吴恩达机器学习笔记 —— 18 大规模机器学习
本章讲了梯度下降的几种方式:batch梯度下降、mini-batch梯度下降、随机梯度下降。也讲解了如何利用mapreduce或者多cpu的思想加速模型的训练。
更多内容参考 机器学习&深度学习
有的时候数据量会影响算法的结果,如果样本数据量很大,使用梯度下降优化参数时,一次调整参数需要计算全量的样本,非常耗时。
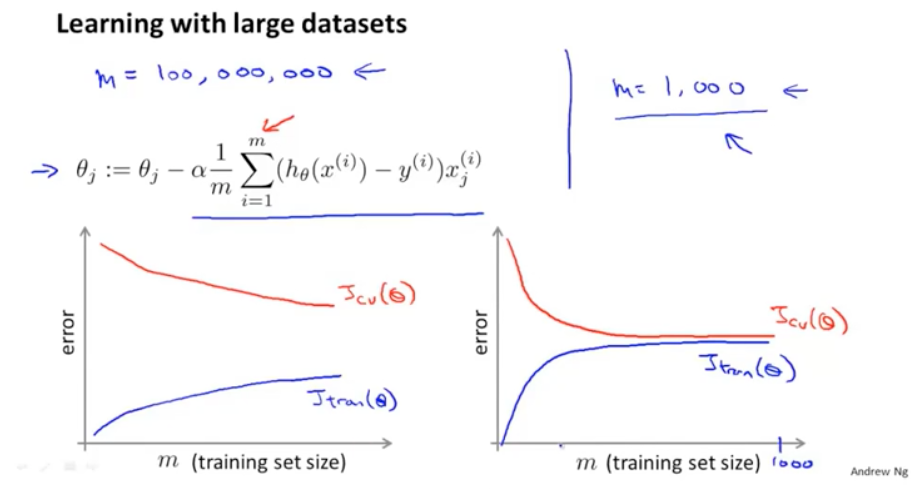
如果训练集和验证集的误差像左边的图形这样,就可以证明随着数据量的增加,将会提高模型的准确度。而如果像右边的图,那么增加样本的数量就没有什么意义了。
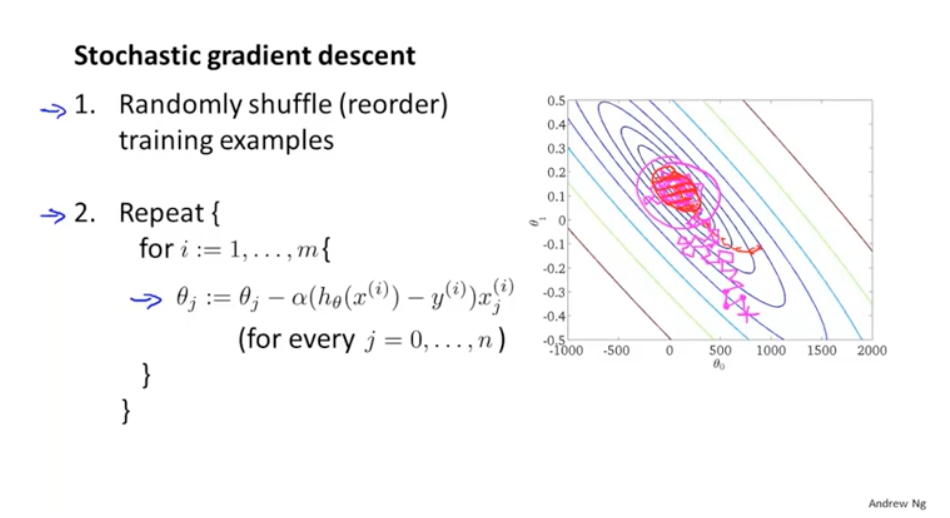
因此可以考虑缩小m的使用量,可以使用随机梯度下降。随机梯度下降的过程是:随机打散所有的样本,然后从第一个样本开始计算误差值,优化参数;遍历所有的样本。这样虽然优化的方向比较散乱,但是最终还是会趋于最优解。
还有一种方式叫做小批量梯度下降,每次使用一小部分的数据进行验证。比批量梯度下降更快,但是比随机梯度下降更稳定。

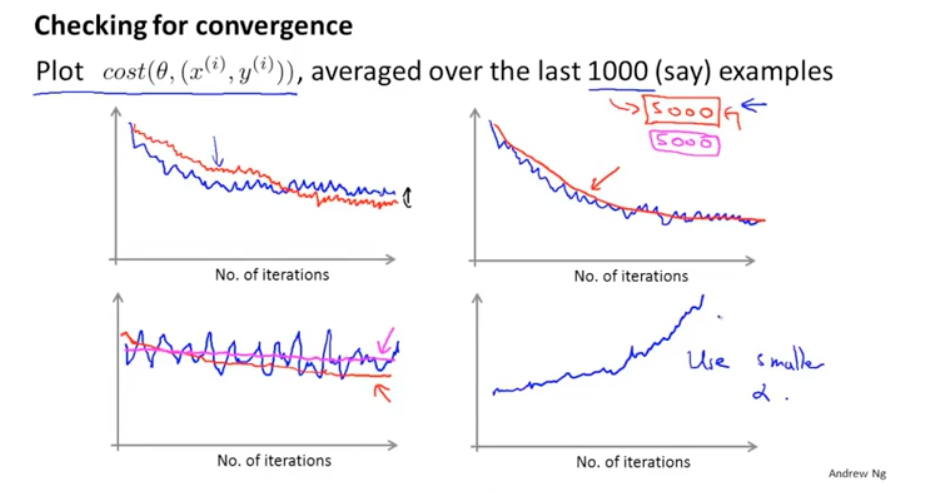
针对损失函数和batch的数量,可以画出下面的图:图1的震荡曲线可以忽略,此时的震荡可能是由于局部最小值造成的;图2如果增加数量能使得曲线更平滑,那么可以考虑增加batch的数量。图3 可能是模型根本没有在学习,可以考虑修改一下其他的参数。图4可能是因为学习太高,可以使用更小的学习率。
在线学习就是随着数据的获取,增量的来当做每个batch进行训练。
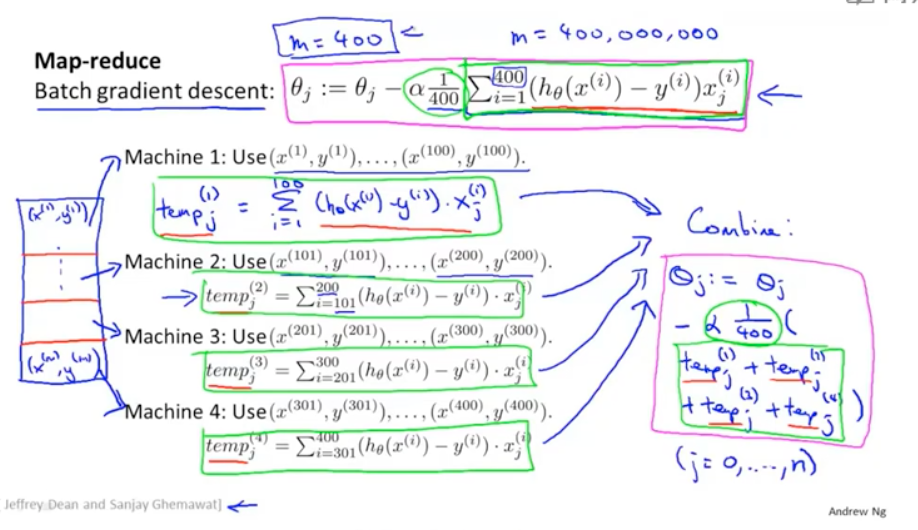
如果数据的样本很大,其实也可以通过map reduce的方式来进行并行处理,比如把数据切分成很多块,每个map运行完,统一在reduce端进行参数梯度下降学习。多CPU的情况下,也是同样的道理。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2016-08-04 Kafka与Logstash的数据采集对接 —— 看图说话,从运行机制到部署
2015-08-04 《胡雪岩·灯火楼台》—— 读后总结
2015-08-04 Elasticsearch使用REST API实现全文检索
2014-08-04 linux安装oracle