吴恩达机器学习笔记 —— 14 无监督学习
本章讲述的是第一个无监督的机器学习算法,在无监督的算法中,样本数据只有特征向量,并没有标注的y值。比如聚类算法,它可以用在市场分类、社交网络分析、天体数据分析等等。
更多内容参考 机器学习&深度学习
在做聚类时,最简单的算法就是k-means,一般的流程是:
- 首先随机选择k个聚类中心点
- 遍历所有的样本,选择一个距离最近的中心点,并标记为对应的聚类
- 重新针对类簇计算中心点
- 重复2-3的过程
还有一个算法在这次的课程中没有提到,就是kmeans++,它与上面的kmeans不同的是,选择中心点是首先随机选择一个,然后选择一个离当前最远的作为下一个中心点....
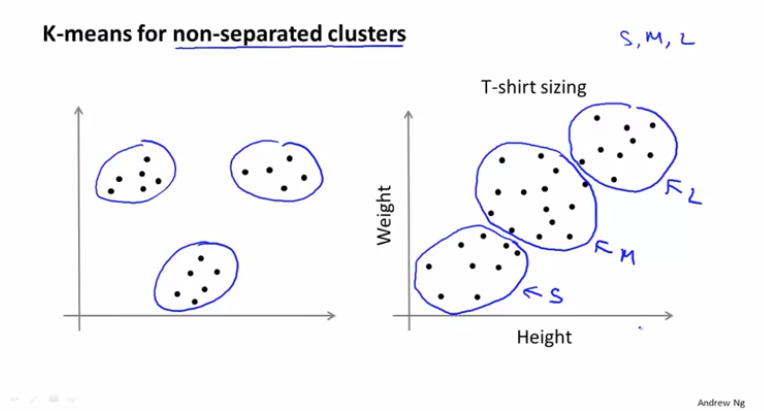
聚类算法有时候并不是那么完美分割的,大部分的时候数据都是连接在一起的:
k-means的优化目标:其实就是每个样本点与其中心点计算一次距离,全部样本的平均距离就是算法的优化目标,min(path)越小,代表聚类算法越好。不过细想一下,如果K越大,这个值就会越小。所以这个值也只能作为一个参考而已...

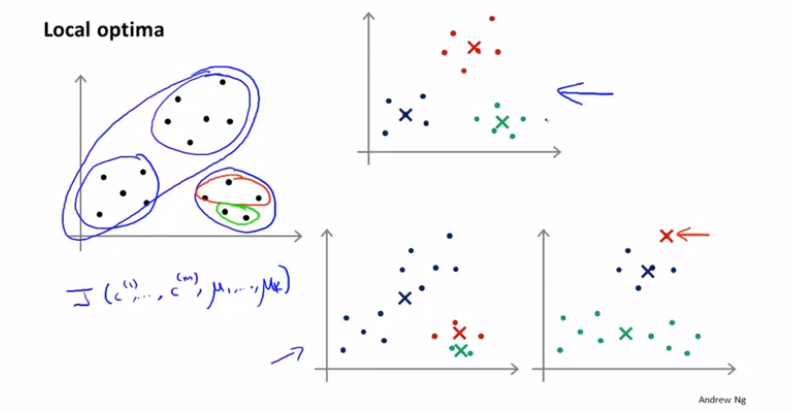
k-means的算法效果很大程度上取决于初始节点的选取。因此可以多尝试随机几次看看效果:
在聚类算法中还有一个很重要的问题,就是K值如何选取:可以通过下面的肘点法选择,比如下面左边的图,随着k的值增加,损失值开始下降,那么那个拐点就是我们选择的最佳值;不过有时候,曲线会像右边的图一样,这时肘点法就不起作用了,最终可以依赖于业务含义来选择k的值。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号