Transformer简介
参考:https://www.zhihu.com/tardis/bd/art/600773858?source_id=1001
Transformer是谷歌在2017年的论文《Attention Is All You Need》中提出的,用于NLP的各项任务
1、Transformer整体结构
在机器翻译中,Transformer可以将一种语言翻译成另一种语言,如果把Transformer看成一个黑盒,那么其结构如下图所示:

拆开这个黑盒,那么可以看到Transformer由若干个编码器和解码器组成,如下图所示
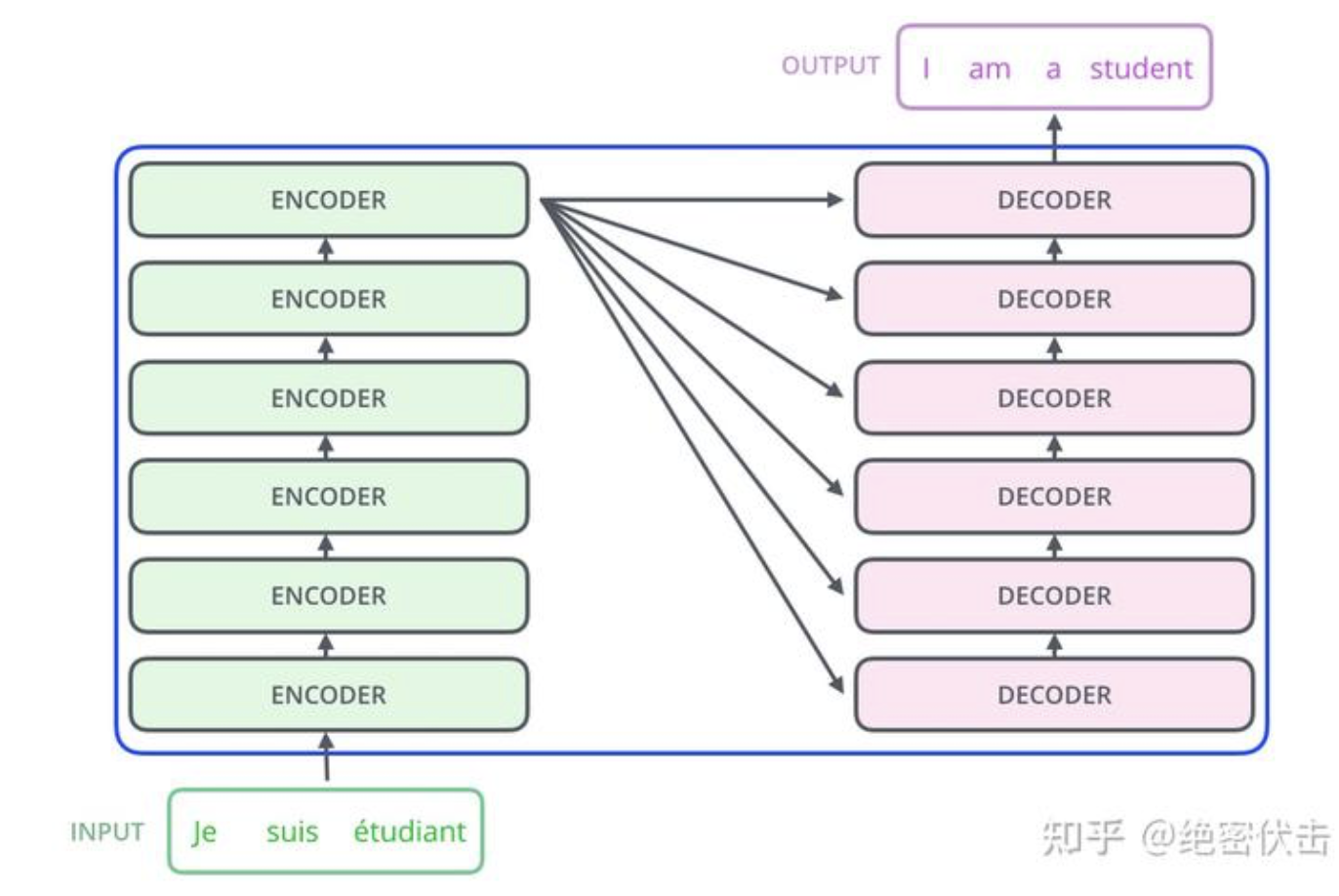
继续将Encoder和Decoder拆开,可以看到完整的结构,如下图所示:
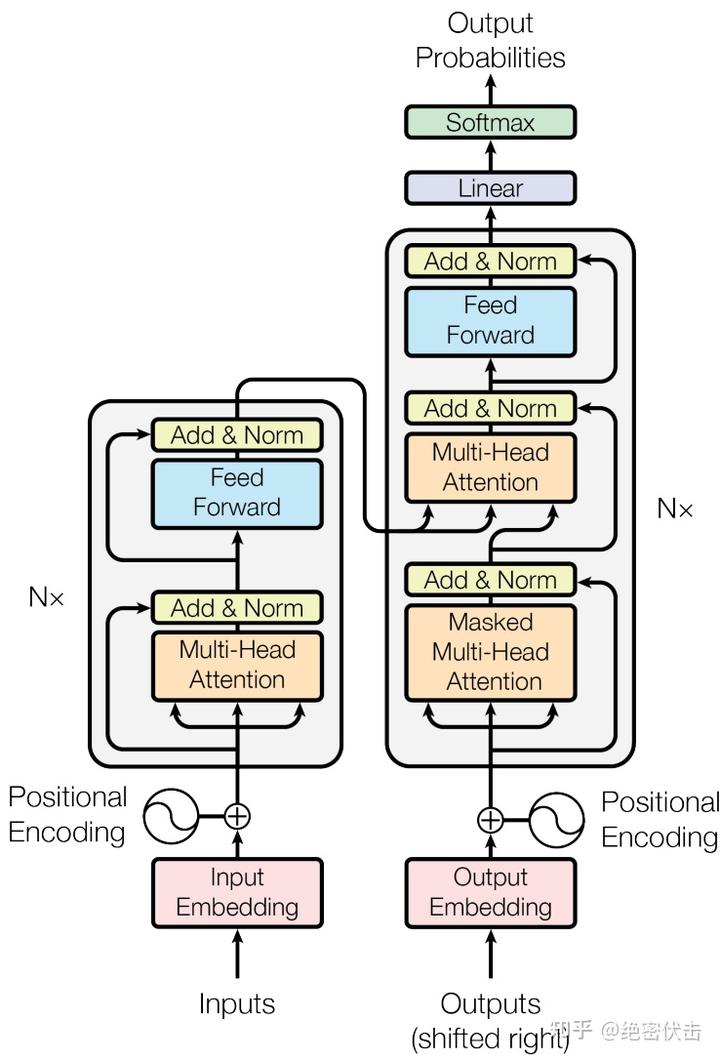
可以看到Encoder包含一个Muti-Head Attention模块,是由多个Self-Attention组成,而Decoder包含两个Muti-Head Attention。Muti-Head Attention上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
假设我们的输入包含两个单词,我们看一下Transformer的整体结构:
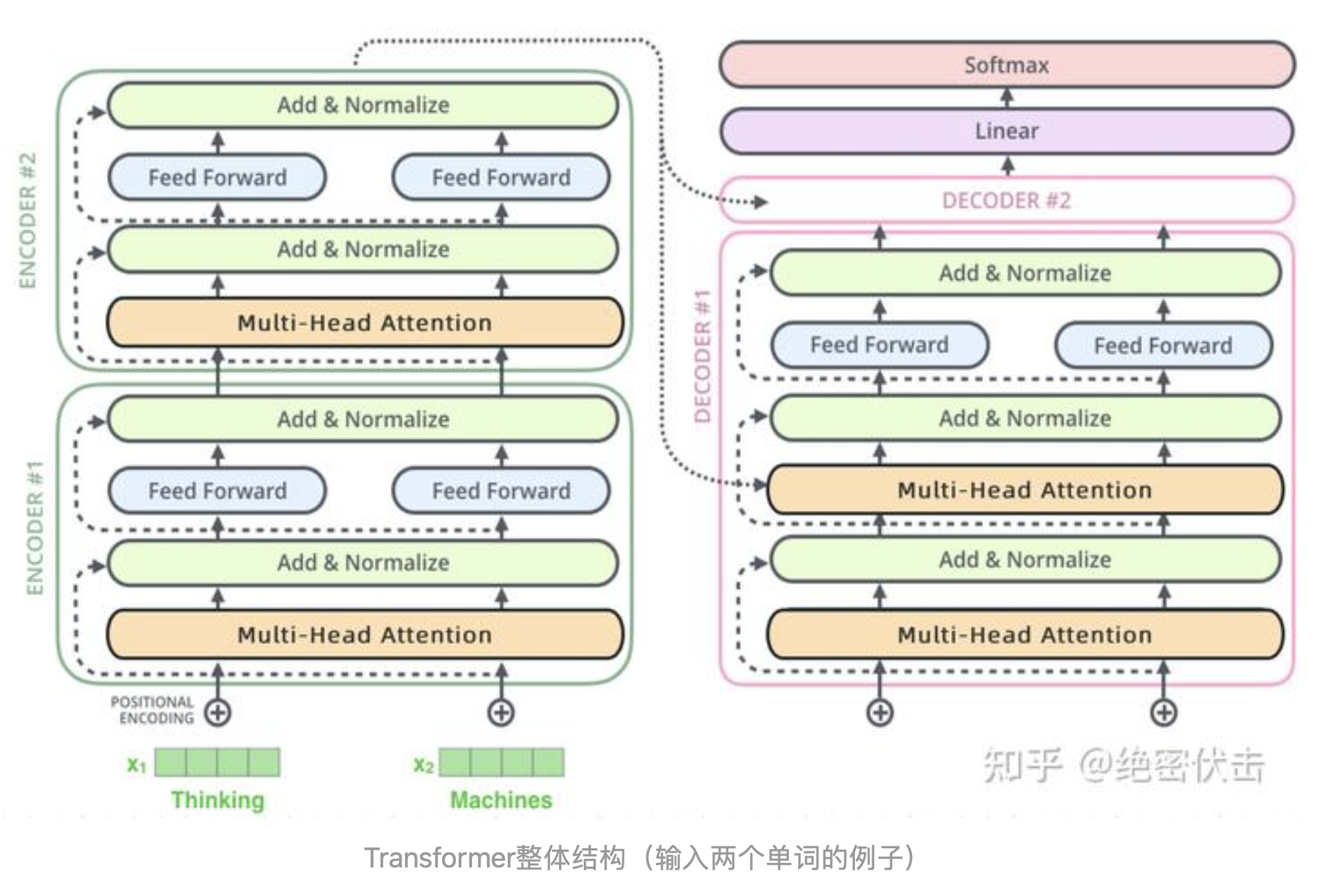
为了能够对Transformer的流程有个大致的了解,我们举一个简单的例子,还是以之前的为例,将法语"Je suis etudiant"翻译成英文。
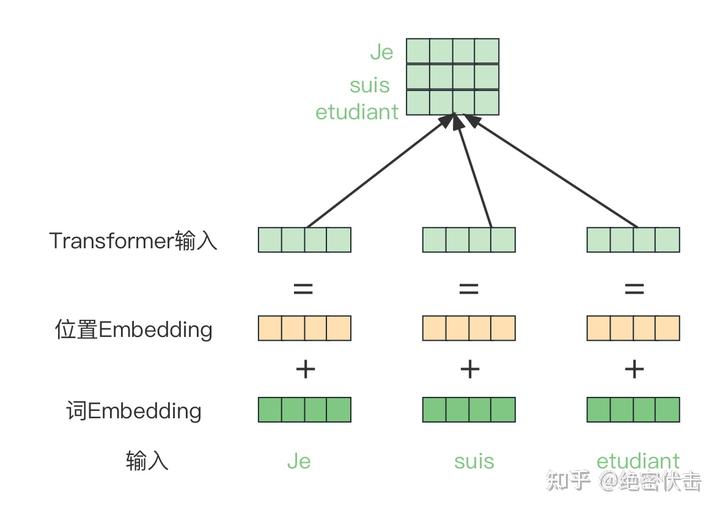
- 第一步:获取输入句子的每一个单词的表示向量
 , 由单词的Embedding和单词位置的Embedding 相加得到。
, 由单词的Embedding和单词位置的Embedding 相加得到。
- 第二步:将单词向量矩阵传入Encoder模块,经过N个Encoder后得到句子所有单词的编码信息矩阵C,如下图。输入句子的单词向量矩阵用 $ X \in{R} ^ {n \times d}$表示,其中n是单词个数,d表示向量的维度,每一个Encoder输出的矩阵维度与输入完全一致。
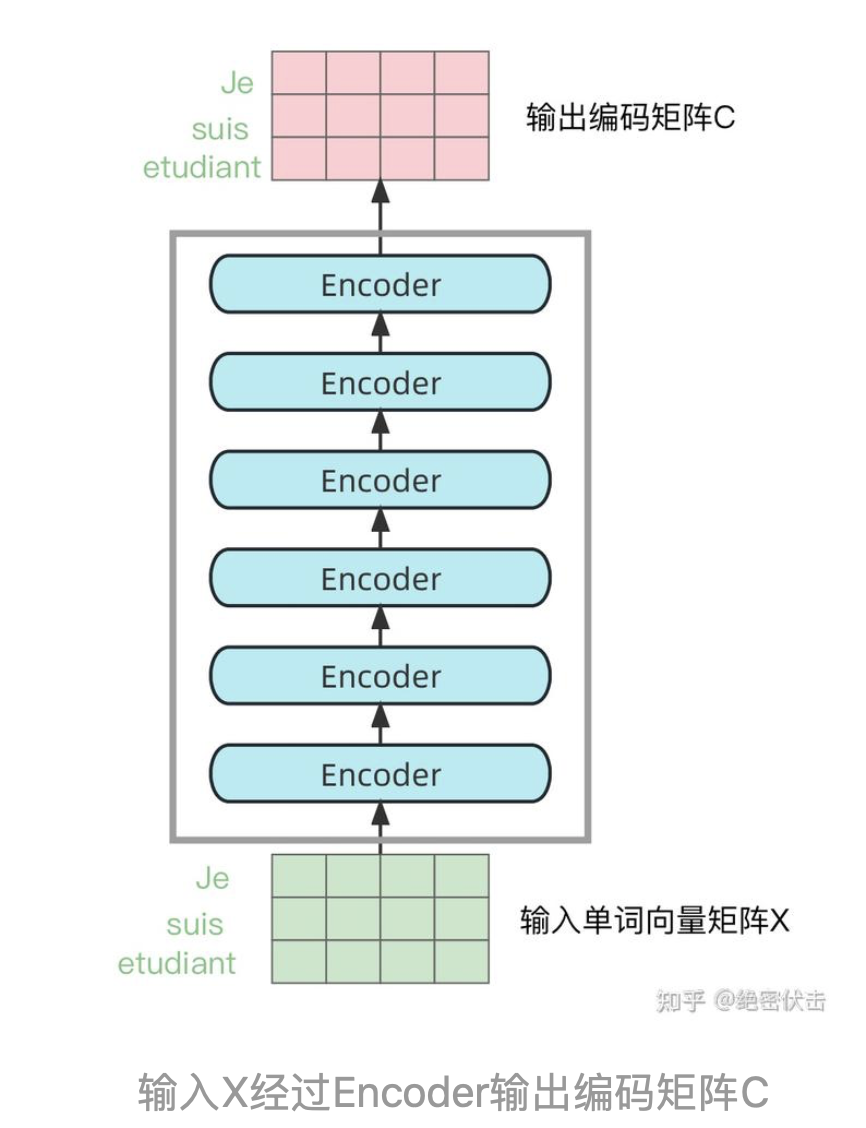
-
第三步:将Encoder输出的编码矩阵C传递到Decoder中,Decoder会根据当前翻译过的单词1~i,翻译下一个单词i+1,如下图所示。
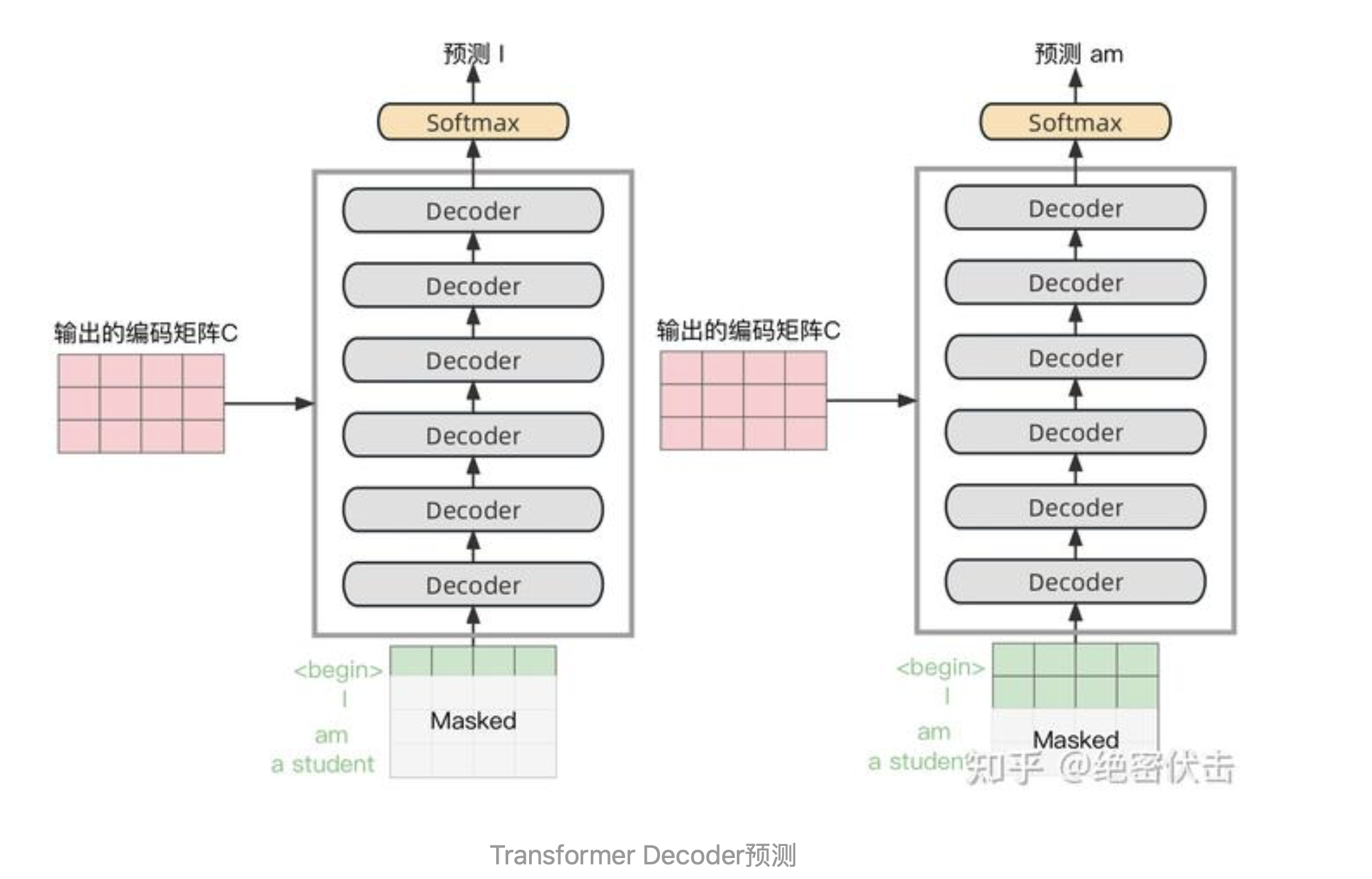
上图Decoder接收了Encoder的编码矩阵,然后首先输入一个开始符 "
2、Transformer的输入表示
Transformer中单词的输入表示由单词Embedding和位置Embedding(Positional Encoding)相加得到。
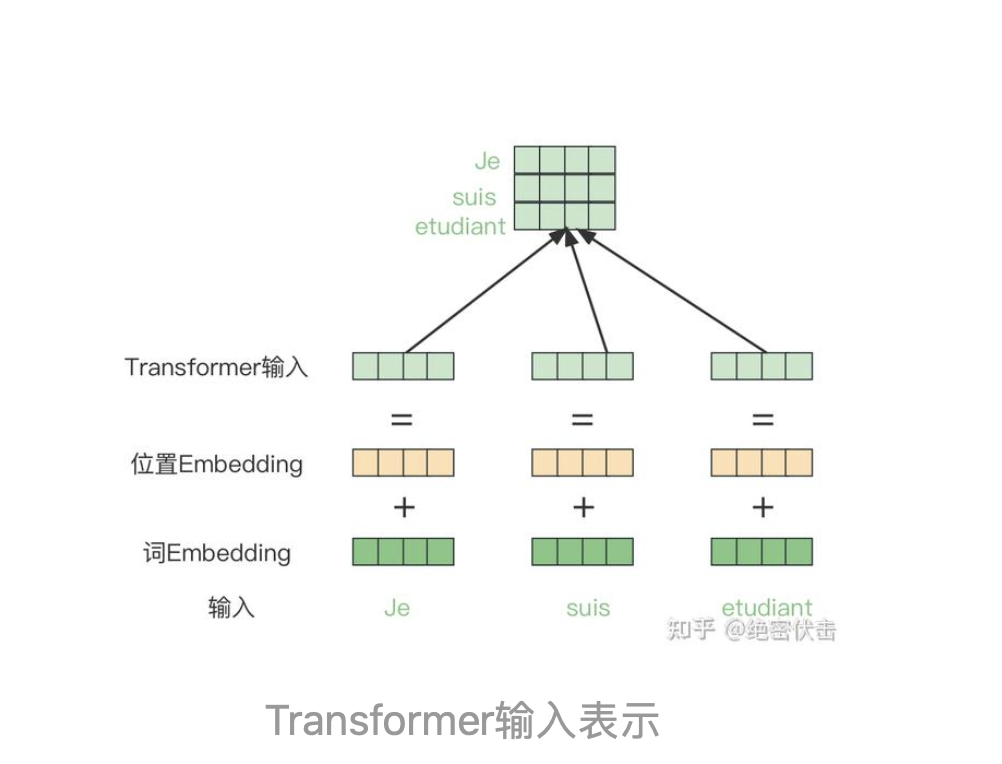
2.1、单词Embedding
单词的Embedding可以通过Word2vec等模型预训练得到,可以在Transformer中加入Embedding层。
2.2、位置Embedding
Transformer 中除了单词的Embedding,还需要使用位置Embedding 表示单词出现在句子中的位置。因为 Transformer不采用RNN结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。所以Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
3、Multi-Head Attention(多头注意力机制)
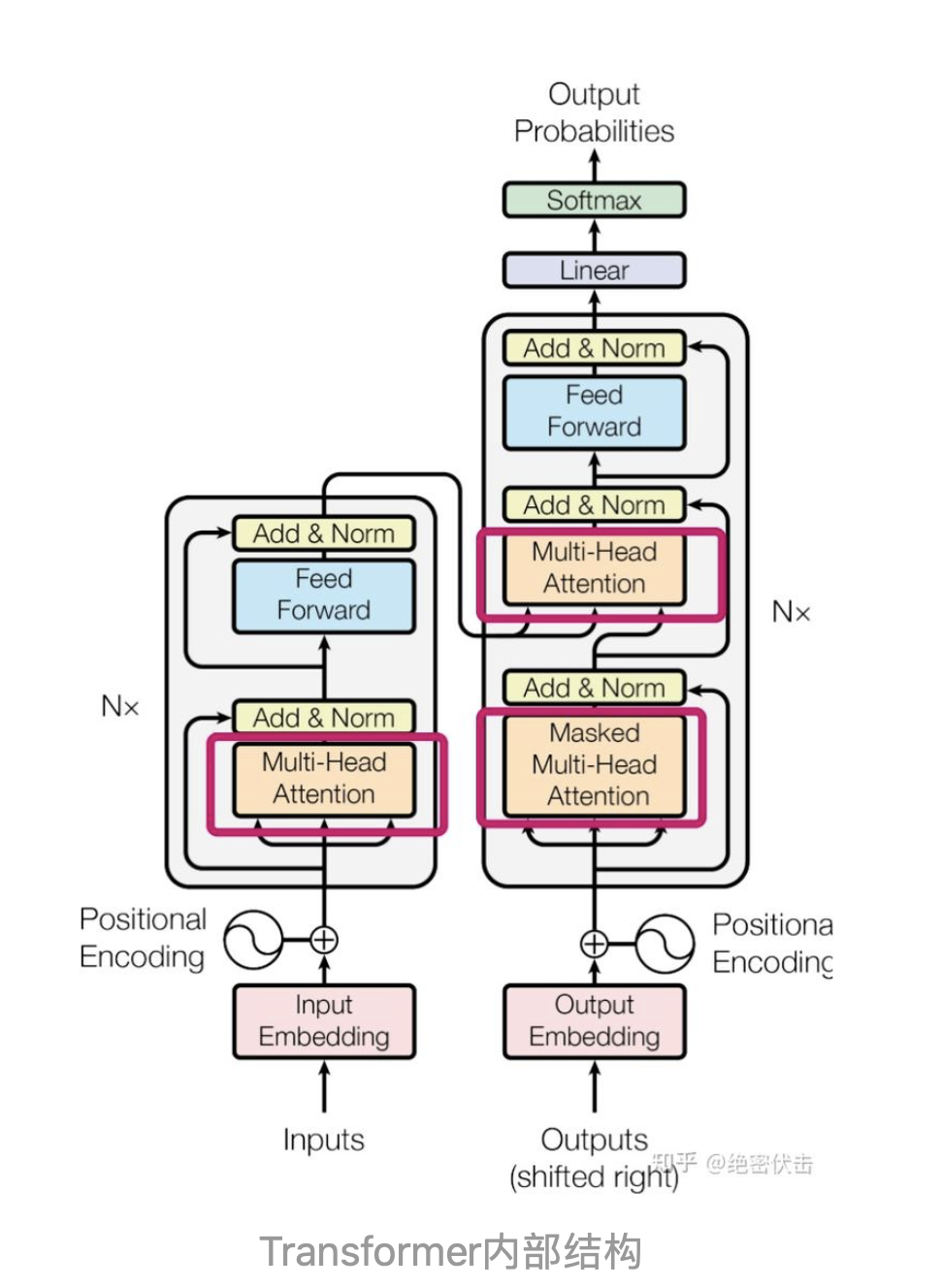
上图是Transformer的内部结构,其中红色方框内为Multi-Head Attention,是由多个Self-Attention组成,具体结构如下图:
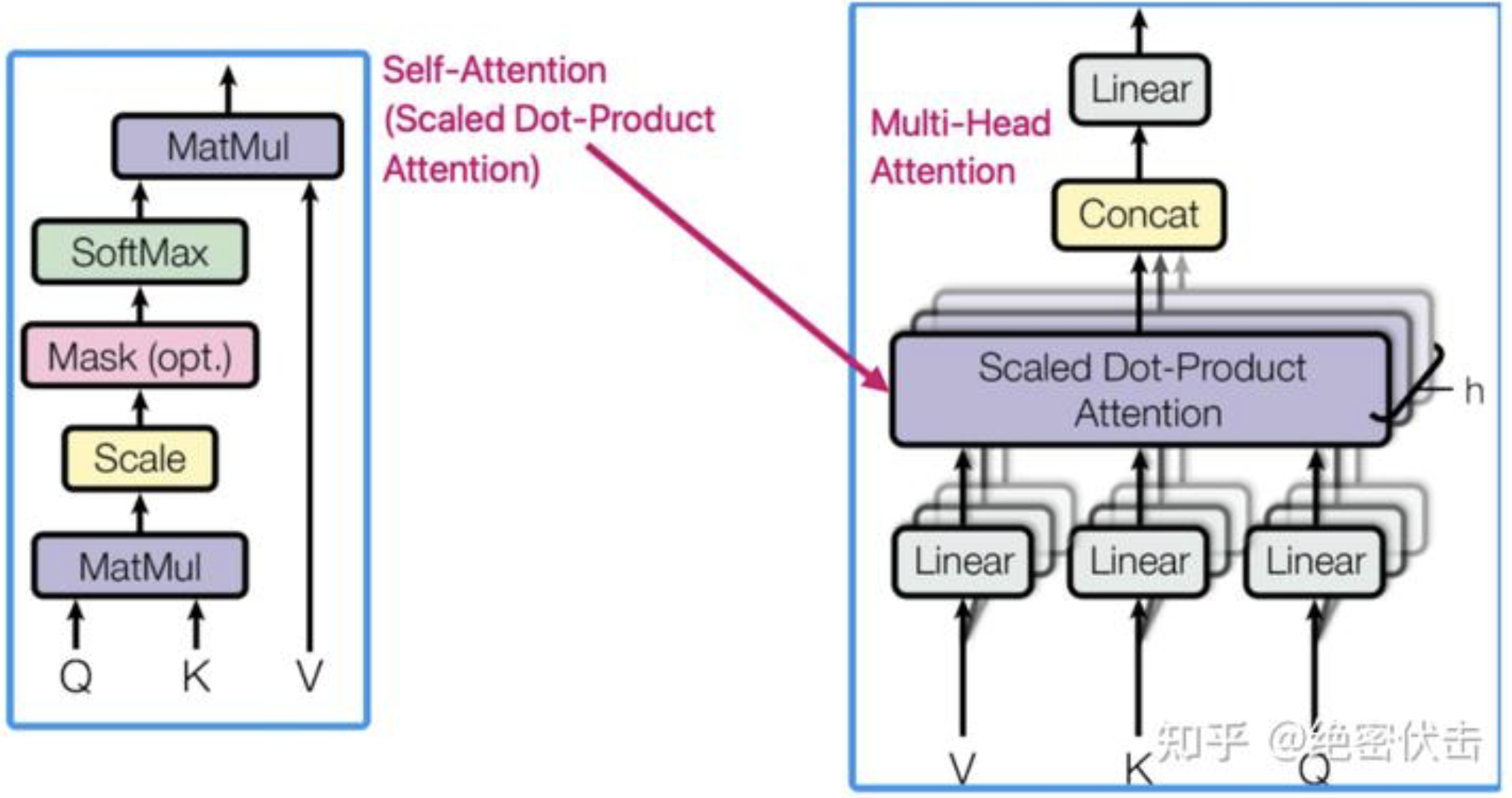
因为Self-Attention是Transformer的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention,首先介绍下Self-Attention的内部逻辑。
3.1 Self-Attention结构
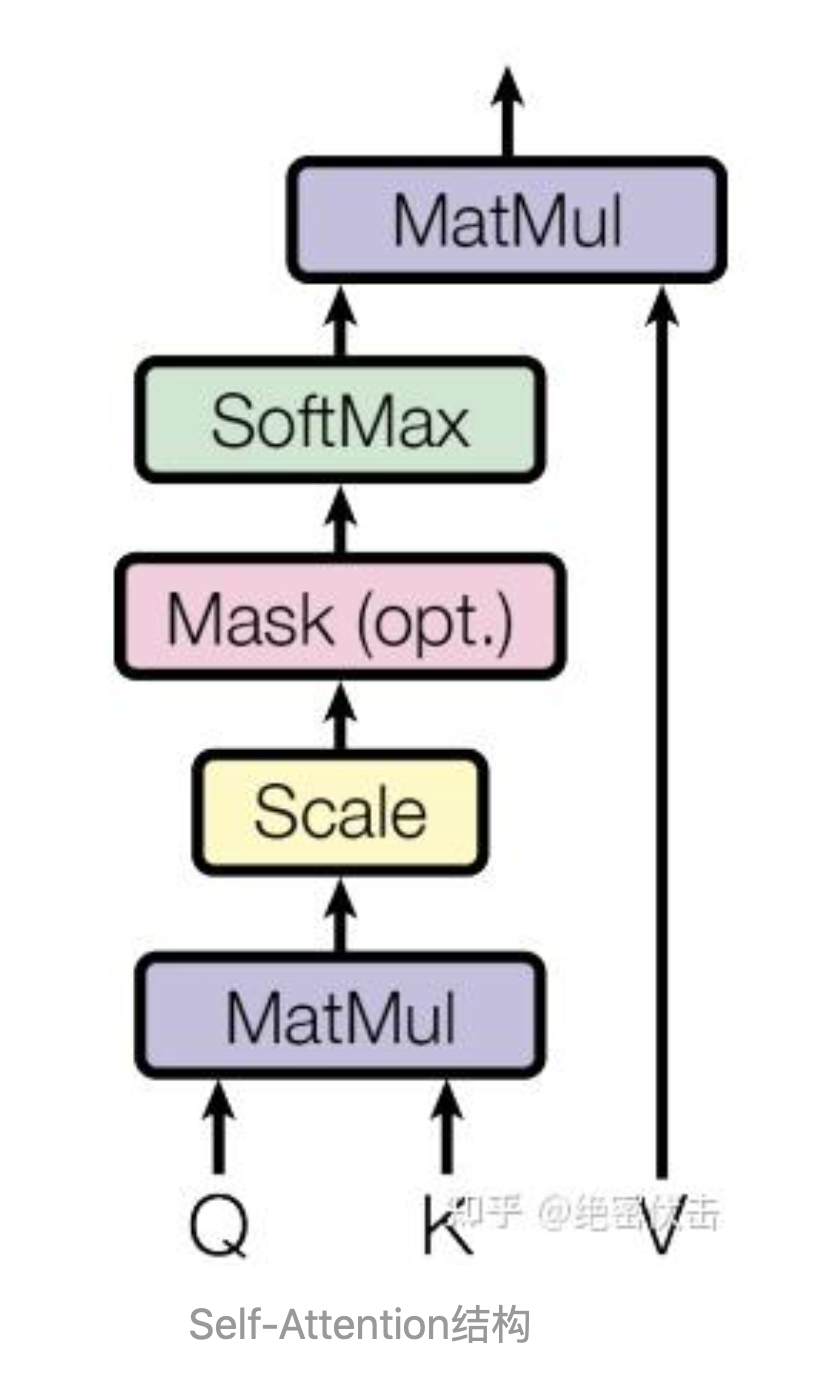
上图是Self-Attention结构,最下面是Q查询、K键值、V值矩阵,是通过输入矩阵X和权重矩阵Wk,Wq,Wv相乘得到的。
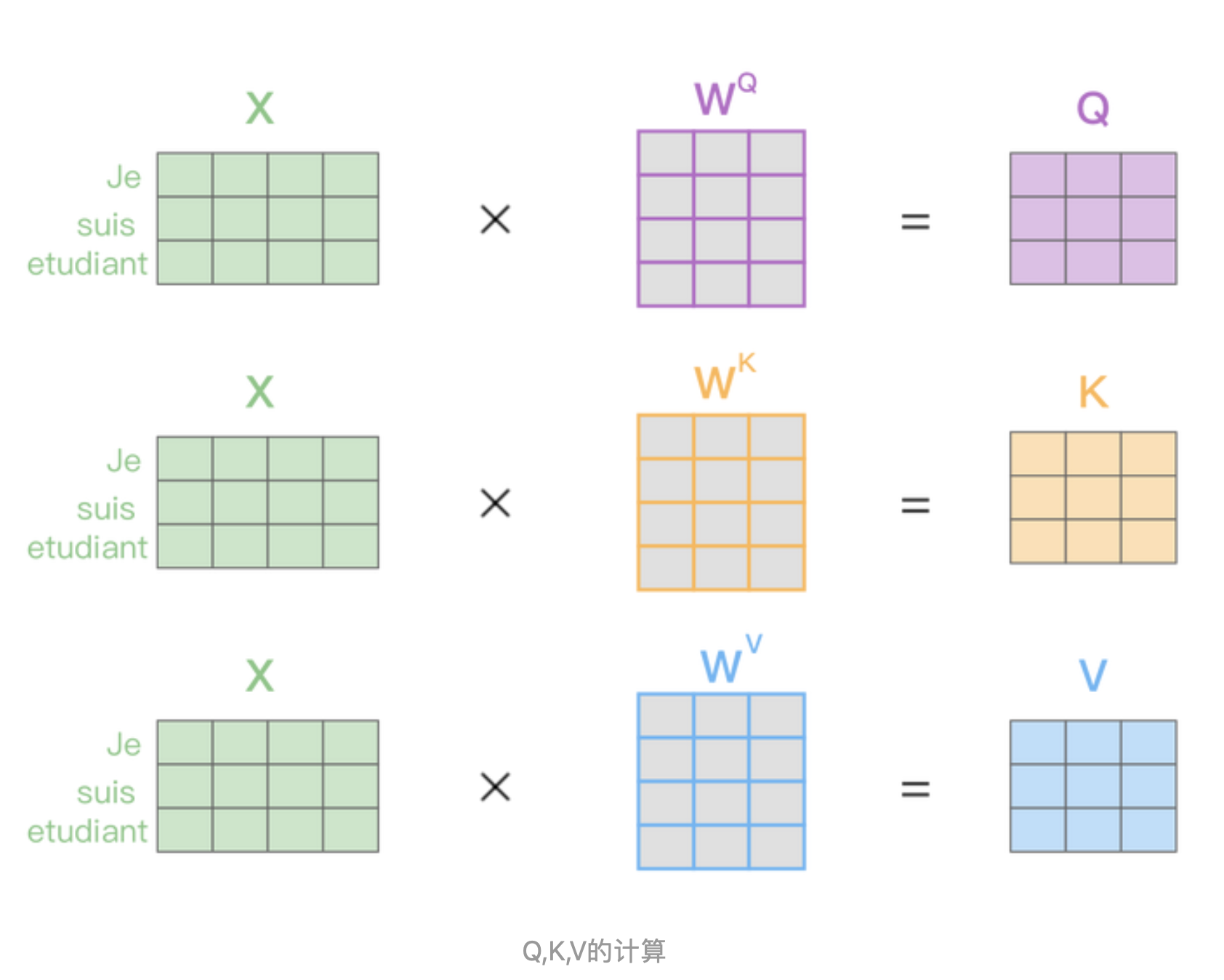
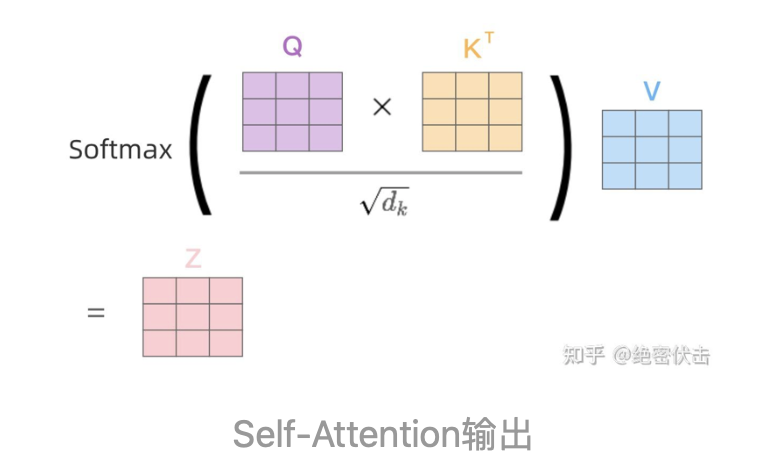
得到Q,K,V之后就可以计算出Self-Attention的输出,如下图所示:
3.2 Multi-Head Attention输出
在上一步,我们已经知道怎么通过Self-Attention计算得到输出矩阵Z,而Multi-Head Attention是由多个Self-Attention组合形成的,下图是论文中Multi-Head Attention的结构图。
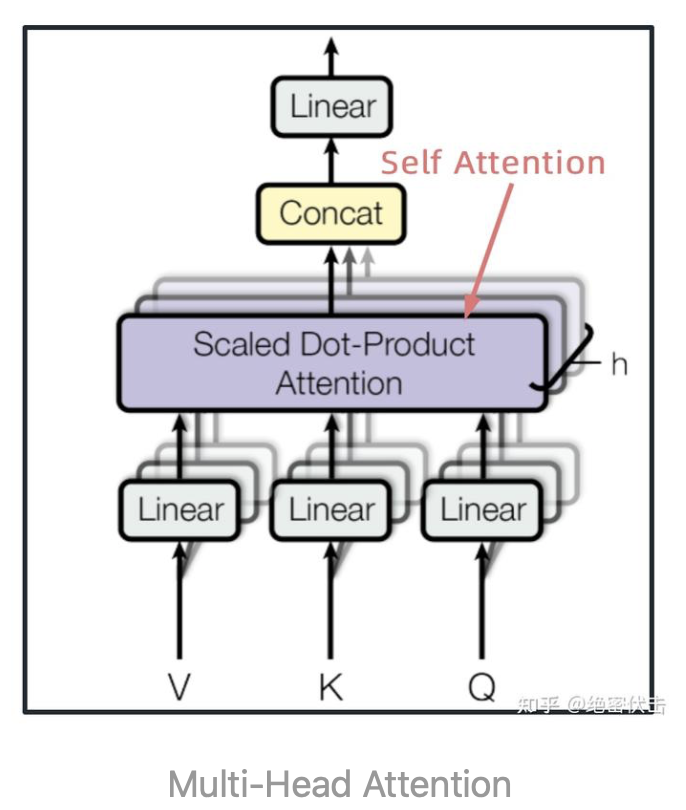
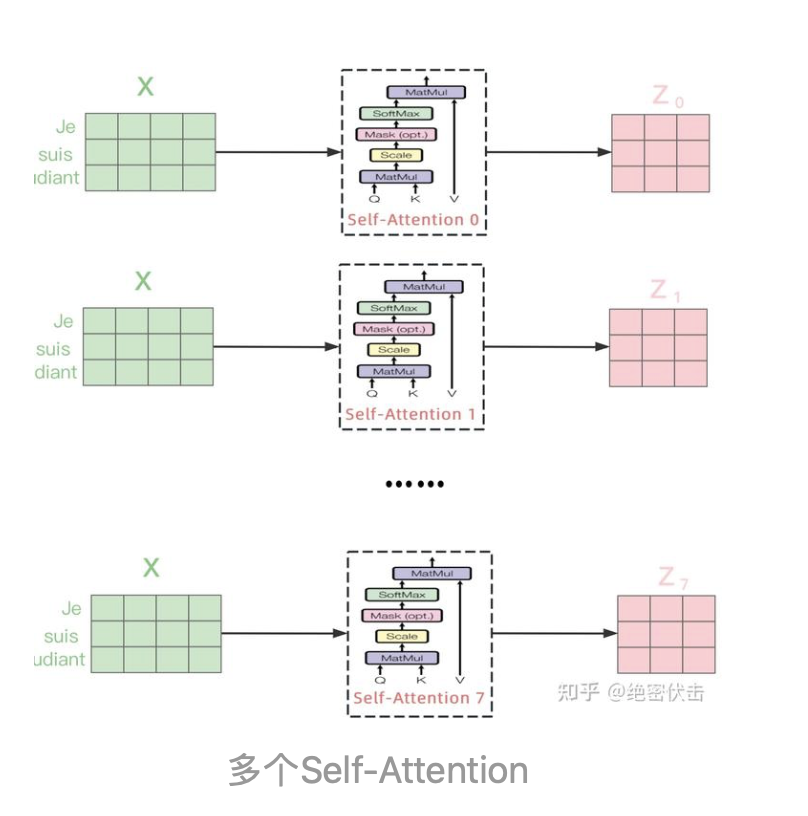
从上图可以看到Multi-Head Attention包含多个Self-Attention层,首先将输入X分别传递到 h个不同的Self-Attention中,计算得到  个输出矩阵 Z。下图是h=8的情况,此时会得到 8 个输出矩阵Z 。
个输出矩阵 Z。下图是h=8的情况,此时会得到 8 个输出矩阵Z 。
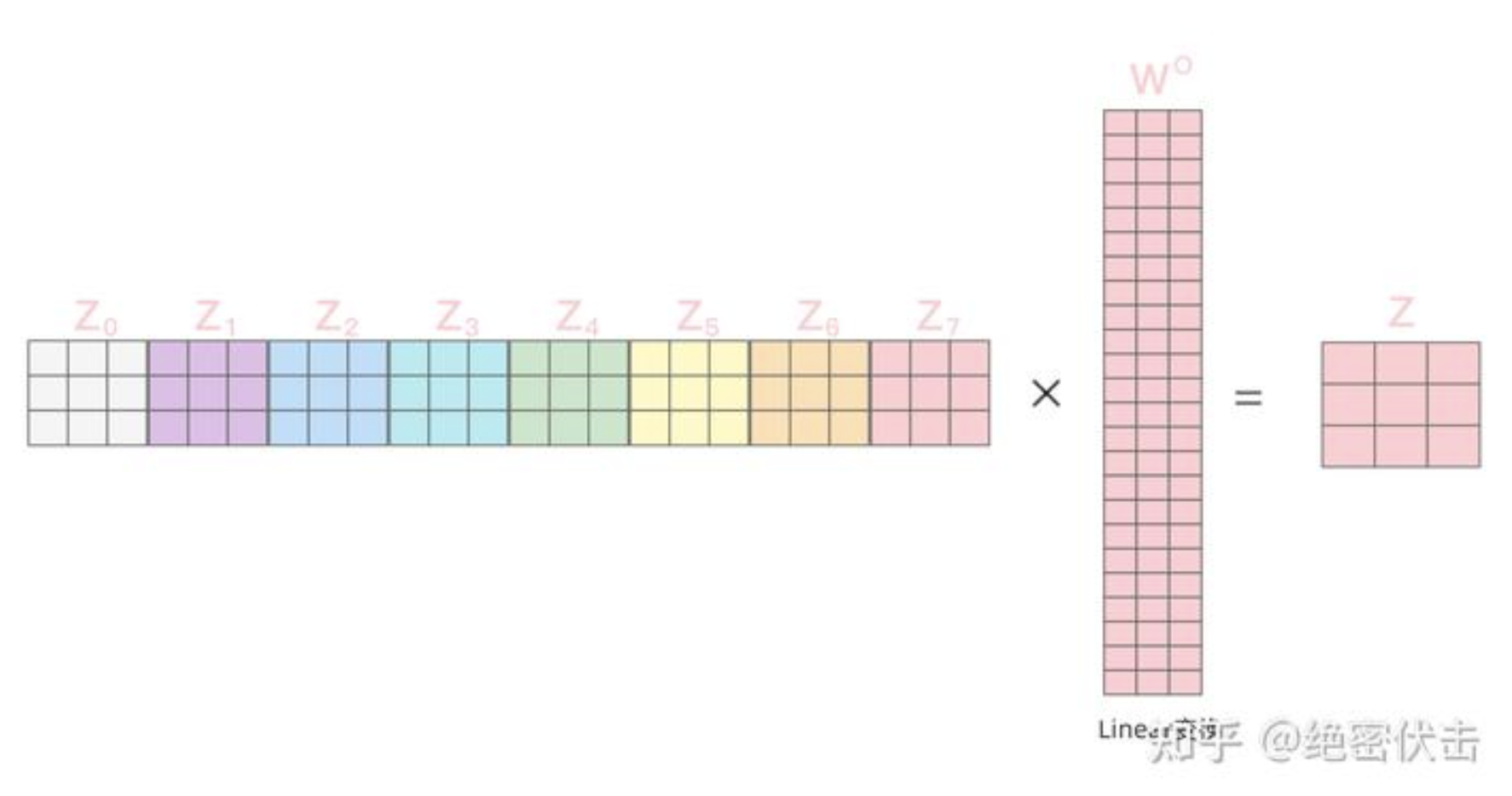
得到8个输出矩阵 \({Z}_0\sim {Z}_7\)后,Multi-Head Attention将它们拼接在一起(Concat),然后传入一个Linear层,得到Multi-Head Attention最终的输出矩阵Z 。
4、编码器Encoder结构
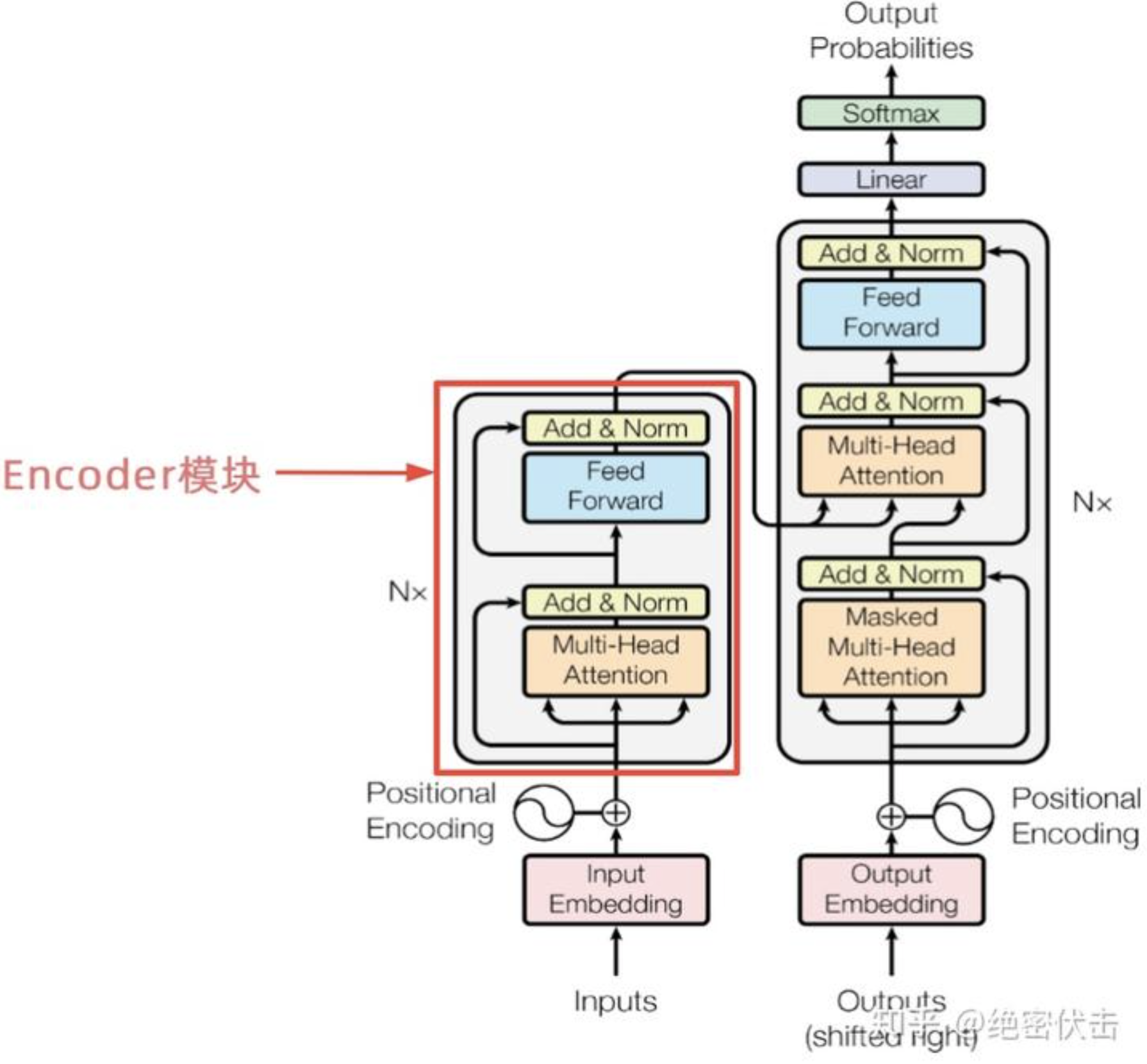
上图红色部分是Transformer的Encoder结构,N表示Encoder的个数,可以看到是由Multi-Head Attention、Add & Norm、Feed Forward、Add & Norm组成的。前面已经介绍了Multi-Head Attention的计算过程,现在了解一下Add & Norm和 Feed Forward部分。
4.1 单个Encoder输出
Add & Norm是指残差连接后使用LayerNorm,表示如下:
Sublayer表示经过的变换,比如第一个Add & Norm中Sublayer表示Multi-Head Attention。
Feed Forward**是指全连接层,表示如下:
因此输入矩阵X经过一个Encoder后,输出表示如下:
4.2 多个Encoder输出
通过上面的单个Encoder,输入矩阵 ${X}\in \mathbb{R}^{n\times d} $,最后输出矩阵 \({O}\in \mathbb{R}^{n\times d}\)。通过多个Encoder叠加,最后便是编码器Encoder的输出。
5、解码器Decoder结构
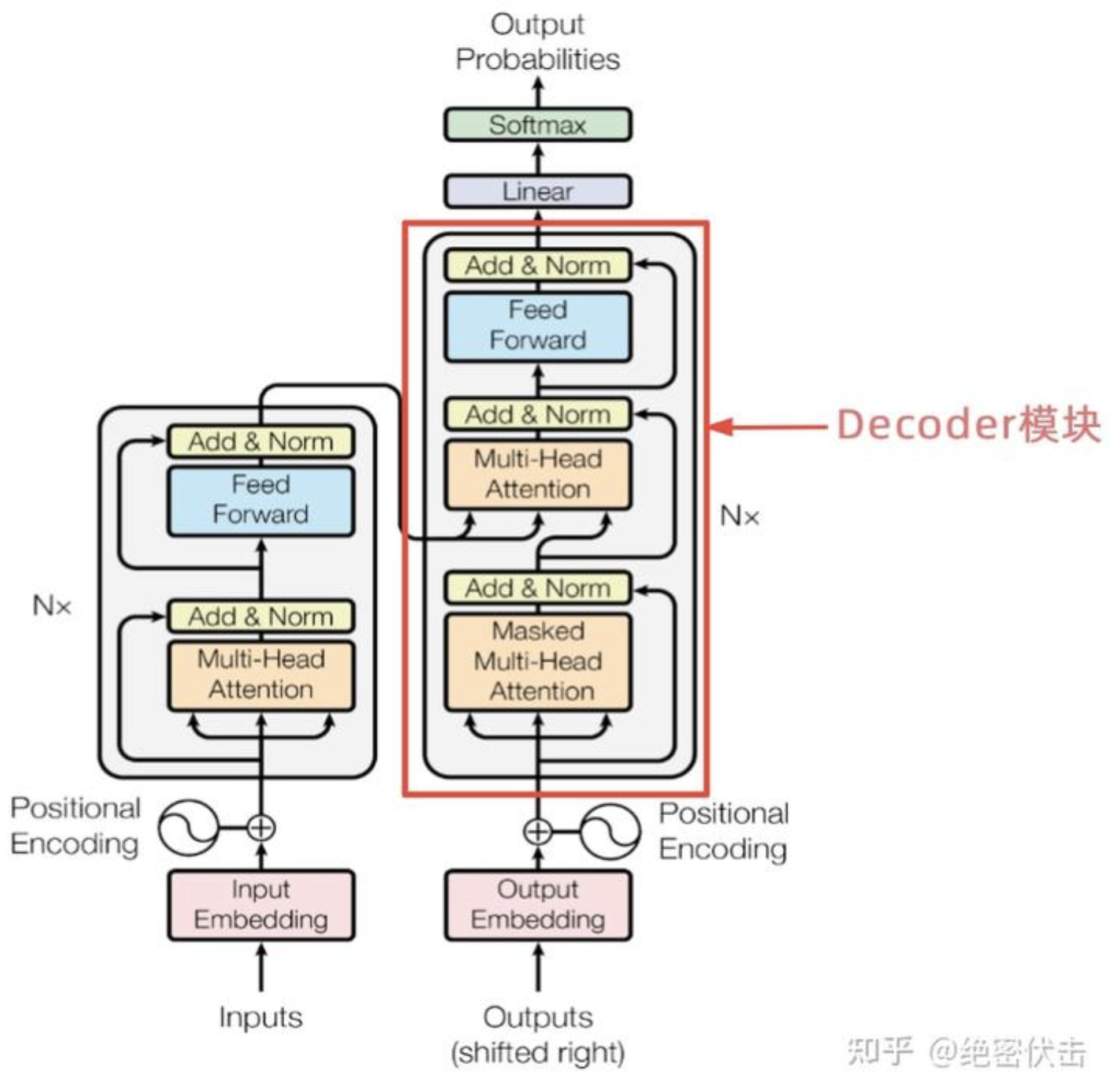
上图红色部分为Transformer的Decoder结构,与Encoder相似,但是存在一些区别:
- 包含两个Multi-Head Attention
- 第一个Multi-Head Attention采用了Masked操作
- 第二个Multi-Head Attention的 \({K},{V}\) 矩阵使用Encoder的**编码信息矩阵 \({C}\)进行计算,而 \({Q}\)使用上一个 Decoder的输出计算
- 最后有一个Softmax层计算下一个翻译单词的概率
5.1、第一个Multi-Head Attention
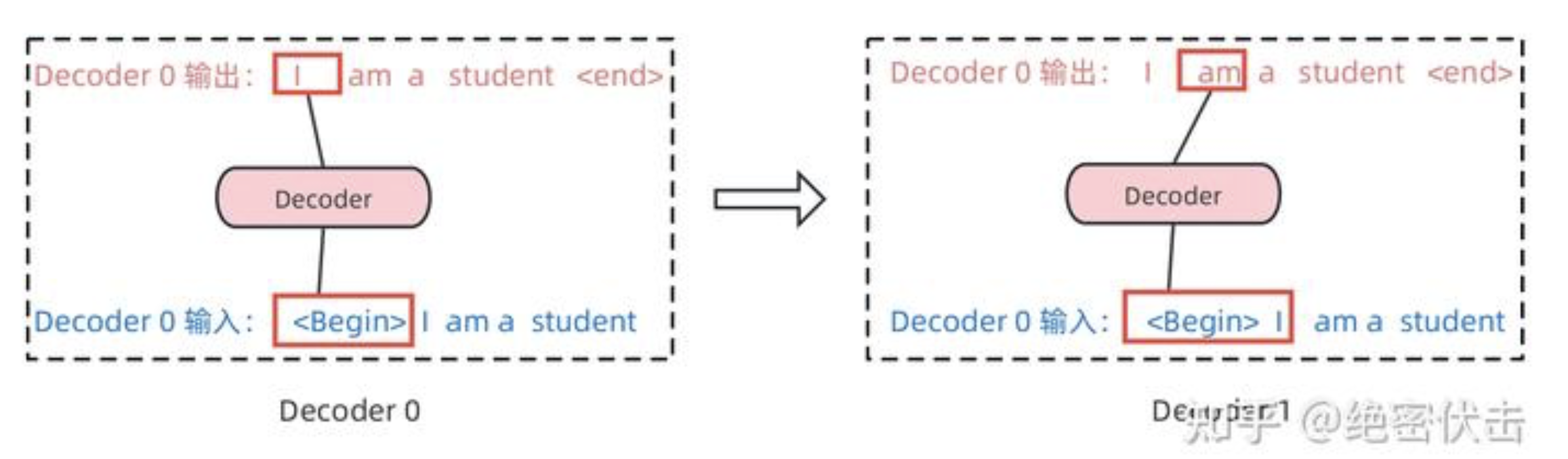
Decoder的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第 \(i\)个单词,才可以翻译第 \(i+1\)个单词。通过 Masked 操作可以防止第 \(i\)个单词知道 \(i+1\)个单词之后的信息。下面以法语"Je suis etudiant"翻译成英文"I am a student"为例,了解一下Masked 操作。
在Decoder的时候,需要根据之前翻译的单词,预测当前最有可能翻译的单词,如下图所示。首先根据输入"
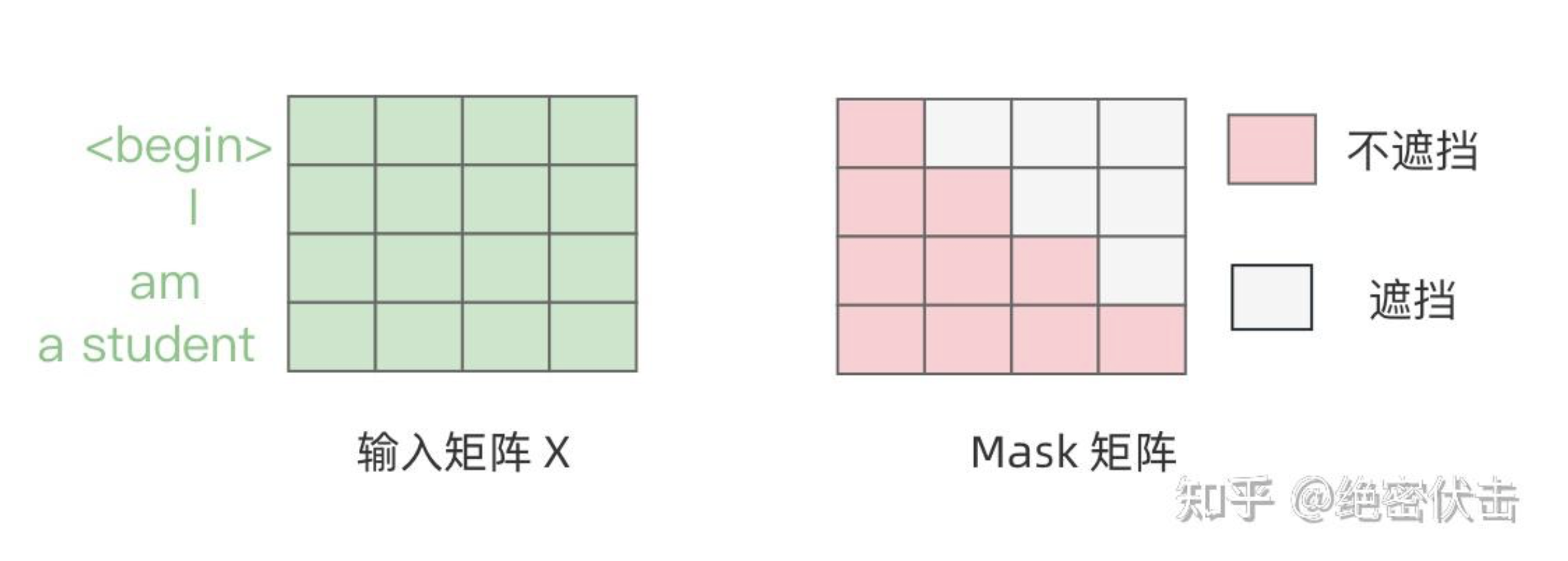
Decoder在预测第i个输出时,需要将第i+1之后的单词掩盖住,Mask操作是在Self-Attention的Softmax之前使用的,下面以前面的"I am a student"为例。
第一步:是Decoder的输入矩阵和Mask矩阵,输入矩阵包含"
第二步:接下来的操作和之前Encoder中的Self-Attention一样,只是在Softmax之前需要进行Mask操作。
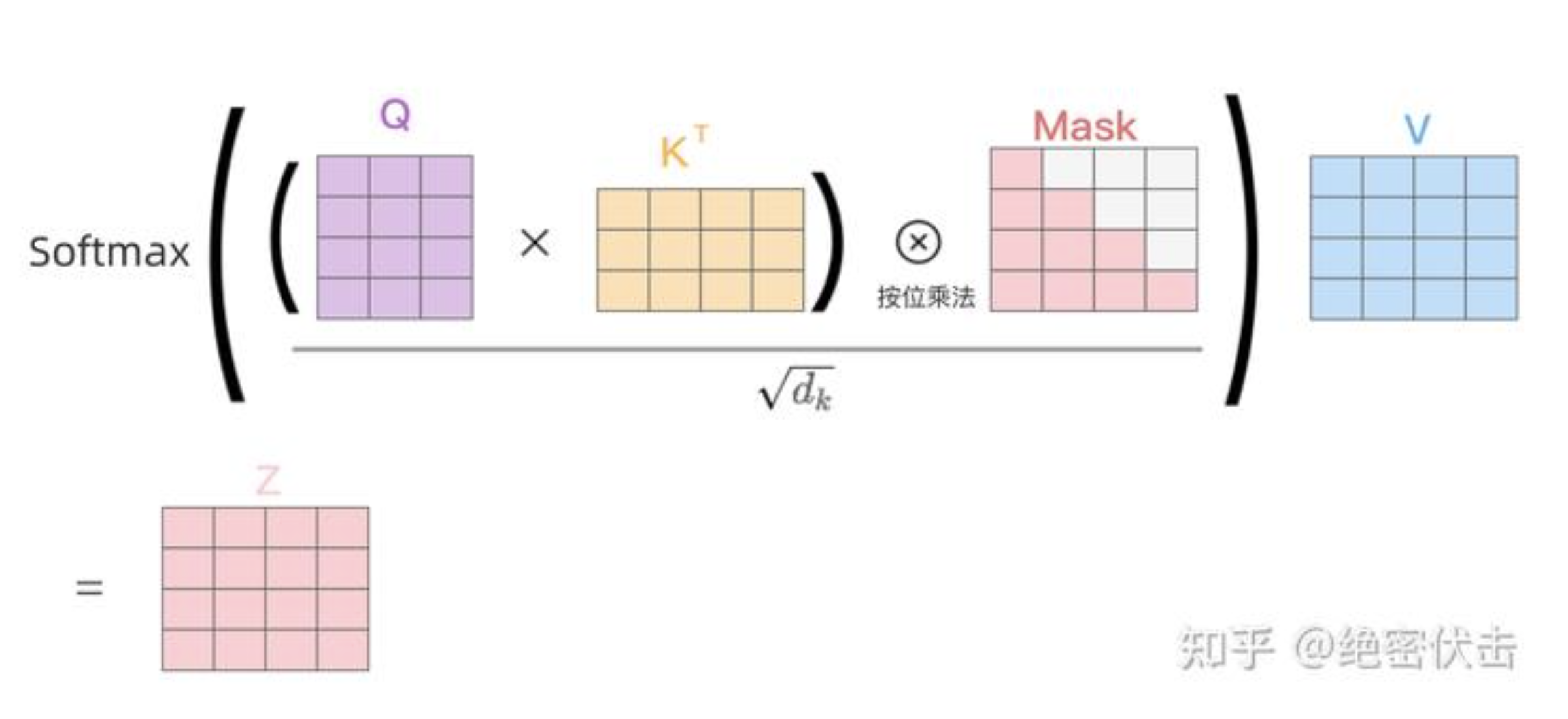
第三步:通过上述步骤就可以得到一个Mask Self-Attention的输出矩 \(Z_{i}\),然后和Encoder类似,通过Multi-Head Attention拼接多个输出 \(Z_{i}\)然后计算得到第一个Multi-Head Attention的输出 \({Z}\),与输入 $ X $ 维度一样。
5.2、第二个Muti-Head Attention
- Decoder的第二个Multi-Head Attention主要的区别在于其中Self-Attention的 \({K},{V}\) 矩阵不是使用上一个Multi-Head Attention的输出,而是使用Encoder的编码信息矩阵 \({C}\) 计算的。
- 根据Encoder的输出 \({C}\) 计算得到 \(K,V\),根据上一个Multi-Head Attention的输出$ {Z} $计算 $ Q $ 。这样做的好处是在Decoder的时候,每一位单词(这里是指"I am a student")都可以利用到Encoder所有单词的信息(这里是指"Je suis etudiant")。
6、Softmax预测输出
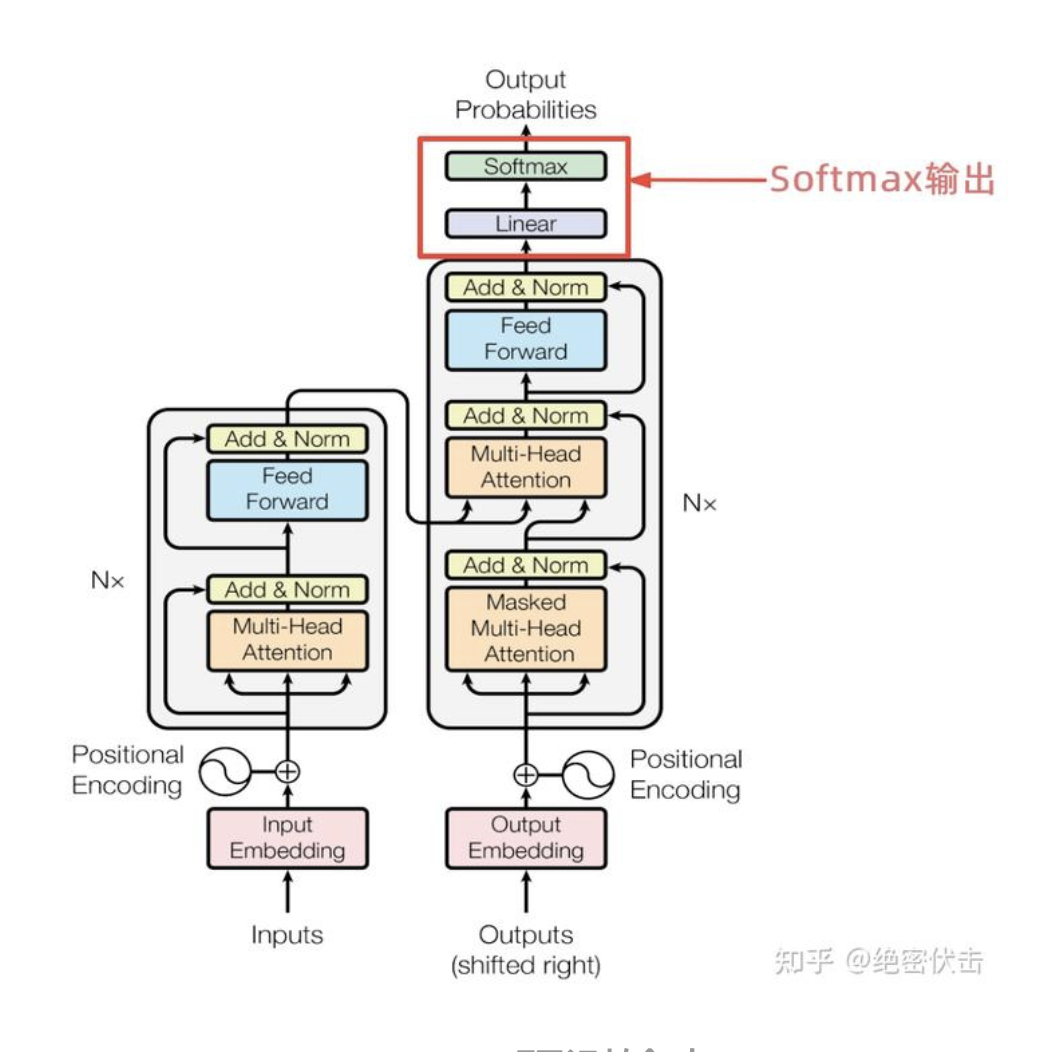
编码器Decoder最后的部分是利用 Softmax 预测下一个单词,在Softmax之前,会经过Linear变换,将维度转换为词表的个数。假设我们的词表只有6个单词,表示如下:
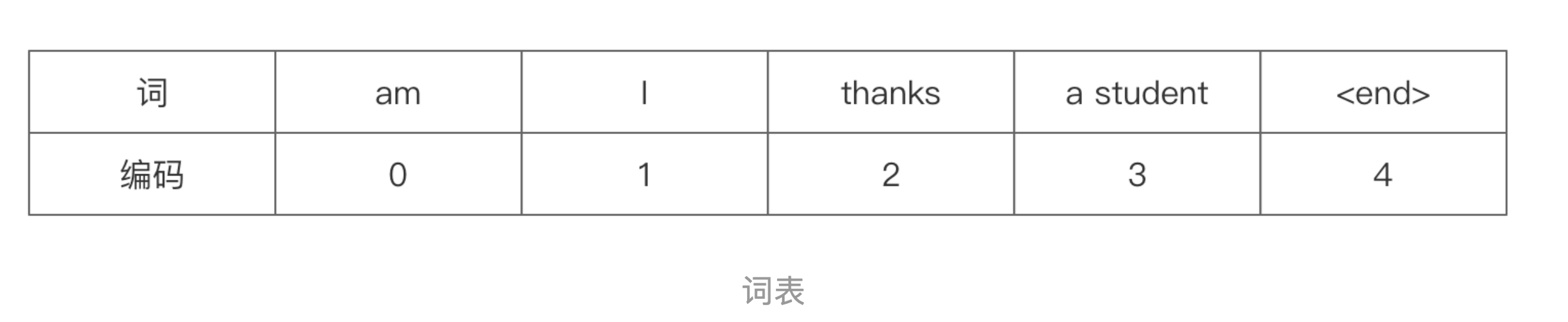
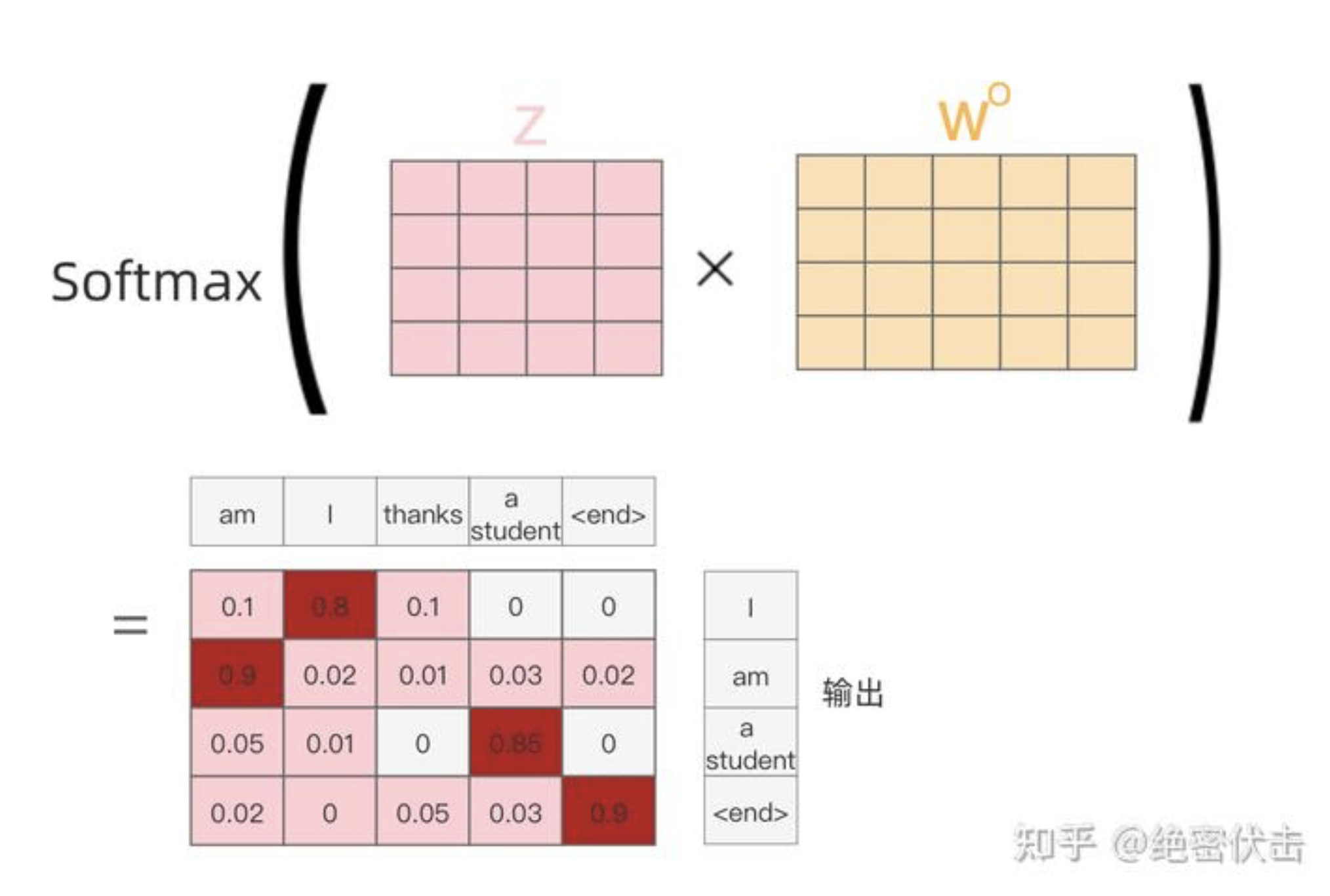
最后的输出为
7、总结
Transformer由于可并行、效果好等特点,如今已经成为机器翻译、特征抽取等任务的基础模块,目前ChatGPT特征抽取的模块用的就是Transformer,这对于后面理解ChatGPT的原理做了好的铺垫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号