
Sentinel的熔断降级源码分析(二十)
限流原理分析
在Sentinel中,所有的资源都对应一个资源名称以及一个Entry。每一个entry可以表示一个请求。而Sentinel中,会针对当前请求基于规则的判断来实现流控的控制,原理如下图所示。
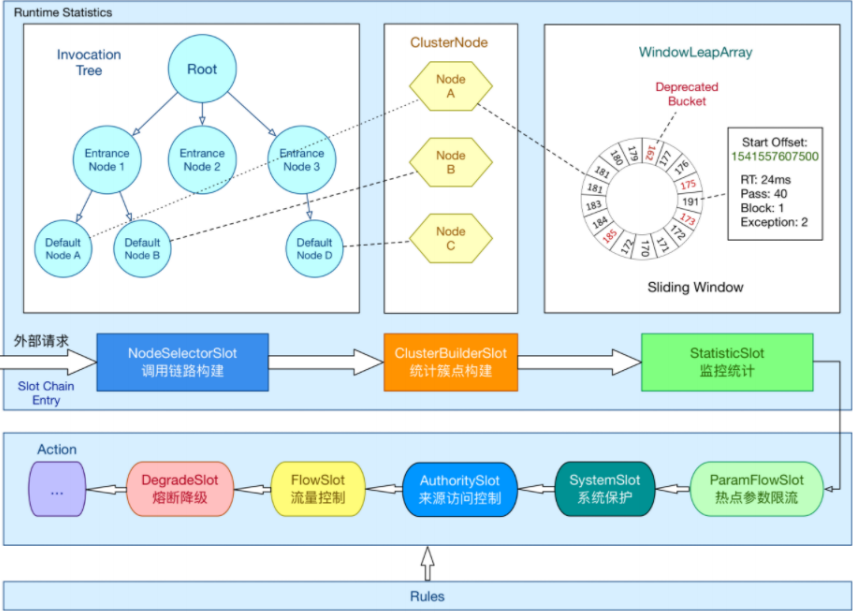
当一个外部请求过来之后,会创建一个Entry,而创建Entry的同时,也会创建一系列的slot 组成一个责任链,每个slot有不同的工作职责。
- NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
- ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS,thread count 等等,这些信息将用作为多维度限流,降级的依据;
- StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;
- FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;
- AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;
- DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;
- SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
- LogSlot 在出现限流、熔断、系统保护时负责记录日志
Sentinel 将 ProcessorSlot 作为 SPI 接口进行扩展(1.7.2 版本以前 SlotChainBuilder 作为SPI),使得 Slot Chain 具备了扩展的能力。您可以自行加入自定义的 slot 并编排 slot 间的顺序,从而可以给 Sentinel 添加自定义的功能。
Spring Cloud 集成Sentinel的原理
Spring Cloud 中集成Sentinel限流,是基于过滤器来实现,具体的实现路径如下。
- SentinelWebAutoConfifiguration
- addInterceptors
- SentinelWebInterceptor->AbstractSentinelInterceptor
- addInterceptors
自动装配类
public void addInterceptors(InterceptorRegistry registry) { if (this.sentinelWebInterceptorOptional.isPresent()) { Filter filterConfig = this.properties.getFilter(); registry.addInterceptor((HandlerInterceptor)this.sentinelWebInterceptorOptional.get()).order(filterConfig.getOrder()).addPathPatterns(filterConfig.getUrlPatterns()); log.info("[Sentinel Starter] register SentinelWebInterceptor with urlPatterns: {}.", filterConfig.getUrlPatterns()); } }
进入针对SentinelWebAutoConfiguration的拦截器中,里面会添加一个新的拦截器,他是针对SentinelWebInterceptor的拦截,里面有一个getResourceName方法,这是得到资源名称的类里面没找到什么核心代码
protected String getResourceName(HttpServletRequest request) { Object resourceNameObject = request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE); if (resourceNameObject != null && resourceNameObject instanceof String) { String resourceName = (String)resourceNameObject; UrlCleaner urlCleaner = this.config.getUrlCleaner(); if (urlCleaner != null) { resourceName = urlCleaner.clean(resourceName); } if (StringUtil.isNotEmpty(resourceName) && this.config.isHttpMethodSpecify()) { resourceName = request.getMethod().toUpperCase() + ":" + resourceName; } return resourceName; } else { return null; } }
看下父类,发现通过ContextUtil.enter(contextName, origin);设置了一个请求来源的信息,然后通过SphU.entry去调用
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { try { String resourceName = this.getResourceName(request); if (StringUtil.isEmpty(resourceName)) { return true; } else if (this.increaseReferece(request, this.baseWebMvcConfig.getRequestRefName(), 1) != 1) { return true; } else { String origin = this.parseOrigin(request); String contextName = this.getContextName(request); ContextUtil.enter(contextName, origin); Entry entry = SphU.entry(resourceName, 1, EntryType.IN); request.setAttribute(this.baseWebMvcConfig.getRequestAttributeName(), entry); return true; } } catch (BlockException var12) { BlockException e = var12; try { this.handleBlockException(request, response, e); } finally { ContextUtil.exit(); } return false; } }
Dubbo集成Sentinel的原理
在集成Dubb的案例中,引入了一个适配的包,这个包会提供集成Sentinel的功能。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-apache-dubbo-adapter</artifactId>
</dependency>
分别提供了两个类
- SentinelDubboConsumerFilter
- SentinelDubboProviderFilter
分别提供针对服务消费端的过滤器,和服务提供端的过滤器。
最终,当触发限流或者降级时,可以实现一个全局的DubboFallback回调,分别为服务提供端、服务消费端提供fallback的实现。然后需要调用 DubboFallbackRegistry 的 setConsumerFallback 和 setProviderFallback 方法分别注册消费端,服务端相关的监听器。通常只需要在启动应用的时候,将其进行注册即可。
SphU.entry
不管是集成dubbo也好,还是集成到spring cloud中也好,最终都是调用SphU.entry这个方法来进行限流判断的,接下来我们从SphU.entry这个方法中去了解它的实现原理。
- ResourceWrapper 表示sentinel的资源,做了封装
- count表示本次请求的占用的并发数量,默认是1
- prioritized,优先级
private Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, boolean prioritized, Object... args) throws BlockException { //获取上下文环境,存储在ThreadLocal中,context中会存储整个调用链 Context context = ContextUtil.getContext(); if (context instanceof NullContext) {//上下文context已经超过阈值,不进行规则检查, 只初始化CtEntry。 // The {@link NullContext} indicates that the amount of context has exceeded the threshold, // so here init the entry only. No rule checking will be done. return new CtEntry(resourceWrapper, null, context); } if (context == null) {//使用默认context // Using default context. context = InternalContextUtil.internalEnter(Constants.CONTEXT_DEFAULT_NAME); } // Global switch is close, no rule checking will do. if (!Constants.ON) {//全局限流开关是否已经开启,如果关闭了,就不进行限流规则检查 return new CtEntry(resourceWrapper, null, context); } //构建一个slot链表 ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper); /* * Means amount of resources (slot chain) exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE}, * so no rule checking will be done. */ //在生成chain的里面有个判断,如果chainMap.size大于一个值就返回null,也不进行规则检测 if (chain == null) { return new CtEntry(resourceWrapper, null, context); } //下面这里才真正开始,生成个entry Entry e = new CtEntry(resourceWrapper, chain, context); try { //开始检测限流规则 chain.entry(context, resourceWrapper, null, count, prioritized, args); } catch (BlockException e1) { e.exit(count, args);//被限流,抛出异常。 throw e1; } catch (Throwable e1) { // This should not happen, unless there are errors existing in Sentinel internal. RecordLog.info("Sentinel unexpected exception", e1); } return e;//返回正常的结果 }
lookProcessChain
构建一个slot链,链路的组成为DefaultProcessorSlotChain -> NodeSelectorSlot -> ClusterBuilderSlot -> LogSlot ->StatisticSlot -> AuthoritySlot -> SystemSlot -> ParamFlowSlot -> FlowSlot -> DegradeSlot
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) { ProcessorSlotChain chain = chainMap.get(resourceWrapper); if (chain == null) { synchronized (LOCK) { chain = chainMap.get(resourceWrapper); if (chain == null) { //chainMap大小大于一个值,也就是entry数量大小限制了,一个chain对应一个 entry // Entry size limit. if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) { return null; } //构建一个slot chain chain = SlotChainProvider.newSlotChain(); //这里是逻辑是,新建一个Map大小是oldMap+1 Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>( chainMap.size() + 1); //然后先整体放入oldMap,再放新建的chain newMap.putAll(chainMap); newMap.put(resourceWrapper, chain);//添加到newMap, 这里应该是考虑 避免频繁扩容 chainMap = newMap; } } } return chain; }
整体流程图
整体的执行流程如下。
- NodeSelectorSlot:主要用于构建调用链。
- ClusterBuilderSlot:用于集群限流、熔断。
- LogSlot:用于记录日志。
- StatisticSlot:用于实时收集实时消息。
- AuthoritySlot:用于权限校验的。
- SystemSlot:用于验证系统级别的规则。
- FlowSlot:实现限流机制。
- DegradeSlot:实现熔断机制。
NodeSelectorSlot
回退代码进入开始检测限流规则这个类主要用于构建调用链,这个需要讲解一下,在后续过程中会比较关键,代码如下。
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
throws Throwable {
/*
* It's interesting that we use context name rather resource name as the map key.
*
* Remember that same resource({@link ResourceWrapper#equals(Object)}) will share
* the same {@link ProcessorSlotChain} globally, no matter in which context. So if
* code goes into {@link #entry(Context, ResourceWrapper, DefaultNode, int, Object...)},
* the resource name must be same but context name may not.
*
* If we use {@link com.alibaba.csp.sentinel.SphU#entry(String resource)} to
* enter same resource in different context, using context name as map key can
* distinguish the same resource. In this case, multiple {@link DefaultNode}s will be created
* of the same resource name, for every distinct context (different context name) each.
*
* Consider another question. One resource may have multiple {@link DefaultNode},
* so what is the fastest way to get total statistics of the same resource?
* The answer is all {@link DefaultNode}s with same resource name share one
* {@link ClusterNode}. See {@link ClusterBuilderSlot} for detail.
*/
DefaultNode node = map.get(context.getName());
if (node == null) {
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
node = new DefaultNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
// Build invocation tree
((DefaultNode) context.getLastNode()).addChild(node);
}
}
}
context.setCurNode(node);
//释放entry,可以跟进
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
这里有几个对象要单独说明:
- context:表示上下文,一个线程对应一个context,其中包含一些属性如下
- name:名字
- entranceNode:调用链入口
- curEntry:当前entry
- origin:调用者来源
- async:异步
- Node: 表示一个节点,这个节点会保存某个资源的各个实时统计数据,通过访问某个节点,就可以获得对应资源的实时状态,根据这个信息来进行限流和降级,它有几种节点类型
- StatisticNode:统计节点
- DefaultNode:默认节点,NodeSelectorSlot中创建的就是这个节点
- ClusterNode:集群节点
- EntranceNode:该节点表示一棵调用链树的入口节点,通过他可以获取调用链树中所有的子节点
- NodeSelectorSlot运行结束之后,context的初始结构如下图所示,其中两个Node指向的是同一个对象
@Override public void fireEntry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args) throws Throwable { if (next != null) { next.transformEntry(context, resourceWrapper, obj, count, prioritized, args); } }
@SuppressWarnings("unchecked") void transformEntry(Context context, ResourceWrapper resourceWrapper, Object o, int count, boolean prioritized, Object... args) throws Throwable { T t = (T)o; entry(context, resourceWrapper, t, count, prioritized, args); }
StatisticSlot
在整个slot链路中,比较重要的,就是流量数据统计以及流量规则检测这两个slot,我们先来分析一下StatisticSlot这个对象。StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
- clusterNode :资源唯一标识的 ClusterNode 的 runtime 统计
- origin :根据来自不同调用者的统计信息
- defaultnode : 根据上下文条目名称和资源 ID 的 runtime 统计
- 入口的统计
@Override public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args) throws Throwable { try { // 先交由后续的限流&降级等processorSlot处理,然后根据处理结果进行统计 // Sentinel责任链的精华(不使用 for 循环遍历调用 ProcessorSlot 的原因) fireEntry(context, resourceWrapper, node, count, prioritized, args); // Request passed, add thread count and pass count. node.increaseThreadNum();//当前节点的请求线程数加1 node.addPassRequest(count);//滑动窗口的实现 //针对不同类型的node记录线程数量和请求通过数量的统计。 if (context.getCurEntry().getOriginNode() != null) { // Add count for origin node. context.getCurEntry().getOriginNode().increaseThreadNum(); context.getCurEntry().getOriginNode().addPassRequest(count); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseThreadNum(); Constants.ENTRY_NODE.addPassRequest(count); } //可调用 StatisticSlotCallbackRegistry#addEntryCallback 静态方法注册 ProcessorSlotEntryCallback // Handle pass event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onPass(context, resourceWrapper, node, count, args); } //优先级等待异常,这个在FlowRule中会有涉及到。 } catch (PriorityWaitException ex) { node.increaseThreadNum(); if (context.getCurEntry().getOriginNode() != null) { // Add count for origin node. context.getCurEntry().getOriginNode().increaseThreadNum(); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseThreadNum(); } // Handle pass event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onPass(context, resourceWrapper, node, count, args); } } catch (BlockException e) { // Blocked, set block exception to current entry. context.getCurEntry().setBlockError(e);//设置限流异常到当前entry中 //根据不同Node类型增加阻塞限流的次数 // Add block count. node.increaseBlockQps(count);//增加被限流的数量 if (context.getCurEntry().getOriginNode() != null) { context.getCurEntry().getOriginNode().increaseBlockQps(count); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseBlockQps(count); } // Handle block event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onBlocked(e, context, resourceWrapper, node, count, args); } throw e; } catch (Throwable e) { // Unexpected internal error, set error to current entry. context.getCurEntry().setError(e); throw e; } }
仔细观察这段代码可以看到,StatisticSlot会分别对线程数和QPS进行递增,这个递增操作会涉及到不同纬度的请求数量的统计。
DefaultNode.addPassRequest
@Override public void addPassRequest(int count) { // 调用父类(StatisticNode)来进行统计 super.addPassRequest(count); // 根据clusterNode 汇总统计(背后也是调用父类StatisticNode) this.clusterNode.addPassRequest(count); }
StatisticNode.addPassRequest
分别调用两个时间窗口来递增请求数量。内部实际调用的是ArrayMetric来进行请求数量的统计
//按照秒来统计,分成两个窗口,每个窗口500ms,用来统计QPS private transient volatile Metric rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT, IntervalProperty.INTERVAL); /** * Holds statistics of the recent 60 seconds. The windowLengthInMs is deliberately set to 1000 milliseconds, * meaning each bucket per second, in this way we can get accurate statistics of each second. */ //按照分钟统计,生成60个窗口,每个窗口1000ms private transient Metric rollingCounterInMinute = new ArrayMetric(60, 60 * 1000, false); @Override public void addPassRequest(int count) { rollingCounterInSecond.addPass(count); rollingCounterInMinute.addPass(count); }
这里采用的是滑动窗口的方式来记录请求的次数。
滑动窗口有关的核心类图
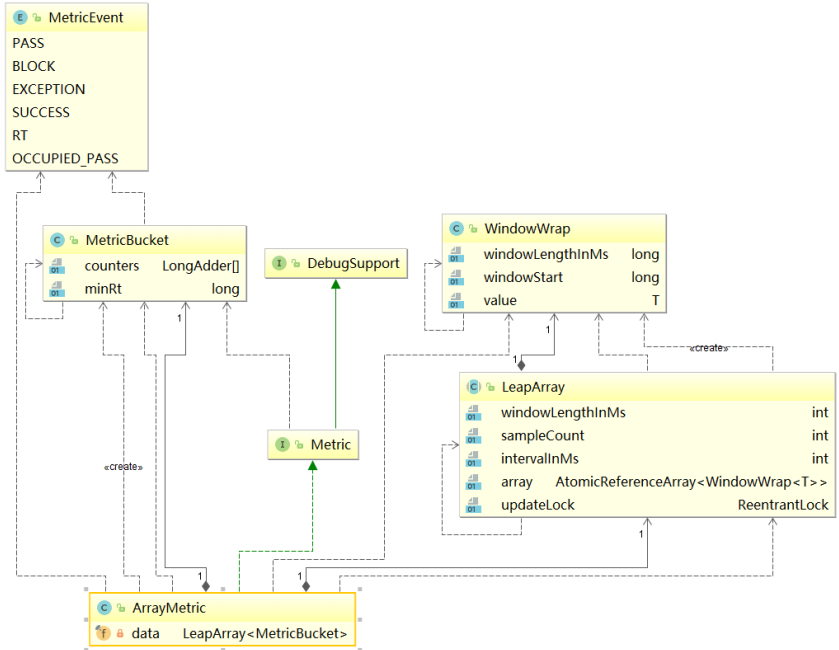
整个类的关系图实际上是比较清晰的,ArrayMetric实际上是一个包装类,内部通过LeapArray来实现具体的统计逻辑,而LeapArray中维护了多个WindowWrap(滑动窗口),而WindowWrap中采用了MetricBucket来进行指标数据的统计。
- Metric: 指标收集的接口,定义滑动窗口中成功数量、异常数量、阻塞数量、TPS、响应时间等数据
- ArrayMetric 滑动窗口核心实现类
- LeapArray
- WindowWrap 每一个滑动窗口的包装类,内部的数据结构采用MetricBucket
- MetricBucket, 表示指标桶,包含阻塞数量、异常数量、成功数、响应时间等
- MetricEvent 指标类型,通过数、阻塞数、异常数、成功数等
ArrayMetric.addPass
继续沿着代码往下看,进入到ArrayMetric.addPass方法。
- 从LeapArray中根据得到当前时间点对应的窗口
- 调用MetricBucket中的addPass方法,增加当前窗口中的统计次数
@Override public void addPass(int count) { WindowWrap<MetricBucket> wrap = data.currentWindow(); wrap.value().addPass(count); }
其中,data对象的实例是,sampleCount=2 , intervalInMs=1000ms。这两个参数表示,滑动窗口的大小是2个,每一个滑动窗口的时间单位是500ms
public ArrayMetric(int sampleCount, int intervalInMs) { this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs); }
OccupiableBucketLeapArray: 实现的思想是当前抽样统计中的“令牌”已耗尽,即达到用户设定的相关指标的阔值后,可以向下一个时间窗口,即借用未来一个采样区间。这块在后续会涉及到,暂时先不讲。
滑动窗口初始化之后的形态
在以秒为单位的时间窗口中,会初始化两个长度的数组: AtomicReferenceArray<WindowWrap<T>>array ,这个数组表示滑动窗口的大小。其中,每个窗口会占用500ms的时间。
LeapArray.currentWindow
根据当前时间,从滑动窗口中获得指定的WindowWrap对象,然后更新对应的各项指标。由于后续做限流规则判断的时候使用。
public WindowWrap<T> currentWindow(long timeMillis) { if (timeMillis < 0) { return null; } //计算当前时间在滑动窗口中的索引,计算方式比较简单,当前时间除以单个时间窗口的时间长度, // 再 从整个时间窗口长度进行取模 int idx = calculateTimeIdx(timeMillis); // Calculate current bucket start time. // 计算当前时间在时间窗口中的开始时间 long windowStart = calculateWindowStart(timeMillis); /* * Get bucket item at given time from the array. * * (1) Bucket is absent, then just create a new bucket and CAS update to circular array. * (2) Bucket is up-to-date, then just return the bucket. * (3) Bucket is deprecated, then reset current bucket and clean all deprecated buckets. */ while (true) { WindowWrap<T> old = array.get(idx);//通过索引找到制定的窗口 if (old == null) {//如果为空,说明此处还未初始化 /* * B0 B1 B2 NULL B4 * ||_______|_______|_______|_______|_______||___ * 200 400 600 800 1000 1200 timestamp * ^ * time=888 * bucket is empty, so create new and update * * If the old bucket is absent, then we create a new bucket at {@code windowStart}, * then try to update circular array via a CAS operation. Only one thread can * succeed to update, while other threads yield its time slice. */ //构建一个新的windowWrap对象 WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis)); if (array.compareAndSet(idx, null, window)) {//通过cas操作替换到array窗 口数组中。 // Successfully updated, return the created bucket. return window;//更新成功,直接返回. } else { // Contention failed, the thread will yield its time slice to wait for bucket available. Thread.yield(); } } else if (windowStart == old.windowStart()) {//如果windowStart得到的窗口就 是当前索引位置的窗口,则直接把该位置的窗口返回 /* * B0 B1 B2 B3 B4 * ||_______|_______|_______|_______|_______||___ * 200 400 600 800 1000 1200 timestamp * ^ * time=888 * startTime of Bucket 3: 800, so it's up-to-date * * If current {@code windowStart} is equal to the start timestamp of old bucket, * that means the time is within the bucket, so directly return the bucket. */ return old; } else if (windowStart > old.windowStart()) { //如果大于,则表示应该在下一个 滑动窗口中 /* * (old) * B0 B1 B2 NULL B4 * |_______||_______|_______|_______|_______|_______||___ * ... 1200 1400 1600 1800 2000 2200 timestamp * ^ * time=1676 * startTime of Bucket 2: 400, deprecated, should be reset * * If the start timestamp of old bucket is behind provided time, that means * the bucket is deprecated. We have to reset the bucket to current {@code windowStart}. * Note that the reset and clean-up operations are hard to be atomic, * so we need a update lock to guarantee the correctness of bucket update. * * The update lock is conditional (tiny scope) and will take effect only when * bucket is deprecated, so in most cases it won't lead to performance loss. */ if (updateLock.tryLock()) {//加锁,并重置MetricBucket try { // Successfully get the update lock, now we reset the bucket. return resetWindowTo(old, windowStart); } finally { updateLock.unlock(); } } else { // Contention failed, the thread will yield its time slice to wait for bucket available. Thread.yield(); } } else if (windowStart < old.windowStart()) { //异常情况 // Should not go through here, as the provided time is already behind. return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis)); } } }
回退代码
@Override public void addPass(int count) { WindowWrap<MetricBucket> wrap = data.currentWindow(); wrap.value().addPass(count); }
public void addPass(int n) { add(MetricEvent.PASS, n); }
MetricBucket.add
public long get(MetricEvent event) { return counters[event.ordinal()].sum(); } //counters的数组长度是6,其中event.ordinal表示MetricEvent, // 那么这里记录的就是,根据 MetricEvent统计指定Event的次数。 public MetricBucket add(MetricEvent event, long n) { counters[event.ordinal()].add(n); return this; }
LongAdder.add
这段代码就是ConcurrentHashMap里面,用来记录请求数量的操作,也就是采用分段锁的方式来做计数处理,从而提升整体的性能。
public void add(long x) { Cell[] as; long b, v; HashCode hc; Cell a; int n; if ((as = cells) != null || !casBase(b = base, b + x)) { boolean uncontended = true; int h = (hc = threadHashCode.get()).code; if (as == null || (n = as.length) < 1 || (a = as[(n - 1) & h]) == null || !(uncontended = a.cas(v = a.value, v + x))) { retryUpdate(x, hc, uncontended); } } }
FlowSlot
这个 slot 主要根据预设的资源的统计信息,按照固定的次序,依次生效。如果一个资源对应两条或者多条流控规则,则会根据如下次序依次检验,直到全部通过或者有一个规则生效为止:
- 指定应用生效的规则,即针对调用方限流的;
- 调用方为 other 的规则;
- 调用方为 default 的规则。
@Override public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args) throws Throwable { checkFlow(resourceWrapper, context, node, count, prioritized); fireEntry(context, resourceWrapper, node, count, prioritized, args); }
checkFlow
进入到FlowRuleChecker.checkFlow方法中。
- 根据资源名称,找到限流规则列表
- 如果限流规则不为空,则遍历规则,调用canPassCheck方法进行校验。
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource, Context context, DefaultNode node, int count, boolean prioritized) throws BlockException { if (ruleProvider == null || resource == null) { return; } Collection<FlowRule> rules = ruleProvider.apply(resource.getName()); if (rules != null) { for (FlowRule rule : rules) { if (!canPassCheck(rule, context, node, count, prioritized)) { throw new FlowException(rule.getLimitApp(), rule); } } } }
canPassCheck
判断是否是集群限流模式,如果是,则走passClusterCheck,否则,调用passLocalCheck方法。
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) { String limitApp = rule.getLimitApp(); if (limitApp == null) { return true; } if (rule.isClusterMode()) { return passClusterCheck(rule, context, node, acquireCount, prioritized); } return passLocalCheck(rule, context, node, acquireCount, prioritized); }
passLocalCheck
- selectNodeByRequesterAndStrategy,根据请求和策略来获得Node
- rule.getRater(), 根据不同的限流控制行为来,调用canPass进行校验。
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) { Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node); if (selectedNode == null) { return true; } return rule.getRater().canPass(selectedNode, acquireCount, prioritized); }
DefaultController.canPass
通过默认的限流行为(直接拒绝),进行限流判断。
public boolean canPass(Node node, int acquireCount, boolean prioritized) { //先根据node获取资源当前的使用数量,这里会根据qps或者并发数策略来获得相关的值 int curCount = avgUsedTokens(node); //当前已使用的请求数加上本次请求的数量是否大于阈值 if (curCount + acquireCount > count) { //如果为true,说明应该被限流 // 如果此请求是一个高优先级请求,并且限流类型为qps,则不会立即失败,而是去占用未来的时 // 间窗口,等到下一个时间窗口通过请求。 if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) { long currentTime; long waitInMs; currentTime = TimeUtil.currentTimeMillis(); waitInMs = node.tryOccupyNext(currentTime, acquireCount, count); if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) { node.addWaitingRequest(currentTime + waitInMs, acquireCount); node.addOccupiedPass(acquireCount); sleep(waitInMs); // PriorityWaitException indicates that the request will pass after waiting for {@link @waitInMs}. throw new PriorityWaitException(waitInMs); } } return false; } return true; }
一旦被拒绝,则抛出 FlowException 异常
PriorityWait
在DefaultController.canPass中,调用如下代码去借后续的窗口
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
node.addOccupiedPass(acquireCount);
addWaitingRequest -> ArrayMetric.addWaiting->OccupiableBucketLeapArray.addWaiting
borrowArray,它是一个FutureBucketLeapArray对象,这里定义的是未来的时间窗口,然后获得未来时间的窗口去增加计数
@Override public void addWaiting(long time, int acquireCount) { WindowWrap<MetricBucket> window = borrowArray.currentWindow(time); window.value().add(MetricEvent.PASS, acquireCount); }
最终,在StatisticSlot.entry中,捕获异常如果存在优先级比较高的任务,并且当前的请求已经达到阈值,抛出这个异常,实际上是去占用未来的一个时间窗口去进行计数,抛出这个异常之后,会进入到StatisticSlot中进行捕获。然后直接通过
@Override public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, boolean prioritized, Object... args) throws Throwable { try { // 先交由后续的限流&降级等processorSlot处理,然后根据处理结果进行统计 // Sentinel责任链的精华(不使用 for 循环遍历调用 ProcessorSlot 的原因) fireEntry(context, resourceWrapper, node, count, prioritized, args); // Request passed, add thread count and pass count. node.increaseThreadNum();//当前节点的请求线程数加1 node.addPassRequest(count);//滑动窗口的实现 //针对不同类型的node记录线程数量和请求通过数量的统计。 if (context.getCurEntry().getOriginNode() != null) { // Add count for origin node. context.getCurEntry().getOriginNode().increaseThreadNum(); context.getCurEntry().getOriginNode().addPassRequest(count); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseThreadNum(); Constants.ENTRY_NODE.addPassRequest(count); } //可调用 StatisticSlotCallbackRegistry#addEntryCallback 静态方法注册 ProcessorSlotEntryCallback // Handle pass event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onPass(context, resourceWrapper, node, count, args); } //优先级等待异常,这个在FlowRule中会有涉及到。 } catch (PriorityWaitException ex) { node.increaseThreadNum(); if (context.getCurEntry().getOriginNode() != null) { // Add count for origin node. context.getCurEntry().getOriginNode().increaseThreadNum(); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseThreadNum(); } // Handle pass event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onPass(context, resourceWrapper, node, count, args); } } catch (BlockException e) { // Blocked, set block exception to current entry. context.getCurEntry().setBlockError(e);//设置限流异常到当前entry中 //根据不同Node类型增加阻塞限流的次数 // Add block count. node.increaseBlockQps(count);//增加被限流的数量 if (context.getCurEntry().getOriginNode() != null) { context.getCurEntry().getOriginNode().increaseBlockQps(count); } if (resourceWrapper.getEntryType() == EntryType.IN) { // Add count for global inbound entry node for global statistics. Constants.ENTRY_NODE.increaseBlockQps(count); } // Handle block event with registered entry callback handlers. for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { handler.onBlocked(e, context, resourceWrapper, node, count, args); } throw e; } catch (Throwable e) { // Unexpected internal error, set error to current entry. context.getCurEntry().setError(e); throw e; } }
集群限流原理
集群限流,每次会发起一个请求到token-server端进行限流判断。
FlowRuleChecker.passClusterCheck
private static boolean passClusterCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) { try { TokenService clusterService = pickClusterService(); if (clusterService == null) { return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized); } long flowId = rule.getClusterConfig().getFlowId(); TokenResult result = clusterService.requestToken(flowId, acquireCount, prioritized); return applyTokenResult(result, rule, context, node, acquireCount, prioritized); // If client is absent, then fallback to local mode. } catch (Throwable ex) { RecordLog.warn("[FlowRuleChecker] Request cluster token unexpected failed", ex); } // Fallback to local flow control when token client or server for this rule is not available. // If fallback is not enabled, then directly pass. return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized); }
这短短的一生我们最终都会失去,不妨大胆一点,爱一个人,攀一座山,追一个梦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号