HBase跨地区机房的压测小程序——从开发到打包部署(图文版)
今天做了一个跨地区机房的压测小程序,主要的思路就是基于事先准备好的rowkey文件,利用多线程模拟并发的rowkey查询,可以实现并发数的自由控制。主要是整个流程下来,遇到了点打包的坑,所以特意记录下。
编写代码
rowkey文件的准备就不说了。首先是HbaseClient的查询接口,由于创建连接的代价很重,因此这里采用HBase的ConnectionFactory工厂:
static {
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "此处不可描述");
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
private static Table getTable(String table) throws IOException {
return connection.getTable(TableName.valueOf(table));
}
查询的时候直接使用get Api即可:
try (Table tab = getTable(table)) {
Get get = new Get(Bytes.toBytes(key));
Cell cell = tab.get(get).getColumnLatestCell(COLUMN_FAMILY, Bytes.toBytes(field));
column = Bytes.toString(CellUtil.cloneValue(cell));
} catch (Exception e) {
logger.error("查询请求出错:" + e.getMessage());
}
为了模拟并发,我这边直接使用了Fixed线程池,并且基于java8的lambda表达式创建线程池:
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(100);
for(String line : lines){
fixedThreadPool.execute(() -> {
Long start = System.currentTimeMillis();
// ... todo ... 我这里只想统计一下平均的访问时间,所以就简单的做减法就行了
Long end = System.currentTimeMillis();
System.out.println(end-start);
});
}
基于Idea打包
整体的项目结构大致如下:

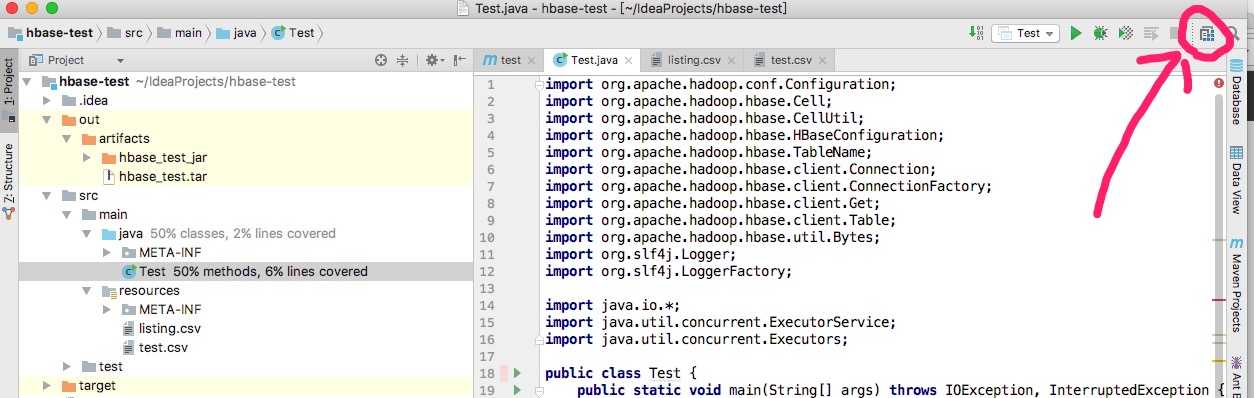
点击project structure
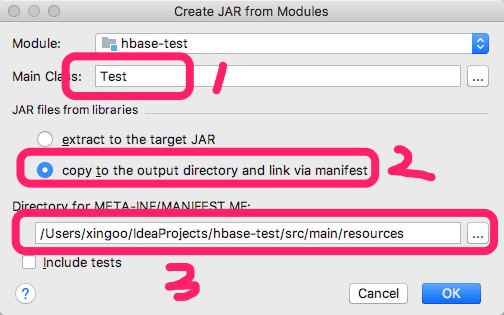
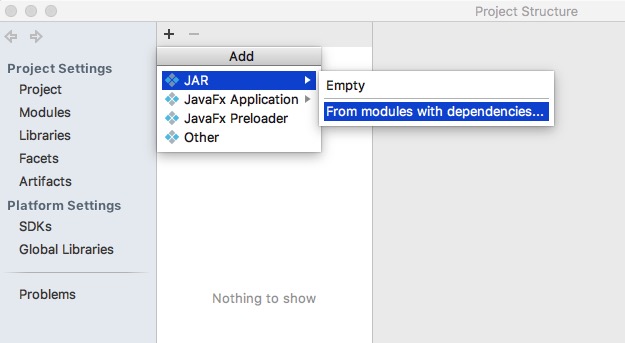
点击add-->jar-->from models with dependencies...
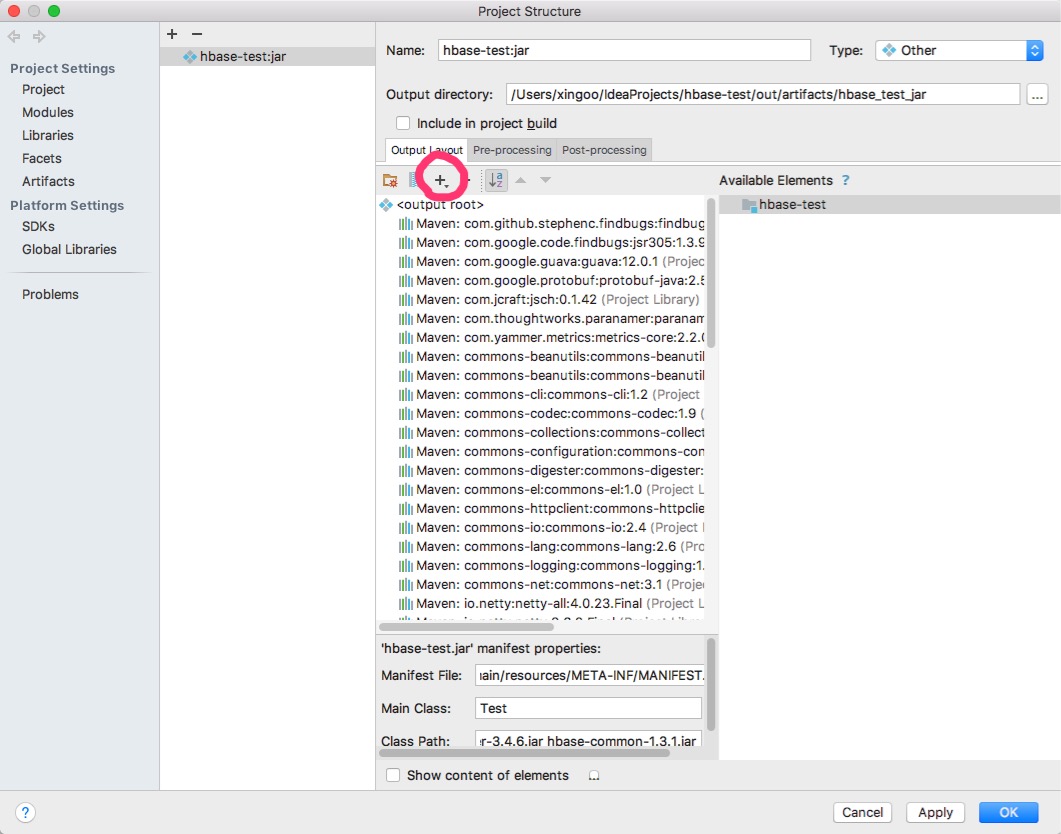
选择对应的资源文件加入到打包路径中
点击build-->build artifacts-->build进行打包
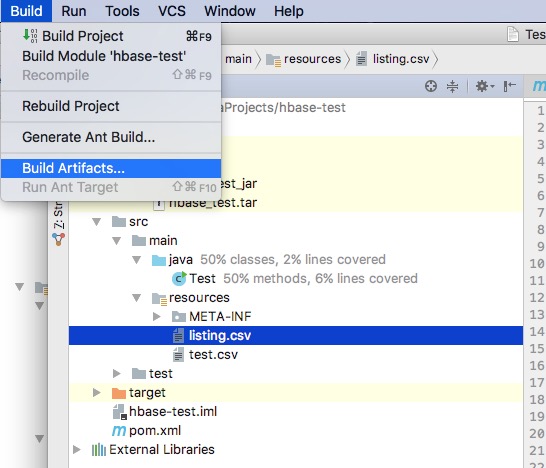
观察文件MANIFEST.MF可以看到里面包含的内容:
Manifest-Version: 1.0
Class-Path: commons-beanutils-core-1.8.0.jar netty-all-4.0.23.Final.ja
r hadoop-auth-2.5.1.jar snappy-java-1.0.4.1.jar protobuf-java-2.5.0.j
ar jcodings-1.0.8.jar hadoop-yarn-common-2.5.1.jar httpclient-4.2.5.j
ar commons-math3-3.1.1.jar commons-lang-2.6.jar findbugs-annotations-
1.3.9-1.jar jaxb-api-2.2.2.jar slf4j-api-1.6.1.jar commons-el-1.0.jar
commons-beanutils-1.7.0.jar commons-collections-3.2.2.jar commons-ht
tpclient-3.1.jar commons-io-2.4.jar avro-1.7.4.jar hamcrest-core-1.3.
jar hbase-client-1.3.1.jar slf4j-log4j12-1.6.1.jar commons-logging-1.
2.jar hadoop-yarn-api-2.5.1.jar hbase-protocol-1.3.1.jar netty-3.6.2.
Final.jar commons-configuration-1.6.jar hadoop-annotations-2.5.1.jar
jackson-core-asl-1.9.13.jar paranamer-2.3.jar junit-4.12.jar metrics-
core-2.2.0.jar jsr305-1.3.9.jar stax-api-1.0-2.jar hadoop-common-2.5.
1.jar commons-compress-1.4.1.jar apacheds-i18n-2.0.0-M15.jar api-asn1
-api-1.0.0-M20.jar jackson-mapper-asl-1.9.13.jar commons-codec-1.9.ja
r xz-1.0.jar htrace-core-3.1.0-incubating.jar activation-1.1.jar hado
op-mapreduce-client-core-2.5.1.jar commons-net-3.1.jar commons-digest
er-1.8.jar hbase-annotations-1.3.1.jar jsch-0.1.42.jar commons-cli-1.
2.jar xmlenc-0.52.jar httpcore-4.2.4.jar joni-2.1.2.jar api-util-1.0.
0-M20.jar apacheds-kerberos-codec-2.0.0-M15.jar log4j-1.2.17.jar jett
y-util-6.1.26.jar guava-12.0.1.jar zookeeper-3.4.6.jar hbase-common-1
.3.1.jar
Main-Class: Test
我们需要的文件就都保存在/project_home/out目录下了,
传输到远程服务器
首先进入对应的out目录,执行下面的命令:
tar -cvf hbase_test.tar hbase_test_jar
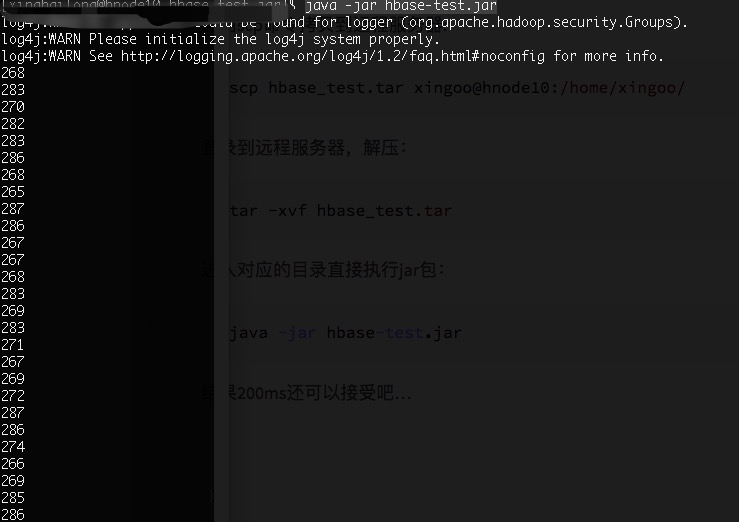
使用scp命令拷贝到远程服务器:
scp hbase_test.tar xingoo@hnode10:/home/xingoo/
登录到远程服务器,解压:
tar -xvf hbase_test.tar
进入对应的目录直接执行jar包:
java -jar hbase-test.jar
结果200ms还可以接受吧...



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2015-11-24 Elaticsearch REST API常用技巧