《Spark MLlib 机器学习实战》1——读后总结
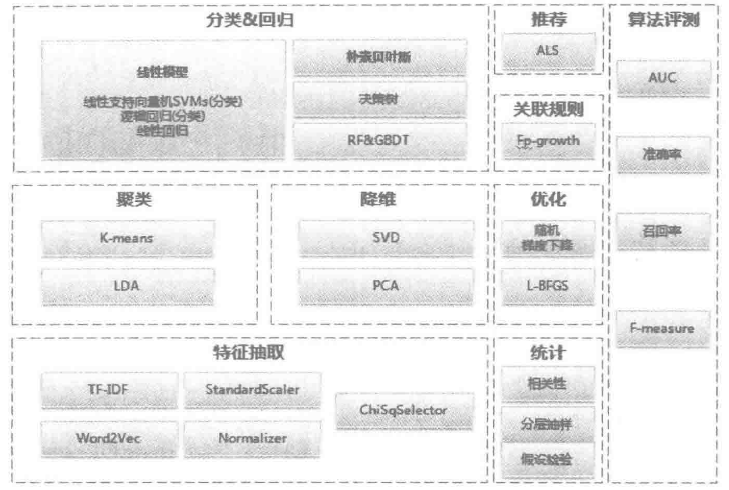
1 概念
2 安装
3 RDD
RDD包含两种基本的类型:Transformation和Action。RDD的执行是延迟执行,只有Action算子才会触发任务的执行。
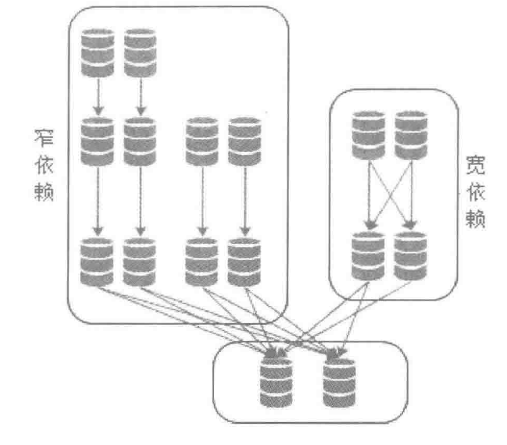
宽依赖和窄依赖用于切分任务,如果都是窄依赖,那么就可以最大化的利用并行。
常用操作:
- cache 缓存
- cartesian 笛卡尔积
- coalesce 重分区
- countByValue 分组统计
- distinct 去除重复
- filter 过滤
- flatMap
- map
- groupBy 分组
- keyBy 增加key
- reduce 拼接
- sortBy 排序
- zip 合并压缩
4 基本概念
基本的数据结构
MLlib中提供几种向量和矩阵的数据结构:
- Local vector,本地向量
- Labeld point,带标签的向量
- Local Matrix,本地矩阵
- Distributed matrix,分布式矩阵
一般向量或者矩阵都有两个方法,dense表示密集版,sparse表示稀疏版,稀疏版是可以指定下标的。
基本的统计方法
- colStats 以列统计基本数据,count个数、max最大值、mean最小值、normL1欧几里德距离、normL2曼哈顿距离、numNonzeros不为0的个数、variance标准差
- chiSqTest 皮尔逊距离计算,
Statistics.corr(rddx,rddy,"spearman") - corr 数据集相关系数计算,
Statistics.corr(rddx,rddy) - 分层抽样
data.sampleByKey(withReplacement=false,fractions,0) - 假设检验
自由度、统计量、P值、卡方检验 - 随机数
RandomRDDs.normalRDD(sc,100)
5 协同过滤
协同过滤可以基于人也可以基于物品,不足之处在于:
- 基于人会对热点物品不够精确
- 基于物品,但是没有什么多样性
相似度度量
- 基于欧几里德距离的计算
- 基于夹角余弦的相似度计算
他们的区别:
- 欧几里德注重空间上的差异
- 夹角余弦注重趋势
最小二乘法
最小二乘,就是基于均方误差寻找最佳匹配函数的过程。在矩阵中就是把大矩阵拆分成连个小矩阵的计算。
实践
new ALS()
rank 隐藏的因子数
iterations 迭代次数
lambda 正则项参数
implicitPref 显示反馈还是隐式反馈
alpha 拟合修正的幅度
6 线性回归
梯度下降
道士下山的例子,以及随机梯度下降中 θ=θ-α*J'(θ)公式的原理。
正则项
避免过拟合,可以使用正则项——lasso回归(L1)和岭回归(L2)。关于岭回归可以参考下面两篇:
- http://baike.baidu.com/link?url=Z51DHIIFnkdsYyx13q7qk24hB_-XUqW3e7IdHsz4gZbjbNx718tzMxVfWibdZOG7Y0Aa4HOZdqhsHDA1rEbW9z-8iNYAb4ykjU6kyhNakSoHQ9Yjk7EyAJnidhE3B_Gx
- http://www.ics.uci.edu/~welling/teaching/KernelsICS273B/Kernel-Ridge.pdf
7 分类
分类算法,包括 逻辑回归、支持向量机SVM、贝叶斯等。
逻辑回归
跟线性回归差不多,多了一个sigmoid函数,输出的内容也稍有变化。
另外,对于损失函数的推导也不同了,这里需要最大似然估计的知识!
基本的流程就是,确定1或者0的概率,然后推导出极大似然公式,然后取对数,求导...最终基于梯度下降,优化参数。
由于忘记最大似然估计,所以这里真是理解不上去.
支持向量机
求解的是划分边界的最优解,他的名字听起来像一种很高级的机器人,其实跟逻辑回归差不多,就是选取一条最优的线把数据分作两类。
这里有疑问的可以参考——逻辑回归和SVM的区别是什么?各适合解决什么问题?
https://www.zhihu.com/question/24904422?sort=created
暂时不知道它的损失函数是怎么算出来的...慢慢研究吧
朴素贝叶斯
明明就是计算概率,非叫这么高大上的名字。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2016-06-14 Java程序员的日常 —— 注册工厂的妙用
2015-06-14 图解Tomcat类加载机制