RabbitMQ持久化机制(二)
前面写的RabbitMQ的东西还是很简单的,百度资料一堆,看看一会就能学会,之所以写前面的文章是想让还不怎么会用RabbitMQ的朋友可以系统看下,但做为架构师关注的重点应该是RabbitMQ的持久化机制及磁盘管理,接下来要写的东西就是关于这些的;在讲下面内容前先来说一点现在的RabbitMQ的环境,目前环境是单机环境,如果消息中间件挂了这是一场灾难事件,所以高可用架构是必不可少的;
一、单一模式
即单机情况不做集群,就单独运行一个rabbitmq而已;在上一篇幅中已经说明了安装方法;
二、普通模式
2.1、RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据:
1.队列元数据:队列名称、属性;
2.交换器元数据:交换器名称、类型和属性;
3.绑定元数据:交换器与队列绑定关系,如binding_key;
4.vhost元数据:虚拟主机内部配置和属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/ vhost等信息都是相同的。
注意:队列只同步元数据信息,不会同步存储的消息,消息只会存在于创建该队列的节点上,其它节点只知道这个队列的元数据信息和一个指向队列的owner node的地址。
2.2、为何RabbitMQ集群仅采用元数据同步的方式
RabbitMQ这么设计主要是基于集群本身的性能和存储空间上来考虑。
第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);
第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
2.3、RabbitMQ集群的基本原理

场景1、客户端直接连接队列所在节点
如果有一个消息生产者或者消息消费者通过amqp-client的客户端连接至节点1进行消息的发布或者订阅,那么此时的集群中的消息收发只与节点1相关。
场景2、客户端连接的是非队列数据所在节点
如果消息生产者所连接的是节点2或者节点3,此时队列1的完整数据不在该两个节点上,那么在发送消息过程中这两个节点主要起了一个路由转发作用,根据这两个节点上的元数据(也就是上文提到的:指向queue的owner node的指针)转发至节点1上,最终发送的消息还是会存储至节点1的队列1上。同样,如果消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费。
2.4、单机多节点集群搭建
2.4.1、启动单节点Rabbit MQ
docker run -d --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:management
2.4.2、多节点集群模式(安装 Docker Compose)
安装dnf
#CentOS 安装 #安装 epel-release 依赖: yum install epel-release #安装 DNF 包: yum install dnf ---------------- #Fedora 安装: dnf install dnf
安装python2-pip
dnf install python2-pip
安装python3-pip(一般选择python3)
dnf install python3-pip
安装docker-compose
pip3 install docker-compose
我在安装docker-compose报了错,错误当时忘记截图了现在找不到了,但我是用下面命令解决了安装错误
pip3 install --upgrade pip
查看版本
docker-compose version
2.4.3、使用 Docker Compose 启动3个 RabbitMQ 节点
vi docker-compose.yml
写入如下配置
version: "2.0" services: rabbit1: image: rabbitmq:management hostname: rabbit1 ports: - 5672:5672 #集群内部访问的端口 - 15672:15672 #外部访问的端口 environment: - RABBITMQ_DEFAULT_USER=guest #用户名 - RABBITMQ_DEFAULT_PASS=guest #密码 - RABBITMQ_ERLANG_COOKIE='imoocrabbitmq' rabbit2: image: rabbitmq:management hostname: rabbit2 ports: - 5673:5672 environment: - RABBITMQ_ERLANG_COOKIE='imoocrabbitmq' links: - rabbit1 rabbit3: image: rabbitmq:management hostname: rabbit3 ports: - 5674:5672 environment: - RABBITMQ_ERLANG_COOKIE='imoocrabbitmq' links: - rabbit1 - rabbit2
2.4.4、将3个 RabbitMQ 节点搭建为集群
启动docker-compose,按照脚本启动集群
docker-compose up -d
上面命令可能会报端口占用,如果出现这个错那就把15672的docker先停下再执行上面命令就好了;进入2号节点
docker exec -it root_rabbit2_1 bash
停止2号节点的rabbitmq
rabbitmqctl stop_app
配置2号节点,加入集群
rabbitmqctl join_cluster rabbit@rabbit1
停止3号节点的rabbitmq
rabbitmqctl stop_app
配置3号节点,加入集群
rabbitmqctl join_cluster rabbit@rabbit1
启动3号节点的rabbitmq
rabbitmqctl start_app
2.4.5、打开客户端
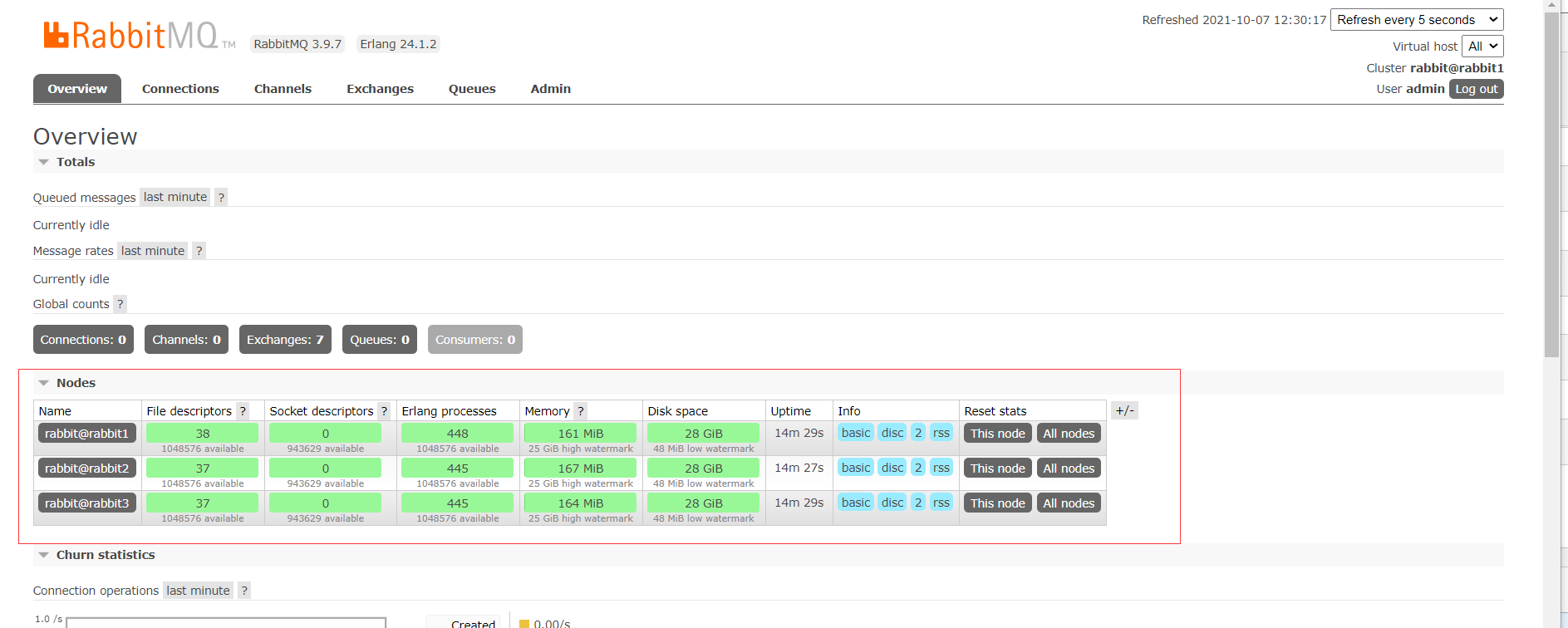
2.5、多机多节点部署
2.5.1、环境说明
本来想搞三个节点,但我自己的一台私有云今天不争气,不知道哪里问题一直启不来,就先搞两个节点吧;两个节点和多个节点原理是一样的
| 节点名称 | IP地址 |
| rabbitmq1 | 192.168.0.1 |
| rabbitmq2 | 192.168.0.2 |
2.5.2、docker-compose 文件
version: '3' services: rabbit1: container_name: rabbit1 image: rabbitmq:management restart: always hostname: rabbit1 extra_hosts: - "rabbit1:192.168.0.1" - "rabbit2:192.168.0.2" environment: - RABBITMQ_ERLANG_COOKIE=MY_COOKIE - RABBITMQ_DEFAULT_USER=admin - RABBITMQ_DEFAULT_PASS=admin ports: - "4369:4369" - "5671:5671" - "5672:5672" - "15671:15671" - "15672:15672" - "25672:25672"
这样,192.168.0.1 上的 docker-compose 文件就写好了,部署另一台时,只要将 rabbit1 改成 rabbit2 就可以了。如果是更多台服务器的话,也是同样的道理,将 IP 配置到 extra_hosts 参数下即可。
2.5.3、启动服务
在两台服务器上分别执行:
docker-compose up -d
2.5.4、加入集群
如果将 rabbit1 作为主节点的话,需要在 rabbit2 上执行命令,将其加入到集群,如下:
# docker exec -it rabbit2 /bin/bash
rabbit2# rabbitmqctl stop_app
rabbit2# rabbitmqctl reset
rabbit2# rabbitmqctl join_cluster rabbit@rabbit1
rabbit2# rabbitmqctl start_app
默认情况下,RabbitMQ 启动后是磁盘节点,如果想以内存节点方式加入,可以加 --ram 参数。如果想要修改节点类型,可以使用命令:
# rabbitmqctl change_cluster_node_type disc(ram)
修改节点类型之前需要先 rabbitmqctl stop_app。
通过下面命令来查看集群状态:
# rabbitmqctl cluster_status
注意,由于 RAM 节点仅将内部数据库表存储在内存中,因此在内存节点启动时必须从其他节点同步这些数据,所以一个集群必须至少包含一个磁盘节点。
2.5.5、HAProxy 负载均衡
ha 同样采用 Docker 方式来部署,先看一下 haproxy.cfg 配置文件:
# Simple configuration for an HTTP proxy listening on port 80 on all # interfaces and forwarding requests to a single backend "servers" with a # single server "server1" listening on 127.0.0.1:8000 global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 5000ms timeout server 5000ms listen rabbitmq_cluster bind 0.0.0.0:5677 option tcplog mode tcp balance leastconn server rabbit1 192.168.0.1:5672 weight 1 check inter 2s rise 2 fall 3 server rabbit2 192.168.0.2:5672 weight 1 check inter 2s rise 2 fall 3 listen http_front bind 0.0.0.0:8002 stats uri /haproxy?stats listen rabbitmq_admin bind 0.0.0.0:8001 server rabbit1 192.168.0.1:15672 server rabbit2 192.168.0.2:15672
再看一下 docker-compose 文件:
version: '3' services: haproxy: container_name: rabbit-haproxy image: haproxy restart: always hostname: haproxy network_mode: rabbitmq_default volumes: - ./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg ports: - "5677:5677" - "8001:8001" - "8002:8002"
启动之后,就可以通过 ha 的地址来访问 RabbitMQ 集群管理页面了。如果公司内部有现成的负载均衡,比如 LVS,那么也可以省略这一步。
三、镜像队列模式集群
3.1、开启镜像队列模式

|
ha-mode
|
ha-params
|
说明
|
|
all
|
(empty)
|
队列镜像到集群类所有节点
|
|
exactly
|
count
|
队列镜像到集群内指定数量的节点。如果集群内节点数少于此
值,队列将会镜像到所有节点。如果大于此值,而且一个包含镜
像的节点停止,则新的镜像不会在其它节点创建。
|
|
nodes
|
nodename
|
队列镜像到指定节点,指定的节点不在集群中不会报错。当队列
申明时,如果指定的节点不在线,则队列会被创建在客户端所连
接的节点上。
|
- 镜像队列模式相比较普通模式,镜像模式会占用更多的带宽来进行同步,所以镜像队列的吞吐量会低于普通模式。
- 但普通模式不能实现高可用,某个节点挂了后,这个节点上的消息将无法被消费,需要等待节点启动后才能被消费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号