

理解『注意力机制』的本质
 本文介绍了注意力机制的本质。从一个简单的引例开始,首先介绍了一维情况的注意力机制。进一步地,推广到多维情况的注意力机制。最后,介绍了自注意力机制。本文举的例子简单易懂,公式推导清晰明了。
本文介绍了注意力机制的本质。从一个简单的引例开始,首先介绍了一维情况的注意力机制。进一步地,推广到多维情况的注意力机制。最后,介绍了自注意力机制。本文举的例子简单易懂,公式推导清晰明了。
一、引例
假设有这样一组数据,它们是腰围和体重一一对应的数据对。我们将根据表中的数据对去估计体重。
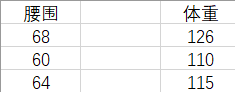
如果现在给出一个新的腰围 62 ,那么体重的估计值是多少呢?
凭经验,我们认为腰围和体重是正相关的,所以我们会自然地『关注』和 62 差距更小的那些腰围,来去估计体重。也就是更加关注表格中腰围是 60 和 64 的『腰围-体重对』(waistline-weight pairs)。即,我们会估计此人的体重在 110 ~ 115 之间。这是一种定性的分析。
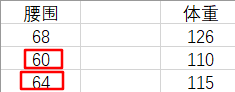
下面我们来算一下具体值。我们选取一种简单直观的方法来计算:
由于 62 距离 60 和 64 的距离是相等的,所以我们取 110 和 115 的平均值作为 62 腰围对应的体重。
也可以这样认为,由于 62 距离 60 和 64 是最近的,所以我们更加『注意』它们,又由于 62 到它俩的距离相等,所以我们给这两对『腰围-体重对』各分配 0.5 的权重。
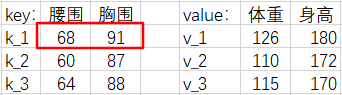
但是,我们到现在还没有用到过 68 --> 126 这个『腰围-体重对』,我们应该再分一些权重给它,让我们的估计结果更准确。
我们上面的讨论可以总结为公式:
这个权重应该如何计算呢?
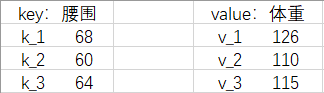
二、注意力机制
我们把『腰围-体重对』改写成 Python 语法中(字典)的『键-值对』(key-value pairs),把给出的新腰围 62 叫请求(query),简称
现在我们给那些值起了新的名字,所以公式可以写为:
这个公式描述了『注意力机制』。其中,
它是如何计算的呢?方法有很多,在本例中,我们使用高斯核计算:
我们取
我们发现,好巧不巧地,
本例中的高斯核计算的相似度为:
注意力权重计算结果为:
体重估计值为:
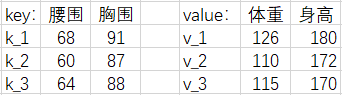
三、多维情况
我们现在加入【胸围】和【身高】数据,把
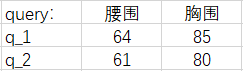
注意力分数
| 模型 | 公式 |
|---|---|
| 加性模型 | |
| 点积模型 | |
| 缩放点积模型 |
我们以『点积模型』为例,计算一下
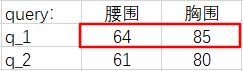
则有
其他注意力分数同理。
那么现在,多维情况下的注意力输出
为了方便计算,我们写成矩阵形式。
为了缓解梯度消失的问题,我们还会除以一个特征维度
这一系列操作,被称为『缩放点积注意力模型』(scaled dot-product attention)
如果
四、自注意力机制
我们用
则上述的注意力机制表达式可以写成:
这个公式描述了『自注意力机制』(Self-Attention Mechanism)。在实际应用中,可能会对
三个可学习的权重矩阵
该公式执行以下步骤:
- 使用权重矩阵
- 计算自注意力分数:
- 对自注意力分数进行 Softmax 操作,得到注意力权重。
- 使用权重矩阵
- 将 Softmax 的结果乘以
这个带有权重矩阵的自注意力机制允许模型学习不同位置的查询、键和值的映射关系,从而更灵活地捕捉序列中的信息。在Transformer等模型中,这样的自注意力机制广泛用于提高序列建模的效果。
相关概念推荐阅读:高斯核是什么?,Softmax 函数是什么?
推荐B站视频:注意力机制的本质(BV1dt4y1J7ov),65 注意力分数【动手学深度学习v2】(BV1Tb4y167rb)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具