吴恩达机器学习笔记 —— 13 支持向量机
本章讲述了SVM,相比于《统计学习方法》,从逻辑回归的角度更容易理解了。
更多内容参考 机器学习&深度学习
从逻辑回归来看,看损失值与Z的值的关系:
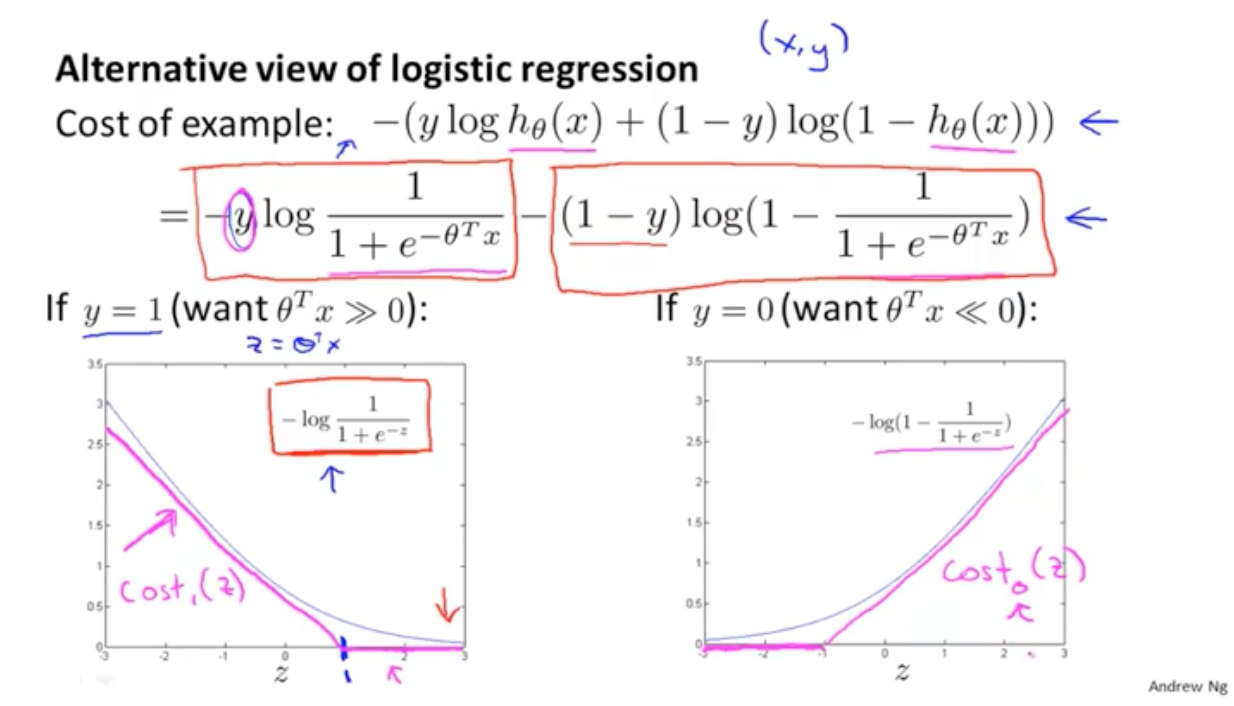
代入原来的是指,可以化简公式:
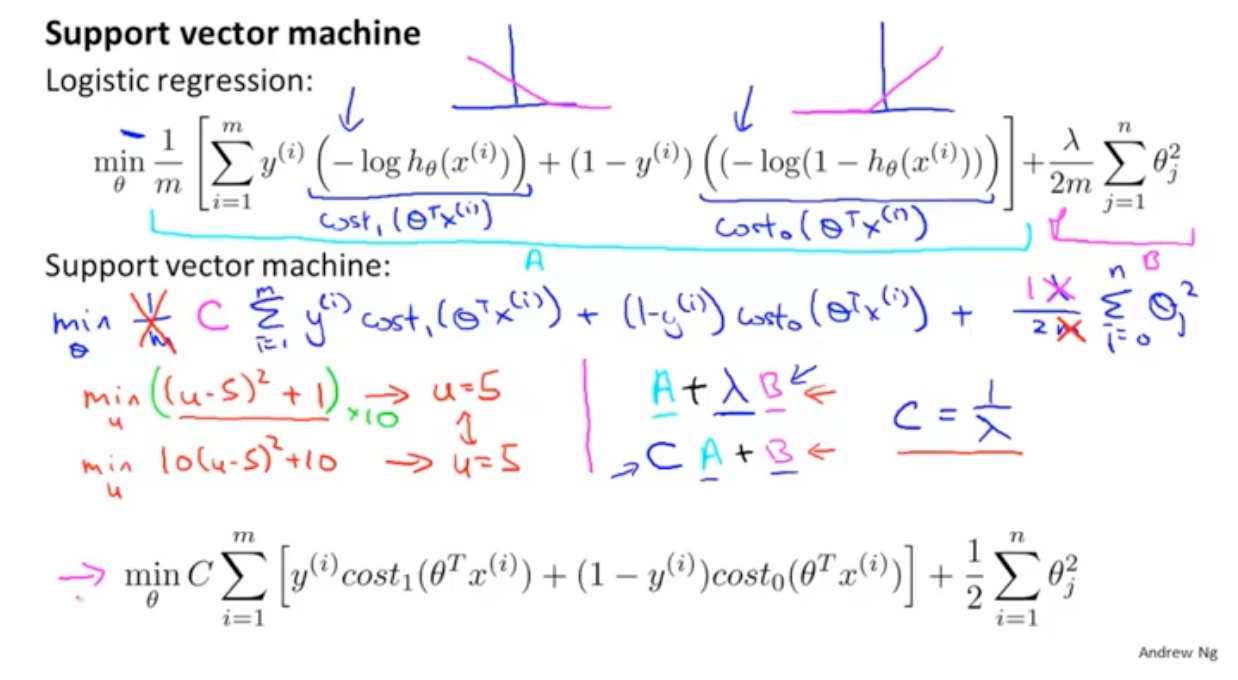
总结来说:如果y=1,我们希望z的值大于等于1,如果y=0,我们希望z的值小于-1,这样损失函数的值都会为0.
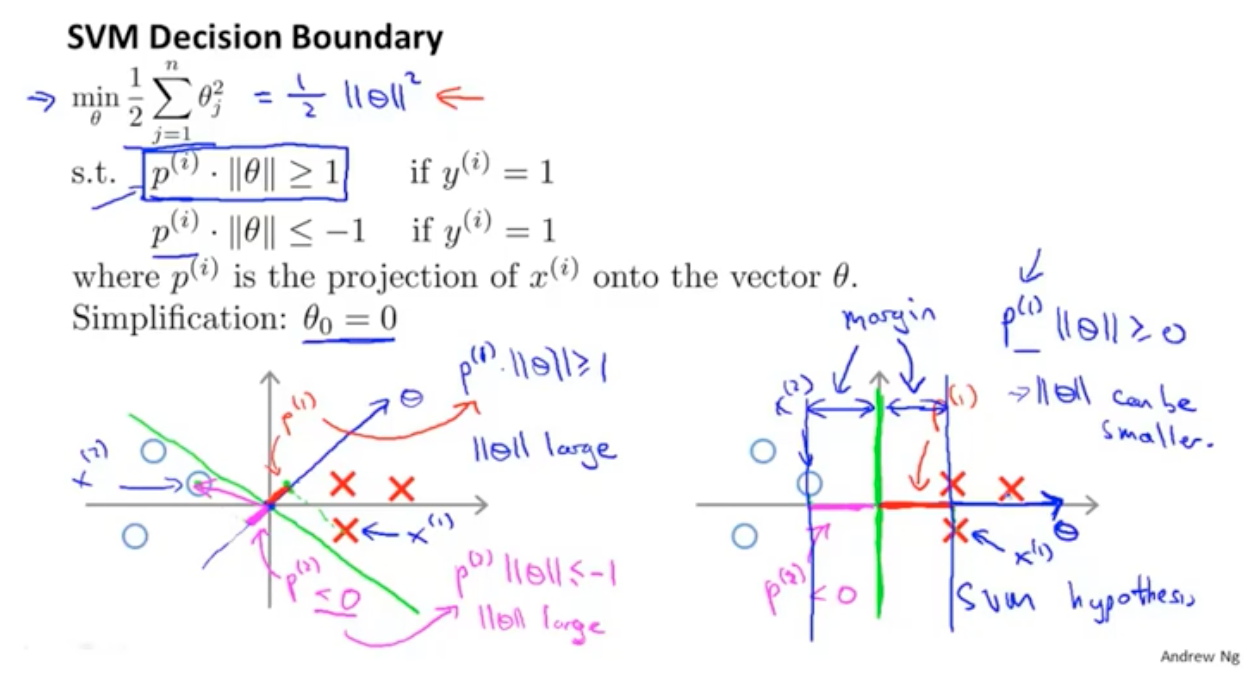
线性可分的决策边界:
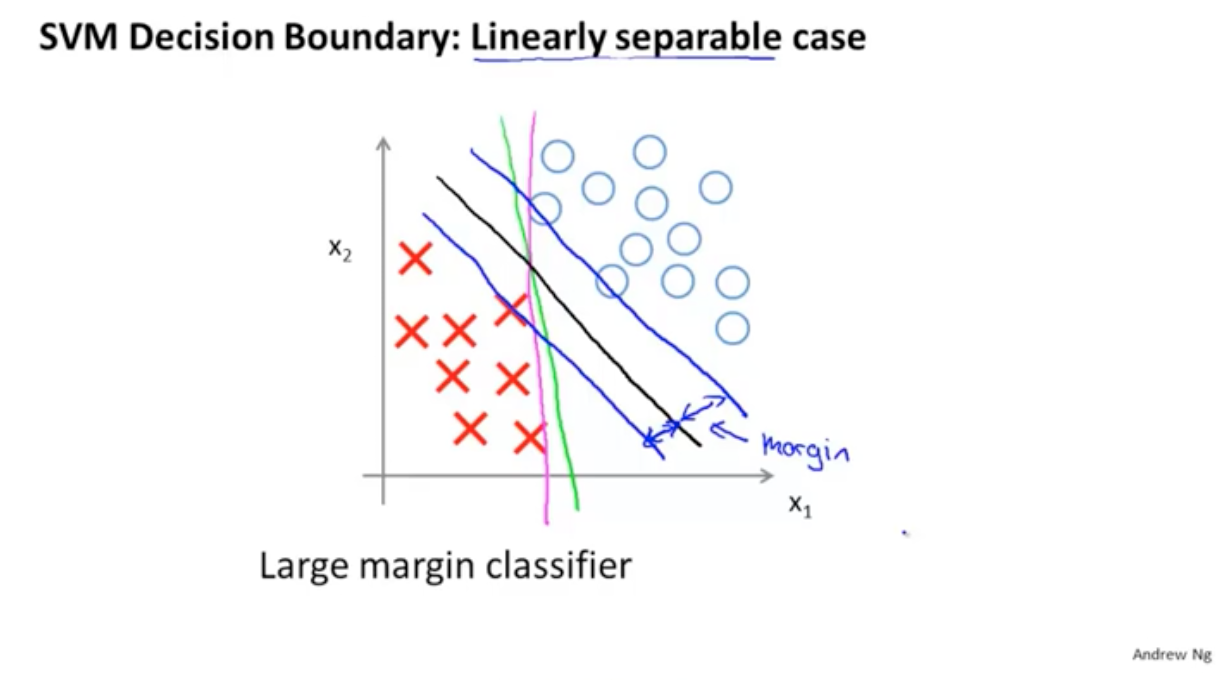
但是这种情况对于异常点是非常敏感的,比如有一个红点,那么决策边界就会发生很大的变化。
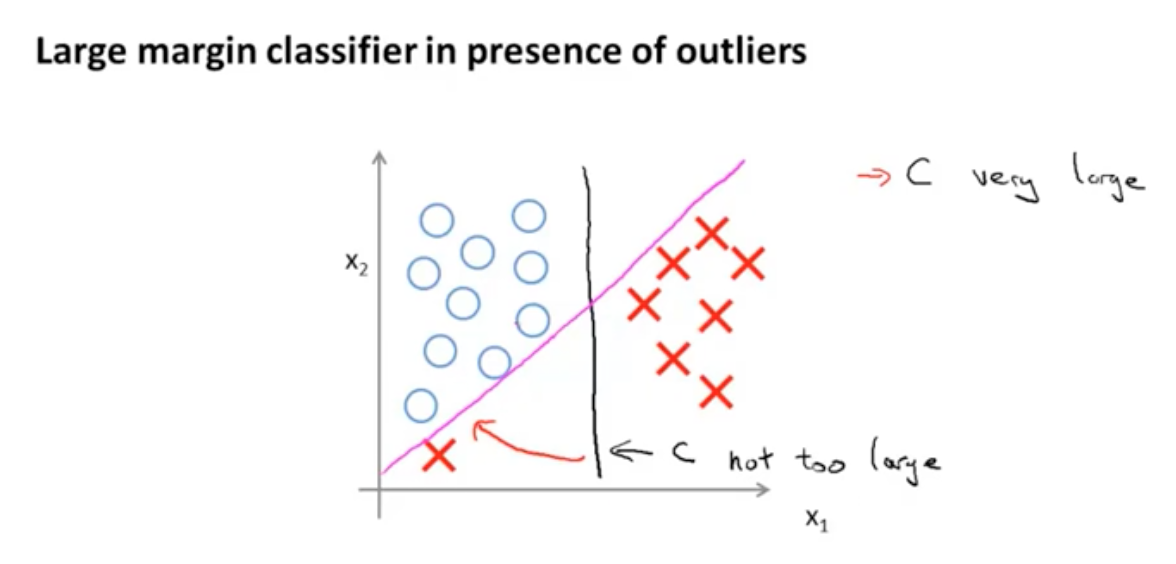
此时希望C不要太大,即λ非常大,鲁棒性更强。
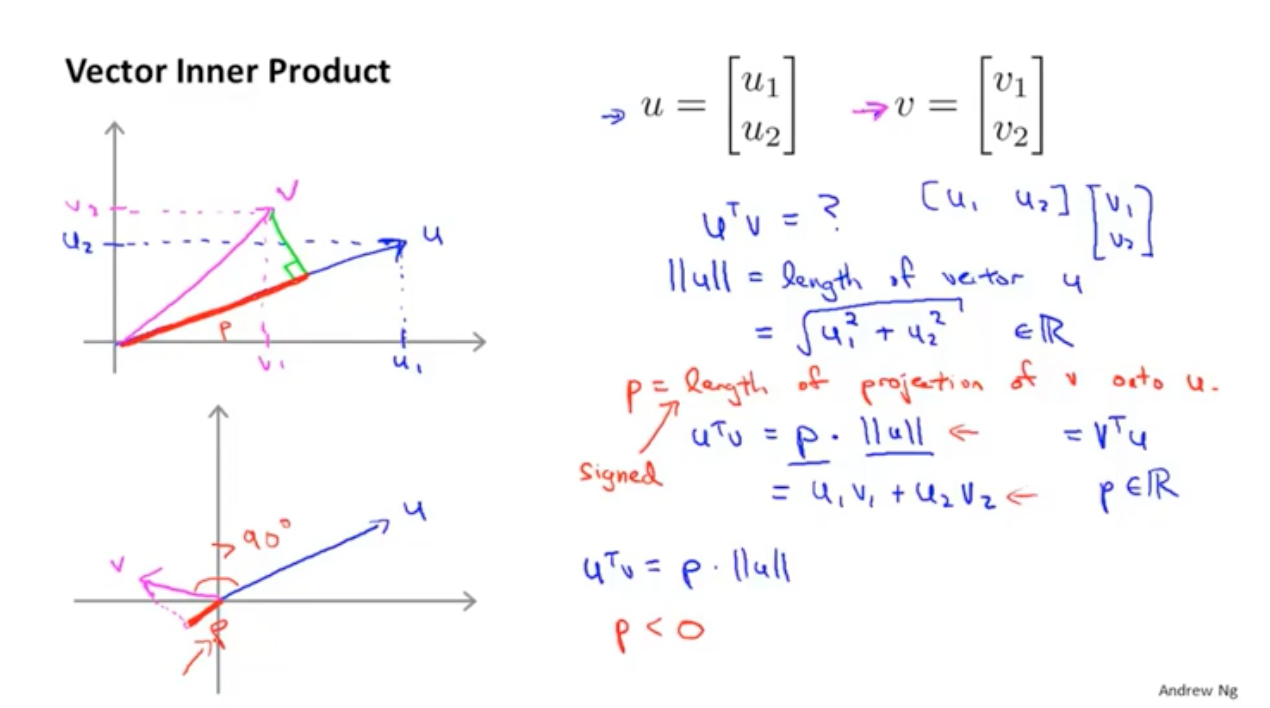
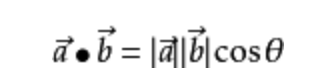
对于向量空间中的两个向量,向量的內积等于p*向量U的长度。
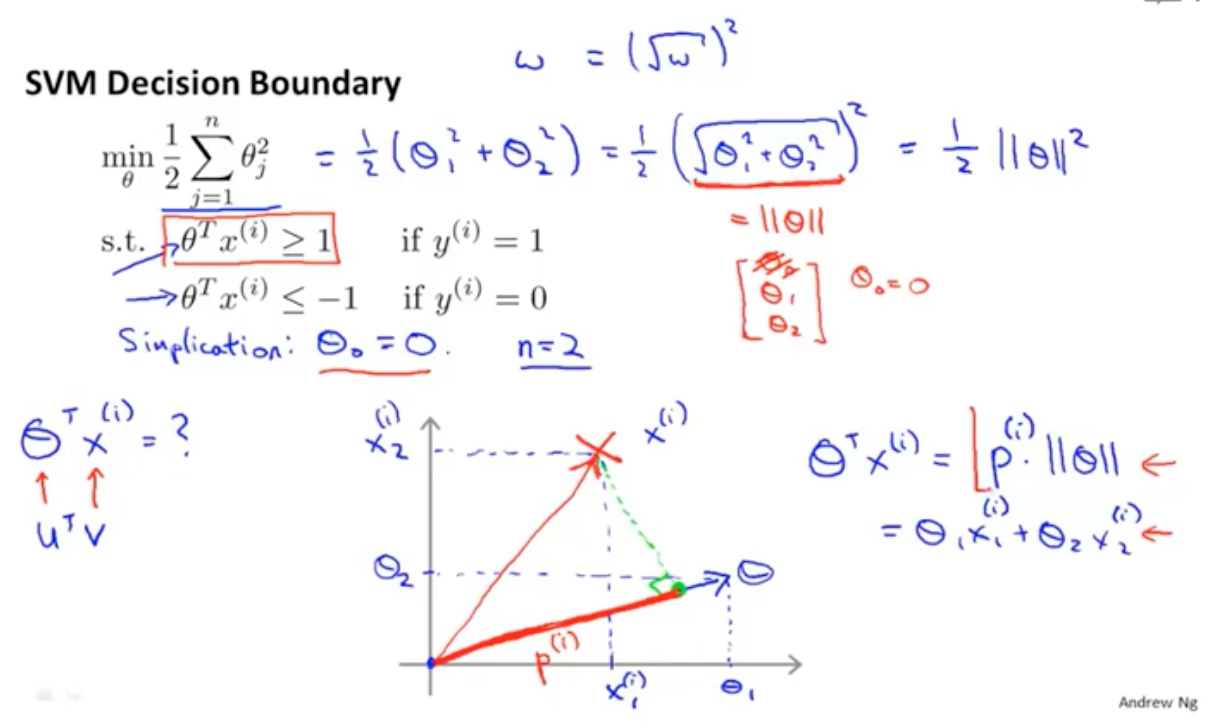
这样θTx就转换成了对向量θ的投影了
在逻辑回归中基于决策边界进行分类,但是特征需要手动来创造,很难去造全比较好的特征

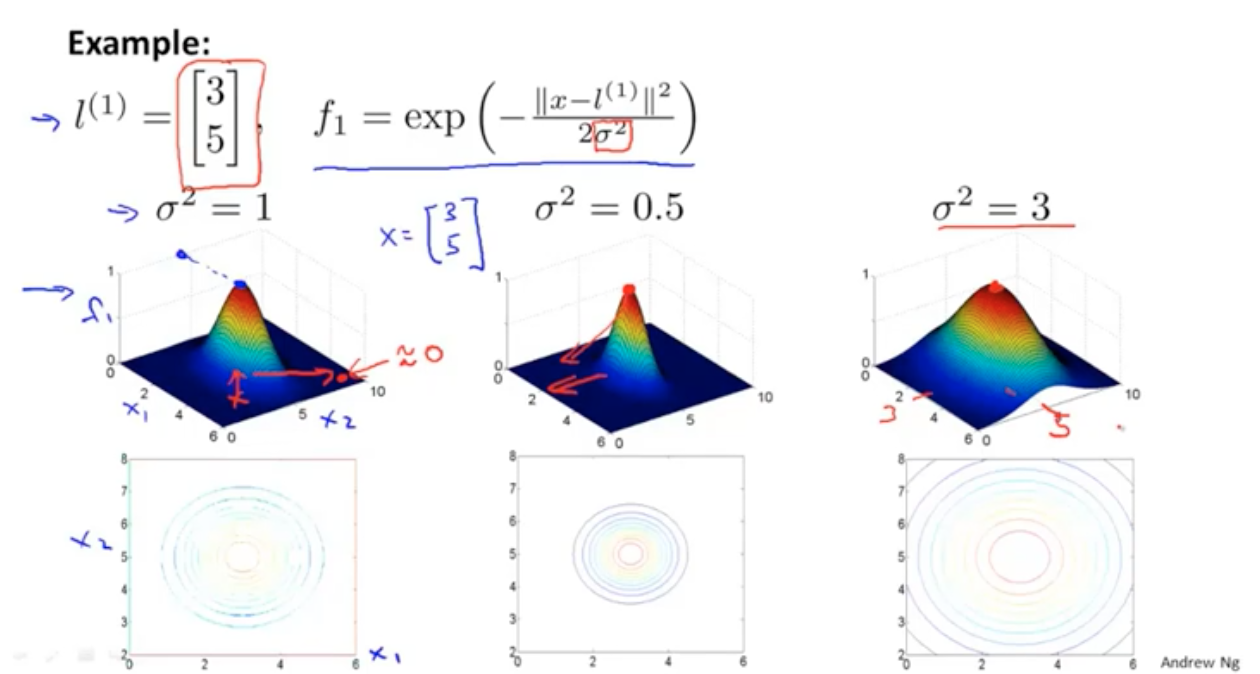
首先假设几个样本的参照点,l1,l2,l3,然后计算每个x与这三个点的相似度,这里是用的高斯混合

这个similarity就是kernel函数。
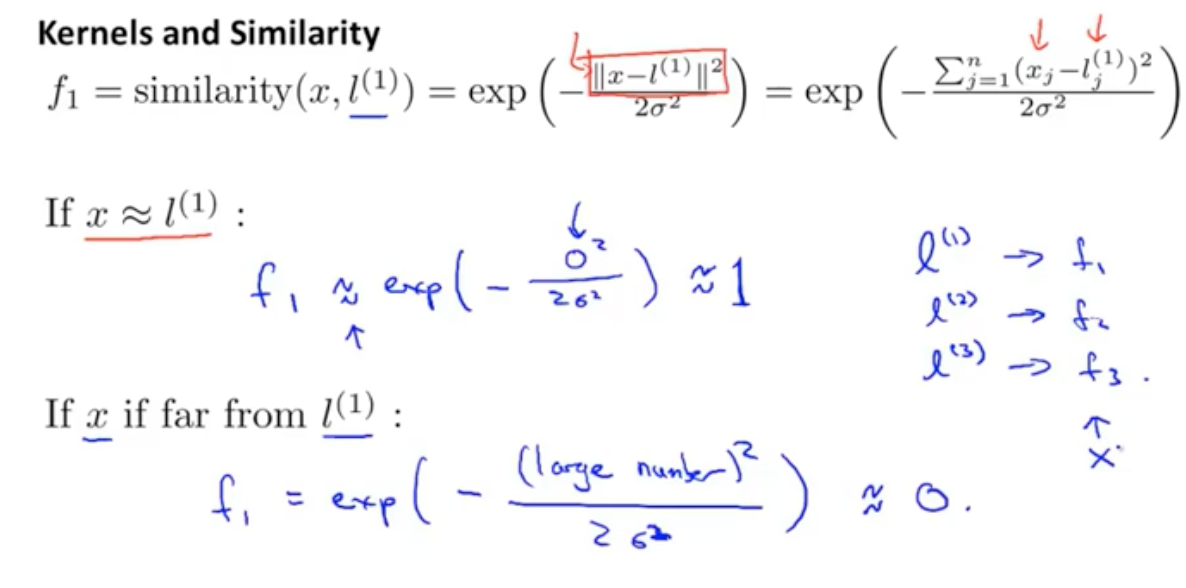
similarity最大是1,最小是0。当两个向量一模一样的时候等于1。
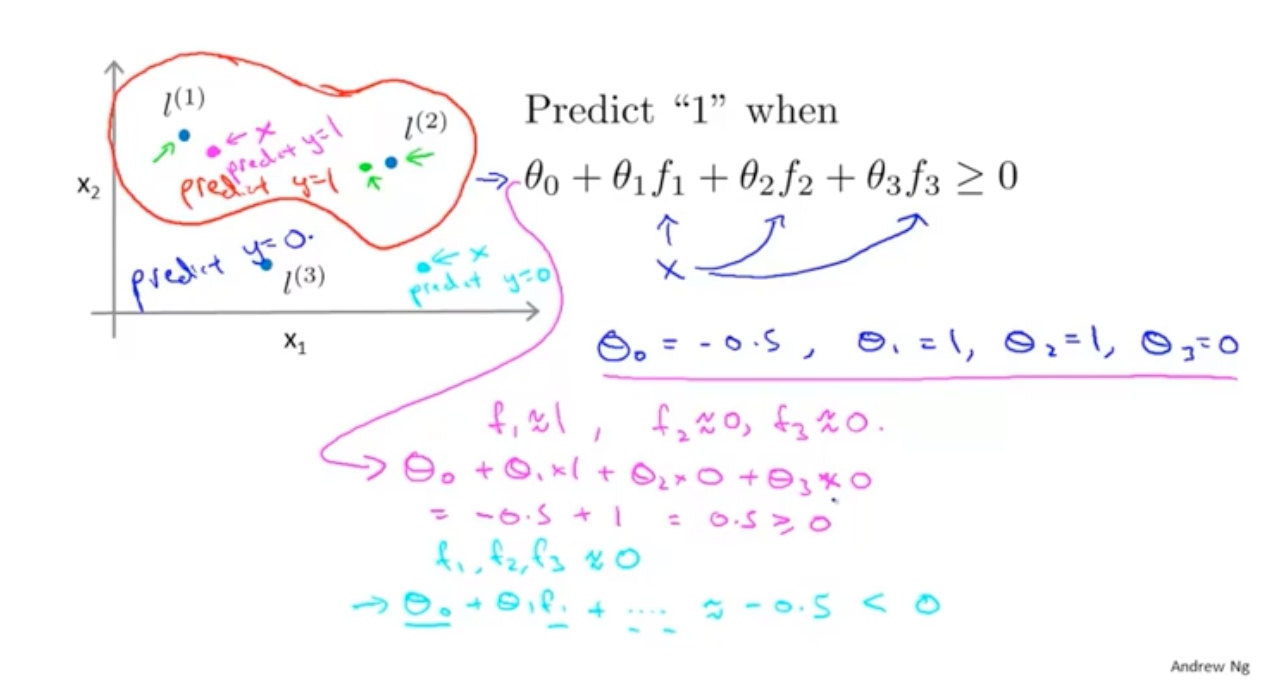
通过选取的点与计算出f值,然后带入到公式,就能得出决策边界:
如何选择l呢,最简单的就是把所有的样本点都当做l。然后计算x与所有样本点的高斯核:



有很多的软件可以算SVM了,只需要选择参数C和kernel函数就行了

逻辑回归和SVM的区别:
- 1 如果特征的维度比样本的维度还高,使用逻辑回归或者不带核函数的SVM。因为没有那么多数据来拟合更高级的函数
- 2 如果n很小,m适中,那么可以使用高斯核的SVM
- 3 如果n很小,m很大,那么使用逻辑回归或者不带核函数的SVM都可以,不然使用高斯核计算会很慢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号