一、mycat注解
1.1、注解原理
概念
MyCat 对自身不支持的 Sql 语句提供了一种解决方案——在要执行的 SQL 语句前添加额外的一段由注解SQL 组织的代码,这样 Sql 就能正确执行,这段代码称之为“注解”。注解的使用相当于对 mycat 不支持的 sql语句做了一层透明代理转发,直接交给目标的数据节点进行 sql 语句执行,其中注解 SQL 用于确定最终执行 SQL的数据节点。注解的形式是:
/*!mycat: sql=注解 Sql 语句*/
注解的使用方式是:
/*!mycat: sql=注解 Sql 语句*/真正执行 Sql
使用时将=号后的“注解 Sql 语句”替换为需要的 Sql 语句即可,后面会提到具体的用法。
原理
MyCat 执行 SQL 语句的流程是先进行 SQL 解析处理,解析出分片信息(路由信息)后,然后到该分片对应的物理库上去执行;若传入的 SQL 语句 MyCat 无法解析,则 MyCat 不会去执行;而注解则是告诉 MyCat 按照注解内的 SQL(称之为注解 SQL)去进行解析处理,解析出分片信息后,将注解后真正要执行的 SQL 语句(称之为原始 SQL)发送到该分片对应的物理库上去执行。从上面的原理可以看到,注解只是告诉 MyCat 到何处去执行原始 SQL;因而使用注解前,要清楚的知道该原始 SQL 去哪个分片执行,然后在注解 SQL 中也指向该分片,这样才能使用!例如sharding_id=10010 即是指明分片信息的。需要说明的是,若注解 SQL 没有能明确到具体某个分片,譬如例子中的注解 SQL 没有添加sharding_id=10010 这个条件,则 MyCat 会将原始 SQL 发送到 persons 表所在的所有分片上去执行去,这样造成的后果若是插入语句,则在多个分片上都存在重复记录,同样查询、更新、删除操作也会得到错误的结果!
解决问题
1. MySql 不支持的语法结构,如 insert …select…;
2. 同一个实例内的跨库关联查询,如用户库和平台库内的表关联;
3. 存储过程调用;
4. 表,存储过程创建。
注解规范
1. 注解 SQL 使用 select 语句,不允许使用 delete/update/insert 等语句;虽然 delete/update/insert 等语句也能用在注解中,但这些语句在 Sql 处理中有额外的逻辑判断,从性能考虑,请使用 select 语句
2. 注解 SQL 禁用表关联语句;
3. 注解 SQL 尽量用最简单的 SQL 语句,如 select id from tab_a where id=’10000’;
4. 无论是原始 SQL 还是注解 SQL,禁止 DDL 语句;
5. 能不用注解的尽量不用;
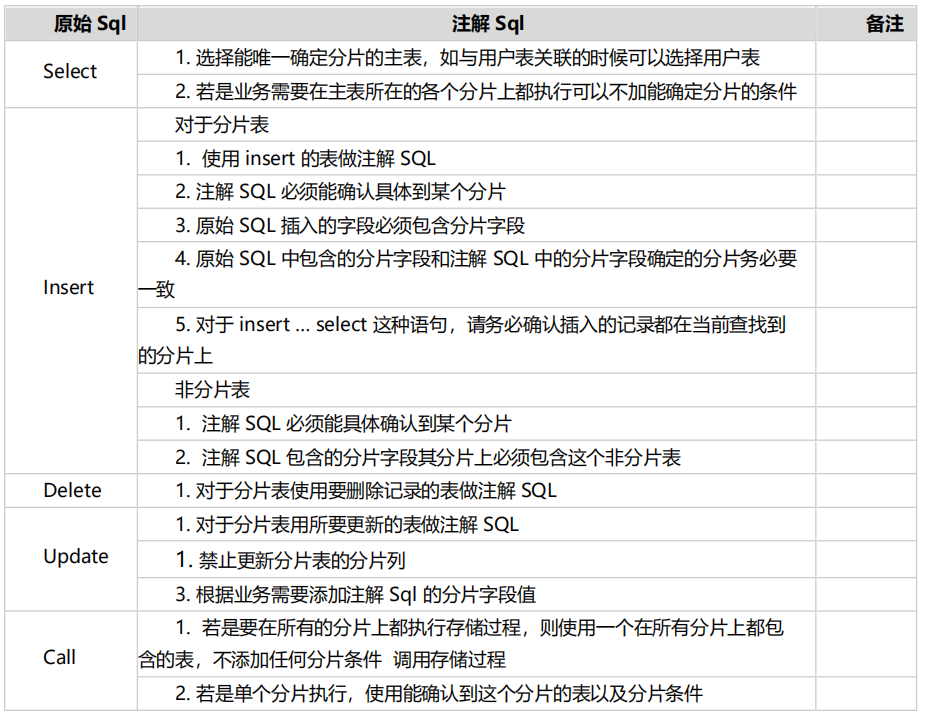
6. 详细要求见下表。
![]()
补充说明:
使用注解并不额外增加 MyCat 的执行时间;从解析复杂度以及性能考虑,注解 SQL 应尽量简单。至于一个SQL 使用注解和不使用注解的性能对比,不存在参考意义,因为前提是 MyCat 不支持的 SQL 才使用注解。
1.2、 注解使用示例
注解支持的'!'不被 mysql 单库兼容,
注解支持的'#'不被 mybatis 兼容
新增加 mycat 字符前缀标志 Hintsql:"/** mycat: */"
从 1.6 开始支持三种注解方式:
/*#mycat:db_type=master*/ select * from travelrecord
/*!mycat:db_type=slave*/ select * from travelrecord
/**mycat:db_type=master*/ select * from travelrecord
1. Mycat 端执行存储创建表或存储过程为:
存储过程:
/*!mycat: sql=select 1 from test */ CREATE PROCEDURE `test_proc`() BEGIN END ;
表:
/*!mycat: sql=select 1 from test */create table test2(id int);
注意注解中语句是节点的表请替换成自己表如 select 1 from 表 ,注解内语句查出来的数据在哪个分片,数据在那个节点往哪个节点建.
2. 特殊语句自定义分片:
/*!mycat: sql=select 1 from test */insert into t_user(id,name) select id,name from t_user2;
3. 读写分离
配置了 Mycat 读写分离后,默认查询都会从读节点获取数据,但是有些场景需要获取实时数据,如果从读节点获取数据可能因延时而无法实现实时,Mycat 支持通过注解/*balance*/来强制从写节点查询数据:
a. 事务内的 SQL,默认走写节点,以注解/*balance*/开头,则会根据 schema.xml 的 dataHost 标签属性的
balance=“1”或“2”去获取节点
b. 非事务内的 SQL,开启读写分离默认根据 balance=“1”或“2”去获取,以注解/*balance*/开头则会走写节
点解决部分已经开启读写分离,但是需要强一致性数据实时获取的场景走写节点
/*balance*/ select a.* from customer a where a.company_id=1;
4. 多表 ShareJoin(这个是有限制条件的,官网上是没有说明的)
/*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.id, b.name as tit from customer a,company b on
a.company_id=b.id;
5.读写分离数据源选择
/*!mycat:db_type=master*/ select * from travelrecord
/*!mycat:db_type=slave*/ select * from travelrecord
/*#mycat:db_type=master*/ select * from travelrecord
/*#mycat:db_type=slave*/ select * from travelrecord
6. 多租户支持
通过注解方式在配置多个 schema 情况下,指定走哪个配置的 schema。
web 部分修改:
a.在用户登录时,在线程变量(ThreadLocal)中记录租户的 id
b.修改 jdbc 的实现:在提交 sql 时,从 ThreadLocal 中获取租户 id, 添加 sql 注释,把租户的 schema放到注释中。例如:/*!mycat : schema = test_01 */ sql ;
在 db 前面建立 proxy 层,代理所有 web 过来的数据库请求。proxy 层是用 mycat 实现的,web 提交的 sql 过来时在注释中指定 schema, proxy 层根据指定的 schema 转发 sql 请求。
/*!mycat : schema = test_01 */ sql ;
二、 事务支持
2.1、Mycat 里的数据库事务
Mycat 目前没有出来跨分片的事务强一致性支持,目前单库内部可以保证事务的完整性,如果跨库事务,在执行的时候任何分片出错,可以保证所有分片回滚,但是一旦应用发起 commit 指令,无法保证所有分片都成功考虑到某个分片挂的可能性不大所以称为弱 xa。
2.2 XA 事务原理
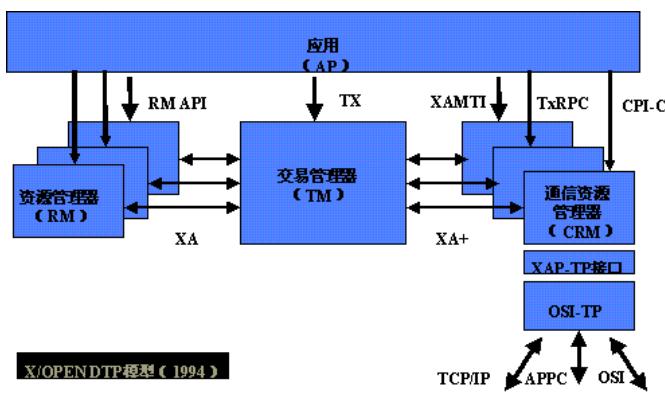
分布式事务处理( Distributed Transaction Processing , DTP )指一个程序或程序段,在一个或多个资源如数据库或文件上为完成某些功能的执行过程的集合,分布式事务处理的关键是必须有一种方法可以知道事务在任何地方所做的所有动作,提交或回滚事务的决定必须产生统一的结果(全部提交或全部回滚)。X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型。 X/Open DTP 模型( 1994 )包括应用程序( AP )、事务管理器( TM )、资源管理器( RM )、通信资源管理器( CRM )四部分。一般,常见的事务管理器( TM )是交易中间件,常见的资源管理器( RM )是数据库,常见的通信资源管理器( CRM )是消息中间件,下图是 X/Open DTP 模型
![]()
一般的编程方式是这样的:
• 配置 TM,通过 TM 或者 RM 提供的方式,把 RM 注册到 TM。可以理解为给 TM 注册 RM 作为数据源。一个 TM 可以注册多个 RM。
• AP 从 TM 获取资源管理器的代理(例如:使用 JTA 接口,从 TM 管理的上下文中,获取出这个 TM 所管理的 RM 的 JDBC 连接或 JMS 连接)
• AP 向 TM 发起一个全局事务。这时,TM 会通知各个 RM。XID(全局事务 ID)会通知到各个 RM。
• AP 通过 1 中获取的连接,直接操作 RM 进行业务操作。这时,AP 在每次操作时把 XID(包括所属分支的信息)传递给 RM,RM 正是通过这个 XID 与 2 步中的 XID 关联来知道操作和事务的关系的。
• AP 结束全局事务。此时 TM 会通知 RM 全局事务结束。
• 开始二段提交,也就是 prepare - commit 的过程。
• XA 协议(XA Specification),指的是 TM 和 RM 之间的接口,其实这个协议只是定义了 xa_和 ax_系列的函数原型以及功能描述、约束和实施规范等。至于 RM 和 TM 之间通过什么协议通信,则没有提及,目前知名的数据库,如 Oracle, DB2 等,都是实现了 XA 接口的,都可以作为 RM。Tuxedo、TXseries 等事务中间件可以通过 XA 协议跟这些数据源进行对接。JTA(Java Transaction API)是符合 X/Open DTP 的一个编程模型,事务管理和资源管理器支架也是用了 XA 协议。
2.3、二阶段提交
所谓的两个阶段是指准备 prepare 阶段和提交 commit 阶段。
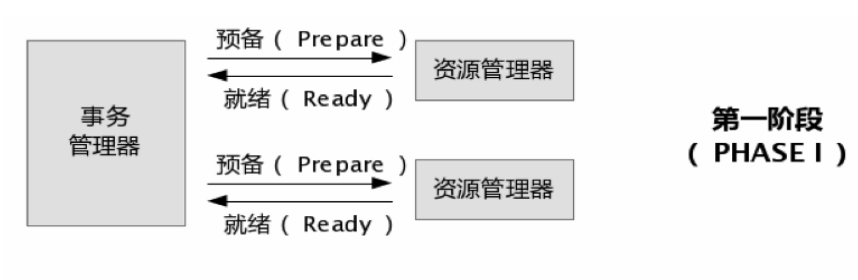
第一阶段分为两个步骤:
1、事务管理器通知参与该事务的各个资源管理器,通知他们开始准备事务。
2、资源管理器接收到消息后开始准备阶段,写好事务日志(redo undo)并执行事务,但不提交,然后将是否就绪的消息返回给事务管理器(此时已经将事务的大部分事情做完,以后的操作耗时极小)。
![]()
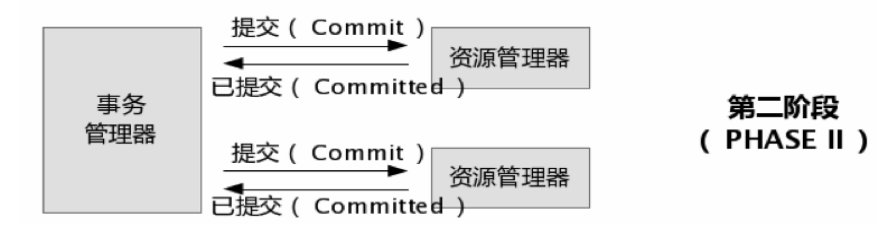
第二阶段也分为两个步骤:
1、事务管理器在接受各个消息后,开始分析,如果有任意数据库失败,则发送回滚命令,否则发送提交命令。
2、各个资源管理器接收到命令后,执行(耗时很少),并将提交消息返回给事务管理器。
![]()
事务管理器接受消息后,事务结束,应用程序继续执行。
至于为什么要分两步执行,一是因为分两步,就有了事务管理器统一管理的机会;二尽可能晚地提交事务,让事务在提交前尽可能地完成所有能完成的工作,这样,最后的提交阶段将是耗时极短,耗时极短意味着操作失败的可能性也就降低。
2.4、 XA 规范
在 XA 的分布式事务处理模型里面涉及到三个角色 AP(应用程序)、RM(数据库)、TM(事务管理器)。AP 定义事务的开始和结束,访问事务内的资源。RM 除了数据库之外,还可以是其他的系统资源,比如文件系统,打印机服务器。 TM 负责管理全局事务,分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚、失败恢复等,是一个协调者的角色,可能是程序或者中间件。XA 协议主要规定了了 TM 与 RM 之间的交互。注意:通过实现 XA 的接口,只是提供了对 XA 分布式事务的支持,并不是说数据库本身有分布式事务的能力。
2.5、MySQL 对 XA 的支持
XA 是一种两阶段提交的实现。数据库本身必须要提供被协调的接口,比如事务开启,准备,事务结束,事务提交,事务回滚。https://dev.mysql.com/doc/refman/5.7/en/xa.html
MySQL 单节点运行 XA 事务演示:
![]()
use ljxmycat;
--开启 XA 事务 xa start 'xid';
--插入数据
INSERT INTO `delivery_mod` (id,name) VALUES (22222, '张三');
5结束一个 XA 事务
xa end 'xid';
6准备提交
xa prepare'xid';
--列出所有处于 PREPARE 阶段的 XA 事务
xa recover;
- 提交
xa commit 'xid';
2.6、XA 事务的问题和 MySQL 的局限
XA 事务的明显问题是 timeout 问题,比如当一个 RM 出问题了,那么整个事务只能处于等待状态。这样可以会连锁反应,导致整个系统都很慢,最终不可用,另外 2 阶段提交也大大增加了 XA 事务的时间,使得 XA 事务无法支持高并发请求。
避免使用 XA 事务的方法通常是最终一致性。
举个例子,比如一个业务逻辑中,最后一步是用户账号增加 300 元,为了减少 DB 的压力,先把这个放到消息队列里,然后后端再从消息队列里取出消息,更新 DB。那么如何保证,这条消息不会被重复消费?或者重复消费后,仍能保证结果是正确的?在消息里带上用户帐号在数据库里的版本,在更新时比较数据的版本,如果相同则加上 300;比如用户本来有 500 元,那么消息是更新用户的钱数为 800,而不是加上 300;
另外一个方式是,建一个消息是否被消费的表,记录消息 ID,在事务里,先判断消息是否已经消息过,如果没有,则更新数据库,加上 300,否则说明已经消费过了,丢弃。
前面两种方法都必须从流程上保证是单方向的。
其实严格意义上,用消息队列来实现最终一致性仍然有漏洞,因为消息队列跟当前操作的数据库是两个不同的资源,仍然存在消息队列失败导致这个账号增加 300 元的消息没有被存储起来(当然复杂的高级的消息队列产品可以避免这种现象,但仍然存在风险),而第二种方式则由于新的表跟之前的事务操作的表示在一个 Database中,因此不存在上述的可能性
MySQL 的 XA 事务,长期以来都存在一个缺陷:
MySQL 数据库的主备数据库的同步,通过 Binlog 的复制完成。而 Binlog 是 MySQL 数据库内部 XA 事务的协调者,并且 MySQL 数据库为 binlog 做了优化——binlog 不写 prepare 日志,只写 commit 日志。所有的参与节点 prepare 完成,在进行 xa commit 前 crash。crash recover 如果选择 commit 此事务。由于binlog 在 prepare 阶段未写,因此主库中看来,此分布式事务最终提交了,但是此事务的操作并未写到 binlog中,因此也就未能成功复制到备库,从而导致主备库数据不一致的情况出现。
2.7、XA 事务使用指南
Mycat 从1.6.5 版本开始支持标准 XA 分布式事务,考虑到 mysql5.7 之前版本 xa 的2 个bug,所以推荐最佳搭配 XA 功能使用 mysql 5.7 版本。Mycat 实现 XA 标准分布式事务,mycat 作为 xa 事务协调者角色,即使事务过程中 mycat 宕
机挂掉,由于 mycat 会记录事务日志,所以 mycat 恢复后会进行事务的恢复善后处理工作。考虑到分布式事务的性能开销比较大,所以只推荐在全局表的事务以及其他一些对一致性要求比较高的场景。
使用示例:
XA 操作说明
1. set autocommit=0;
XA 事务 需要设置手动提交
2. set xa=on;
使用该命令开启 XA 事务
3. insert into travelrecord(id,name)
values(1,'N'),(6000000,'A'),(321,'D'),(13400000,'C'),(59,'E');
执行相应的 SQL 语句部分
4.commit;
对事务进行提交,事务结束
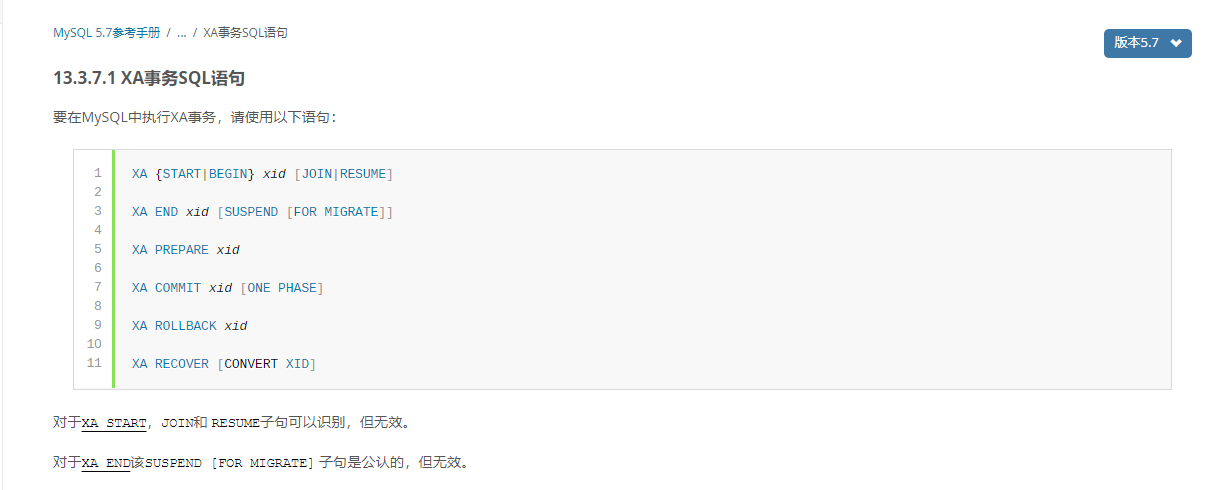
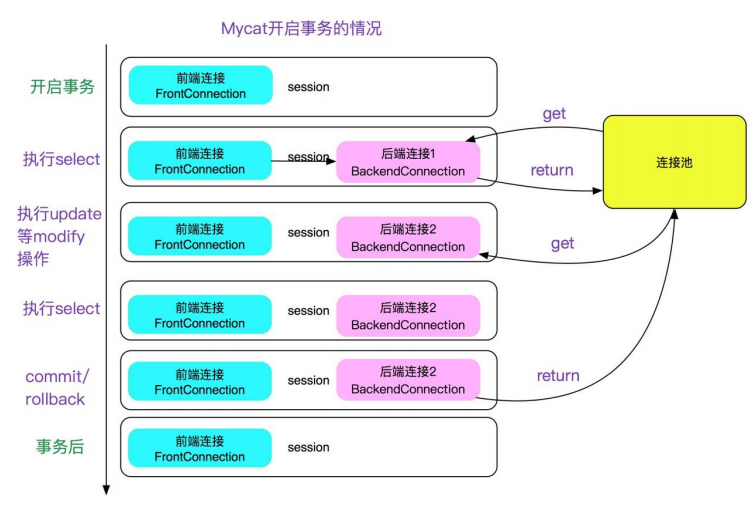
2.8、保证 repeatable read
mycat 有一个特性,就是开事务之后,如果不运行 update/delete/select for update 等更新类语句 SQL 的话,不会将当前连接与当前 session 绑定。如下图所示:
![]()
这样做的好处是可以保证连接可以最大限度的复用,提升性能。但是,这就会导致两次 select 中如果有其它的在提交的话,会出现两次同样的 select 不一致的现象,即不能 repeatable read,这会让人直连 mysql 的人很困惑,可能会在依赖
repeatable read 的场景出现问题。所以做了一个开关,当 server.xml 的system 配置了strictTxIsolation=true 的时候(true),会关掉这个特性,以保证 repeatable read,加了开关后如下图所示:
![]()
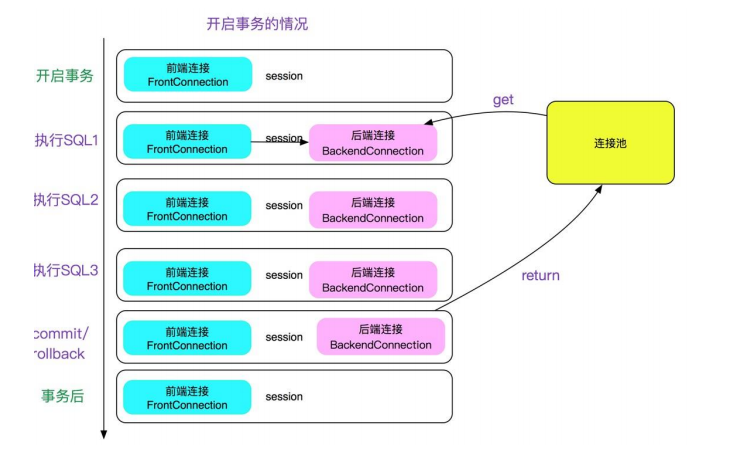
2.9、Mycat SQL 拦截机制
SQL 拦截是一个比较有用的高级技巧,用户可以写一个 java 类,将传入 MyCAT 的 SQL 进行改写然后交给Mycat 去执行,此技巧可以完成如下一些特殊功能:
• 捕获和记录某些特殊的 SQL;
• 记录 sql 查找异常;
• 出于性能优化的考虑,改写 SQL,比如改变查询条件的顺序或增加分页限制;
• 将某些 Select SQL 强制设置为 Read 模式,走读写分离(很多事务框架很难剥离事务中的 Select SQL;
• 后期 Mycat 智能优化,拦截所有 sql 做智能分析,自动监控节点负载,自动优化路由,提供数据库优化建议
SQL 拦截的原理是在路由之前拦截 SQL,然后做其他处理,完了之后再做路由,执行,如下图所示:
![]()
默认的拦截器实现了 Mysql 转义字符的过滤转换,非默认拦截器只有一个拦截记录 sql 的拦截器。
a. 默认 SQL 拦截器:
配置:
<system>
<property name="sqlInterceptor">io.mycat.interceptor.impl.DefaultSqlInterceptor</property>
</system>
源码:
/**
* escape mysql escape letter
*/
@Override
public String interceptSQL(String sql, int sqlType) {
if (sqlType == ServerParse.UPDATE || sqlType == ServerParse.INSERT||sqlType ==
ServerParse.SELECT||sqlType == ServerParse.DELETE) {
return sql.replace("\\'", "''");
} else {
return sql;
} }
b. 捕获记录 sql 拦截器配置:
<system>
<property name="sqlInterceptor">io.mycat.interceptor.impl.StatisticsSqlInterceptor</property>
<property name="sqlInterceptorType">select,update,insert,delete</property>
<property name="sqlInterceptorFile">E:/mycat/sql.txt</property>
</system>
sqlInterceptorType : 拦截 sql 类型
sqlInterceptorFile : sql 保存文件路径
注意:捕获记录 sql 拦截器的配置只有 1.4 及其以后可用,1.3 无本拦截。
如果需要实现自己的 sql 拦截,只需要将配置类改为自己配置即可:
1.定义自定义类 implements SQLInterceptor ,然后改写 sql 后返回。
2.将自己实现的类放入 catlet 目录,可以为 class 或 jar。
3.配置配置文件:
<system>
<property name="sqlInterceptor">io.mycat.interceptor.impl.自定义 class</property>
<!--其他配置-->
</system>
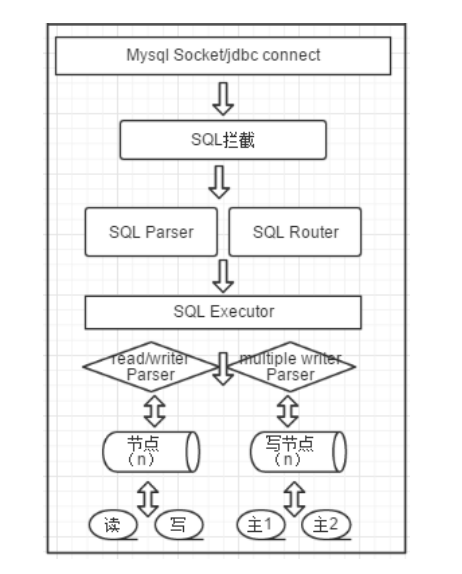
三、核心流程总结
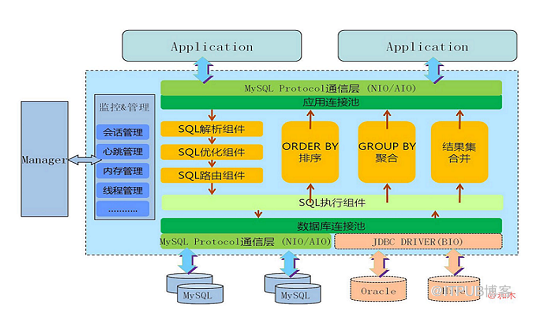
官网的架构图:
![]()
启动
1、MycatServer 启动,解析配置文件,包括服务器、分片规则等
2、创建工作线程,建立前端连接和后端连接
执行 SQL
1、前端连接接收 MySQL 命令
2、解析 MySQL,Mycat 用的是 Druid 的 DruidParser
3、获取路由
4、改写 MySQL,例如两个条件在两个节点上,则变成两条单独的 SQL
例如 select * from text where id in(5000001, 10000001);
改写成:
select * from text where id = 5000001;(dn2 执行)
select * from text where id = 10000001;(dn3 执行)
又比如多表关联查询,先到各个分片上去获取结果,然后在内存中计算
5、与后端数据库建立连接
6、发送 SQL 语句到 MySQL 执行
7、获取返回结果
8、处理返回结果,例如排序、计算等等
9、返回给客户端
四、Mycat 高可用
目前 Mycat 没有实现对多 Mycat 集群的支持。集群之前最麻烦的是数据同步和选举。可以暂时使用 HAProxy+Keepalived 实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号