JVM内存模型(五)
一、JVM内存模型
1.1、与运行时数据区
前面讲过了运行时数据区那接下来我们聊下内存模型,JVM的内存模型指的是方法区和堆;在很多情况下网上讲解会把内存模型和运行时数据区认为是一个东西,这是错误的想法,如果不信可以自己去官网求证
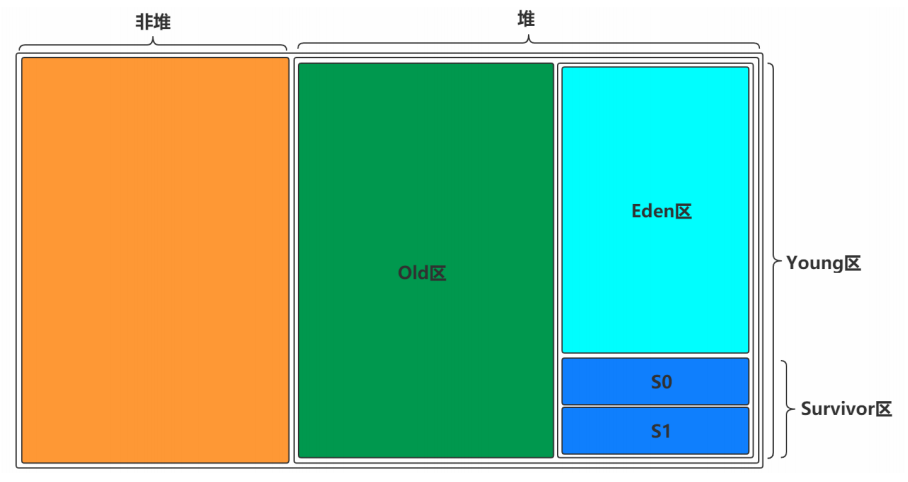
内存模型我们可以分为非堆区(元空间,用的是本地内存)和堆区,在堆区分为两大块,一个是Old区,一个是Young区。Young区分为两大块,一个是Survivor区(S0+S1),一块是Eden区。 Eden:S0:S1=8:1:1;S0和S1一样大,也可以叫From和To。
1.2、图形展示
一块是非堆区,一块是堆区,堆区分为两大块,一个是Old区,一个是Young区,Young区分为两大块,一个是Survivor区(S0+S1),一块是Eden区,S0和S1一样大,也可以叫From和To
1.3、对象创建过程
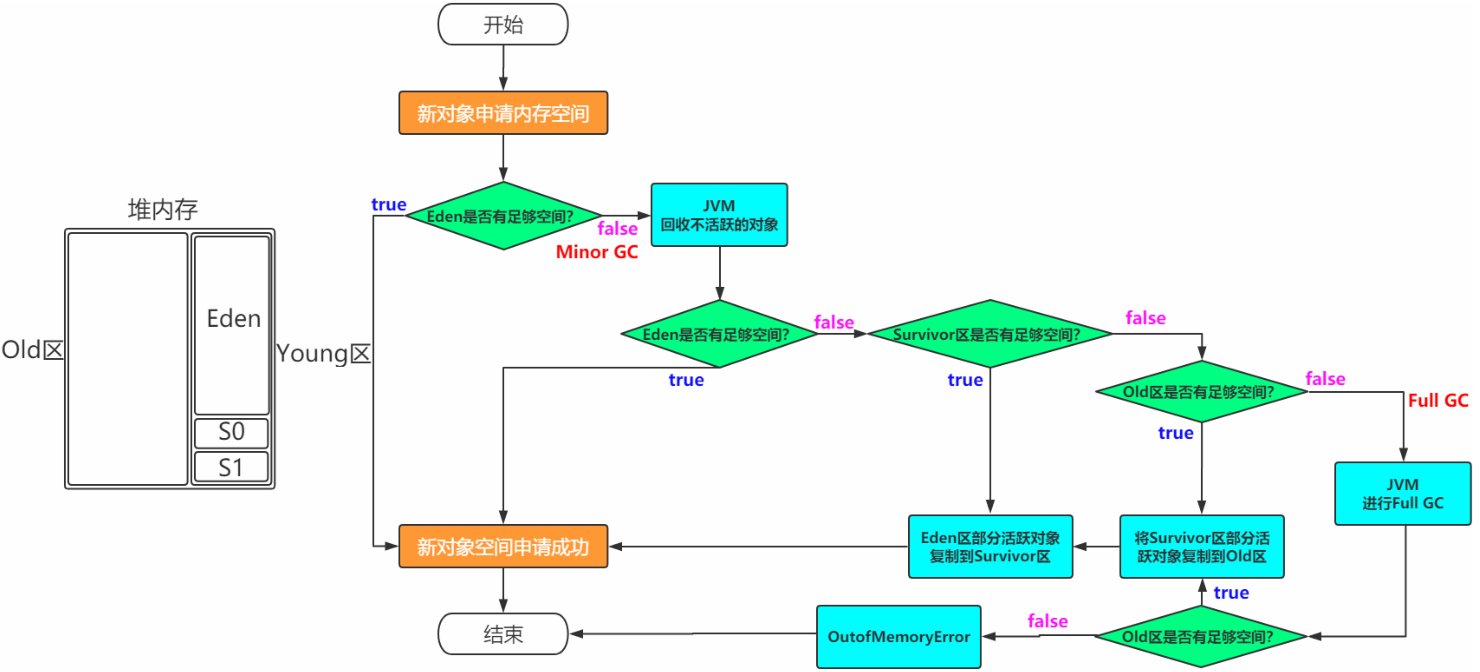
一般情况下,新创建的对象都会被分配到Eden区,一些特殊的大的对象会直接分配到Old区(新生代空间不够时,借老年代空间用的情况)比如有对象A,B,C等创建在Eden区,但是Eden区的内存空间肯定有限,比如有100M,假如已经使用了100M或者达到一个设定的临界值,这时候就需要对Eden内存空间进行清理,即垃圾收集(Garbage Collect),这样的GC我们称之为Minor GC,Minor GC指得是Young区的GC。经过GC之后,有些对象就会被清理掉,有些对象可能还存活着,对于存活着的对象需要将其复制到Survivor区,然后再清空Eden区中的这些对象。Survivor区分为两块S0和S1。在同一个时间点上,S0和S1只能有一个区有数据,另外一个是空的。
b.survivor区工作过程
比如一开始只有Eden区和From中有对象,To中是空的。此时进行一次GC操作,From区中对象的年龄就会+1,我们知道Eden区中所有存活的对象会被复制到To区,From区中还能存活的对象会有两个去处。若对象年龄达到之前设置好的年龄阈值,此时对象 会被移动到Old区,没有达到阈值的对象会被复制到To区。此时Eden区和From区已经被清空。这时候From和To交换角色,之前的From变成了To,之前的To变成了From。也就是说无论如何都要保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到To区被填满,然后会将所有对象复制到老年代中。
1.4、OId区
一般Old区都是年龄比较大的对象,或者相对超过了某个阈值的对象。在Old区也会有GC的操作,Old区的GC我们称作为Major GC,每次GC之后还能存活的对象年龄也会+1,如果年龄超过了某个阈值,就会被回收。
二、常见问题
2.1、如何理解各种GC
- Partial GC:Partial其实也就是部分的意思.那么翻译过来也就是回收部分GC堆的模式,他并不会回收我们整个堆.而我们的young GC以及我们的Old GC都属于这种模式
- young GC:只回收young区
- old GC:只回收Old区
- full GC:实际上就是对于整体回收
2.2、为什么需要Survivor区
如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代。这样一来,老年代很快被填满,触发Major GC(因为Major GC一般伴随着Minor GC,也可以看做触发了Full GC)。老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。执行时间长有什么坏处?频发的Full GC消耗的时间很长,会影响大型程序的执行和响应速度。
这时有人会想到对老年代的空间进行增加。假如增加老年代空间,更多存活对象才能填满老年代。虽然降低Full GC频率,但是随着老年代空间加大,一旦发生Full GC,执行所需要的时间更长。假如减少老年代空间,虽然Full GC所需时间减少,但是老年代很快被存活对象填满,Full GC频率增加。所以Survivor的存在意义,就是减少被送到老年代的对象,进而减少Full GC的发生,Survivor的预筛选保证,只有经历16次Minor GC还能在新生代中存活的对象,才会被送到老年代。
2.3、为什么需要两个Survivor区
最大的好处就是解决了碎片化。也就是说为什么一个Survivor区不行?第一部分中,我们知道了必须设置Survivor区。假设现在只有一个Survivor区,我们来模拟一下流程:刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。所以要有两个survivor,并且永远有一个Survivor space是空的,另一个非空的Survivor space无碎片。
2.4、新生代中Eden:S1:S2为什么是8:1:1
新生代中的可用内存:复制算法用来担保的内存为9:1;可用内存中Eden:S1区为8:1;即新生代中Eden:S1:S2 = 8:1:1现代的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象大概98%是“朝生夕死”的
2.5、堆内存中都是线程共享的区域吗
JVM默认为每个线程在Eden上开辟一个buffer区域,用来加速对象的分配,称之为TLAB,全称:Thread Local Allocation Buffer。对象优先会在TLAB上分配,但是TLAB空间通常会比较小,如果对象比较大,那么还是在共享区域分配。
三、体验验证
如果我们想自己验证下JVM的运行过程我们也可以用在cmd窗口写命令调出查看工具jvisualgc插件下载链接 :https://visualvm.github.io/pluginscenters.html --->选择对应版本链接--->Tools--->Visual GC

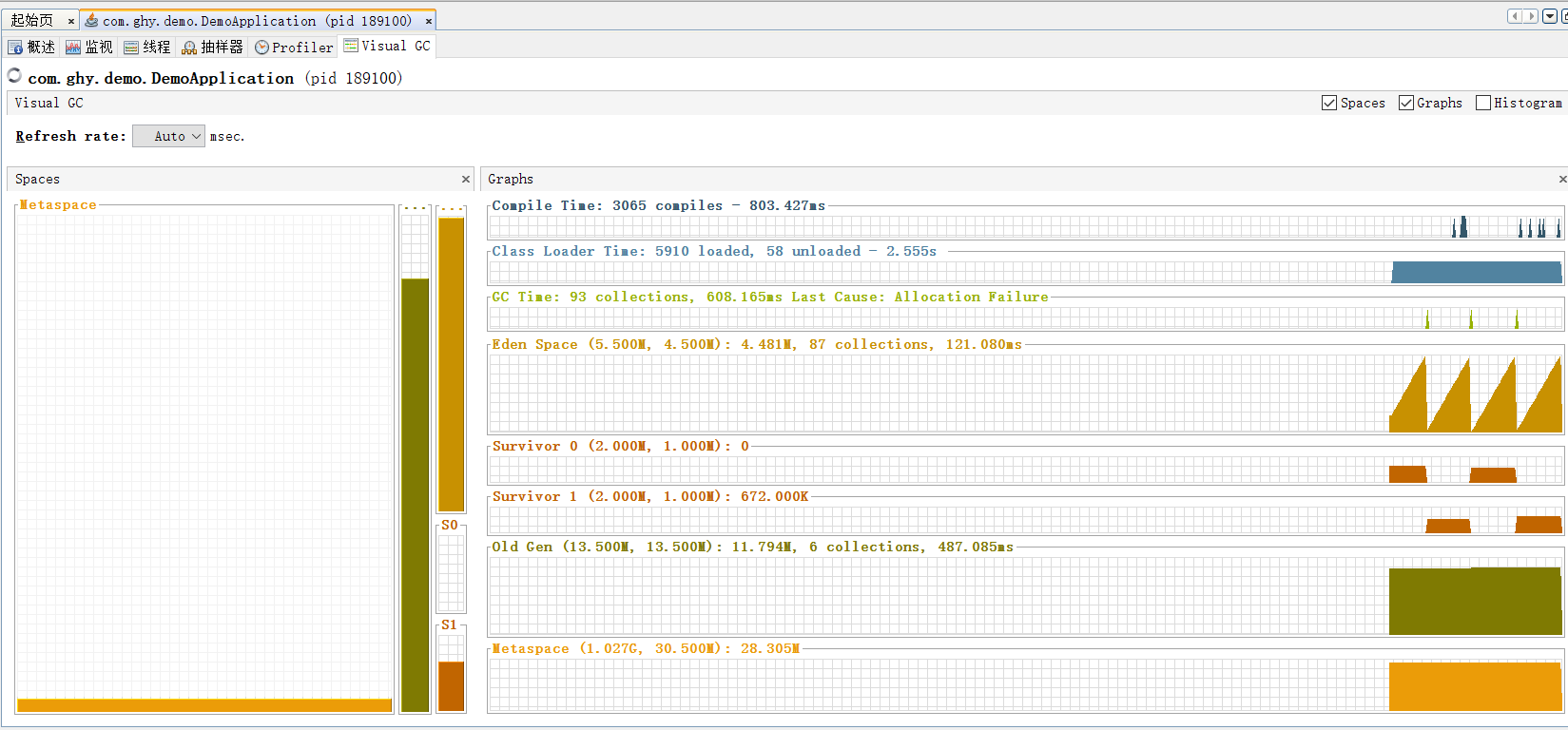
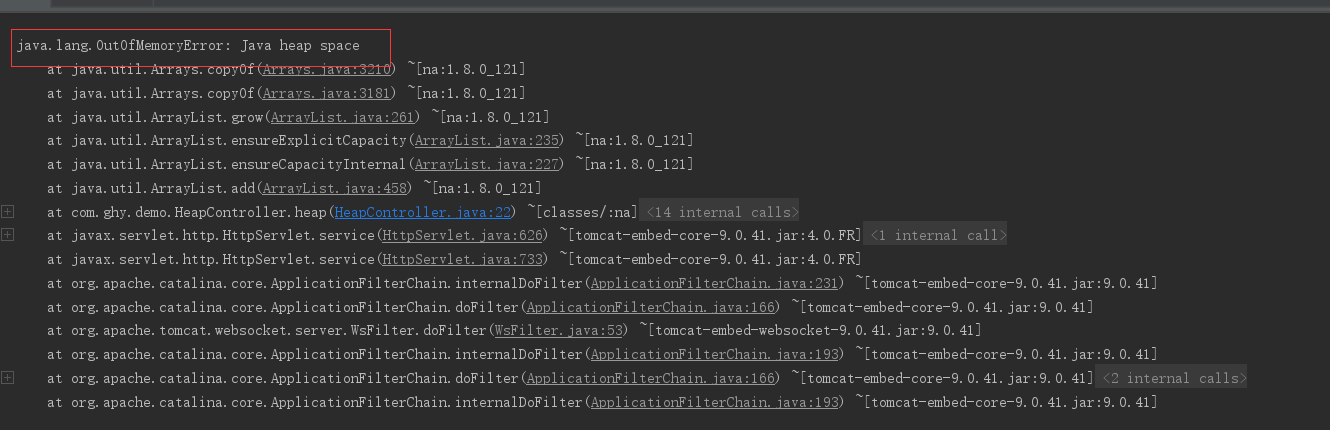
3.1、堆内存溢出
@RestController public class HeapController { List<String > list=new ArrayList<String> (); @GetMapping("/heap") public String heap(){ while(true){ list.add(" 堆内存溢出"); } } }
记得设置参数比如-Xmx20M -Xms20M ;启动项目后我们用监听工具访问可以在本地看到如下图解
3.2、方法区内存溢出
比如向方法区中添加Class的信息,加入依赖
<dependency>
<groupId>asm</groupId>
<artifactId>asm</artifactId>
<version>3.3.1</version>
</dependency>
public class MyMetaspace extends ClassLoader { public static List<Class<?>> createClasses() { List<Class<?>> classes = new ArrayList<Class<?>> (); for (int i = 0; i < 10000000; ++i) { ClassWriter cw = new ClassWriter(0); cw.visit( Opcodes.V1_1, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); MethodVisitor mw = cw.visitMethod(Opcodes.ACC_PUBLIC, "<init>", "()V", null, null); mw.visitVarInsn(Opcodes.ALOAD, 0); mw.visitMethodInsn(Opcodes.INVOKESPECIAL, "java/lang/Object", "<init>", "()V"); mw.visitInsn(Opcodes.RETURN); mw.visitMaxs(1, 1); mw.visitEnd(); MyMetaspace test = new MyMetaspace(); byte[] code = cw.toByteArray(); Class<?> exampleClass = test.defineClass("Class" + i, code, 0, code.length); classes.add(exampleClass); } return classes; } }
@RestController public class NonHeapController { List<Class<?>> list=new ArrayList<Class<?>> (); @GetMapping("/nonheap") public String nonheap(){ while(true){ list.addAll(MyMetaspace.createClasses()); } } }
设置Metaspace的大小,比如-XX:MetaspaceSize=50M -XX:MaxMetaspaceSize=50M ,然后运行代码

3.3、虚拟机栈
public class Demo { public static long count=0; public static void method(long i){ System.out.println(count++); method(i); } public static void main(String[] args) { method(1); } }

Stack Space用来做方法的递归调用时压入Stack Frame(栈帧)。所以当递归调用太深的时候,就有可能耗尽Stack Space,爆出StackOverflow的错误。-Xss128k:设置每个线程的堆栈大小。JDK 5以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误。
这短短的一生我们最终都会失去,不妨大胆一点,爱一个人,攀一座山,追一个梦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号