IO流详解之字节流与编码方式
IO流
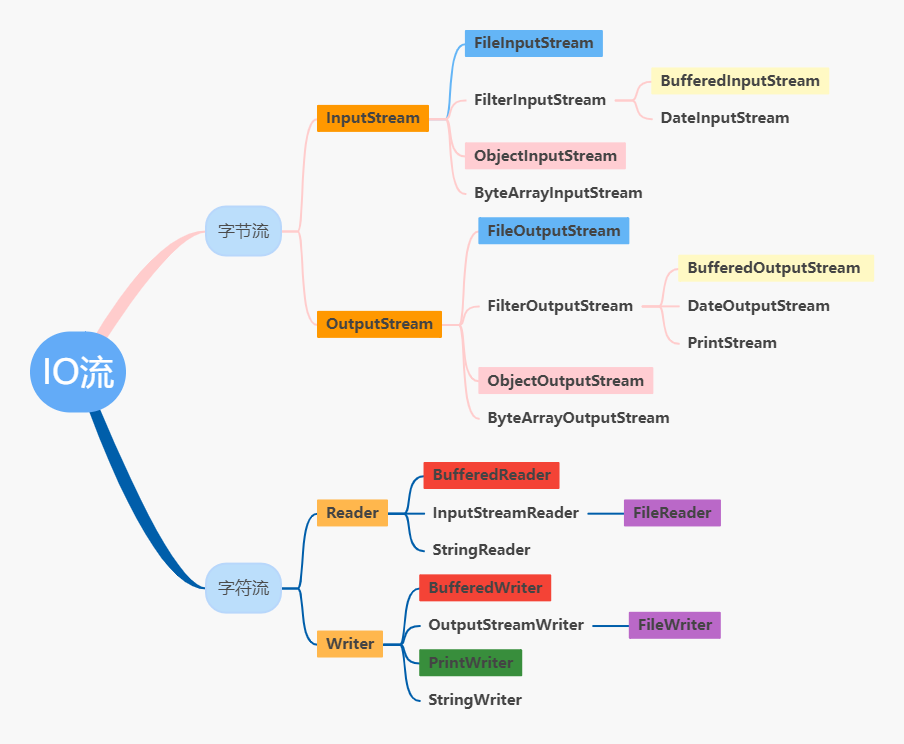
1.流的概念和分类
- IO流核心组成
- 核心组成:一个类(File)、一个接口(Serializable)、四个抽象类(InputStream/OutputStream、Reader/Writer)
-
什么是流
- 流:内存与存储设备之间传输数据的通道
-
流的分类
-
按方向
- 输入流:将<存储设备>中的内容读到<内存>中
- 输出流:将<内存>中的内容写到<存储设备>中
-
按单位
- 字节流:以字节为单位,可以读写所有数据
- 字符流:以字符为单位,只能读写文本数据
-
按功能
- 节点流:具有实际传输数据的读写功能
- 过滤流:在节点流的基础之上增强功能
2.字节流
2.1字节流抽象类
-
InputStream
- 此抽象类是表示字节输入流的所有类的父类。InputSteam是一个抽象类,它不可以实例化。数据的读取需要由它的子类来实现。根据节点的不同,它派生了不同的节点流子类。
- 继承自InputSteam的流都是用于向程序中输入数据,且数据的单位为字节(8 bit)
- 常用方法:
public int read(){}:读取一个字节的数据,并将字节的值作为int类型返回(0-255之间的一个值)。如果未读出字节则返回-1(返回值为-1表示读取结束)。while((data=fis.read())!=-1)来判断读取文件是否结束。
public int read(byte[] b){}:从该输入流读取最多 b.length个字节的数据,并把读取的数据存放到b这个字符数组里面
public int read(byte[] b, int off, int len){}
-
OutputStream
- 此抽象类是表示字节输出流的所有类的父类。输出流接收输出字节并将这些字节发送到某个目的地
public void write(int n):向目的地中写入一个字节
public void write(byte[] b){}: 将 b.length个字节从指定的字节数组写入此文件输出流。
public void write(byte[] b, int off, int len){}
- 此抽象类是表示字节输出流的所有类的父类。输出流接收输出字节并将这些字节发送到某个目的地
2.2文件字节流
-
FileInputStream:
- public int read(byte[] b) // 从流中读取多个字节,将读到内容存入 b 数组,返回实际读到的字节数;如果达到文件的尾部,则返回 -1
-
FileOutputStream:
- public void write(byte[] b) // 一次写多个字节,将 b 数组中所有字节,写入输出流
2.21 文件字节输入流代码演示
package stream.demo01;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
FileInputStream 使用
文件字节输入流
*/
public class FileInputStreamTest {
public static void main(String[] args) throws IOException {
// 1 创建FileInputStream 并指定文件路径
FileInputStream fileInputStream = new FileInputStream("D:\\atext.txt");
// 2 读取文件
/*
// 方式一:单字节读取
int date=0;
//int d1 = fileInputStream.read(); 不可以在这里赋值给d1,不然就只是读了一个字节
//必须加括号,不然不知道执行谁
while ((date=fileInputStream.read())!=-1){
System.out.print((char) date);
}
*/
// 方式二:一次读取多个字节(3)
byte[] array=new byte[3];// 大小为3的缓存区
/*
int count = fileInputStream.read(array);
//System.out.println((new String(array)));// 一次读3个
String s = new String(array);
System.out.println(s);
int count2 = fileInputStream.read(array);
System.out.println(new String(array));// 再读3个
int count3=fileInputStream.read(array);
System.out.println(new String(array));
*/
// 上述优化后
int count=0;
//返回读取到了多少个元素,如果没有读取到返回-1
while ((count=fileInputStream.read(array))!=-1){
System.out.println(new String(array,0,count)); // new String(bytes, 0, count) 转换字符串从bytes的0下标开始,读count个字符串
}
// 3 关闭
fileInputStream.close();
System.out.println();
System.out.println("执行完毕");
}
}
运行结果
abc
def
gha
bcd
efg
hab
cde
fga
bcd
efg
hab
cde
fgh
abc
def
ghh
abc
def
gha
bcd
efg
h
执行完毕
2.22 文件字节输出流代码演示
package stream.demo01;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/*
文件输出流的使用
FileOutputStream
*/
public class FileOutputStreamTest {
public static void main(String[] args) throws IOException {
// 1 创建文件字节输出流
FileOutputStream fileOutputStream = new FileOutputStream("D:\\fff.txt",true);// true表示不覆盖 接着写
/*
// 2 写入文件
fileOutputStream.write(97);
fileOutputStream.write('b');
fileOutputStream.write('c');
fileOutputStream.write('d');
fileOutputStream.write('e');
*/
byte[] bytes = new byte[10];
String st="hello world";
fileOutputStream.write(st.getBytes());//getBytes():获取字节数据
//getBytes(String charsetName):使用指定的字符集将字符串编码为byte序列,并将结果存储到一个新的byte数组中
// 3 关闭
fileOutputStream.close();
System.out.println("复制完成");
}
}
运行结果
复制完成

2.23 文件字节流复制文件代码演示
package stream.demo01;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
//使用字节流实现文件的复制
public class StreamCopyTest {
public static void main(String[] args) throws IOException {
// 1 创建流
// 1.1 文件字节输入流
FileInputStream fis = new FileInputStream("D:\\a50.jpg");
// 1.2 文件字节输出流
FileOutputStream fos = new FileOutputStream("D:\\b50.jpg");
// 2 边读边写
byte[] bytes = new byte[1024*5];
int count=0;
while ((count=fis.read(bytes))!=-1){
fos.write(bytes,0,count);
}
// 3 关闭
fis.close();
fos.close();
System.out.println("执行完毕");
}
}
运行结果
执行完毕
2.3 字节缓冲流
- 缓冲流:BufferedInputStream/ BufferedOutputStream
- 提高IO效率,减少访问磁盘次数
- 数据存储在缓冲区中,flush是将缓冲区的内容写入文件中,也可以直接close
2.31 字节缓冲输入流代码演示:
package stream.demo01;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
// 字节缓冲流输入流
public class BufferedInputStreamTest {
public static void main(String[] args) throws Exception {
// 1 创建BufferedInputStream
FileInputStream fis = new FileInputStream("D:\\atext.txt");
BufferedInputStream bis = new BufferedInputStream(fis);// 目的是增强底层流的功能, 先读到缓冲区
//创建字节缓冲流对象时需要向其输入一个底层流
/*
// 2 读取
int count=0;
while ((count=bis.read())!=-1){
System.out.print((char)count);
}
*/
// 用自己创建的缓冲流
byte[] bytes = new byte[1024 * 5];
int count=0;
while ((count=bis.read(bytes))!=-1){
System.out.println(new String(bytes,0,count));
}
// 3 关闭
bis.close();
}
}
运行结果
abcdefghabcdefghabcdefgabcdefghabcdefghabcdefghhabcdefghabcdefgh
2.32 字节缓冲输出流代码演示:
package stream.demo01;
import java.io.*;
// 使用字节缓冲流 写入 文件
public class BufferedOutputStreamTest {
public static void main(String[] args) throws IOException {
// 1 创建BufferedInputStream
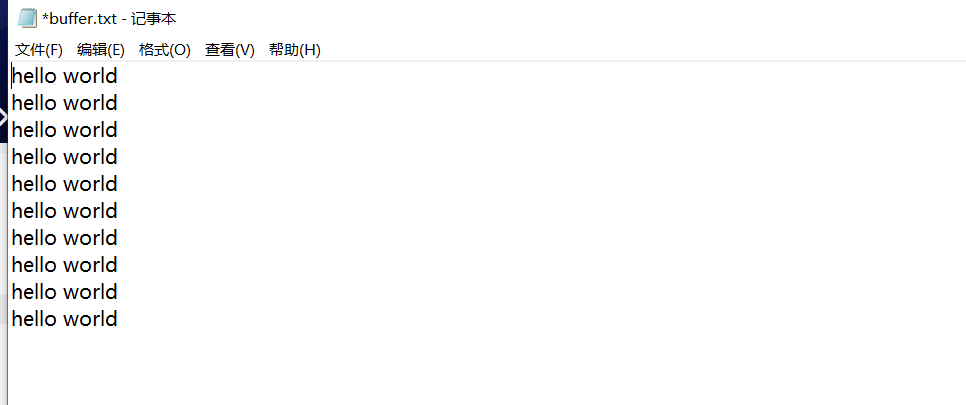
FileOutputStream fis = new FileOutputStream("D:\\buffer.txt");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fis);
// 2 写入文件
for (int i = 0; i < 10; i++) {// 此时读到了缓冲区,没有在文件中
bufferedOutputStream.write("hello world\r\n".getBytes());//\r\n 转义字符换行打印
}
System.out.println("执行完毕");
// 3 关闭 bos.flush(); // 刷新到硬盘 close方法里自带有
bufferedOutputStream.close();
}
}
运行结果
执行完毕
2.4 对象流
-
ObjectInputStream/ObiectOutputStream
-
增强了缓冲区功能
-
增强了读写 8 种基本数据类型和字符串功能
-
增强了读写对象的功能
readObject()从流中读取一个对象
writeObject(Object obj)向流中写入一个对象 -
使用流传输对象的过程称为序列化、反序列化
-
-
序列化对象类的书写注意事项
- 序列化类必须实现 Serializable 接口
- 序列化类中的对象属性要实现 Serializable 接口
- 序列化版本号ID,保证序列化的类和反序列化的类是同一个类
private static final long serialVersionUID = 100L; - 使用transient修饰属性,这个属性就不能序列化
- 静态属性不能序列化
- 序列化多个对象,可以借助集合来实现
2.41 序列化代码演示:
package stream.demo01;
import java.io.Serializable;
public class Student implements Serializable {
//类要想序列化必须实现Serializable接口
private String name;
// private int age;
private transient int age; //Student{name='zhangsan', age=0}
//使用transient修饰属性,使属性不能被序列化
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
package stream.demo01;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
// 使用objectoutputStream实现对象的序列化
//注意:在写对象这个类的时候需要public class Student implements Serializable实现这个接口。
/*
1.某个类要想序列化必须实现Serializable接口
2.序列化类中对象属性要求实现Serializable接口
3.序列化版本号ID,保证序列化的类和反序列化的类是同一个类
4.使用transient修饰属性,这个属性就不能序列化
5.静态属性不能序列化
6.序列化多个对象,可以借助集合来实现
*/
public class ObjectOutputStreamTest {
public static void main(String[] args) throws IOException {
// 1. 创建对象流
FileOutputStream fos = new FileOutputStream("D:\\student.bin");//这里文件类型可以随便写,但是和反序列化一定要一致
ObjectOutputStream obj = new ObjectOutputStream(fos); //bin表示这是一个二进制文件类型
// 2. 序列化(写入操作)
Student s = new Student("zhangsan",18);
Student lisi = new Student("lisi", 20);
ArrayList<Student> Arry=new ArrayList<>();
Arry.add(s);
Arry.add(lisi);
obj.writeObject(Arry);
// obj.writeObject(s);
// obj.writeObject(lisi);
// 3. 关闭
obj.close();
System.out.println("序列化执行完毕");
}
}
运行结果
序列化执行完毕
2.42 反序列化代码演示:
package stream.demo01;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.ArrayList;
import java.util.Objects;
// 使用ObjectInputSteam实现反序列化(读取重构对象)
//反序列化(重构成对象)
public class ObjectInputStreamTest {
public static <ArrrayList> void main(String[] args) throws IOException, ClassNotFoundException {
// 1. 创建对象流
FileInputStream fis = new FileInputStream("D:\\student.bin");
ObjectInputStream obs = new ObjectInputStream(fis);
// 2. 读取文件(反序列化)
// Student s = (Student) obs.readObject(); //readObject() 返回类型为Object,因此需要强转
// Student o = (Student)obs.readObject();
ArrayList<Student> objects=(ArrayList<Student>) obs.readObject();
// 3. 关闭
obs.close();
System.out.println("反序列化执行完毕");
// System.out.println(s.toString());
// System.out.println(o.toString());
System.out.println(objects.toString());
}
}
运行结果
反序列化执行完毕
[Student{name='zhangsan', age=0}, Student{name='lisi', age=0}]
3.编码方式(常见字符形式)
-
引言
- 在计算机中提供给用户最常见的显示就是字符,也称之为文本,字符的种类非常多,每种语言都有自己的字符集,那么,这么多的字符,如何存储进计算机中呢?
-
计算机存储字符的本质原理
- 每个字符都通过字符集的映射转化为一个整数存储在计算机中,所以存储字符的本质还是存储整数。
- 将字符转为对应码值,然后将码值转换为二进制,最后存到计算机中。
3.1 常用编码介绍
- 采用不同的编码方式,则字符对应的码值就不同。目前常见的编码方式有:
- ASCII码。固定使用1个字节来表示字符,可以表示128个字符
- Unicode码。固定使用2个字节来表示字符(字母和汉字都是)。
- utf-8。字母用1个字节表示,汉字用3个字节表示。
- GBK。字母用1个字节表示,汉字用2个字节表示。
3.2 各编码详细介绍
-
英文字符集 —— ASCII
-
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系做了统一规定,这一规定被称为 ASCII 码
-
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码
-
ASCII 码规定使用一个字节来存储英文字符,最前面的一位统一规定为0,不同的字符由后面的7位确定, 所以ASCII码一共规定了128个字符的编码
-
【优点】只用1个字节表示字符
-
【缺点】最多只表示127个字符,表示字符数量有限。
-
-
全世界的字符集 —— Unicode
-
全世界的语言非常多,每种语言都有自己的字符集,非常的不方便,并且极其容易出现乱码,所以Unicode字符集的诞生就是为了将世界上所有的字符都纳入其中,形成一种统一的编码规定。
-
Unicode,统一码,又叫万国码。
-
Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
-
【优点】不会出现乱码现象
-
【缺点】固定使用2个字节表示一个字符(包括字母、汉字),比较占用存储空间。
-
-
UTF-8编码
-
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。(可以理解为是对Unicode编码的改进)
-
它可以用来表示Unicode编码中的任何字符,而且其编码中的第一个字节仍与ASCII相容(即同样向下兼容ASCII编码),使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
-
【特点】字母用1个字节表示,汉字用3个字节。
-
-
中文字符集 —— GBK
- 中华文明源远流长,目前汉字大约有十万个,常用的汉字都有几千个,这么多的字符,显然靠美国的ASCII码字符集是不可能存储的
- 国家标准化委员于1995年颁布了GBK标准,全称“汉字编码扩展规范”,GBK兼容GB2312标准,同时在GB2312标准的基础上扩展了GB13000包含的字,但编码不同
- GBK标准中收录了2万多汉字及符号,因其最早被WINDOWS采用,所以其应用范围非常广
————————————————————————————————————————————————————————————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号