[Hadoop大数据]——Hive初识
Hive出现的背景
Hadoop提供了大数据的通用解决方案,比如存储提供了Hdfs,计算提供了MapReduce思想。但是想要写出MapReduce算法还是比较繁琐的,对于开发者来说,需要了解底层的hadoop api。如果不是开发者想要使用mapreduce就会很困难....
另一方面,大部分的开发者都有使用SQL的经验。SQL成为开发者必备的技能...
那么可以不可以使用SQL来完成MapReduce的过程呢?—— 答案就是,Hive
Hive能够解决的问题
Hive可以帮助开发者从现有的数据基础架构转移到Hadoop上,而这个基础架构是基于传统关系型数据库和SQL的。Hive提供了Hive查询语言,即HQL,它可以使用SQL方言查询存储在hadoop中的数据。
执行原理
Hive本身不会生成java的mapreduce程序,而是通过XML文件 驱动执行内置的、原生的Mapper和Reducer。
Hive的缺点
- 1 不支持记录级别的更新、插入或者删除
- 2 查询延迟比较严重
- 3 不支持事务
如果想要基于SQL还想具有上面的特性,可以直接使用hadoop提供的nosql数据库——HBase
适合的场景
Hive适合做 数据仓库 应用程序,可以维护海量数据,对数据进行挖掘,形成意见和报表。
其他
同类型的工具就是Pig
暂时的疑问!!
1 HQL是如何变成MapReduce算法的?
2 平时HQL都是怎么使用的?——最佳实践
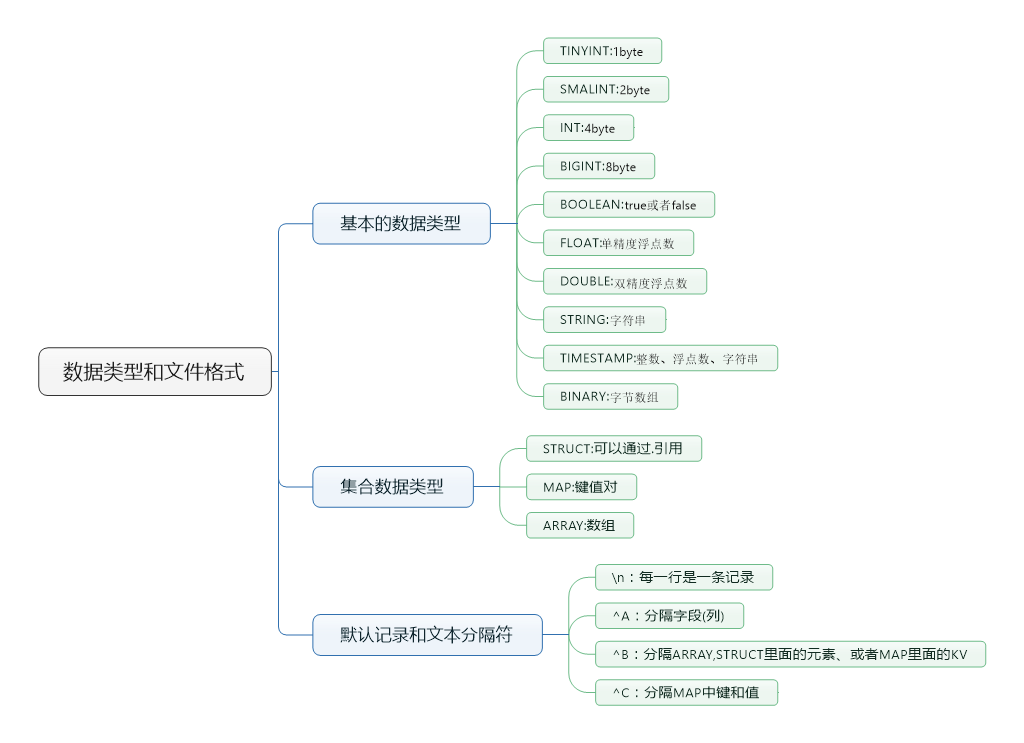
Hive中的数据类型与文件格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号