数据采集第一次作业
数据采集实践第一次作业
目录
● 码云链接 作业1 · xh102202145/crawl_project
作业①:定向爬取大学排名信息
1.1 实验要求
使用 requests 和 BeautifulSoup 库定向爬取指定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息,输出如下格式的表格:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 |
1.2 实验思路
- 使用
requests获取网页数据,利用BeautifulSoup解析 HTML 内容。 - 定位并提取表格中的排名、学校名称、所在省市、学校类型和总分等信息。
- 输出格式化的表格。
1.3 主要代码块
点击查看代码
def extract_chinese(text):
return ''.join(re.findall(r'[\u4e00-\u9fff]+', text))
try:
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
table = soup.find('table')
if table:
# Extract table rows
rows = table.find_all('tr')
# Print the header with proper tab spacing
print(f"{'排名':<6}{'学校名称':<20}{'省市':<10}{'学校类型':<10}{'总分':<10}")
# Iterate over rows and extract data
for row in rows[1:]: # Skip the header row
cells = row.find_all('td')
if len(cells) > 1: # Ensure the row contains data
ranking = cells[0].get_text(strip=True)
# Extract only the Chinese part of the school name
school_name = extract_chinese(cells[1].get_text(strip=True))
province_city = cells[2].get_text(strip=True)
school_type = cells[3].get_text(strip=True)
total_score = cells[4].get_text(strip=True)
1.4 运行结果
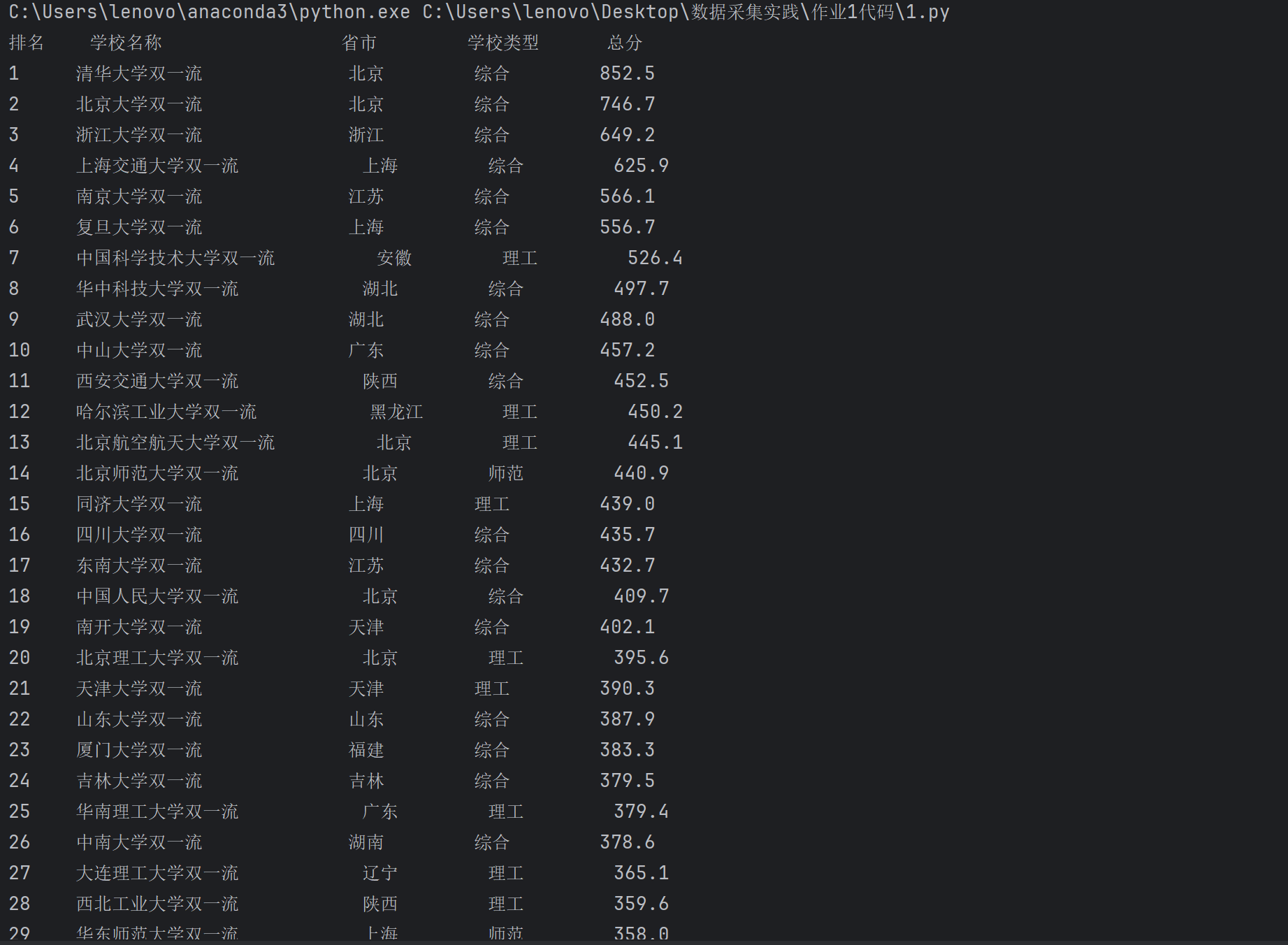
1.5 心得体会
- 分析与定位挑战:准确定位目标数据是爬虫开发中的一大挑战。通过学习 HTML 结构,提升了我在无明显标识的情况下定位数据的能力。
- 正则表达式应用:提取学校名称时,使用正则表达式过滤掉多余字符,使数据更加精准。
- 异常处理的重要性:通过加入异常处理机制,我的程序在网络请求失败或网页结构变化时能够保持稳定并返回清晰的错误信息。
作业②:商品比价定向爬虫
1.1 实验要求
使用 requests 和 re 库编写爬虫,爬取指定商城(自行选择)中关于“书包”的商品信息,包括商品名称和价格。输出如下格式的表格:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 |
1.2 实验思路
- 使用
requests获取网页内容,结合正则表达式提取商品的价格和名称。 - 对数据进行简单处理后,输出为整齐的表格。
1.3 主要代码块
点击查看代码
def main():
goods = urllib.parse.quote(input("请输入要爬取的商品:"))
page = int(input("请输入要获取的页面序列:"))
print("正在爬取...")
url = f'https://search.dangdang.com/?key={goods}&act=input&page_index={page}'
info = []
data = getHTMLText(url)
if data:
print("HTML文本获取成功!")
parsePage(info, data)
printGoodslist(info)
else:
print("HTML文本获取失败。")
1.4 运行结果
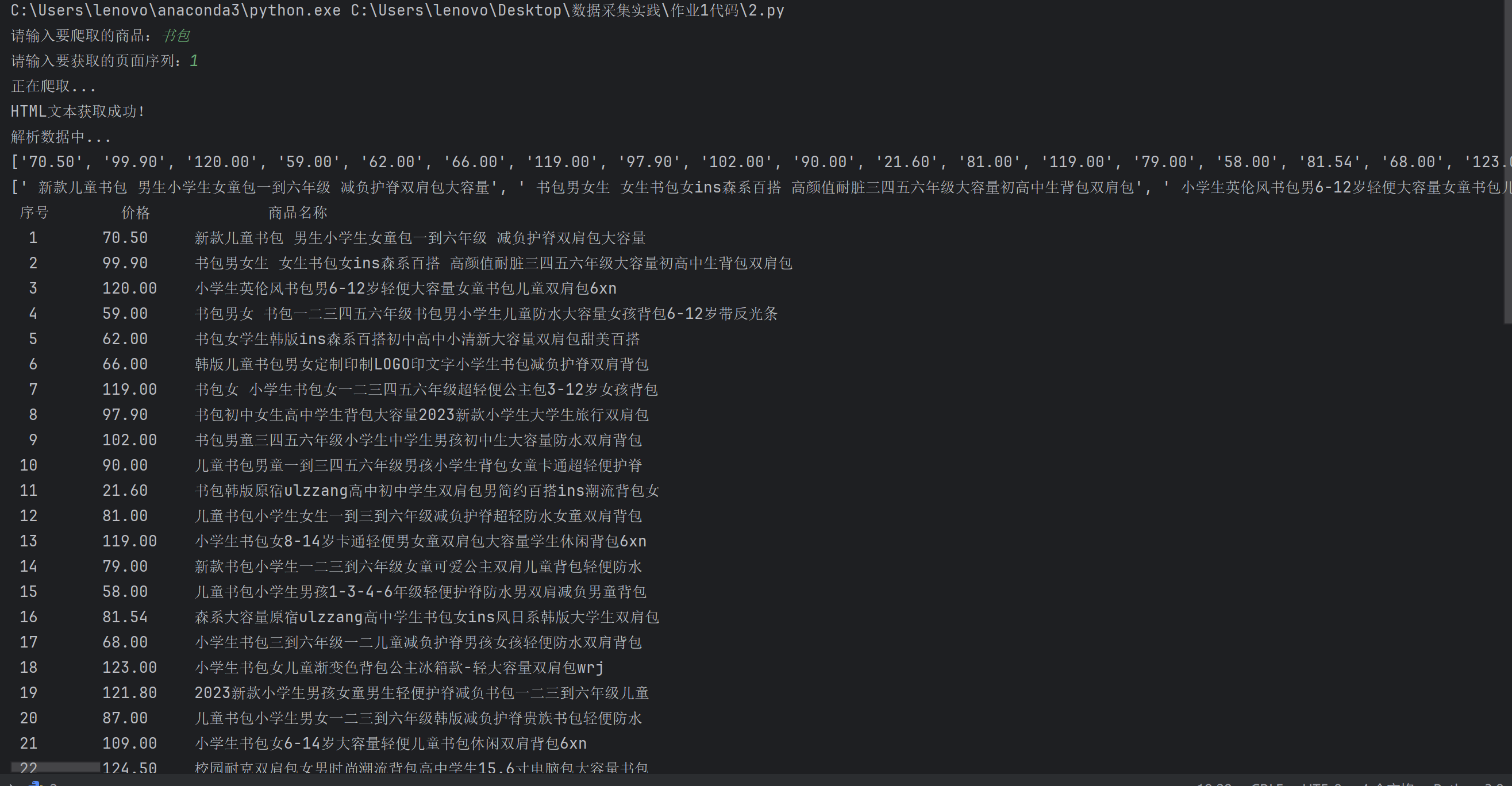
1.5 心得体会
- 爬虫的实际应用:通过这次实验,我更好地理解了网络爬虫在商品比价中的实际应用,能有效从多个平台获取商品信息。
- 正则表达式的灵活性:通过练习,我加深了对正则表达式的掌握,特别是在从复杂网页中提取关键数据时。
- 数据抓取的合规性:开发爬虫时,我认识到应遵守网站的爬取规则,尊重网站的版权及用户隐私,保持数据抓取的合法性。
作业③:爬取网页中的JPEG和JPG格式图片
1.1 实验要求
编写爬虫爬取指定网页(https://news.fzu.edu.cn/yxfd.htm)或自选网页中的所有 JPEG 和 JPG 图片文件,并将其保存到本地文件夹中。
1.2 实验思路
- 使用
requests发送 HTTP 请求获取网页内容。 - 利用
BeautifulSoup提取所有<img>标签,下载其中符合条件的图片。 - 将图片保存到指定文件夹中。
1.3 主要代码块
点击查看代码
for img in soup.find_all('img'):
# 获取图片的URL
img_url = img.get('src')
# 确保图片URL是完整的
img_url = urljoin(url, img_url)
# 检查图片扩展名是否为.jpg或.jpeg
if img_url.endswith('.jpg') or img_url.endswith('.jpeg'):
try:
# 获取图片内容
img_data = requests.get(img_url).content
# 获取图片的文件名
img_name = os.path.basename(img_url)
# 保存图片到文件夹
with open(os.path.join(folder_name, img_name), 'wb') as f:
f.write(img_data)
print(f'图片已下载: {img_name}')
except Exception as e:
print(f'下载图片 {img_url} 时发生错误: {e}')
print('所有.jpg和.jpeg图片下载完成。')
1.4 运行结果

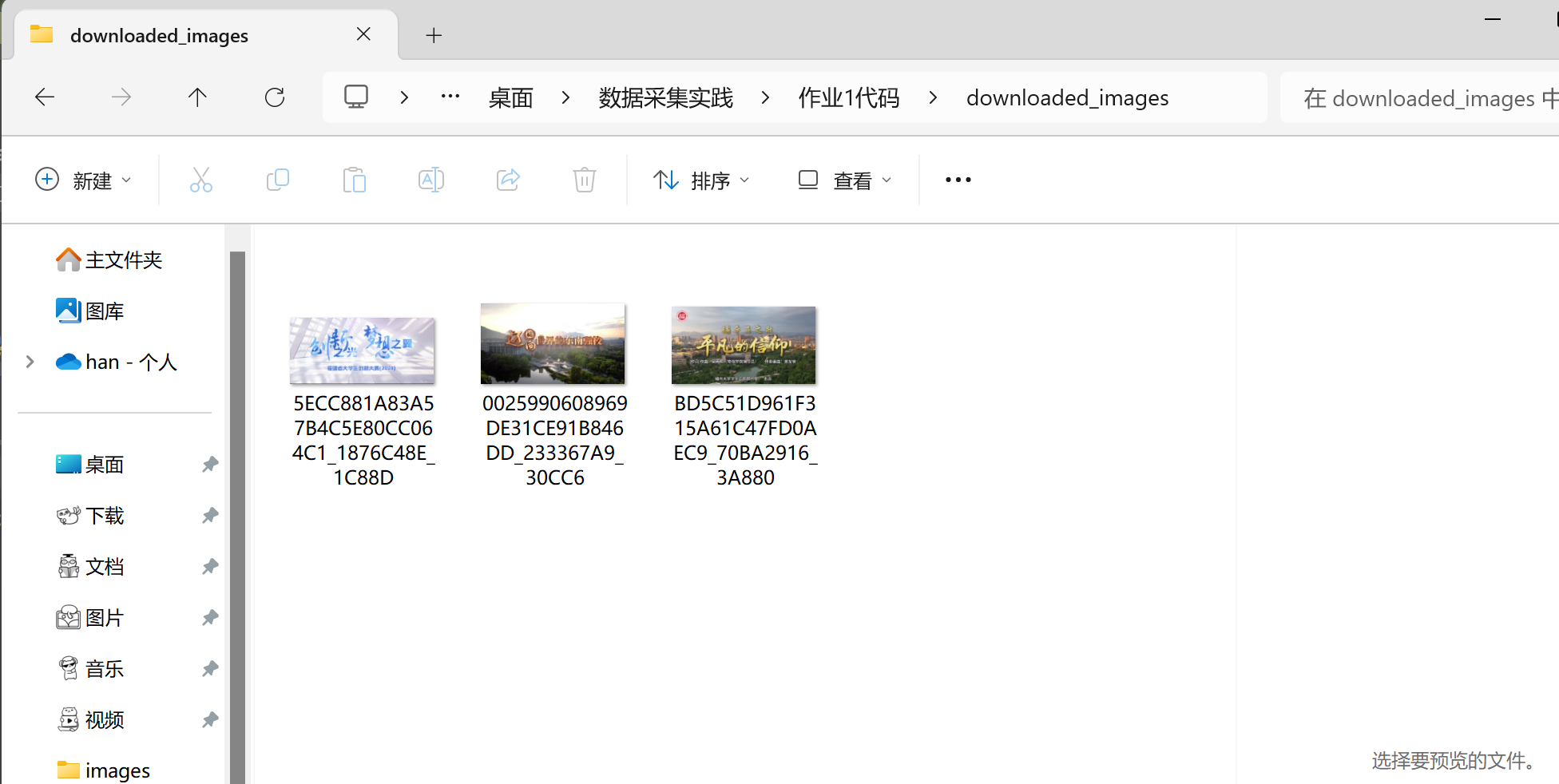
1.5 心得体会
- 请求与解析的结合:通过此次实验,我学会了如何结合 HTTP 请求和 HTML 解析,使爬虫程序的爬取能力和数据处理能力有机结合。
- 图片下载的实践:图片下载不仅涉及 URL 提取,还需要处理本地文件存储问题,这让我加深了对文件操作的理解。
- 程序健壮性:异常处理机制确保了爬虫在遇到网络波动或其他异常情况时,仍然能够稳定运行,减少程序中断的风险。
总结
通过这三次作业,我对 requests、BeautifulSoup 和 re 等库的使用有了深入的理解,尤其是在数据采集和网络爬虫方面的能力得到了很大提升。三次实验中,爬虫技术不仅让我在数据提取和处理上有了显著进步,同时也意识到程序健壮性和合规性的重要性。每次实验后,我都进一步完善了异常处理机制,确保爬虫能够应对复杂的网页结构和可能出现的异常情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号