深度学习Tensorflow生产环境部署(上·环境准备篇)
最近在研究Tensorflow Serving生产环境部署,尤其是在做服务器GPU环境部署时,遇到了不少坑。特意总结一下,当做前车之鉴。
1 系统背景
系统是ubuntu16.04
ubuntu@ubuntu:/usr/bin$ cat /etc/issue
Ubuntu 16.04.5 LTS \n \l
或者
ubuntu@ubuntu:/usr/bin$ uname -m && cat /etc/*release
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
DISTRIB_CODENAME=xenial
DISTRIB_DESCRIPTION="Ubuntu 16.04.5 LTS"
NAME="Ubuntu"
VERSION="16.04.5 LTS (Xenial Xerus)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 16.04.5 LTS"
VERSION_ID="16.04"
HOME_URL="http://www.ubuntu.com/"
SUPPORT_URL="http://help.ubuntu.com/"
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
VERSION_CODENAME=xenial
UBUNTU_CODENAME=xenial
显卡是Tesla的P40
ubuntu@ubuntu:~$ nvidia-smi
Thu Jan 3 16:53:36 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.130 Driver Version: 384.130 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:3B:00.0 Off | 0 |
| N/A 34C P0 49W / 250W | 22152MiB / 22912MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 108329 C python 4963MiB |
| 0 133840 C tensorflow_model_server 17179MiB |
+-----------------------------------------------------------------------------+
TensorFlow则是当下最新的1.12.0版本。
2 背景知识
在介绍如何部署之前,先来了解一下相关的概念。
2.1 TensorFlow Serving
参考资料

TensorFlow Serving是google提供的一种生产环境部署方案,一般来说在做算法训练后,都会导出一个模型,在应用中直接使用。
正常的思路是在flask这种web服务中嵌入tensorflow的模型,提供rest api的云服务接口。考虑到并发高可用性,一般会采取多进程的部署方式,即一台云服务器上同时部署多个flask,每个进程独享一部分GPU资源,显然这样是很浪费资源的。
Google提供了一种生产环境的新思路,他们开发了一个tensorflow-serving的服务,可以自动加载某个路径下的所有模型,模型通过事先定义的输入输出和计算图,直接提供rpc或者rest的服务。
- 一方面,支持多版本的热部署(比如当前生产环境部署的是1版本的模型,训练完成后生成一个2版本的模型,tensorflow会自动加载这个模型,停掉之前的模型)。
- 另一方面,tensorflow serving内部通过异步调用的方式,实现高可用,并且自动组织输入以批次调用的方式节省GPU计算资源。
因此,整个模型的调用方式就变成了:
客户端 ----> web服务(flask或者tornado) --grpc或者rest--> tensorflow serving
如果我们想要替换模型或者更新版本,只需要训练模型并将训练结果保存到固定的目录下就可以了。
2.2 Docker
参考资料:
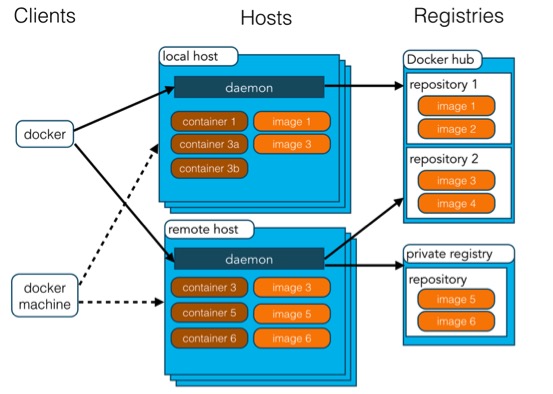
docker简单来说就是一种容器技术,如果有做过技术支持的朋友肯定了解安装软件的痛苦——各种系统环境,导致各种安装报错...docker解决的问题就是,只要你再服务器上安装上docker,那么它会自动屏蔽所有的硬件信息,拉取一个镜像,就能直接启动提供服务。
搭建docker也很简单,如果是mac直接下载dmg文件就可以双击运行;如果是ubuntu直接运行
sudo apt-get install docker
不过Ubuntu安装后只能通过root使用,如果想让其他用户使用,需要调整docker组,细节百度一下即可。
常用的命令也比较少:
# 查看当前部署的服务
docker ps
# 运行一个容器服务
docker run
# 删除一个服务
docker kill xxx
2.3 Nvidia-docker
参考资料:
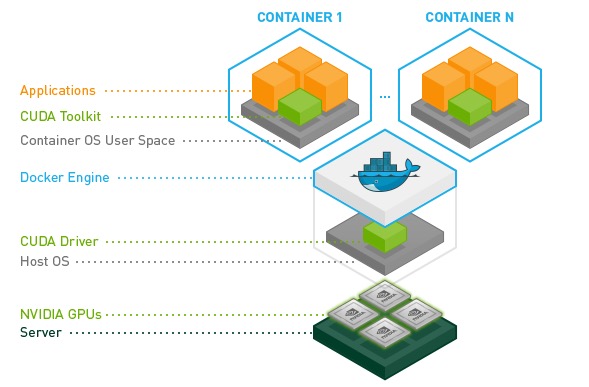
因为docker是虚拟在操作系统之上的,屏蔽了很多底层的信息。如果想使用显卡这种硬件,一种思路是docker直接把操作系统上的驱动程序和算法库映射到容器内,但是这样就丧失了可移植性。
另一种方法就是在docker启动的时候挂载一个类似驱动的插件——这就是nvidia-docker的作用。
总的来说,如果想要在docker中使用tensorflow-gpu,需要首先安装docker-ce(社区版,其他版本nvidia-docker不一定支持),然后安装nvidia-container-runtime,最后安装nvidia-docker2。
当使用的时候,需要直接指定nvidia-docker2运行, 如:
sudo nvidia-docker run -p 8500:8500 --mount type=bind,source=/home/ubuntu/data/east_serving/east_serving,target=/models/east -e MODEL_NAME=east -t tensorflow/serving:1.12.0-gpu &
3 部署实战
下面就进入部署的实战篇了:
3.1 Docker\Nvidia-Docker、Tensorflow部署
主要参考:
首先安装docker-ce:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo apt-key fingerprint 0EBFCD88
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get install docker-ce
sudo service docker restart
如果之前安装了nvidia-docker1需要删除掉:
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
修改docker的镜像地址vi /etc/docker/daemon.json:
{
"registry-mirrors":["https://registry.docker-cn.com","http://hub-mirror.c.163.com"]
}
然后重启docker配置服务systemctl restart docker.service。
更新nvidia-docker地址:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
执行安装命令:
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
测试:
ubuntu@ubuntu:~$ sudo nvidia-docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
Thu Jan 3 09:52:06 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.130 Driver Version: 384.130 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:3B:00.0 Off | 0 |
| N/A 35C P0 49W / 250W | 22152MiB / 22912MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
可以看到,已经能再docker内部看到显卡的使用信息了。
在docker容器外,执行nvidia-smi可以看到有个tensorflow serving的服务
ubuntu@ubuntu:~$ nvidia-smi
Thu Jan 3 17:52:43 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.130 Driver Version: 384.130 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:3B:00.0 Off | 0 |
| N/A 35C P0 49W / 250W | 22152MiB / 22912MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 108329 C python 4963MiB |
| 0 133840 C tensorflow_model_server 17179MiB |
+-----------------------------------------------------------------------------+
注意正常需要配置docker占用的显存比例!
4 总结
搞深度学习还是需要全栈基础的,涉及到各种linux底层动态库、硬件、容器等等相关的知识,虽然踩了不少坑,但是很多概念性的东西都得到了实践,这才是工作最大的意义。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架