数据分析之pandas
简介:
pandas是一个强大的python数据分析的工具包,它是基于numpy构建的,正因pandas的出现,让python语言也成为最广泛而且强大的数据分析环境之一。
主要功能:
具备对其功能的数据结构DataFrame,Series
集成时间序列功能
提供丰富的数学运算和操作
灵活处理缺失数据
Series
是一种类似于一堆数组的对象,由一组数据和一组与之相关的数据标签组成。
创建方法:
第一种: pd.Series([4,5,6,7,8]) 执行结果: 0 4 1 5 2 6 3 7 4 8 dtype: int64 # 将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取值,跟之前学过的数组和列表一样 ----------------------------------------------- 第二种: pd.Series([4,5,6,7,8],index=['a','b','c','d','e']) 执行结果: a 4 b 5 c 6 d 7 e 8 dtype: int64 # 自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。 ----------------------------------------------- 第三种: pd.Series({"a":1,"b":2}) 执行结果: a 1 b 2 dtype: int64 # 指定索引 ----------------------------------------------- 第四种: pd.Series(0,index=['a','b','c']) 执行结果: a 0 b 0 c 0 dtype: int64 # 创建一个值都是0的数组 -----------------------------------------------
对于Series,其实我们可以认为它是一个长度固定且有序的字典,因为它的索引和数据是按位置进行匹配的,像我们会使用字典的上下文,就肯定也会使用Series。
缺失数据:
dropna() 过滤掉值为NaN的行
fill()填充缺失数据
isnull()返回布尔数据,缺失值对应为True
notnull()返回布尔数组,缺失值对应为False
# 第一步,创建一个字典,通过Series方式创建一个Series对象 st = {"sean":18,"yang":19,"bella":20,"cloud":21} obj = pd.Series(st) obj 运行结果: sean 18 yang 19 bella 20 cloud 21 dtype: int64 ------------------------------------------ # 第二步 a = {'sean','yang','cloud','rocky'} # 定义一个索引变量 ------------------------------------------ #第三步 obj1 = pd.Series(st,index=a) obj1 # 将第二步定义的a变量作为索引传入 # 运行结果: rocky NaN cloud 21.0 sean 18.0 yang 19.0 dtype: float64 # 因为rocky没有出现在st的键中,所以返回的是缺失值
判断缺失值
1、 obj1.isnull() # 是缺失值返回Ture 运行结果: rocky True cloud False sean False yang False dtype: bool 2、 obj1.notnull() # 不是缺失值返回Ture 运行结果: rocky False cloud True sean True yang True dtype: bool 3、过滤缺失值 # 布尔型索引 obj1[obj1.notnull()] 运行结果: cloud 21.0 yang 19.0 sean 18.0 dtype: float64
DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引。
创建方式:
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来形成DataFrame:
第一种: pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) # 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列 运行结果: one two 0 1 4 1 2 3 2 3 2 3 4 1 > 指定列 可以通过columns参数指定顺序排列 data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) pd.DataFrame(data,columns=['one','two']) # 打印结果会按照columns参数指定顺序 第二种: pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])}) 运行结果: one two a 1 2 b 2 1 c 3 3
常用属性和方法:
index获取行索引
columns获取列索引
T转置
values获取值索引
describe 获取快速统计
one two a 1 2 b 2 1 c 3 3 # 这样一个数组df ----------------------------------------------------------------------------- df.index 运行结果: Index(['a', 'b', 'c'], dtype='object') ---------------------------------------------------------------------------- df.columns 运行结果: Index(['one', 'two'], dtype='object') -------------------------------------------------------------------------- df.T 运行结果: a b c one 1 2 3 two 2 1 3 ------------------------------------------------------------------------- df.values 运行结果: array([[1, 2], [2, 1], [3, 3]], dtype=int64) ------------------------------------------------------------------------ df.describe() 运行结果: one two count 3.0 3.0 mean 2.0 2.0 std 1.0 1.0 min 1.0 1.0 25% 1.5 1.5 50% 2.0 2.0 75% 2.5 2.5 max 3.0 3.0
时间对象处理
时间序列类型
时间戳:特定时刻
固定时间
时间间隔:起始时间-结束时间
时间库 datatime
dt.strftime()
strptime()
灵活处理时间对象:dateutil包
dateutil.parser.parse()
import dateutil dateutil.parser.parse("2019 Jan 2nd") # 这中间的时间格式一定要是英文格式 运行结果: datetime.datetime(2019, 1, 2, 0, 0)
数据分组和聚合
pandas对象(无论Series、DataFrame还是其他的什么)当中的数据会根据提供的一个或者多个键被拆分为多组,拆分操作实在对象的特定轴上执行的。就比如DataFrame可以在他的行上或者列上进行分组,然后将一个函数应用到各个分组上并产生一个新的值。最后将所有的执行结果合并到最终的结果对象中。
分组键的形式:
- 列表或者数组,长度与待分组的轴一样
- 表示DataFrame某个列名的值。
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或者索引中的各个标签吗
后三种只是快捷方式,最终仍然是为了产生一组用于拆分对象的值。
首先,通过一个很简单的DataFrame数组尝试一下:
df = pd.DataFrame({'key1':['x','x','y','y','x',
'key2':['one','two','one',',two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
运行结果:
key1 key2 data1 data2
0 x one 0.951762 1.632336
1 x two -0.369843 0.602261
2 y one 1.512005 1.331759
3 y ,two 1.383214 1.025692
4 x one -0.475737 -1.182826
访问data1,并根据key1调用groupby:
f1 = df['data1'].groupby(df['key1']) f1 运行结果: <pandas.core.groupby.groupby.SeriesGroupBy object at 0x00000275906596D8>
上述运行是没有进行任何计算的,但是我们想要的中间数据已经拿到了,接下来,就可以调用groupby进行任何计算
f1.mean() # 调用mean函数求出平均值 运行结果: key1 x 0.106183 y 2.895220 Name: data1, dtype: float64
以上数据经过分组键(一个Series数组)进行了聚合,产生了一个新的Series,索引就是key1列中的唯一值。这些索引的名称就为key1。接下来就尝试一次将多个数组的列表传进来。
f2 = df['data1'].groupby([df['key1'],df['key2']]) f2.mean() 运行结果: key1 key2 x one 0.083878 two 0.872437 y one -0.665888 two -0.144310 Name: data1, dtype: float64
传入多个数据之后会发现,得到的数据具有一个层次化的索引,key1对应的x\y;key2对应的one\two.
f2.mean().unstack() 运行结果: key2 one two key1 x 0.083878 0.872437 y -0.665888 -0.144310 # 通过unstack方法就可以让索引不堆叠在一起了
apply
GroupBy当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将它们组合到一起
df.apply(
['func', 'axis=0', 'broadcast=None', 'raw=False', 'reduce=None', 'result_type=None', 'args=()', '**kwds']
func:传入一个自定义函数
axis:函数传入参数当axis=1就会把一行数据作为Series的数据
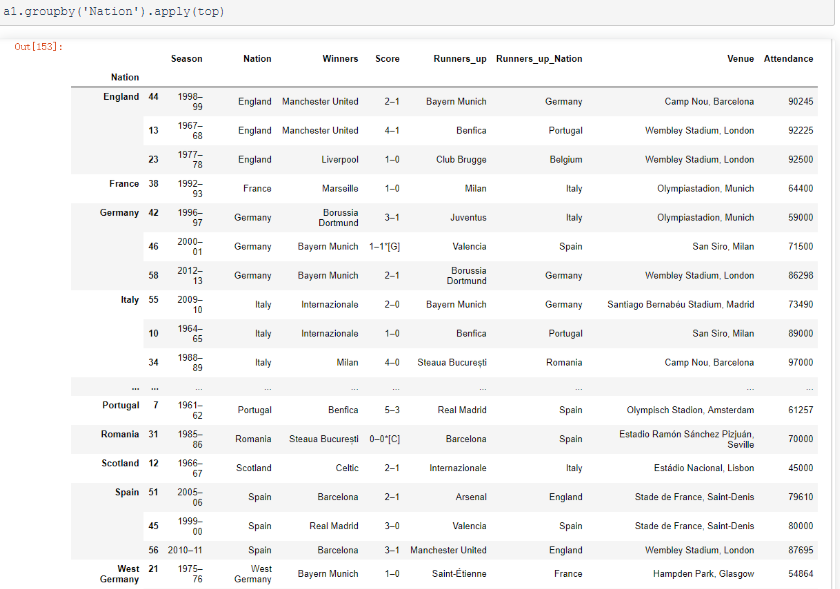
# 分析欧洲杯和欧洲冠军联赛决赛名单 import pandas as pd url="https://en.wikipedia.org/wiki/List_of_European_Cup_and_UEFA_Champions_League_finals" eu_champions=pd.read_html(url) # 获取数据 a1 = eu_champions[2] # 取出决赛名单 a1.columns = a1.loc[0] # 使用第一行的数据替换默认的横向索引 a1.drop(0,inplace=True) # 将第一行的数据删除 a1.drop('#',axis=1,inplace=True) # 将以#为列名的那一列删除 a1.columns=['Season', 'Nation', 'Winners', 'Score', 'Runners_up', 'Runners_up_Nation', 'Venue','Attendance'] # 设置列名 a1.tail() # 查看后五行数据 a1.drop([64,65],inplace=True) # 删除其中的缺失行以及无用行 a1
运行结果

接下来,就对a1分组并且使用apply调用该函数:
a1.groupby('Nation').apply(top)
其他常用方法
pandas其他常用方法(适用于Series和Dataframe)
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis, …, ascending) # 按行或列索引排序
- sort_values(by, axis, ascending) # 按值排序
- apply(func, axis=0) # 将自定义函数应用在各行或者各列上,func可返回标量或者Series
- applymap(func) # 将函数应用在DataFrame各个元素上
- map(func) # 将函数应用在Series各个元素上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号