[大数据之Yarn]——资源调度浅学
在hadoop生态越来越完善的背景下,集群多用户租用的场景变得越来越普遍,多用户任务下的资源调度就显得十分关键了。比如,一个公司拥有一个几十个节点的hadoop集群,a项目组要进行一个计算任务,b项目组要计算一个任务,集群到底先执行哪个任务?如果你需要提交1000个任务呢?这些任务又是如何执行的?
为了解决上面的问题,就需要在hadoop集群中引入资源管理和任务调度的框架。这就是——Yarn。
YARN的发展
Yarn在第一代的时候,框架跟hdfs差不多。一个主节点jobtracker,用来分配任务和监控任务运行情况;多个从节点tasktracker,用来执行真正的计算。

这种方式还是有一定的弊端的:
- tasktracker出现故障,会导致整个任务计算失败。
- jobtracker压力过大,既要负责全局的任务分配,还需要时刻与tasktracker沟通。
因此,就出现了第二代的YARN。

这种模式主要的特点,就是两个地方:
jobtracker被分离为两个角色,一个是resourcemanager,简称RM,仅仅负责任务的调度和应用的管理;一个是applicationmaster,简称AM,每个应用任务都会创建一个AM,用于申请任务需要的资源并且监控任务运行状况。
YARN资源调度流程
YARN的资源调度可以看官网提供的图片:
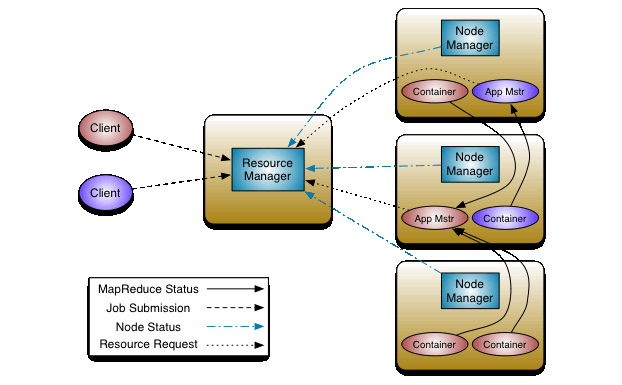
流程大致如下:
- client客户端向yarn集群(resourcemanager)提交任务
- resourcemanager选择一个node创建appmaster
- appmaster根据任务向rm申请资源
- rm返回资源申请的结果
- appmaster去对应的node上创建任务需要的资源(container形式,包括内存和CPU)
- appmaster负责与nodemanager进行沟通,监控任务运行
- 最后任务运行成功,汇总结果。
其中Resourcemanager里面一个很重要的东西,就是调度器Scheduler,调度规则可以使用官方提供的,也可以自定义。
官方大概提供了三种模式:
- FIFO,最简单的先进先出,按照用户提交任务的顺序执行。这种方式最简单,但是也一大堆问题,比如任务可能独占资源,导致其他任务饿死等。
- Capacity,采用队列的概念,任务提交到队列,队列可以设置资源的占比,并且支持层级队列、访问控制、用户限制、预定等等高级的玩法。
- Fair share,基于用户或者应用去平分资源,灵活分配。
capacity和fair share都是采用队列的模式,队列内部基本上还是FIFO。并且同级的队列任务,如果一个队列是空闲的,那么另一个队列任务可以使用资源;如果这个队列又提交了任务,则会抢占或者等待资源释放,直到资源到达预定的分配比例。
总的来说,YARN的资源调度还是比较完善的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号