数据采集第二次作业
数据采集实践第二次作业
目录
● 码云链接 作业2 · xh102202145/crawl_project
作业①:定向爬取7日天气预报
1.1 实验要求
在中国气象网(http://www.weather.com.cn)上爬取给定城市的7日天气预报,并将数据存储到数据库中。
1.2 实验思路
- 使用
requests向中国气象网发送请求,获取城市天气预报数据。 - 利用
BeautifulSoup解析返回的HTML内容,提取目标天气信息。 - 将数据保存至SQLite数据库。
1.3 主要代码块
点击查看代码
# 爬取天气数据类
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text if li.select('h1') else "N/A"
weather = li.select('p[class="wea"]')[0].text if li.select('p[class="wea"]') else "N/A"
temp_high = li.select('p[class="tem"] span')[0].text if li.select('p[class="tem"] span') else "N/A"
temp_low = li.select('p[class="tem"] i')[0].text if li.select('p[class="tem"] i') else "N/A"
temp = temp_high + "/" + temp_low
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print("Error parsing data:", err)
except Exception as err:
print("Error accessing URL:", err)
def process(self, cities):
self.db = WeatherDB()
for city in cities:
self.forecastCity(city)
self.db.close()
1.4 运行结果

1.5 心得体会
通过本次实验,我对爬虫的基本流程有了更深入的理解。使用requests库进行网页请求时,需要注意设置合适的请求头,以避免被目标网站识别为爬虫。此外,BeautifulSoup库的使用让我能够轻松解析HTML文档并提取所需的信息。将爬取的数据存入SQLite数据库也让我对数据存储有了更深入的认识。整体而言,这是一次很有价值的实践,增强了我对Python爬虫的掌握。
作业②:定向爬取股票相关信息
2.1 实验要求
使用 requests 和 BeautifulSoup 定向爬取股票相关信息,并将数据存储在数据库中。
2.2 实验思路
-
数据爬取:使用
requests库通过API获取股票数据,构建请求URL和请求头,遍历用户输入的页面进行数据请求。 -
数据解析:提取响应中的JSON数据,转换为Python字典,获取所需的股票信息字段,并准备存储。
-
数据库操作:连接SQLite数据库,创建数据表并定义表结构,通过
sqlite3库插入提取的股票数据,确保数据的完整性。 -
结果展示:查询数据库中的数据,并格式化输出,便于阅读和分析,验证数据的准确性。
2.3 主要代码块
点击查看代码
# 获取页面输入
keypage = input("请输入要搜索的页面:")
searchlist = list(map(int, keypage.split()))
# 遍历每一页进行数据爬取
for page in searchlist:
url = f'http://76.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112405166990298085778_1696666115151&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696666115152'
response = requests.get(url, headers=headers)
data = response.text
# 提取括号中的JSON数据
start = response.text.find('(')
end = response.text.rfind(')')
data = response.text[start + 1:end]
data = json.loads(data)
# 提取股票信息
data = data['data']['diff']
plist = ['f12', 'f14', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18', 'f10', 'f8', 'f9', 'f23']
for stock in data:
row = tuple(stock[field] for field in plist)
cursor.execute('''INSERT INTO my_table (code, name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, high, low, opening_price, yesterday_close,
volume_ratio, turnover_rate, pe_ratio, pb_ratio)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', row)
# 提交更改并关闭数据库连接
conn.commit()
2.4 运行结果

股票数据成功保存至数据库中,包含股票代码、公司名称、最新价格、涨跌幅等信息。
2.5 心得体会
实际编码过程让我更加深刻地理解了HTTP请求、JSON数据解析和数据库操作等基本概念,掌握了如何将这些概念结合起来,实现数据的自动化抓取和存储。
作业③:定向爬取中国大学2021主榜信息
3.1 实验要求
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)
所有院校信息,并存储在数据库中。将浏览器F12调试分析的过程录制为Gif并加入博客中。
3.2 实验思路
-
数据请求:使用
requests库获取指定URL的JavaScript数据,包含高校排名及相关信息。 -
数据提取:
- 使用正则表达式提取学校名称、总分、类型和省份等信息。
- 提取
function中参数的编码和含义,将其分别存入code_name和value_name列表。
-
数据整理:将提取的信息整理成一个
pandasDataFrame,设置合适的列名(排名、学校、省份、类型、总分),并逐行填充数据。 -
结果保存:将整理好的数据保存为Excel文件,便于后续分析和使用。
3.3 主要代码块
点击查看代码
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
resquest = requests.get(url=url)
name = re.findall(',univNameCn:"(.*?)",',resquest.text)#获取学校名称
score = re.findall(',score:(.*?),',resquest.text)#获取学校总分
category = re.findall(',univCategory:(.*?),',resquest.text)#获取学校类型
province = re.findall(',province:(.*?),',resquest.text)#获取学校所在省份
3.4 运行结果
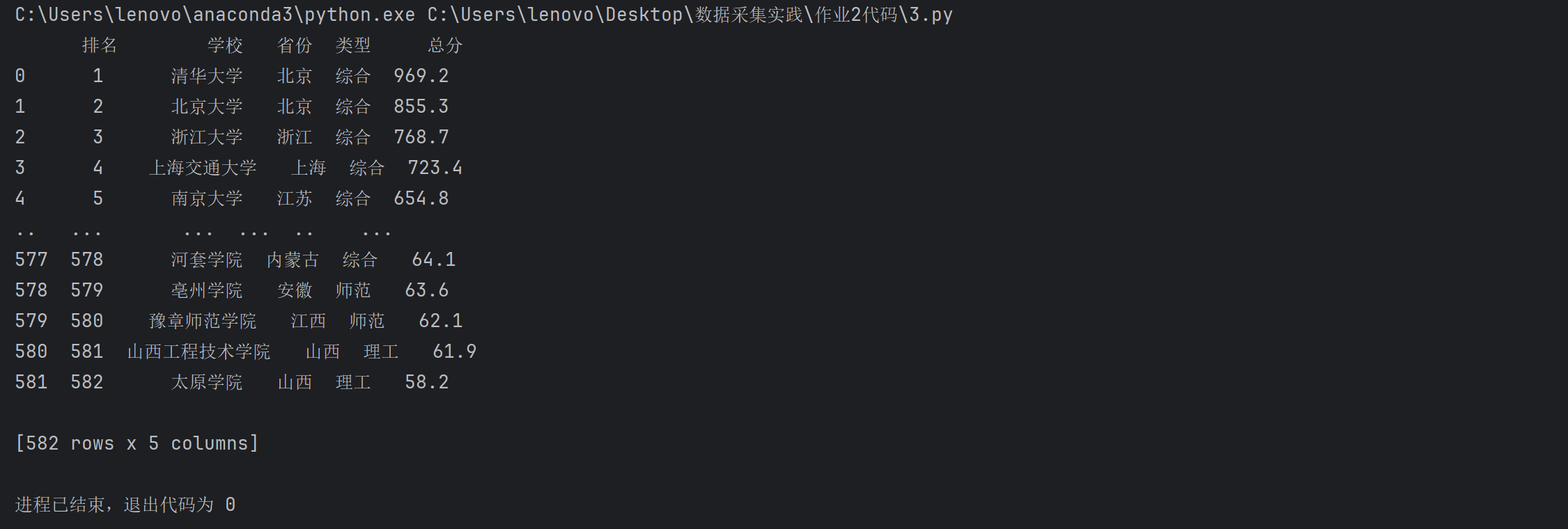
3.5 运行结果浏览器F12调试分析的过程
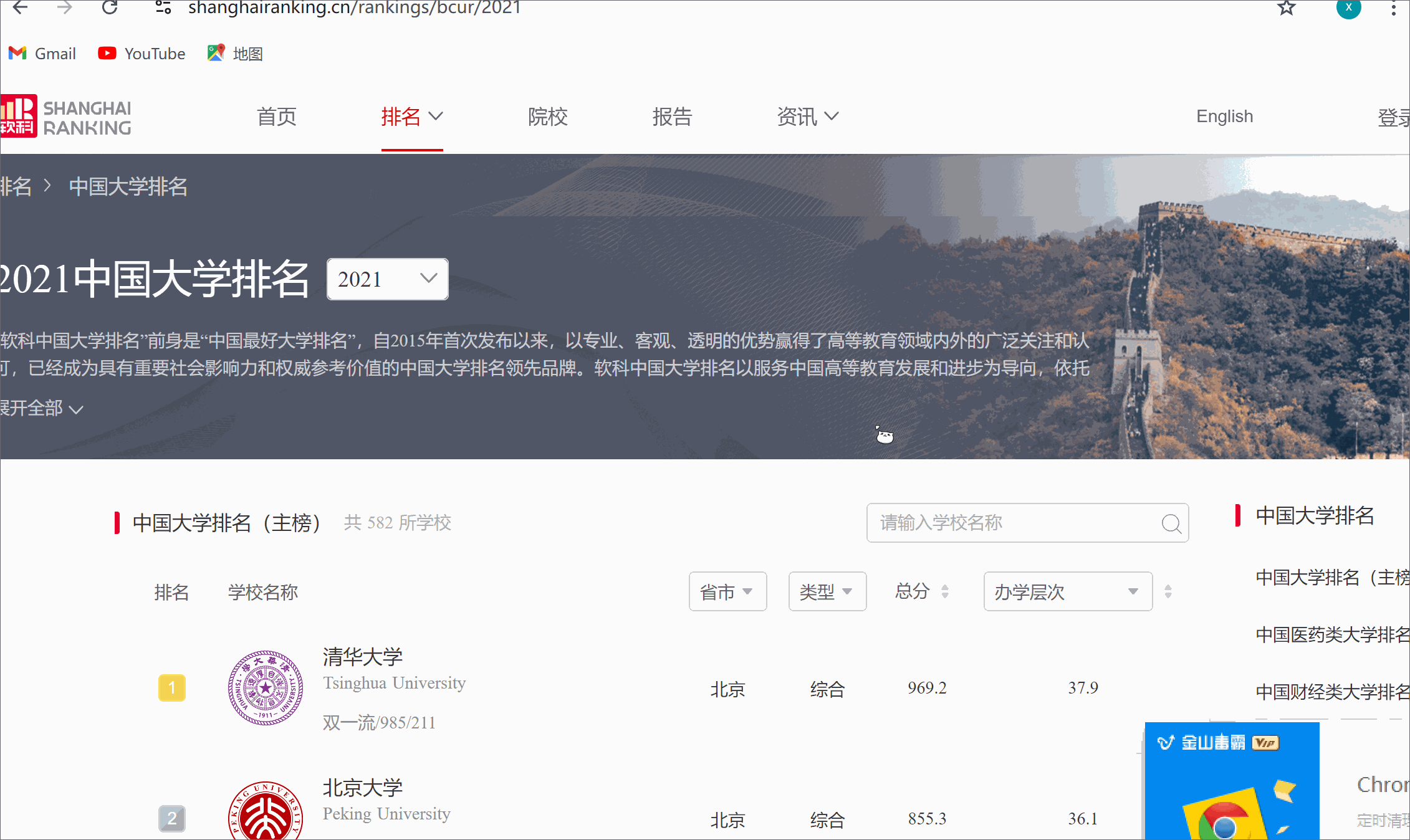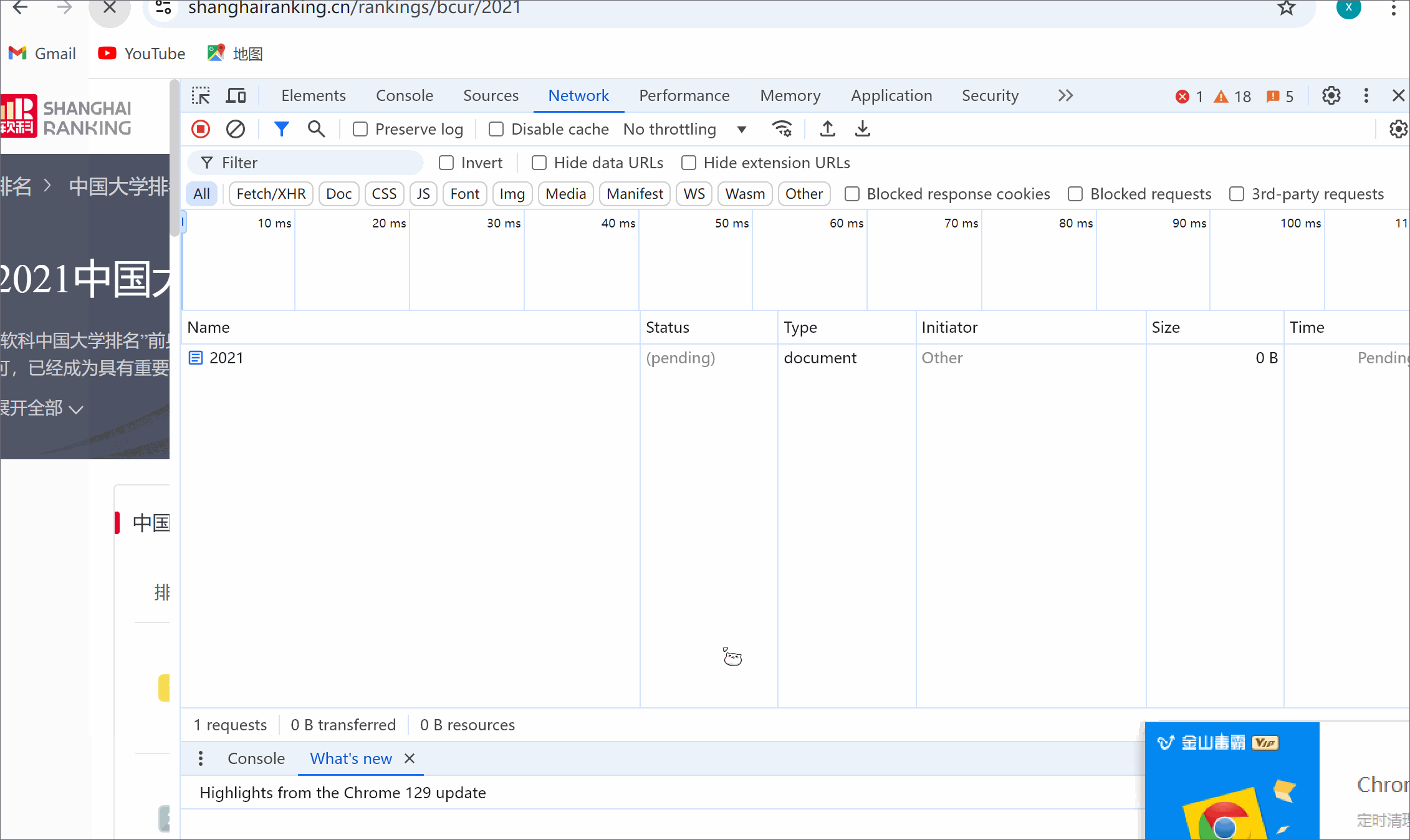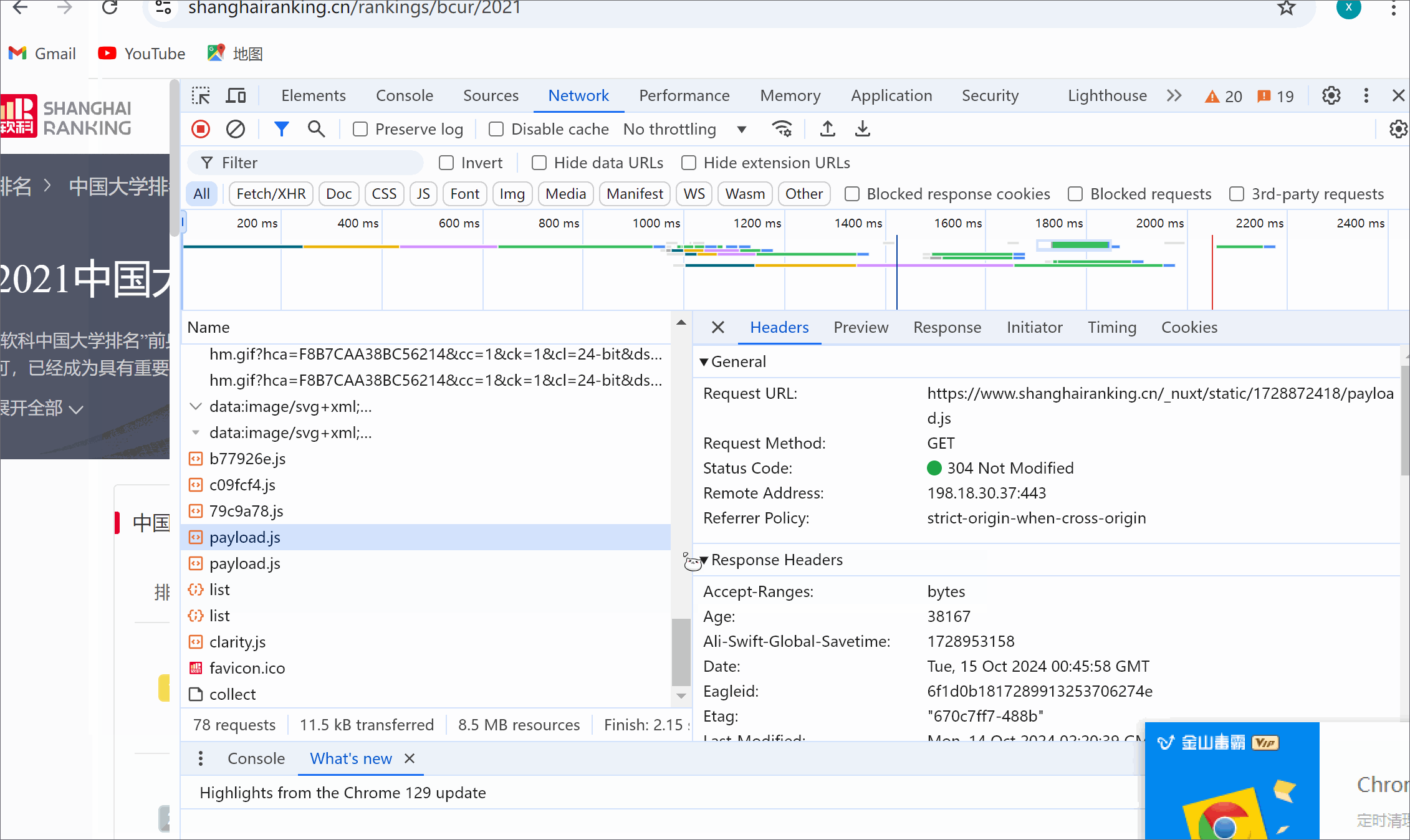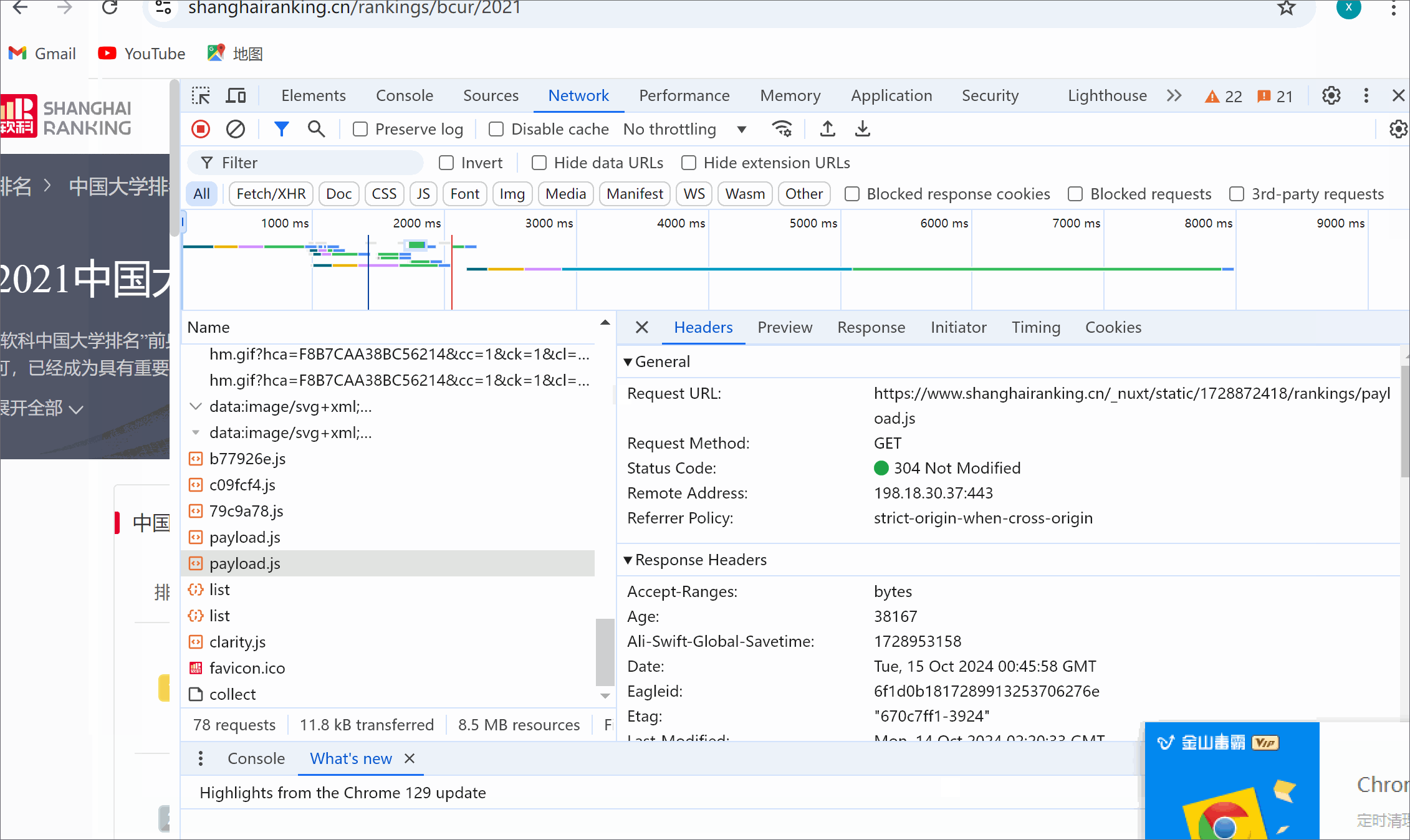
3.6 心得体会
正则表达式的应用:通过正则表达式提取复杂文本中的特定信息,提高了数据处理的灵活性,但也需要注意正则的匹配精度。
数据整理能力:使用pandas进行数据整理和分析,使数据呈现更加直观,方便后续的处理和分析。
实际应用:该代码展示了如何从网页中提取数据并进行处理的实际应用,为爬虫技术和数据分析的结合提供了有力的示例。
总结
本次作业通过requests和BeautifulSoup实现了对7日天气预报、股票信息以及中国大学排名的爬取和存储任务。在实践中,我不仅学到了如何使用Python进行数据抓取,还掌握了如何分析网页请求以及解析不同格式的数据。每个作业都让我在实际操作中逐步提升了技能,增强了对数据采集的理解。我希望在未来的学习中,能够继续探索更复杂的数据抓取和分析技术,将这些技能应用到实际项目中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号