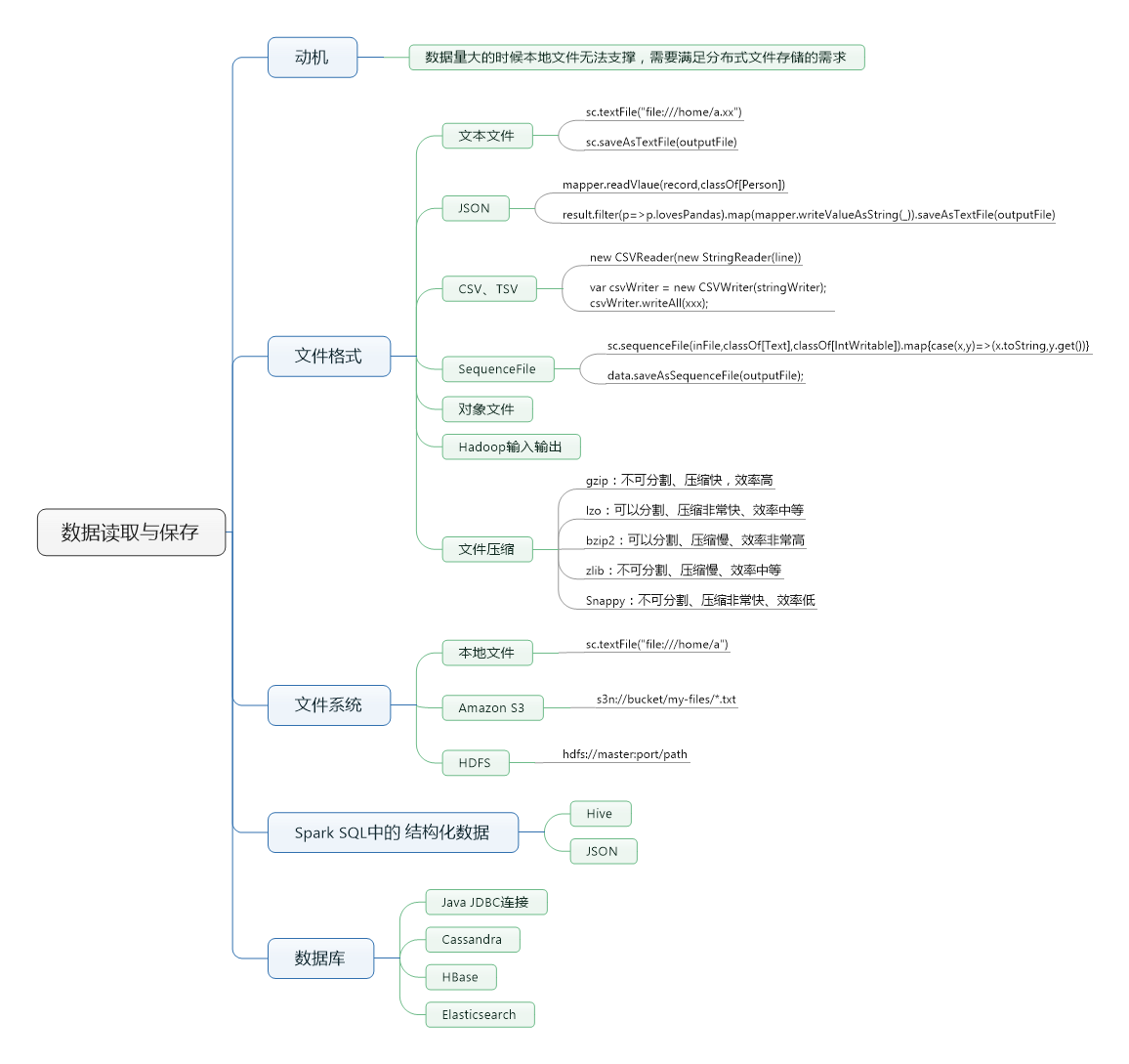
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~
扫码关注公众号,不定期分享大数据和机器学习工作经验与学习心得



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
2015-09-05 《胡雪岩·萧瑟洋场》—— 读后总结
2013-09-05 ADX3000 三层网络 纠错
2013-09-05 ADX3000二层的负载均衡设计问题