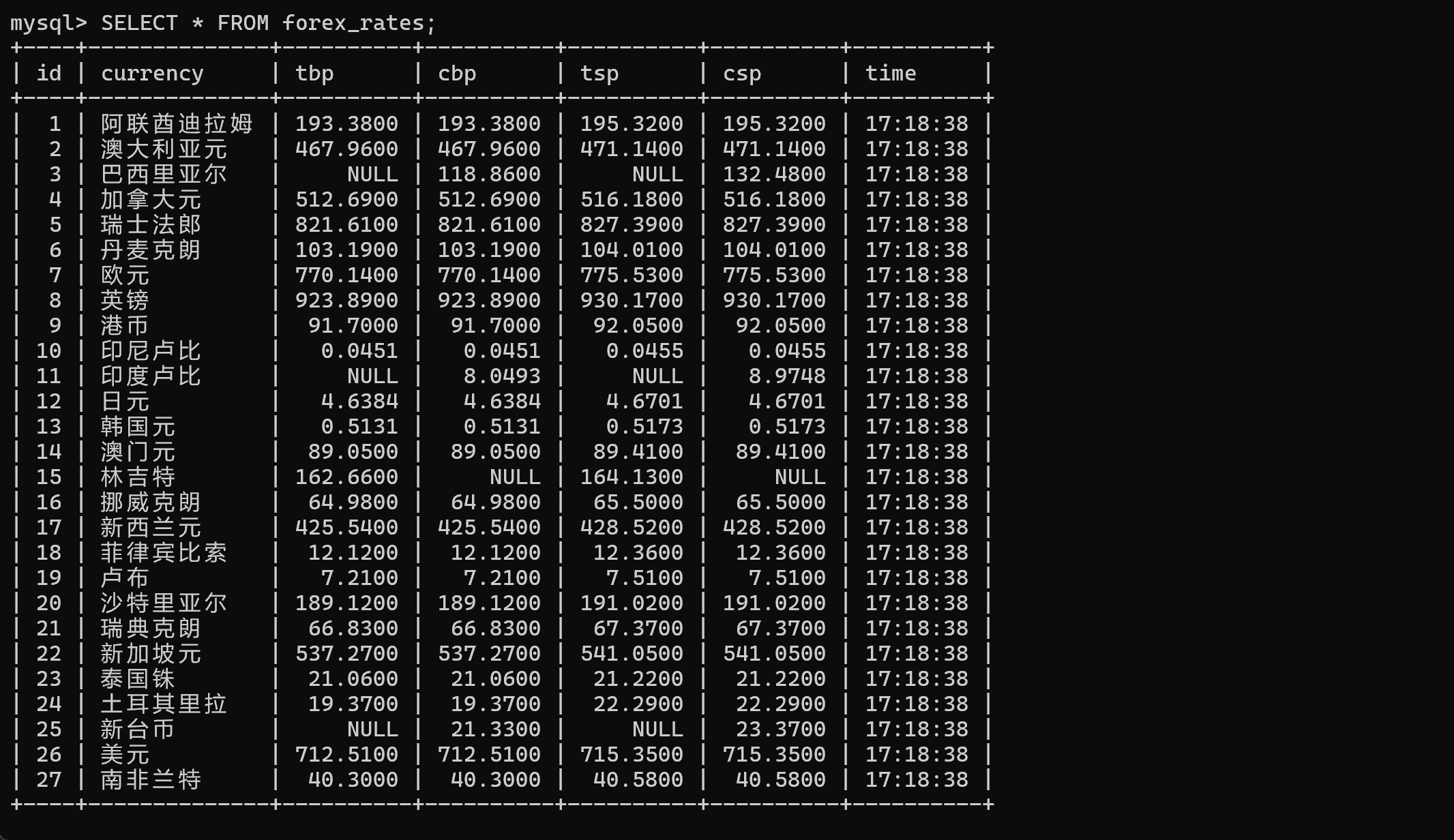
外汇数据成功保存至 MySQL 数据库中,包含货币名称、买入价、卖出价、汇率及时间信息。💰
3.5 心得体会
此次作业让我进一步掌握了 Scrapy 框架在不同数据源的应用。通过对中国银行外汇牌价页面的分析,使用 XPath 精确提取所需的外汇信息,并结合 Pipeline 将数据高效地存储到 MySQL 数据库中。在这个过程中,我使用了调试工具(F12)分析网页结构,确保数据提取的准确性。这些实践经验提升了我在实际项目中处理多样化数据源的能力。🚀
通过运行与调试,我发现初次尝试时存在查询失败的问题,可能由于页面结构变化或 XPath 表达式不准确。通过仔细检查和调整 XPath 表达式,成功解决了这些问题,确保了数据的完整性和准确性。这让我意识到,在实际爬取过程中,灵活应对网页结构的变化和不断优化爬虫代码的重要性。🔧
附录
Gitee 文件夹链接:作业3-第三题
总结
本次第三次作业通过三个不同的爬取任务,全面提升了我对 Scrapy 框架的应用能力。首先,通过爬取中国气象网的图片,掌握了 Scrapy 在媒体资源抓取方面的技巧,并通过单线程与多线程的对比,理解了并发设置对爬取效率的影响。🌐
其次,针对东方财富网的股票信息爬取,深入学习了 Scrapy 的 Item 和 Pipeline 的使用,熟练掌握了与 MySQL 数据库的集成,实现了数据的序列化和持久化存储。📊
最后,通过中国银行网的外汇数据爬取,进一步巩固了 XPath 的应用技巧,并通过调试工具分析网页结构,确保数据提取的准确性。💱
整个作业过程中,不仅提升了编写高效爬虫的能力,还增强了对数据存储与管理的理解。这些实践经验为我未来在数据采集与处理领域的深入学习和项目开发奠定了坚实的基础。我期待在接下来的学习中,继续探索更复杂的数据抓取技术,优化爬虫性能,并应用所学知识解决实际问题。💡🎯
😊 感谢阅读!
