吴恩达机器学习笔记 —— 16 异常点检测
本篇介绍了异常点检测相关的知识
更多内容参考 机器学习&深度学习
我感觉这篇整理的很好很用心,可以详细参考:
https://blog.csdn.net/Snail_Moved_Slowly/article/details/78826088
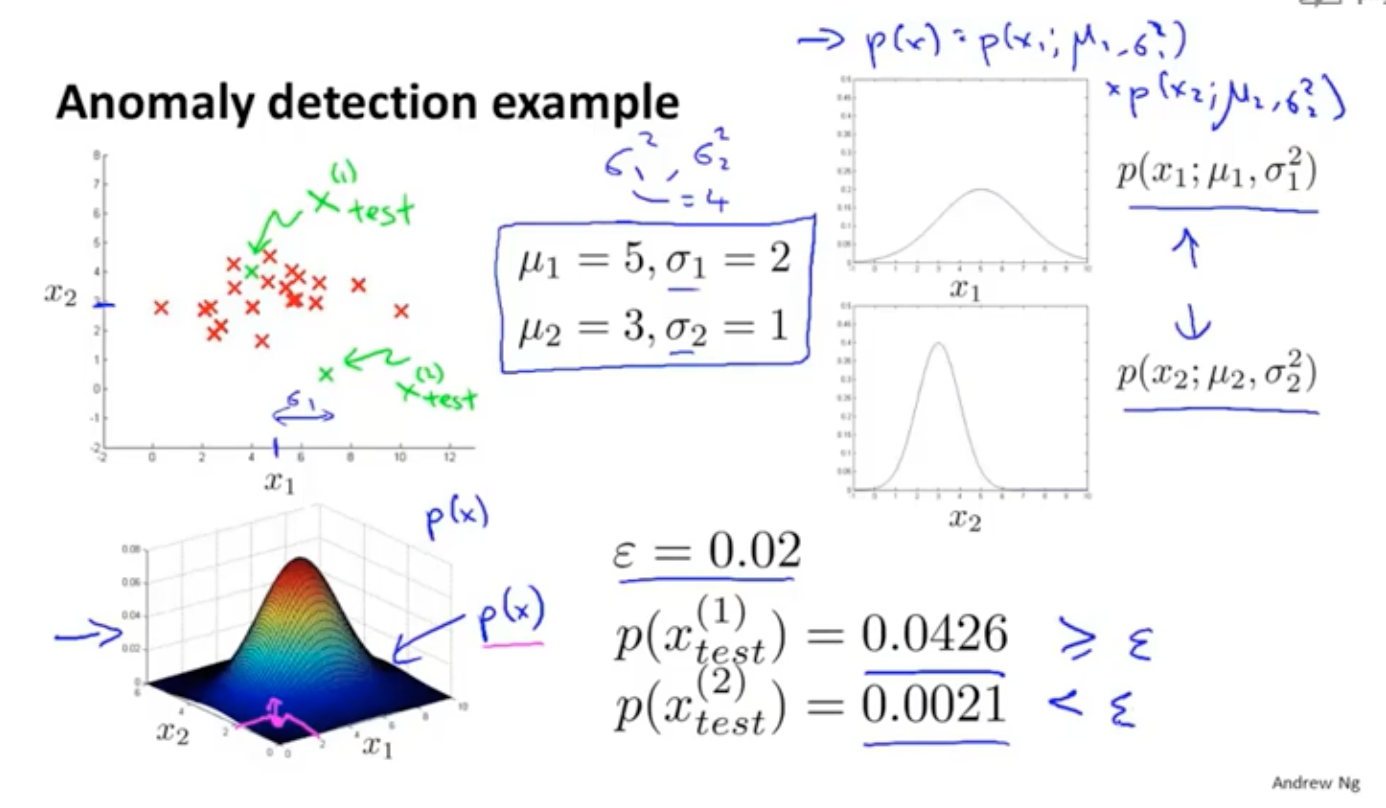
什么是异常点检测?比如针对飞机的引擎做测试,x1代表温度、x2代表引擎的震动等等,希望判断新生产的引擎是否有问题。如果这个新的引擎在点的中心可能是正常的,如果离大部分的样本点都很远,那就可能是异常点。
另外可以假设有一个模型可以预测概率,如果P<ξ,就是异常点;如果P>ξ就是正常点。再比如消费者的信用行为、数据中心的监控等等。
高斯分布也叫做正态分布,描述了数据分布的情况

使用高斯分布进行异常点检测的算法流程:
1 选择可能产生异常值影响的特征
2 计算每个特征的平均值和方差
3 基于方差和均值计算p(x)

得到结果后就可以进行异常点的判断了,比如ξ选择了0.02,那么就可以对各个样本点进行对比,小于它的,就认为是异常点。
那么如何开发一个异常点检测的应用呢。如果能有部分的样本带有标注y=1或者y=0,就可以基于这些数据做为模型的评价了。如果我们有10000个正常点,20个异常点。那么可以分配6000个正常点作为训练集,10个异常点+2000个正常点作为验证集,剩下的作为测试集。然后使用P R F1做为模型的评估。
异常点检测和监督学习还是不同的:首先就是异常点检测异常样本极少,而监督学习要求正常样本点和异常点都很多才行。在数据分布方面,高斯分布需要各个维度都保持在正态分布;模型训练方面,异常点只是在验证集与测试集上起作用。
在使用高斯分布之前应该把数据构造成正态分布的样子,否则就是用一些Log或者开方等方法,使得图形贴近高斯分布。如果选择了一个特征,结果异常点在样本点中间,那么最好能开发一些新的特征,使得这个异常点脱离正常点。
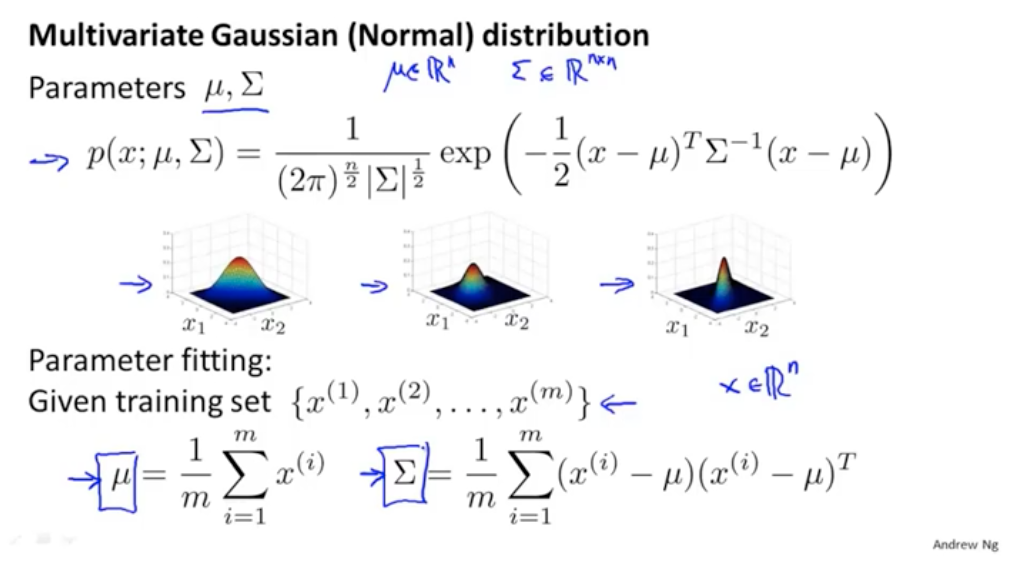
多元高斯分布是高斯分布的一种特殊情况,他们也有不同的使用场景:
1 高斯分布需要手动设计特征;多变量多元高斯分布则可以自己捕获特征
2 高斯分布的计算代价比较小;
3 高斯分布在m样本量比较少的时候也无所谓;多元高斯分布由于要构造一个矩阵,所以需要保证m有足够的量
多元高斯分布的出现主要是解决多个特征拟合后,虽然在自己的维度都不属于异常点,但是通过多元的作用,就可以把异常点排除。






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?