搭建ChatGLM2-6B CPU版本
https://huggingface.co/THUDM/chatglm3-6b-32k
https://github.com/THUDM/ChatGLM3
1、前言
1.1、简介
清华开源LLM ChatGLM2-6B是一款对汉语支持不错的大语言模型。由于完全开源,可对其进行微调,对研究LLM本身,以及基于预训练LLM进行领域知识微调验证都有帮助,在国内受到普遍欢迎。该模型可以部署在内存不少于32G的Windows环境中, 本文提供一个简单的安装指导,
如果你只是想快速安装体验,对原理性说明不感兴趣,可以直接跳转到附录A,按照无废话ChatGLM2-6B Windows本地安装指导操作即可。
ChatGLM2-6B对环境有一定要求,这部分对其运行环境进行检查。
作为开源LLM,目前其项目托管在github,模型可在Hugging Face上下载。因此本地安装时需要用到托管代码管理工具git。
1.2、环境
- 主机与操作系统环境
- Windows10以上,64位操作系统
- 内存32G以上
- 空闲磁盘空间20G以上
以上信息可以通过Windows [开始] -> [设置] -> [关于]来查看
- 语言环境
ChatGLM2-6B基于Pytorch AI开发框架、transformers库建设,使用Python语言作为前端开发语言,要求Python版本不低于3.8版本。
- 代码仓管理工具
本文用git作为代码仓管理工具,从github和Hugging Face下载项目文件和模型文件。
1.3、设置pip镜像仓
pip config set global.index-url http://mirrors.****.com/pypi/simple
1.4、设置git外访代理
git config --global http.proxy
git config --global http.sslverify false
git config --global https.proxy
git config --global https.sslverify false
二、下载ChatGLM2-6B项目代码
2.1、下载项目文件
git clone https://github.com/THUDM/ChatGLM2-6B.git
2.2、安装项目依赖库
pip install -r requirements.txt
2.4 修正运行脚本,解决无GPU运行ChatGML2-6B问题
我们需要关注以下四个文件:
cli_demo.py:是一个LLM命令行演示程序,运行后会加载模型数据,以命令行的方式启动人机对话(聊天)。
web_demo.py:是Web版本的演示程序,运行后会加载模型,并启动Web服务,可以通过浏览器远程接入对话。web_demo.py用Gradio部署AI模型,提供可视化交互界面。因其能够直接在jupyter中展示页面,因此在AI开发中广泛使用。
web_demo2.py:是基于Streamlit的Web UI交互示例脚本。Streamlit在AI模型部署上作用与Gradio类似,Streamlit以markdown或html语言渲染页面,据说生成页面使用更流畅;但因其使用复杂,且无法直接在Jupyter中展示页面,相对Gradio,在开发阶段使用较少。
api.py:这个脚本启动ChatGLM2-6B模型,并以服务API的方式提供能力,客户端通过POST服务调用与ChatGLM2-6B模型进行交互。
这四个脚本默认都是将模型加载在GPU上执行计算,如果你的主机上没有GPU,或不支持英伟达CUDA,需要修改上述四个脚本进行适配。
2.4.1、cli_demo.py
这个文件需要修改两处地方。
1、修改第一处
import readline将其注释掉。
2、修改第二处
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
其作用是将保存在相对路径THUDM/chatglm2-6b下的ChatGLM2-B6模型加载到CUDA上运行。如果你的主机上有可用的GPU,且支持CUDA,则无需修改上述代码,否则将其复制一行并注释原始代码,将代码中最后的.cuda()调用修改为.float()调用,即代码修改为:
#model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
2.4.2、web_demo.py
这个文件也涉及两处修改。
1、修改第一处
在文件web_demo.py第7行,会看到加载LLM模型的代码:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
与修改cli_demo.py相同,复制粘贴一行后,将本来的代码注释掉,然后将代码最后的.cuda()调用修改为.float():
#model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
2、修改第二处
在文件web_demo.py的最后一行,可以看到Web交互式部署模型的启动代码:
demo.queue().launch(share=False, inbrowser=True)
这个默认启动使得Web服务只绑定本机本地回环地址127.0.0.1,监听端口7860。这样启动后,服务只能在本机通过
http://127.0.0.1:7860
来打开ChatGLM2-6B的WebUI交互界面。如果你希望改变IP和端口号,就需要修改上面这一行代码,通过命名参数server_name修改主机地址(主机域名或IP地址),通过命名参数server_port修改监听端口号,例如:
demo.queue().launch(server_name=’0.0.0.0’, server_port=8081, share=False, inbrowser=True)
将使得ChatGLM2-6B LLM交互服务部署在本机所有IP的8081端口上,这样就可以远程(根据你的IP开放范围)访问了。
但对外提供服务,如果不做登录认证,会很危险。Gradio提供了登录认证的能力,是通过命名参数auth指定的。该参数可以指定一个用户定义函数来完成认证。输入参数是用户名、密码。函数返回布尔类型结果,如果返回True,表示认证通过,登录成功;否则认证失败,Gradio将禁止接入使用LLM服务。
因此可以先定义一个认证函数:
def my_authentication(username, password):
# 可以根据配置或接入认证服务器完成接入认证
# 本示例简单考虑,用户名固定为'guest',密码是'changeit'
return (username, password) == ('guest', 'changeit')
然后修改启动代码,增加auth参数:
demo.queue().launch(server_name= '0.0.0.0', server_port=8081,
auth=my_authentication,
share=False, inbrowser=True)
2.4.3、web_demo2.py
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
将最后的.cuda()修改为.float():
#model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
2.4.4、修改api.py
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改为
#model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
这个文件的最后一行(第60行)是启动API服务的代码:
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
显然绑定本机所有IP,并监听端口8000,根据个人需要修改,或调整为可通过命令行指定监听端口,本文不做进一步展开。
三、下载ChatGLM2-6B模型
ChatGLM2-6B模型官方下载路径在Hugging Face,大概有12G
ChatGLM2-6B模型文件默认放置在开源项目源代码目录下的THUDM\chatglm2-6b之中,即以本文档示例而言,模型文件全路径是
D:\ChatGLM2-6B\THUDM\chatglm2-6b
这个位置是由开源项目几个.py源文件中代码固定设定的。以cli_demo.py为例,其第7、第8两行代码
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
如果你想把模型文件放到其它地方,需要修改所有.py文件中涉及到的模型加载路径指示串。当然你不想用其开源项目源代码,自己写模型应用,则另当别论。
ChatGLM2-6B模型文件由以下18个文件构成
pytorch_model-0000x-of-0007.bin,共7个文件,就是ChatGLM2-6B模型参数文件,这几个文件都达到或超过1G大小
3.1、下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b THUDM/chatglm2-6b
上述克隆下载命令执行完成后,将会在当前目录下创建子目录THUDM,并在其下创建子目录chatglm2-6b,LLM模型文件会保存在这个目录下。即本文示例中,ChatGLM2-6B模型完整路径为:
D:ChatGLM2-6B\THUDM\chatglm2-6b
下载后,请与图2中文件清单进行比较,确保除两个.txt文件,一个.md文件外的其它15个文件都存在。
你也可以通过浏览器访问以下链接来下载ChatGLM2-6B模型文件:
https://huggingface.co/THUDM/chatglm2-6b
打开上述网页后,需要点击“Files and versions”
在该页面逐个下载模型文件到本地
这种下载方式也不会自动生成模型放置路径,需要自行创建目录,并确保将模型文件放置到正确的位置。本示例中,模型文件放置位置为:
D:ChatGLM2-6B\THUDM\chatglm2-6b
四、运行ChatGLM2-6B LLM模型
ChatGLM2-6B开源项目提供了3种LLM运行方式。无论哪种方式,对于一台没有GPU的普通个人计算机,启动过程都比较漫长。启动后占用内容22G左右,对话后内存占用会进一步增长。
4.1、在清华开源ChatGLM2-6B项目根目录下执行以下命令:
python cli_demo.py
如果没有意外,你将看到模型加载进度条:
Loading checkpoint shards: 57%|████████████ | 4/7 [00:08<00:06, 2.24s/it]
等待一段时间,甚至聆听到CPU风扇的一番挣扎后,你终于看到ChatGLM2-6B的交互提示:
欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户:
意思是,ChatGLM2-6B已经准备好了,你可以输入交流的问题。输入“stop”后退出对话交流。ChatGLM2-6B项目对历史对话进行了简单记忆处理,因此已经交流过的问题可能影响后续交流。如果这种影响造成回答不准确,请输入“clear”将历史对话清空,ChatGLM2-6B将恢复到刚启动时的初始对话状态。
4.2、Web UI交互方式
python web_demo.py
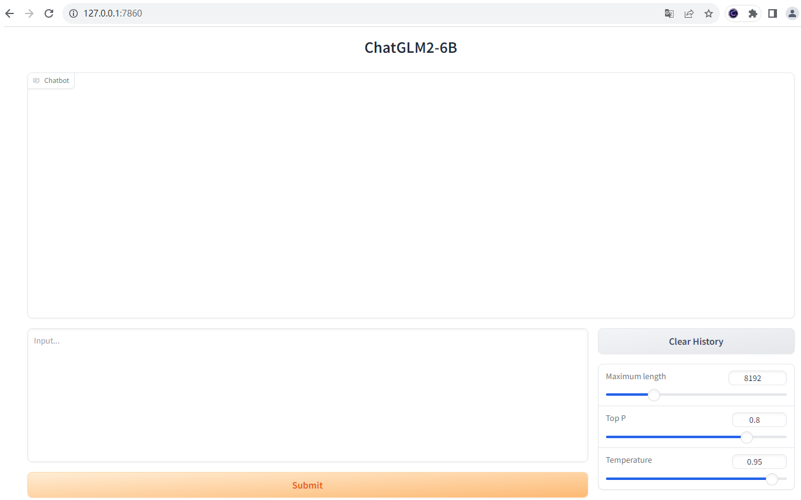
4.3、服务API交互方式
在Windows命令行执行以下命令:
python api.py
同样是加载模型,显示提示:
Loading checkpoint shards: 100%|███████████████████| 7/7 [00:15<00:00, 2.19s/it]
INFO: Started server process [15612]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
curl -X POST http://110.71.46.17:8000 -H "Content-Type: application/json;charset=utf-8" -d "{\"prompt\": \"你好?\", \"history\": []}"
五、总结
清华开源ChatGLM2-6B LLM是一个规模较小的通用预训练语言模型,对中文支持较好,对运行环境要求也比较小,甚至在一台内存不少于32G、无独立GPU显卡的的主机上都可以运行。这么低的入门门槛,为人们体验LLM提供了便利。
不但如此,ChatGLM2-6B开源项目在其主目录下的ptuning子目录中,还提供了P-Tuning微调代码,只需要按要求提供自己的领域微调数据集,代码略作修改即可对ChatGLM2-6B进行微调,形成新的模型检查点。这为一般的LLM应用研究提供了方便。
ChatGLM2-6B同时还推出了32K历史&提示信息版本(需要下载专门的模型版本,本文提供的是通用8K版本的),这为LLM与知识库结合的领域问答系统提供了便利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号