GPT 1-3 发展简介
1、OPENAI简介
OpenAI总部位于旧金山,由特斯拉的马斯克、Sam Altman及其他投资者在2015年共同创立,目标是开发造福全人类的AI技术。而马斯克则在2018年时因公司发展方向分歧而离开。
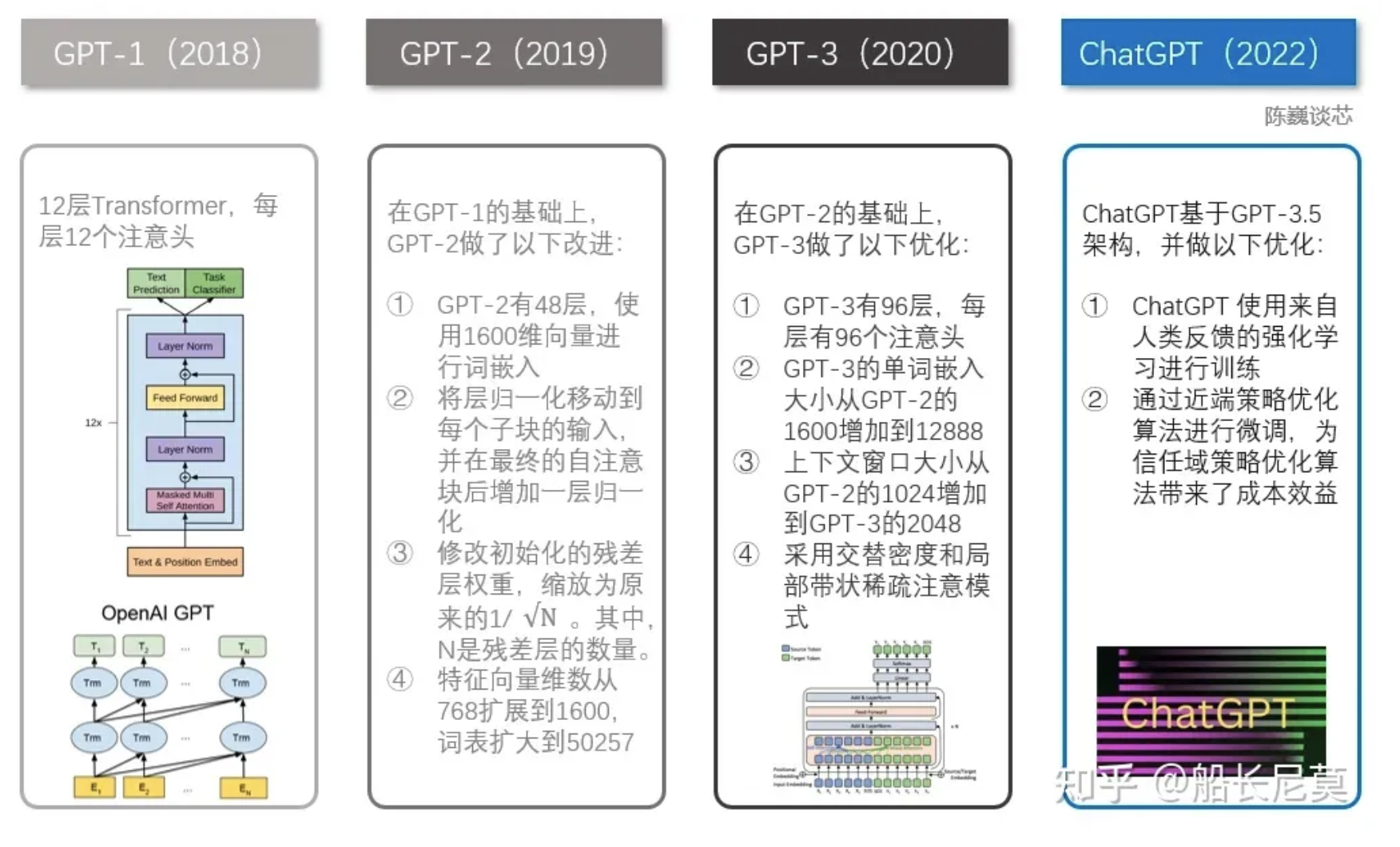
此前,OpenAI 因推出 GPT系列自然语言处理模型而闻名。从2018年起,OpenAI就开始发布生成式预训练语言模型GPT(Generative Pre-trained Transformer),可用于生成文章、代码、机器翻译、问答等各类内容。每一代GPT模型的参数量都爆炸式增长,堪称“越大越好”。2019年2月发布的GPT-2参数量为15亿,而2020年5月的GPT-3,参数量达到了1750亿。从下面的参数量可以看出,这是个多么恐怖的模型。
2、GPT-1介绍
论文链接:GPT Improving Language Understanding by Generative Pre-Training. 2018.
2018年由OpenAI的研究团队发布的一篇论文。它介绍了一种名为“生成式预训练”(Generative Pre-Training,简称GPT)的新型语言模型,该模型通过在大规模语料库上进行训练,能够学习自然语言的模式和规律,从而实现更好的语言理解。
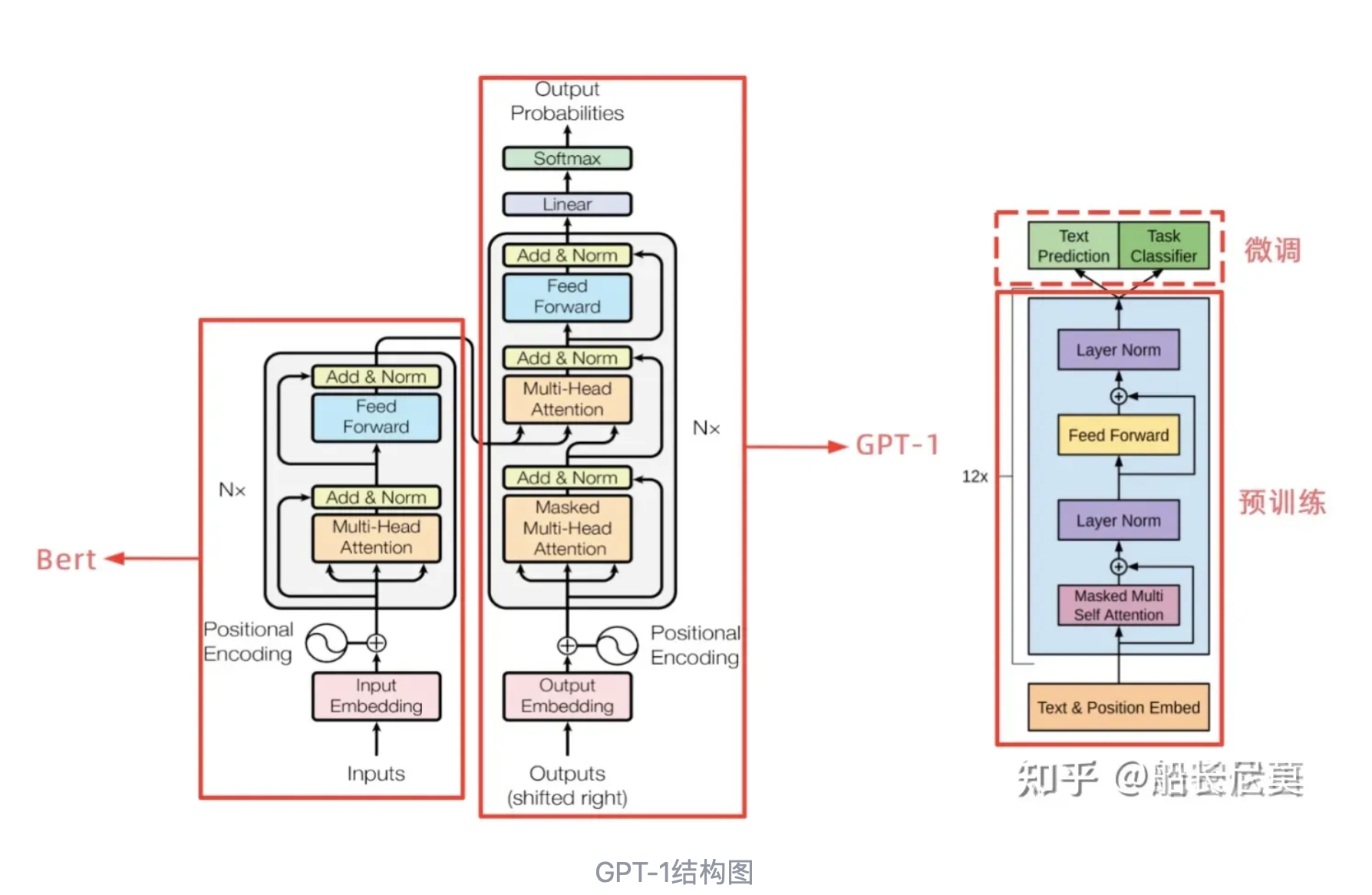
GPT模型是一种基于神经网络的自回归语言模型。该模型使用了一个称为“Transformer”的架构,这是一种新型的序列到序列模型,能够在处理长序列数据时避免传统的循环神经网络(Recurrent Neural Network,RNN)中存在的梯度消失问题。Transformer架构中的关键组件包括多头注意力机制和残差连接等。GPT使用了Transformer的解码器部分。
以下是GPT1的主要技术特点:
基于Transformer架构:GPT1采用了Transformer架构,其中包括多头自注意力机制和前向神经网络。这使得GPT1可以在处理自然语言时捕捉长距离依赖性,并且具有高效的并行性。
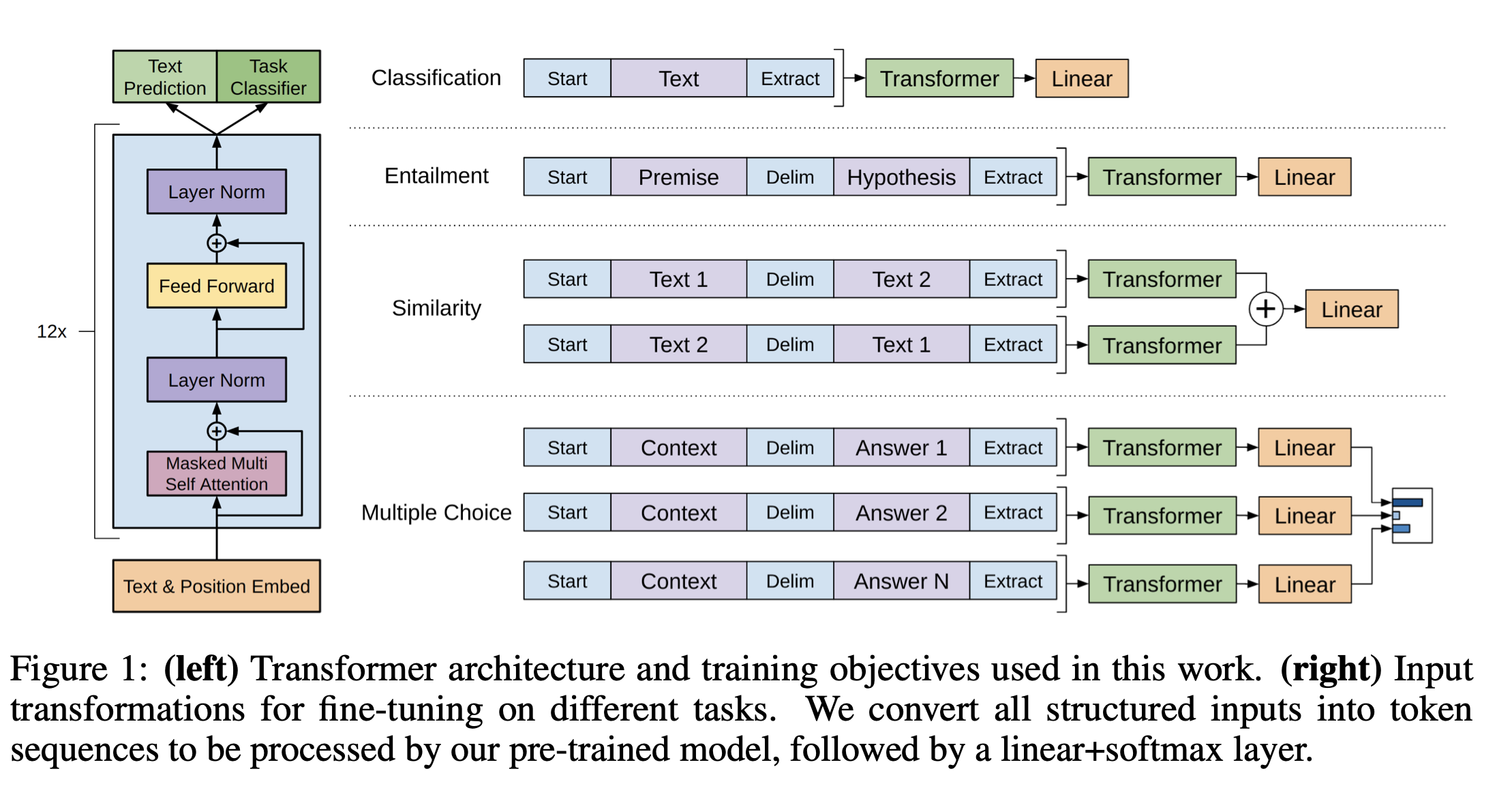
预训练技术:GPT-1使用了一种称为“生成式预训练”(Generative Pre-Training,GPT)的技术。预训练分为两个阶段:预训练和微调(fine-tuning)。在预训练阶段,GPT-1使用了大量的无标注文本数据集,例如维基百科和网页文本等。通过最大化预训练数据集上的log-likelihood来训练模型参数。在微调阶段,GPT-1将预训练模型的参数用于特定的自然语言处理任务,如文本分类和问答系统等。
多层模型:GPT-1模型由多个堆叠的Transformer编码器组成,每个编码器包含多个注意力头和前向神经网络。这使得模型可以从多个抽象层次对文本进行建模,从而更好地捕捉文本的语义信息。通过使用上述预训练任务,研究团队成功地训练出了一个大规模的语言模型GPT。该模型在多项语言理解任务上取得了显著的成果,包括阅读理解、情感分类和自然语言推理等任务。
通过微调GPT模型,可以针对特定的任务进行优化,例如文本生成、机器翻译和对话系统等。
3、GPT2介绍
Language Models are Unsupervised Multitask Learners. 2018.
GPT-2和GPT-1的区别在于GPT-2使用了更多的网络参数和更大的数据集,以此来训练一个泛化能力更强的词向量模型。GPT-2相比于GPT-1有如下几点区别:
- 主推zero-shot,而GPT-1为pre-train+fine-tuning;
- 模型更大,参数量达到了15亿个,而GPT-1只有1亿个;
- 数据集更大,WebText数据集包含了40GB的文本数据,而GPT-1只有5GB;
- 训练参数变化,batch_size 从 64 增加到 512,上文窗口大小从 512 增加到 1024;
3.1、Zero-Shot方法
在 GPT-1 中,模型预训练完成之后会在下游任务上微调,在构造不同任务的对应输入时,我们会引入开始符(Start)、分隔符(Delim)、结束符(Extract)。虽然模型在预训练阶段从未见过这些特殊符号,但是毕竟有微调阶段的参数调整,模型会学着慢慢理解这些符号的意思。
现在,在 GPT-2 中,要做的是 zero-shot,也就是没有任何调整的过程了。这时我们在构造输入时就不能用那些在预训练时没有出现过的特殊符号了。所幸自然语言处理的灵活性很强,我们只要把想要模型做的任务 “告诉” 模型即可,如果有足够量预训练文本支撑,模型想必是能理解我们的要求的。
举个机器翻译的例子,要用 GPT-2 做 zero-shot 的机器翻译,只要将输入给模型的文本构造成 translate english to chinese, [englist text], [chinese text] 就好了。比如:translate english to chinese, [machine learning], [机器学习] 。这种做法就是日后鼎鼎大名的 prompt。下面还有其他任务的zero-shot形式:
4、GPT3介绍
Language Models are Few-Shot Learners
GPT模型指出,如果用Transformer的解码器和大量的无标签样本去预训练一个语言模型,然后在子任务上提供少量的标注样本做微调,就可以很大的提高模型的性能。GPT2则是更往前走了一步,说在子任务上不去提供任何相关的训练样本,而是直接用足够大的预训练模型去理解自然语言表达的要求,并基于此做预测。但是,GPT2的性能太差,有效性低。
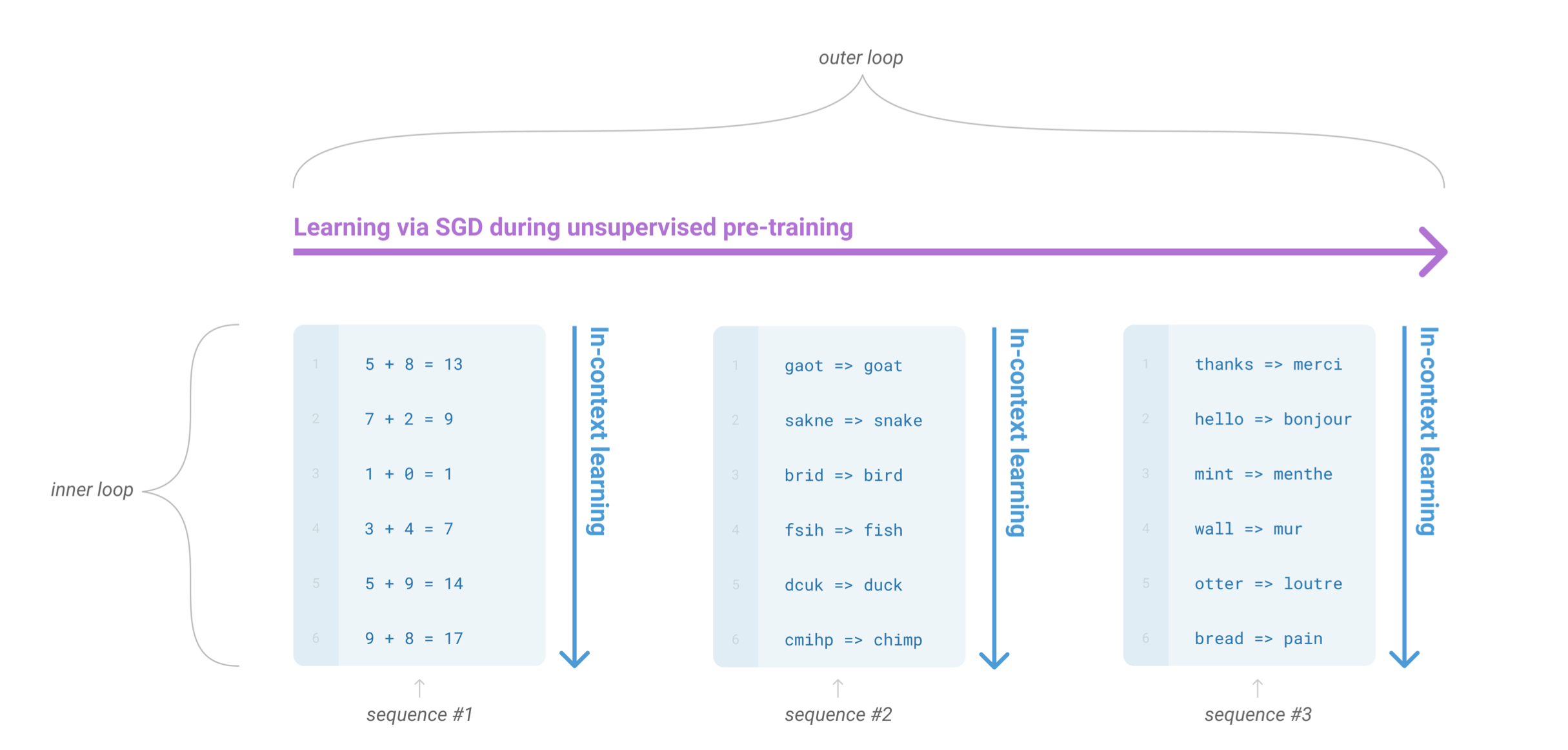
GPT-3是一种语言模型,它可以通过少量的样本进行学习,因此被称为“Few-Shot Learner”。和人类一样,GPT-3不需要完全不看任何样例就能学习,只需要看一小部分样例就能学会更多的知识。GPT-3的体量非常庞大,因此在下游任务中进行fine-tune的成本很高。为了解决这个问题,GPT-3使用了“In-Context Learning”的方式,在不进行梯度更新或fine-tune的情况下,直接在上下文中进行学习。
4.1、GPT-3的few-shot learning是不会做梯度下降,它是怎么做的:
只做预测,不做训练,我们希望Transformer在做前向推理的时候,能够通过注意力机制,从我们给他的输入之中抽取出有用的信息,从而进行预测任务,而预测出来的结果其实也就是我们的任务指示了。这就是上下文学习(In context learning)。
要理解in-context learning,我们需要先理解meta-learning(元学习)。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
为了体现ICL,OpenAI用三个方法来评估他:
1、Few Shot Learning(FS):用自然语言告诉模型任务;对每个子任务,提供10~100个训练样本。
2、One-shot Learning(1S):用自然语言告诉模型任务,而后只给该任务提供1个样本。
3、Zero-shot learning(0S):用自然语言告诉模型任务,但一个样本都不给。

这个模式的缺陷:
- GPT-3的输入窗口长度是有限的,不可能无限的堆叠example的数量,即有限的输入窗口限制了我们利用海量数据的能力。
- 每次做一次新的预测,模型都要从输入的中间抓取有用的信息;可是我们做不到把从上一个输入中抓取到的信息存起来,存在模型中,用到下一次输入里。
5、总结
GPT系列从1到3,通通采用的是transformer架构,模型结构并没有创新性的设计。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。此外,GPT3长文本生成能力还是很弱。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号