DGL说明文档
DGL源码
https://docs.dgl.ai/en/0.5.x/_modules/index.html
一、DGL概述
Deep Graph Library(DGL)是一个Python软件包,用于在现有DL框架(例如PyTorch,MXNet,Gluon等)之上实现图神经网络模型。
DGL将图神经网络的实现简化为声明一组函数。
此外,DGL还提供:
- 消息传递的多功能控件,从低级别的操作(如沿选定边缘发送和在特定节点上接收)到高层的控件(如图形范围的功能更新。
- 具有自动批处理计算和稀疏矩阵乘法的透明速度优化。
- 与现有深度学习框架的无缝集成。
- 简单易用的界面,用于节点/边缘特征访问和图形结构操作。
- 对具有数千万个顶点的图具有良好的可伸缩性。
二、安装
DGL可与以下操作系统配合使用:
-
Ubuntu 16.04
-
mac OS X
-
Windows 10
DGL需要Python 3.6或更高版本。
DGL支持作为后端,例如PyTorch,MXNet。 有关后端的要求以及如何选择后端的信息,请参阅使用不同的后端。
2.1、源码下载
Download the source files from GitHub.
git clone --recurse-submodules https://github.com/dmlc/dgl.git
(Optional) Clone the repository first, and then run the following:
git submodule update --init --recursive
2.2、mac安装
Installation on macOS is similar to Linux. But macOS users need to install build tools like clang, GNU Make, and cmake first. These installation steps were tested on macOS X with clang 10.0.0, GNU Make 3.81, and cmake 3.13.1.
Tools like clang and GNU Make are packaged in Command Line Tools for macOS. To install, run the following:
xcode-select --install
After you install Homebrew, install cmake.
brew install cmake
Go to root directory of the DGL repository, build a shared library, and install the Python binding for DGL.
mkdir build
cd build
cmake -DUSE_OPENMP=off ..
make -j4
cd ../python
python setup.py install
三、图
图表示实体(节点)和它们的关系(边),其中节点和边可以是有类型的 (例如,"用户" 和 "物品" 是两种不同类型的节点)。
DGL通过其核心数据结构 DGLGraph 提供了一个以图为中心的编程抽象。
DGLGraph 提供了接口以处理图的结构、节点/边 的特征,以及使用这些组件可以执行的计算。
3.1、关于图的基本概念
-
图是用以表示实体及其关系的结构,记为 𝐺=(𝑉,𝐸)。
-
图由两个集合组成,一是节点的集合 𝑉 ,一个是边的集合 𝐸 。 在边集 𝐸中,一条边 (𝑢,𝑣)连接一对节点 𝑢和𝑣,表明两节点间存在关系。
-
关系可以是无向的, 如描述节点之间的对称关系;也可以是有向的,如描述非对称关系。例如,若用图对社交网络中人们的友谊关系进行建模,因为友谊是相互的,则边是无向的; 若用图对Twitter用户的关注行为进行建模,则边是有向的。图可以是 有向的 或 无向的 ,这取决于图中边的方向性。
-
图可以是 加权的 或 未加权的 。在加权图中,每条边都与一个标量权重值相关联。例如,该权重可以表示长度或连接的强度。
-
图可以是 同构的 或是 异构的 。在同构图中,所有节点表示同一类型的实体,所有边表示同一类型的关系。例如,社交网络的图由表示同一实体类型的人及其相互之间的社交关系组成。相对地,在异构图中,节点和边的类型可以是不同的。例如,编码市场的图可以有表示”顾客”、”商家”和”商品”的节点, 它们通过“想购买”、“已经购买”、“是顾客”和“正在销售”的边互相连接。
-
二分图是一类特殊的、常用的异构图, 其中的边连接两类不同类型的节点。例如,在推荐系统中,可以使用二分图表示”用户”和”物品”之间的关系。
-
在多重图中,同一对节点之间可以有多条(有向)边,包括自循环的边。例如,两名作者可以在不同年份共同署名文章, 这就带来了具有不同特征的多条边。
3.2、图、节点和边
-
DGL使用一个唯一的整数来表示一个节点,称为点ID;并用对应的两个端点ID表示一条边。
-
同时,DGL也会根据边被添加的顺序, 给每条边分配一个唯一的整数编号,称为边ID。节点和边的ID都是从0开始构建的。
-
在DGL的图里,所有的边都是有方向的, 即边 (𝑢,𝑣)表示它是从节点 𝑢 指向节点 𝑣 的。对于多个节点,DGL使用一个一维的整型张量(如,PyTorch的Tensor类,TensorFlow的Tensor类或MXNet的ndarray类)来保存图的点ID, DGL称之为”节点张量”。
-
为了指代多条边,DGL使用一个包含2个节点张量的元组 (𝑈,𝑉),其中,用 (𝑈[𝑖],𝑉[𝑖]) 指代一条 𝑈[𝑖] 到 𝑉[𝑖] 的边。创建一个
DGLGraph对象的一种方法是使用dgl.graph()函数。它接受一个边的集合作为输入。 -
DGL也支持从其他的数据源来创建图对象。
-
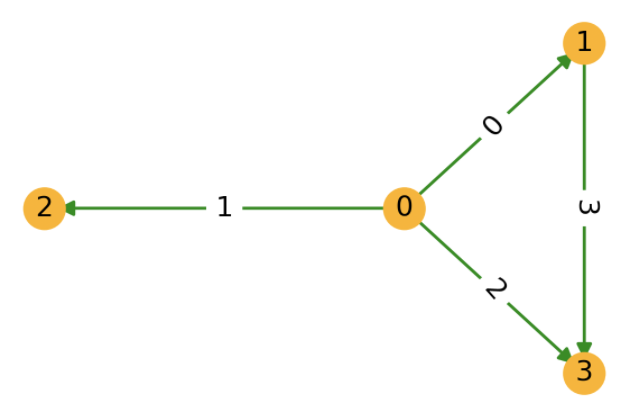
下面的代码段使用了
dgl.graph()函数来构建一个DGLGraph对象,对应着下图所示的包含4个节点的图。 其中一些代码演示了查询图结构的部分API的使用方法。
>>> import dgl
>>> import torch as th
>>> # 边 0->1, 0->2, 0->3, 1->3
>>> u, v = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
>>> g = dgl.graph((u, v))
>>> print(g) # 图中节点的数量是DGL通过给定的图的边列表中最大的点ID推断所得出的
Graph(num_nodes=4, num_edges=4,
ndata_schemes={}
edata_schemes={})
>>> # 获取节点的ID
>>> print(g.nodes())
tensor([0, 1, 2, 3])
>>> # 获取边的对应端点
>>> print(g.edges())
(tensor([0, 0, 0, 1]), tensor([1, 2, 3, 3]))
>>> # 获取边的对应端点和边ID
>>> print(g.edges(form='all'))
(tensor([0, 0, 0, 1]), tensor([1, 2, 3, 3]), tensor([0, 1, 2, 3]))
>>> # 如果具有最大ID的节点没有边,在创建图的时候,用户需要明确地指明节点的数量。
>>> g = dgl.graph((u, v), num_nodes=8)
对于无向的图,用户需要为每条边都创建两个方向的边。
可以使用 dgl.to_bidirected() 函数来实现这个目的。 如下面的代码段所示,这个函数可以把原图转换成一个包含反向边的图。
>>> bg = dgl.to_bidirected(g)
>>> bg.edges()
(tensor([0, 0, 0, 1, 1, 2, 3, 3]), tensor([1, 2, 3, 0, 3, 0, 0, 1]))
DGL支持使用 32 位或 64 位的整数作为节点ID和边ID。节点和边ID的数据类型必须一致。如果使用 64 位整数, DGL可以处理最多 \(2^{63}−1\)个节点或边。不过,如果图里的节点或者边的数量小于$ 2^{63}−1$,用户最好使用 32 位整数。 这样不仅能提升速度,还能减少内存的使用。
DGL提供了进行数据类型转换的方法,如下例所示。
>>> edges = th.tensor([2, 5, 3]), th.tensor([3, 5, 0]) # 边:2->3, 5->5, 3->0
>>> g64 = dgl.graph(edges) # DGL默认使用int64
>>> print(g64.idtype)
torch.int64
>>> g32 = dgl.graph(edges, idtype=th.int32) # 使用int32构建图
>>> g32.idtype
torch.int32
>>> g64_2 = g32.long() # 转换成int64
>>> g64_2.idtype
torch.int64
>>> g32_2 = g64.int() # 转换成int32
>>> g32_2.idtype
torch.int32
3.3、节点和边的特征
DGLGraph 对象的节点和边可具有多个用户定义的、可命名的特征,以储存图的节点和边的属性。
以下代码创建了2个节点特征(分别在第8、15行命名为 'x' 、 'y' )和1个边特征(在第9行命名为 'x' )。
>>> import dgl
>>> import torch as th
>>> g = dgl.graph(([0, 0, 1, 5], [1, 2, 2, 0])) # 6个节点,4条边
>>> g
Graph(num_nodes=6, num_edges=4,
ndata_schemes={}
edata_schemes={})
>>> g.ndata['x'] = th.ones(g.num_nodes(), 3) # 长度为3的节点特征
>>> g.edata['x'] = th.ones(g.num_edges(), dtype=th.int32) # 标量整型特征
>>> g
Graph(num_nodes=6, num_edges=4,
ndata_schemes={'x' : Scheme(shape=(3,), dtype=torch.float32)}
edata_schemes={'x' : Scheme(shape=(,), dtype=torch.int32)})
>>> # 不同名称的特征可以具有不同形状
>>> g.ndata['y'] = th.randn(g.num_nodes(), 5)
>>> g.ndata['x'][1] # 获取节点1的特征
tensor([1., 1., 1.])
>>> g.edata['x'][th.tensor([0, 3])] # 获取边0和3的特征
tensor([1, 1], dtype=torch.int32)
- 仅允许使用数值类型(如单精度浮点型、双精度浮点型和整型)的特征。这些特征可以是标量、向量或多维张量。
- 每个节点特征具有唯一名称,每个边特征也具有唯一名称。节点和边的特征可以具有相同的名称(如上述示例代码中的
'x')。 - 通过张量分配创建特征时,DGL会将特征赋给图中的每个节点和每条边。该张量的第一维必须与图中节点或边的数量一致。 不能将特征赋给图中节点或边的子集。
- 相同名称的特征必须具有相同的维度和数据类型。
- 特征张量使用”行优先”的原则,即每个行切片储存1个节点或1条边的特征(参考上述示例代码的第16和18行)。
对于加权图,用户可以将权重储存为一个边特征,如下。
>>> # 边 0->1, 0->2, 0->3, 1->3
>>> edges = th.tensor([0, 0, 0, 1]), th.tensor([1, 2, 3, 3])
>>> weights = th.tensor([0.1, 0.6, 0.9, 0.7]) # 每条边的权重
>>> g = dgl.graph(edges)
>>> g.edata['w'] = weights # 将其命名为 'w'
>>> g
Graph(num_nodes=4, num_edges=4,
ndata_schemes={}
edata_schemes={'w' : Scheme(shape=(,), dtype=torch.float32)})
3.4、从外部源创建图
1、从SciPy稀疏矩阵和NetworkX图创建DGL图
>>> import dgl
>>> import torch as th
>>> import scipy.sparse as sp
>>> spmat = sp.rand(100, 100, density=0.05) # 5%非零项
>>> dgl.from_scipy(spmat) # 来自SciPy
Graph(num_nodes=100, num_edges=500,
ndata_schemes={}
edata_schemes={})
>>> import networkx as nx
>>> nx_g = nx.path_graph(5) # 一条链路0-1-2-3-4
>>> g=dgl.from_networkx(nx_g) # 来自NetworkX
>>> bg = dgl.to_bidirected(g)
>>> bg.edges()
(tensor([0, 1, 1, 2, 2, 3, 3, 4]), tensor([1, 0, 2, 1, 3, 2, 4, 3]))
2、从磁盘加载图
有多种文件格式可储存图,所以这里难以枚举所有选项。本节仅给出一些常见格式的一般情况。
CSV是一种常见的格式,以表格格式储存节点、边及其特征:
参考: 从成对的边 CSV 文件中加载 Karate Club Network 的教程
!ls -lh 'data'
total 24
-rw-r--r--@ 1 wzx staff 3.7K 11 1 22:50 edges.csv
-rw-r--r--@ 1 wzx staff 1.2K 11 1 22:50 gen_data.py
-rw-r--r--@ 1 wzx staff 461B 11 1 22:50 nodes.csv
import pandas as pd
nodes_data = pd.read_csv('data/nodes.csv')
print(nodes_data)
edges_data = pd.read_csv('data/edges.csv')
print(edges_data)
import dgl
src = edges_data['Src'].to_numpy()
dst = edges_data['Dst'].to_numpy()
# Create a DGL graph from a pair of numpy arrays
g = dgl.graph((src, dst))
# Print a graph gives some meta information such as number of nodes and edges.
print(g)
Graph(num_nodes=34, num_edges=156,
ndata_schemes={}
edata_schemes={})
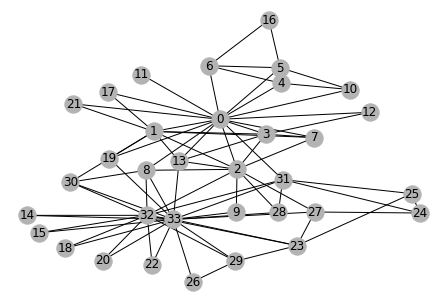
A DGL graph can be converted to a networkx graph, so to utilize its rich functionalities such as visualization.
import networkx as nx
# Since the actual graph is undirected, we convert it for visualization
# purpose.
nx_g = g.to_networkx().to_undirected()
# Kamada-Kawaii layout usually looks pretty for arbitrary graphs
pos = nx.kamada_kawai_layout(nx_g)
nx.draw(nx_g, pos, with_labels=True, node_color=[[.7, .7, .7]])
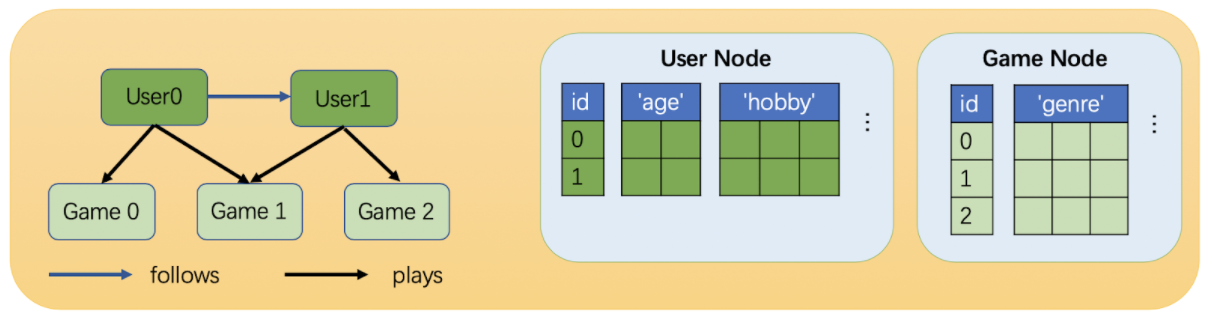
3.5、异构图
相比同构图,异构图里可以有不同类型的节点和边。这些不同类型的节点和边具有独立的ID空间和特征。
例如在下图中,”用户”和”游戏”节点的ID都是从0开始的,而且两种节点具有不同的特征。
1、创建异构图
在DGL中,一个异构图由一系列子图构成,一个子图对应一种关系。每个关系由一个字符串三元组 定义 (源节点类型, 边类型, 目标节点类型) 。由于这里的关系定义消除了边类型的歧义,DGL称它们为规范边类型。
下面的代码是一个在DGL中创建异构图的示例。
>>> import dgl
>>> import torch as th
>>> # 创建一个具有3种节点类型和3种边类型的异构图
>>> graph_data = {
... ('drug', 'interacts', 'drug'): (th.tensor([0, 1]), th.tensor([1, 2])),
... ('drug', 'interacts', 'gene'): (th.tensor([0, 1]), th.tensor([2, 3])),
... ('drug', 'treats', 'disease'): (th.tensor([1]), th.tensor([2]))
... }
>>> g = dgl.heterograph(graph_data)
>>> g.ntypes
['disease', 'drug', 'gene']
>>> g.etypes
['interacts', 'interacts', 'treats']
>>> g.canonical_etypes
[('drug', 'interacts', 'drug'),
('drug', 'interacts', 'gene'),
('drug', 'treats', 'disease')]
>>> g
Graph(num_nodes={'disease': 3, 'drug': 3, 'gene': 4},
num_edges={('drug', 'interacts', 'drug'): 2, ('drug', 'interacts', 'gene'): 2, ('drug', 'treats', 'disease'): 1},
metagraph=[('drug', 'drug', 'interacts'), ('drug', 'gene', 'interacts'), ('drug', 'disease', 'treats')])
注意,同构图和二分图只是一种特殊的异构图,它们只包括一种关系。
>>> # 一个同构图
>>> dgl.heterograph({('node_type', 'edge_type', 'node_type'): (u, v)})
>>> # 一个二分图
>>> dgl.heterograph({('source_type', 'edge_type', 'destination_type'): (u, v)})
3.6、在GPU上使用DGLGraph
>>> import dgl
>>> import torch as th
>>> u, v = th.tensor([0, 1, 2]), th.tensor([2, 3, 4])
>>> g = dgl.graph((u, v))
>>> g.ndata['x'] = th.randn(5, 3) # 原始特征在CPU上
>>> g.device
device(type='cpu')
>>> cuda_g = g.to('cuda:0') # 接受来自后端框架的任何设备对象
>>> cuda_g.device
device(type='cuda', index=0)
>>> cuda_g.ndata['x'].device # 特征数据也拷贝到了GPU上
device(type='cuda', index=0)
>>> # 由GPU张量构造的图也在GPU上
>>> u, v = u.to('cuda:0'), v.to('cuda:0')
>>> g = dgl.graph((u, v))
>>> g.device
device(type='cuda', index=0)
任何涉及GPU图的操作都是在GPU上运行的。
因此,这要求所有张量参数都已经放在GPU上,其结果(图或张量)也将在GPU上。
此外,GPU图只接受GPU上的特征数据。
>>> cuda_g.in_degrees()
tensor([0, 0, 1, 1, 1], device='cuda:0')
>>> cuda_g.in_edges([2, 3, 4]) # 可以接受非张量类型的参数
(tensor([0, 1, 2], device='cuda:0'), tensor([2, 3, 4], device='cuda:0'))
>>> cuda_g.in_edges(th.tensor([2, 3, 4]).to('cuda:0')) # 张量类型的参数必须在GPU上
(tensor([0, 1, 2], device='cuda:0'), tensor([2, 3, 4], device='cuda:0'))
>>> cuda_g.ndata['h'] = th.randn(5, 4) # ERROR! 特征也必须在GPU上!
DGLError: Cannot assign node feature "h" on device cpu to a graph on device
cuda:0. Call DGLGraph.to() to copy the graph to the same device.
四、消息传递范式
消息传递是实现GNN的一种通用框架和编程范式。它从聚合与更新的角度归纳总结了多种GNN模型的实现。
假设节点 𝑣 上的的特征为 \(𝑥_𝑣∈R^{𝑑_1}\),边 (𝑢,𝑣) 上的特征为 \(𝑤_𝑒∈R^{𝑑_2}\)。 消息传递范式定义了以下逐节点和边上的计算
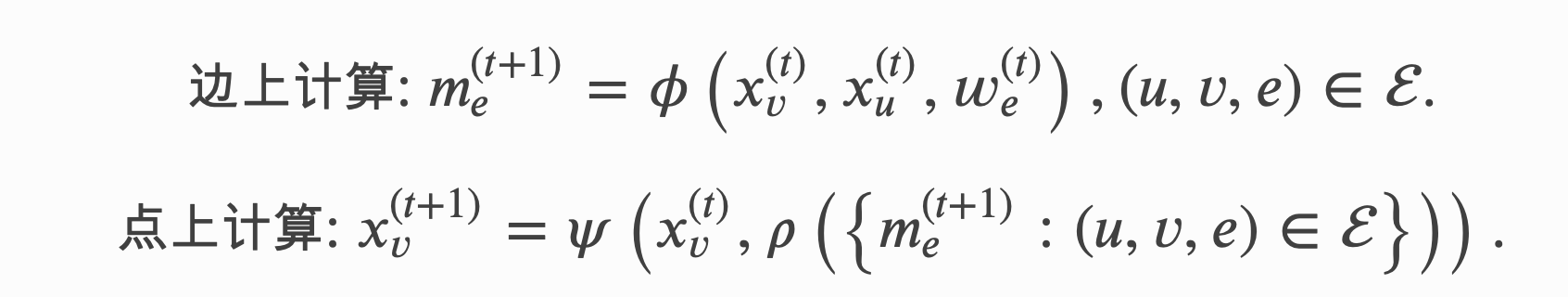
在上面的等式中, 𝜙是定义在每条边上的消息函数,它通过将边上特征与其两端节点的特征相结合来生成消息。
聚合函数 𝜌 会聚合节点接受到的消息。
更新函数 𝜓 会结合聚合后的消息和节点本身的特征来更新节点的特征。
4.1、内置函数和消息传递API*
- 消息函数接受一个参数
edges,这是一个EdgeBatch的实例,在消息传递时,它被DGL在内部生成以表示一批边。edges有src、dst和data共3个成员属性, 分别用于访问源节点、目标节点和边的特征。聚合函数接受一个参数nodes,这是一个NodeBatch的实例, 在消息传递时,它被DGL在内部生成以表示一批节点。nodes的成员属性mailbox可以用来访问节点收到的消息。 一些最常见的聚合操作包括sum、max、min等。 - 更新函数 接受一个如上所述的参数
nodes。此函数对聚合函数的聚合结果进行操作, 通常在消息传递的最后一步将其与节点的特征相结合,并将输出作为节点的新特征。 - DGL在命名空间
dgl.function中实现了常用的消息函数和聚合函数作为 内置函数。 一般来说,DGL建议 尽可能 使用内置函数,因为它们经过了大量优化,并且可以自动处理维度广播。 - 如果用户的消息传递函数无法用内置函数实现,则可以实现自己的消息或聚合函数(也称为 用户定义函数 )。
内置消息函数可以是一元函数或二元函数。
对于一元函数,DGL支持 copy 函数。
对于二元函数, DGL现在支持 add、 sub、 mul、 div、 dot 函数。
消息的内置函数的命名约定是 u 表示 src 节点, v 表示 dst 节点,e 表示 edge。这些函数的参数是字符串,指示相应节点和边的输入和输出特征字段名。 关于内置函数的列表,请参见 DGL Built-in Function。例如,要对源节点的 hu特征和目标节点的 hv 特征求和, 然后将结果保存在边的 he 特征上,用户可以使用内置函数 dgl.function.u_add_v('hu', 'hv', 'he')。 而以下用户定义消息函数与此内置函数等价。
def message_func(edges):
return {'he': edges.src['hu'] + edges.dst['hv']}
DGL支持内置的聚合函数 sum、 max、 min 和 mean 操作。 聚合函数通常有两个参数,它们的类型都是字符串。一个用于指定 mailbox 中的字段名,一个用于指示目标节点特征的字段名, 例如, dgl.function.sum('m', 'h') 等价于如下所示的对接收到消息求和的用户定义函数:
import torch
def reduce_func(nodes):
return {'h': torch.sum(nodes.mailbox['m'], dim=1)}
在DGL中,也可以在不涉及消息传递的情况下,通过 apply_edges() 单独调用逐边计算。 apply_edges() 的参数是一个消息函数。并且在默认情况下,这个接口将更新所有的边。例如:
import dgl.function as fn
graph.apply_edges(fn.u_add_v('el', 'er', 'e'))
对于消息传递, update_all() 是一个高级API。它在单个API调用里合并了消息生成、 消息聚合和节点特征更新,这为从整体上进行系统优化提供了空间。
update_all() 的参数是一个消息函数、一个聚合函数和一个更新函数。 更新函数是一个可选择的参数,用户也可以不使用它,而是在 update_all 执行完后直接对节点特征进行操作。
由于更新函数通常可以用纯张量操作实现,所以DGL不推荐在 update_all 中指定更新函数。例如:
def updata_all_example(graph):
# 在graph.ndata['ft']中存储结果
graph.update_all(fn.u_mul_e('ft', 'a', 'm'),fn.sum('m', 'ft'))
# 在update_all外调用更新函数
final_ft = graph.ndata['ft'] * 2
return final_ft
此调用通过将源节点特征 ft 与边特征 a 相乘生成消息 m, 然后对所有消息求和来更新节点特征 ft,再将 ft 乘以2得到最终结果 final_ft。
调用后,中间消息 m 将被清除。上述函数的数学公式为:
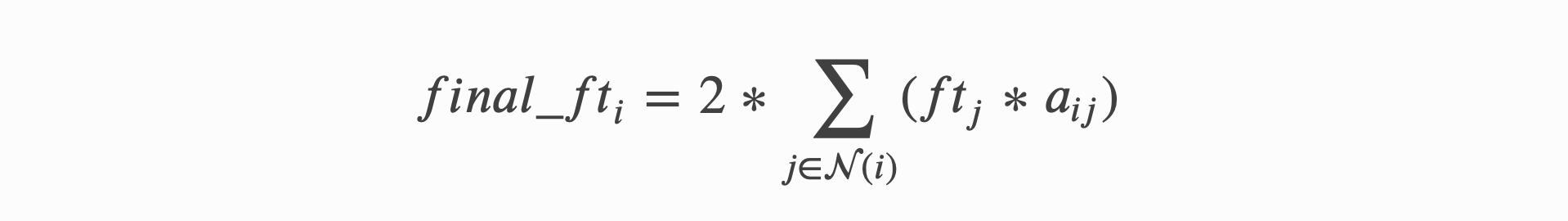
4.2、编写高效的消息传递代码
DGL优化了消息传递的内存消耗和计算速度,这包括:
- 将多个内核合并到一个内核中:这是通过使用
update_all()一次调用多个内置函数来实现的。(速度优化) - 节点和边上的并行计算:DGL抽象了逐边计算,将
apply_edges()作为一种广义抽样稠密-稠密矩阵乘法 (gSDDMM) 运算,并实现了跨边并行计算。同样,DGL将逐节点计算update_all()抽象为广义稀疏-稠密矩阵乘法(gSPMM)运算, 并实现了跨节点并行计算。(速度优化) - 避免不必要的从点到边的内存拷贝:想要生成带有源节点和目标节点特征的消息,一个选项是将源节点和目标节点的特征拷贝到边上。 对于某些图,边的数量远远大于节点的数量。这个拷贝的代价会很大。DGL内置的消息函数通过使用条目索引对节点特征进行采集来避免这种内存拷贝。 (内存和速度优化)
- 避免具体化边上的特征向量:完整的消息传递过程包括消息生成、消息聚合和节点更新。 在调用
update_all()时,如果消息函数和聚合函数是内置的,则它们会被合并到一个内核中, 从而避免存储消息对象。(内存优化)
根据以上所述,利用这些优化的一个常见实践是通过基于内置函数的 update_all() 来开发消息传递功能。
对于某些情况,比如 GATConv,计算必须在边上保存消息, 那么用户就需要调用基于内置函数的 apply_edges()。有时边上的消息可能是高维的,这会非常消耗内存。 DGL建议用户尽量减少边的特征维数。
下面是一个如何通过对节点特征降维来减少消息维度的示例。该做法执行以下操作:拼接 源 节点和 目标 节点特征, 然后应用一个线性层,即 𝑊×(𝑢||𝑣)。 src 节点和 dst 节点特征维数较高,而线性层输出维数较低。 一个直截了当的实现方式如下:
import torch
import torch.nn as nn
linear = nn.Parameter(torch.FloatTensor(size=(1, node_feat_dim * 2)))
def concat_message_function(edges):
return {'cat_feat': torch.cat([edges.src.ndata['feat'], edges.dst.ndata['feat']])}
g.apply_edges(concat_message_function)
g.edata['out'] = g.edata['cat_feat'] * linear
建议的实现是将线性操作分成两部分,一个应用于 源 节点特征,另一个应用于 目标 节点特征。 在最后一个阶段,在边上将以上两部分线性操作的结果相加,即执行 𝑊𝑙×𝑢+𝑊𝑟×𝑣Wl×u+Wr×v, 因为 𝑊×(𝑢||𝑣)=𝑊𝑙×𝑢+𝑊𝑟×𝑣W×(u||v)=Wl×u+Wr×v,其中 𝑊𝑙Wl 和 𝑊𝑟Wr 分别是矩阵 𝑊W 的左半部分和右半部分:
import dgl.function as fn
linear_src = nn.Parameter(torch.FloatTensor(size=(1, node_feat_dim)))
linear_dst = nn.Parameter(torch.FloatTensor(size=(1, node_feat_dim)))
out_src = g.ndata['feat'] * linear_src
out_dst = g.ndata['feat'] * linear_dst
g.srcdata.update({'out_src': out_src})
g.dstdata.update({'out_dst': out_dst})
g.apply_edges(fn.u_add_v('out_src', 'out_dst', 'out'))
以上两个实现在数学上是等价的。后一种方法效率高得多,因为不需要在边上保存feat_src和feat_dst, 从内存角度来说是高效的。另外,加法可以通过DGL的内置函数 u_add_v 进行优化,从而进一步加快计算速度并节省内存占用。
4.3、在图的一部分上进行消息传递
如果用户只想更新图中的部分节点,可以先通过想要囊括的节点编号创建一个子图, 然后在子图上调用 update_all() 方法。例如:
nid = [0, 2, 3, 6, 7, 9]
sg = g.subgraph(nid)
sg.update_all(message_func, reduce_func, apply_node_func)
这是小批量训练中的常见用法。更多详细用法请参考用户指南 第6章:在大图上的随机(批次)训练。
4.4、在消息传递中使用边的权重
一类常见的图神经网络建模的做法是在消息聚合前使用边的权重, 比如在 图注意力网络(GAT) 和一些 GCN的变种 。 DGL的处理方法是:
- 将权重存为边的特征。
- 在消息函数中用边的特征与源节点的特征相乘。
例如:
import dgl.function as fn
graph.edata['a'] = affinity
graph.update_all(fn.u_mul_e('ft', 'a', 'm'),fn.sum('m', 'ft'))
在以上代码中,affinity被用作边的权重。边权重通常是一个标量。
五、构建图神经网络(GNN)模块*
DGL NN模块是用户构建GNN模型的基本模块。根据DGL所使用的后端深度神经网络框架, DGL NN模块的父类取决于后端所使用的深度神经网络框架。
-
对于PyTorch后端, 它应该继承 PyTorch的NN模块;
-
对于MXNet后端,它应该继承 MXNet Gluon的NN块;
-
对于TensorFlow后端,它应该继承 Tensorflow的Keras层。
在DGL NN模块中,构造函数中的参数注册和前向传播函数中使用的张量操作与后端框架一样。这种方式使得DGL的代码可以无缝嵌入到后端框架的代码中。 DGL和这些深度神经网络框架的主要差异是其独有的消息传递操作。
DGL已经集成了很多常用的 Conv Layers、 Dense Conv Layers、 Global Pooling Layers 和 Utility Modules。欢迎给DGL贡献更多的模块!
本章将使用PyTorch作为后端,用 SAGEConv 作为例子来介绍如何构建用户自己的DGL NN模块。
5.1、 DGL NN模块的构造函数
构造函数完成以下几个任务:
- 设置选项。
- 注册可学习的参数或者子模块。
- 初始化参数。
import torch.nn as nn
from dgl.utils import expand_as_pair
class SAGEConv(nn.Module):
def __init__(self,
in_feats,
out_feats,
aggregator_type,
bias=True,
norm=None,
activation=None):
super(SAGEConv, self).__init__()
self._in_src_feats, self._in_dst_feats = expand_as_pair(in_feats)
self._out_feats = out_feats
self._aggre_type = aggregator_type
self.norm = norm
self.activation = activation
# 聚合类型:mean、max_pool、lstm、gcn
if aggregator_type not in ['mean', 'max_pool', 'lstm', 'gcn']:
raise KeyError('Aggregator type {} not supported.'.format(aggregator_type))
if aggregator_type == 'max_pool':
self.fc_pool = nn.Linear(self._in_src_feats, self._in_src_feats)
if aggregator_type == 'lstm':
self.lstm = nn.LSTM(self._in_src_feats, self._in_src_feats, batch_first=True)
if aggregator_type in ['mean', 'max_pool', 'lstm']:
self.fc_self = nn.Linear(self._in_dst_feats, out_feats, bias=bias)
self.fc_neigh = nn.Linear(self._in_src_feats, out_feats, bias=bias)
self.reset_parameters()
def reset_parameters(self):
"""重新初始化可学习的参数"""
gain = nn.init.calculate_gain('relu')
if self._aggre_type == 'max_pool':
nn.init.xavier_uniform_(self.fc_pool.weight, gain=gain)
if self._aggre_type == 'lstm':
self.lstm.reset_parameters()
if self._aggre_type != 'gcn':
nn.init.xavier_uniform_(self.fc_self.weight, gain=gain)
nn.init.xavier_uniform_(self.fc_neigh.weight, gain=gain)
-
在构造函数中,用户首先需要设置数据的维度。对于一般的PyTorch模块,维度通常包括输入的维度、输出的维度和隐层的维度。 对于图神经网络,输入维度可被分为源节点特征维度和目标节点特征维度。
-
除了数据维度,图神经网络的一个典型选项是聚合类型(
self._aggre_type)。对于特定目标节点,聚合类型决定了如何聚合不同边上的信息。常用的聚合类型包括mean、sum、max和min。一些模块可能会使用更加复杂的聚合函数,比如lstm。 -
上面代码里的
norm是用于特征归一化的可调用函数。在SAGEConv论文里,归一化可以是L2归一化: \(ℎ_𝑣=ℎ_𝑣/‖ℎ_𝑣‖_2\)。 -
注册参数和子模块。
-
在SAGEConv中,子模块根据聚合类型而有所不同。这些模块是纯PyTorch NN模块,例如
nn.Linear、nn.LSTM等。 -
构造函数的最后调用了
reset_parameters()进行权重初始化。
5.2、编写DGL NN模块的forward函数
5.3、异构图上的GraphConv模块
六、图数据处理管道
DGL在 dgl.data 里实现了很多常用的图数据集。
它们遵循了由 dgl.data.DGLDataset 类定义的标准的数据处理管道。
DGL推荐用户将图数据处理为 dgl.data.DGLDataset 的子类。该类为导入、处理和保存图数据提供了简单而干净的解决方案。
本章介绍了如何为用户自己的图数据创建一个DGL数据集。以下内容说明了管道的工作方式,并展示了如何实现管道的每个组件。
6.1、DGLDataset类
为了处理位于远程服务器或本地磁盘上的图数据集,下面的例子中定义了一个类,称为 MyDataset, 它继承自 dgl.data.DGLDataset。
from dgl.data import DGLDataset
class MyDataset(DGLDataset):
""" 用于在DGL中自定义图数据集的模板:
Parameters
----------
url : str
下载原始数据集的url。
raw_dir : str
指定下载数据的存储目录或已下载数据的存储目录。默认: ~/.dgl/
save_dir : str
处理完成的数据集的保存目录。默认:raw_dir指定的值
force_reload : bool
是否重新导入数据集。默认:False
verbose : bool
是否打印进度信息。
"""
def __init__(self,
url=None,
raw_dir=None,
save_dir=None,
force_reload=False,
verbose=False):
super(MyDataset, self).__init__(name='dataset_name',
url=url,
raw_dir=raw_dir,
save_dir=save_dir,
force_reload=force_reload,
verbose=verbose)
def download(self):
# 将原始数据下载到本地磁盘
pass
def process(self):
# 将原始数据处理为图、标签和数据集划分的掩码
pass
def __getitem__(self, idx):
# 通过idx得到与之对应的一个样本
pass
def __len__(self):
# 数据样本的数量
pass
def save(self):
# 将处理后的数据保存至 `self.save_path`
pass
def load(self):
# 从 `self.save_path` 导入处理后的数据
pass
def has_cache(self):
# 检查在 `self.save_path` 中是否存有处理后的数据
pass
DGLDataset 类有抽象函数 process(), __getitem__(idx) 和 __len__()。
子类必须实现这些函数。同时DGL也建议实现保存和导入函数, 因为对于处理后的大型数据集,这么做可以节省大量的时间, 并且有多个已有的API可以简化此操作(请参阅 4.4 保存和加载数据)。
请注意, DGLDataset 的目的是提供一种标准且方便的方式来导入图数据。 用户可以存储有关数据集的图、特征、标签、掩码,以及诸如类别数、标签数等基本信息。 诸如采样、划分或特征归一化等操作建议在 DGLDataset 子类之外完成。
6.2、下载原始数据(可选)
6.3、处理数据
6.4、保存和加载数据
6.5、使用ogb包导入OGB数据集
七: 训练图神经网络*
本章讨论训练用于节点分类,边分类,链接预测和批图的图分类的图神经网络。
本章假设您的图及其所有节点和边都可以放入GPU。 如果不能的话, 参阅第6章:在大图上的随机(批次)训练。。
以下文本假定已经准备好图形和节点/边特征。
如果您打算使用DGL提供的数据集或其他兼容的“ DGLDataset”,则可以使用以下内容获取单图形数据集的图形:
import dgl
dataset = dgl.data.CiteseerGraphDataset()
graph = dataset[0]
Note: In this chapter we will use PyTorch as backend.
异构图
有时您想处理异构图。 这里我们以合成异构图为例,演示节点分类,边分类和链接预测任务。
合成异构图hetero_graph具有以下边类型:
('user', 'follow', 'user')('user', 'followed-by', 'user')('user', 'click', 'item')('item', 'clicked-by', 'user')('user', 'dislike', 'item')('item', 'disliked-by', 'user')
import numpy as np
import torch
n_users = 1000
n_items = 500
n_follows = 3000
n_clicks = 5000
n_dislikes = 500
n_hetero_features = 10
n_user_classes = 5
n_max_clicks = 10
follow_src = np.random.randint(0, n_users, n_follows)
follow_dst = np.random.randint(0, n_users, n_follows)
click_src = np.random.randint(0, n_users, n_clicks)
click_dst = np.random.randint(0, n_items, n_clicks)
dislike_src = np.random.randint(0, n_users, n_dislikes)
dislike_dst = np.random.randint(0, n_items, n_dislikes)
hetero_graph = dgl.heterograph({
('user', 'follow', 'user'): (follow_src, follow_dst),
('user', 'followed-by', 'user'): (follow_dst, follow_src),
('user', 'click', 'item'): (click_src, click_dst),
('item', 'clicked-by', 'user'): (click_dst, click_src),
('user', 'dislike', 'item'): (dislike_src, dislike_dst),
('item', 'disliked-by', 'user'): (dislike_dst, dislike_src)})
hetero_graph.nodes['user'].data['feature'] = torch.randn(n_users, n_hetero_features)
hetero_graph.nodes['item'].data['feature'] = torch.randn(n_items, n_hetero_features)
hetero_graph.nodes['user'].data['label'] = torch.randint(0, n_user_classes, (n_users,))
hetero_graph.edges['click'].data['label'] = torch.randint(1, n_max_clicks, (n_clicks,)).float()
# randomly generate training masks on user nodes and click edges
hetero_graph.nodes['user'].data['train_mask'] = torch.zeros(n_users, dtype=torch.bool).bernoulli(0.6)
hetero_graph.edges['click'].data['train_mask'] = torch.zeros(n_clicks, dtype=torch.bool).bernoulli(0.6)
7.1 点分类/回归
图神经网络最流行和广泛采用的任务之一是节点分类,其中训练/验证/测试集中的每个节点都从一组预定义的类别中分配了一个地面真相类别。节点回归是相似的,其中训练/验证/测试集中的每个节点都分配有地面真实数字。
概述
为了对节点进行分类,图神经网络执行了第2章:消息传递中讨论的消息传递,以利用节点自身的功能以及相邻节点和边缘的功能。消息传递可以重复多次,以合并来自更大范围邻居的信息。
编写神经网络模型
DGL提供了一些内置的图形卷积模块,可以执行一轮消息传递。在本指南中,我们选择dgl.nn.pytorch.SAGEConv(在MXNet和Tensorflow中也提供),这是GraphSAGE的图形卷积模块。
通常对于图上的深度学习模型,我们需要一个多层图神经网络,在其中进行多轮消息传递。这可以通过如下堆叠图卷积模块来实现。
# Contruct a two-layer GNN model
import dgl.nn as dglnn
import torch.nn as nn
import torch.nn.functional as F
class SAGE(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats):
super().__init__()
self.conv1 = dglnn.SAGEConv(
in_feats=in_feats, out_feats=hid_feats, aggregator_type='mean')
self.conv2 = dglnn.SAGEConv(
in_feats=hid_feats, out_feats=out_feats, aggregator_type='mean')
def forward(self, graph, inputs):
# inputs are features of nodes
h = self.conv1(graph, inputs)
h = F.relu(h)
h = self.conv2(graph, h)
return h
请注意,您不仅可以将上述模型用于节点分类,还可以为其他任务例如7.2边分类/回归,7.3链接预测或7.4图形分类获得隐藏的节点表示。
循环训练
在完整图上进行训练仅涉及上述模型的正向传播,并通过将预测与训练节点上的地面真实标签进行比较来计算损失。
本节使用DGL内置数据集dgl.data.CiteseerGraphDataset来显示训练循环。
The following is an example of evaluating your model by accuracy.
def evaluate(model, graph, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(graph, features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
You can then write our training loop as follows.
model = SAGE(in_feats=n_features, hid_feats=100, out_feats=n_labels)
opt = torch.optim.Adam(model.parameters())
for epoch in range(10):
model.train()
# forward propagation by using all nodes
logits = model(graph, node_features)
# compute loss
loss = F.cross_entropy(logits[train_mask], node_labels[train_mask])
# compute validation accuracy
acc = evaluate(model, graph, node_features, node_labels, valid_mask)
# backward propagation
opt.zero_grad()
loss.backward()
opt.step()
print(loss.item())
# Save model if necessary. Omitted in this example.
GraphSAGE 提供了一个端到端的同构图节点分类示例。 您可以在示例中的GraphSAGE类中看到相应的模型实现,其中具有可调整的层数,loss以及可自定义的聚合函数和non-linear。
异构图
如果图是异构的,则您可能希望从所有边的邻居那里收集消息。 您可以使用模块dgl.nn.pytorch.HeteroGraphConv 在所有边上执行消息传递,然后为每种边组合不同的图卷积模块。
以下代码将定义一个异构图卷积模块,该模块首先对每种边缘类型执行单独的图卷积,然后将每种边缘类型上的消息聚合求和,作为所有节点类型的最终结果。
# Define a Heterograph Conv model
import dgl.nn as dglnn
class RGCN(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats, rel_names):
super().__init__()
self.conv1 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(in_feats, hid_feats)
for rel in rel_names}, aggregate='sum')
self.conv2 = dglnn.HeteroGraphConv({
rel: dglnn.GraphConv(hid_feats, out_feats)
for rel in rel_names}, aggregate='sum')
def forward(self, graph, inputs):
# inputs are features of nodes
h = self.conv1(graph, inputs)
h = {k: F.relu(v) for k, v in h.items()}
h = self.conv2(graph, h)
return h
DGL为节点分类提供了RGCN 的端到端示例,您可以在 model implementation file的RelGraphConvLayer中看到异构图卷积的定义。
7.2 边分类/回归
有时您希望预测图边上的属性,甚至预测两个给定节点之间是否存在边。在这种情况下,您需要一个边分类/回归模型。在这里,我们生成用于边预测的随机图作为演示。
src = np.random.randint(0, 100, 500)
dst = np.random.randint(0, 100, 500)
# make it symmetric
edge_pred_graph = dgl.graph((np.concatenate([src, dst]), np.concatenate([dst, src])))
# synthetic node and edge features, as well as edge labels
edge_pred_graph.ndata['feature'] = torch.randn(100, 10)
edge_pred_graph.edata['feature'] = torch.randn(1000, 10)
edge_pred_graph.edata['label'] = torch.randn(1000)
# synthetic train-validation-test splits
edge_pred_graph.edata['train_mask'] = torch.zeros(1000, dtype=torch.bool).bernoulli(0.6)
概述
从上一节中,学习了如何使用多层GNN进行节点分类。 可以将相同技术应用于计算任何节点的隐藏表示。 然后可以从其入射节点的表示中得出边的预测。
在边上计算预测的最常见情况是将其表示为其入射节点表示以及边自身特征的参数化函数。
模型实现与节点分类的区别
假设您使用上一部分中的模型计算节点表示形式,则只需要编写另一个使用 apply_edges() 方法计算边缘预测的组件。
例如,如果您想计算每个边缘的分数以进行边回归,则以下代码将计算每个边上入射节点表示的点积
import dgl.function as fn
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
# h contains the node representations computed from the GNN defined
# in the node classification section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
还可以编写一种预测函数,该函数使用MLP预测每个边缘的向量。 这种载体可用于进一步的下游任务,例如 作为分类分布的对数。
class MLPPredictor(nn.Module):
def __init__(self, in_features, out_classes):
super().__init__()
self.W = nn.Linear(in_features * 2, out_classes)
def apply_edges(self, edges):
h_u = edges.src['h']
h_v = edges.dst['h']
score = self.W(torch.cat([h_u, h_v], 1))
return {'score': score}
def forward(self, graph, h):
# h contains the node representations computed from the GNN defined
# in the node classification section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(self.apply_edges)
return graph.edata['score']
训练循环
给定节点表示计算模型和边缘预测器模型,我们可以轻松编写一个全图训练循环,在其中计算所有边缘的预测。下例以上一节中的SAGE作为节点表示计算模型,以DotPredictor作为边缘预测器模型。
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, x):
h = self.sage(g, x)
return self.pred(g, h)
在此示例中,我们还假定训练/验证/测试边缘集由边缘上的布尔掩码标识。 此示例也不包括提前停止和模型保存。
node_features = edge_pred_graph.ndata['feature']
edge_label = edge_pred_graph.edata['label']
train_mask = edge_pred_graph.edata['train_mask']
model = Model(10, 20, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(10):
pred = model(edge_pred_graph, node_features)
loss = ((pred[train_mask] - edge_label[train_mask]) ** 2).mean()
opt.zero_grad()
loss.backward()
opt.step()
print(loss.item())
异构图
异构图上的边分类与齐次图上的边分类没有太大区别。 如果希望对一种边缘类型执行边缘分类,则只需要计算所有节点类型的节点表示形式,并使用apply_edges()方法对该边缘类型进行预测。
例如,要使DotProductPredictor在异构图的一种边缘类型上工作,只需在apply_edges方法中指定边缘类型。
class HeteroDotProductPredictor(nn.Module):
def forward(self, graph, h, etype):
# h contains the node representations for each edge type computed from
# the GNN for heterogeneous graphs defined in the node classification
# section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h # assigns 'h' of all node types in one shot
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'), etype=etype)
return graph.edges[etype].data['score']
You can similarly write a HeteroMLPPredictor.
class MLPPredictor(nn.Module):
def __init__(self, in_features, out_classes):
super().__init__()
self.W = nn.Linear(in_features * 2, out_classes)
def apply_edges(self, edges):
h_u = edges.src['h']
h_v = edges.dst['h']
score = self.W(torch.cat([h_u, h_v], 1))
return {'score': score}
def forward(self, graph, h, etype):
# h contains the node representations for each edge type computed from
# the GNN for heterogeneous graphs defined in the node classification
# section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h # assigns 'h' of all node types in one shot
graph.apply_edges(self.apply_edges, etype=etype)
return graph.edges[etype].data['score']
预测单个边缘类型上每个边得分的端到端模型如下所示:
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, rel_names):
super().__init__()
self.sage = RGCN(in_features, hidden_features, out_features, rel_names)
self.pred = HeteroDotProductPredictor()
def forward(self, g, x, etype):
h = self.sage(g, x)
return self.pred(g, h, etype)
使用模型仅涉及向模型提供节点类型和特征的字典。
model = Model(10, 20, 5, hetero_graph.etypes)
user_feats = hetero_graph.nodes['user'].data['feature']
item_feats = hetero_graph.nodes['item'].data['feature']
label = hetero_graph.edges['click'].data['label']
train_mask = hetero_graph.edges['click'].data['train_mask']
node_features = {'user': user_feats, 'item': item_feats}
然后,训练循环看起来与齐次图中的几乎相同。 例如,如果您希望预测边缘类型“ click”的边缘标签,则只需
opt = torch.optim.Adam(model.parameters())
for epoch in range(10):
pred = model(hetero_graph, node_features, 'click')
loss = ((pred[train_mask] - label[train_mask]) ** 2).mean()
opt.zero_grad()
loss.backward()
opt.step()
print(loss.item())
预测异构图上现有边的边类型
有时您可能想预测现有边属于哪种类型。例如,在给出异构图形示例的情况下, heterogeneous graph example指定了一条将用户和项目连接起来的边,以预测用户是单击还是不喜欢该项目。
可以使用异构图卷积网络来获取节点表示。例如仍然可以为此使用先前定义的RGCN。要预测边缘的类型,您可以简单地重新使用上面的HeteroDotProductPredictor,以便它使用另一种仅包含一个边类型的图来“合并”所有要预测的边类型,并为每个边发出每种类型的得分。
在此处的示例中,您需要一个图,该图具有两种节点类型:用户和项目,以及一个单一的边缘类型,用于“合并”用户和项目中的所有边缘类型,即单击和不喜欢。可以使用以下语法方便地创建它:
dec_graph = hetero_graph['user', :, 'item']
它返回具有节点类型user和item的异构图形,以及返回合并了介于两者之间的所有边缘类型(即单击和不喜欢)的单个边缘类型。
由于上面的语句还返回了原始边缘类型作为名为dgl.ETYPE的功能,因此我们可以将其用作标签。
edge_label = dec_graph.edata[dgl.ETYPE]
给定上图作为边缘类型预测器模块的输入,您可以如下编写预测器模块。
class HeteroMLPPredictor(nn.Module):
def __init__(self, in_dims, n_classes):
super().__init__()
self.W = nn.Linear(in_dims * 2, n_classes)
def apply_edges(self, edges):
x = torch.cat([edges.src['h'], edges.dst['h']], 1)
y = self.W(x)
return {'score': y}
def forward(self, graph, h):
# h contains the node representations for each edge type computed from
# the GNN for heterogeneous graphs defined in the node classification
# section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h # assigns 'h' of all node types in one shot
graph.apply_edges(self.apply_edges)
return graph.edata['score']
结合了节点表示模块和边缘类型预测器模块的模型如下
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, rel_names):
super().__init__()
self.sage = RGCN(in_features, hidden_features, out_features, rel_names)
self.pred = HeteroMLPPredictor(out_features, len(rel_names))
def forward(self, g, x, dec_graph):
h = self.sage(g, x)
return self.pred(dec_graph, h)
训练循环如下:
model = Model(10, 20, 5, hetero_graph.etypes)
user_feats = hetero_graph.nodes['user'].data['feature']
item_feats = hetero_graph.nodes['item'].data['feature']
node_features = {'user': user_feats, 'item': item_feats}
opt = torch.optim.Adam(model.parameters())
for epoch in range(10):
logits = model(hetero_graph, node_features, dec_graph)
loss = F.cross_entropy(logits, edge_label)
opt.zero_grad()
loss.backward()
opt.step()
print(loss.item())
DGL提供了图卷积矩阵 作为rating预测的示例,该rating通过预测异构图上现有边的类型来制定。 model implementation file 中的节点表示模块称为GCMCLayer。 边缘类型预测器模块称为BiDecoder。 两者都比此处描述的设置复杂。
7.3 链接预测
总的来说,Link Prediction是一个Graph问题,它的目标是根据已知的节点和边,得到新的边的权值或特征。
在不同的 task 中,Link Prediction 被用于:
-
在社交网络中,进行用户/商品推荐
-
在生物学领域,进行相互作用发现
-
在知识图谱中,进行实体关系学习
-
在基础研究中,进行图结构捕捉
从图的角度出发,可以简单理解为从一个点到其他点的链接概率,就好比说,一个社交网络上,你只和其中很少一部分人建立了社交关系,剩下这么多用户你都没有关注啥的,那我现在要给你推荐一些用户,让你们互相关注,点赞啥的,推荐的这个过程就可以理解为一个链接预测。您可能想预测两个给定节点之间是否存在边。 这种模型称为链接预测模型。
概述
基于GNN的链路预测模型将两个节点 \(u\) 和 \(v\) 之间的连通性的可能性表示为 \(ℎ^{𝐿}_𝑢\) 和 \(ℎ^𝐿_𝑣\)的函数,节点是从多层GNN计算得出的。
\(𝑦_{𝑢,𝑣}\) 代表了u和v节点之间的 \(score\)。
训练链路预测模型涉及将通过边连接的节点之间的score与任意一对节点之间的 \(score\)进行比较。
例如,在给定连接𝑢和𝑣的边的情况下,
我们鼓励节点𝑢和𝑣之间得分高于节点 𝑢 和采样节点 𝑣' 之间的得分,该得分来自任意噪声分布\(v'〜P_𝑛(𝑣)\)。 这种方法称为“负采样”。如果最小化,有很多损失函数可以实现上述行为。 非详尽清单包括:
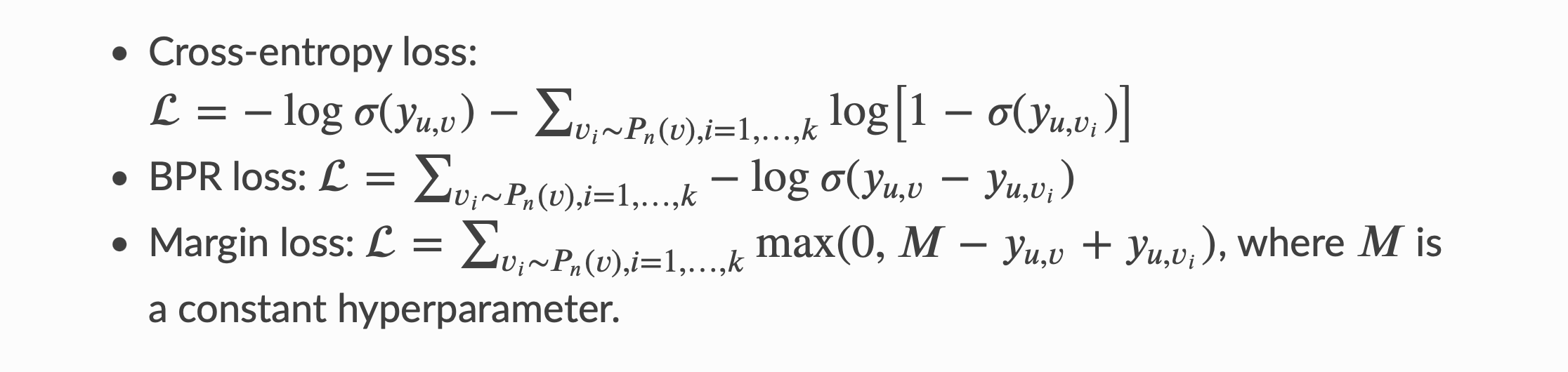
模型实现与边分类的区别
用于计算 \(𝑢\) 和 \(v\) 之间得分的神经网络模型与上述边缘回归模型相同。
这是使用点积计算边得分的示例.
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
# h contains the node representations computed from the GNN defined
# in the node classification section (Section 5.1).
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
训练循环
因为我们的分数预测模型是在图上运行的,所以我们需要negative examples表示为另一个图。
该图包含所有负节点对作为边。下面显示了将negative examples表示为图的示例。 每个边(𝑢,𝑣)取𝑘个negative examples \((𝑢,𝑣_𝑖)\),其中\(v_i\)从均匀分布中采样。
def construct_negative_graph(graph, k):
src, dst = graph.edges()
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.number_of_nodes(), (len(src) * k,))
return dgl.graph((neg_src, neg_dst), num_nodes=graph.number_of_nodes())
预测边缘得分的模型与边缘分类/回归模型相同。
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, neg_g, x):
h = self.sage(g, x)
return self.pred(g, h), self.pred(neg_g, h)
然后,训练循环反复构造负图并计算损失。
def compute_loss(pos_score, neg_score):
# Margin loss
n_edges = pos_score.shape[0]
return (1 - neg_score.view(n_edges, -1) + pos_score.unsqueeze(1)).clamp(min=0).mean()
node_features = graph.ndata['feat']
n_features = node_features.shape[1]
k = 5
model = Model(n_features, 100, 100)
opt = torch.optim.Adam(model.parameters())
for epoch in range(10):
negative_graph = construct_negative_graph(graph, k)
pos_score, neg_score = model(graph, negative_graph, node_features)
loss = compute_loss(pos_score, neg_score)
opt.zero_grad()
loss.backward()
opt.step()
print(loss.item())
经过训练,可以得到node embeding
node_embeddings = model.sage(graph, node_features)
有多种使用node embeding方法。 示例包括训练下游分类器,或对相关实体推荐进行最近邻搜索或最大内积搜索。
7.4 图分类
有时可能会有多个图的数据,而不是一个大图,例如一组不同类型人的社区。
通过用图表描述同一社区中人们之间的友谊,就可以得到一系列图表进行分类。
在这种情况下,图分类模型可以帮助识别社区的类型,即根据结构和整体信息对每个图进行分类。
概述
图分类与节点分类或链接预测之间的主要区别在于,预测结果表征了整个输入图的特性。
可以像以前的任务一样在节点/边缘上执行消息传递,但是还需要检索图形级表示。
图形分类管道的过程如下:
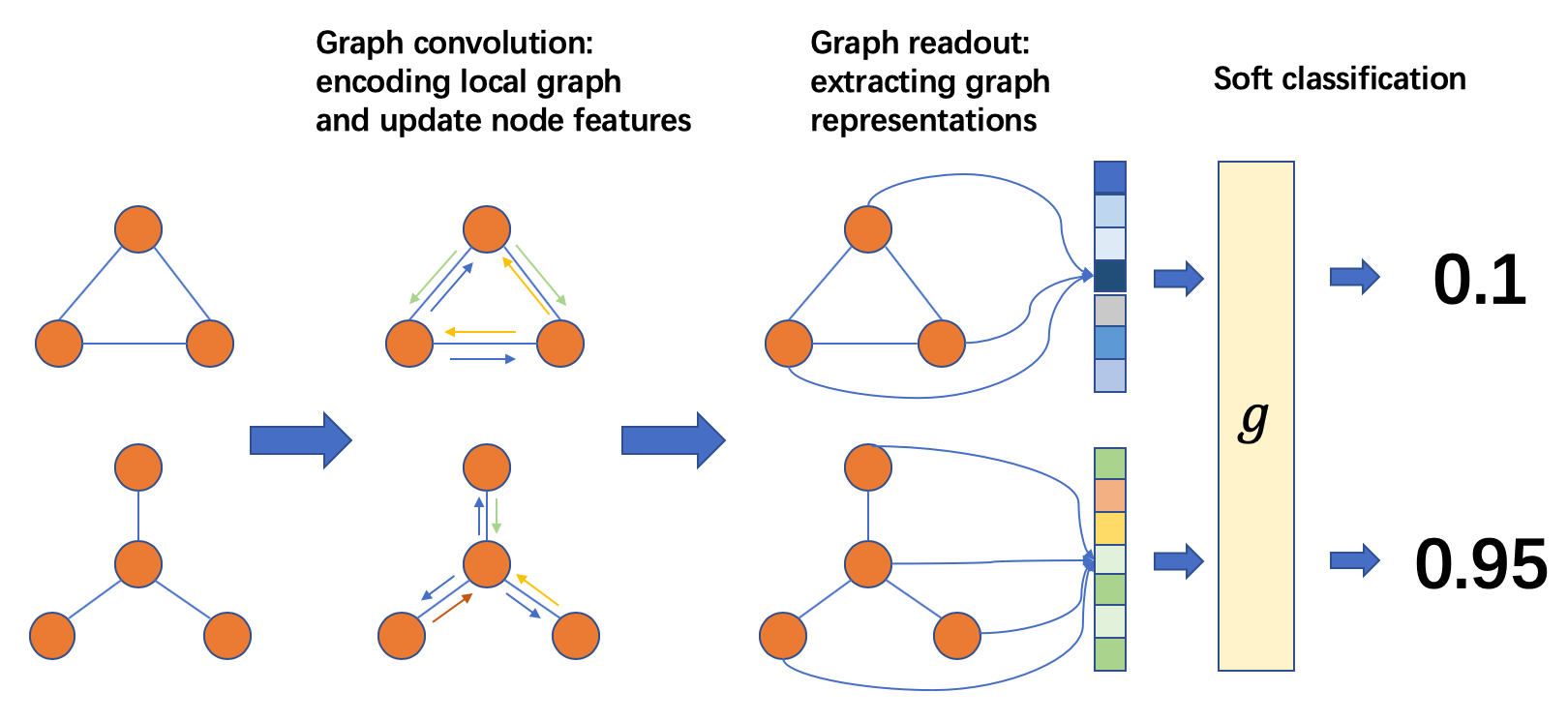
- 准备一批图
- 在批处理图上执行消息传递以更新节点/边缘功能
- 将节点/边缘特征聚合为图表示
- 根据图表示对图进行分类
批图
通常,图分类任务在许多图上进行训练,在训练模型时,一次仅使用一个图将非常低效。 从常见的深度学习实践中借鉴了小批量培训的想法,可以构建一批多个图并将它们一起发送以进行一次培训迭代。
在DGL中,可以从图列表中构建单个批处理图。
该批处理图可以简单地用作单个大图,其连接的组件对应于原始小图。
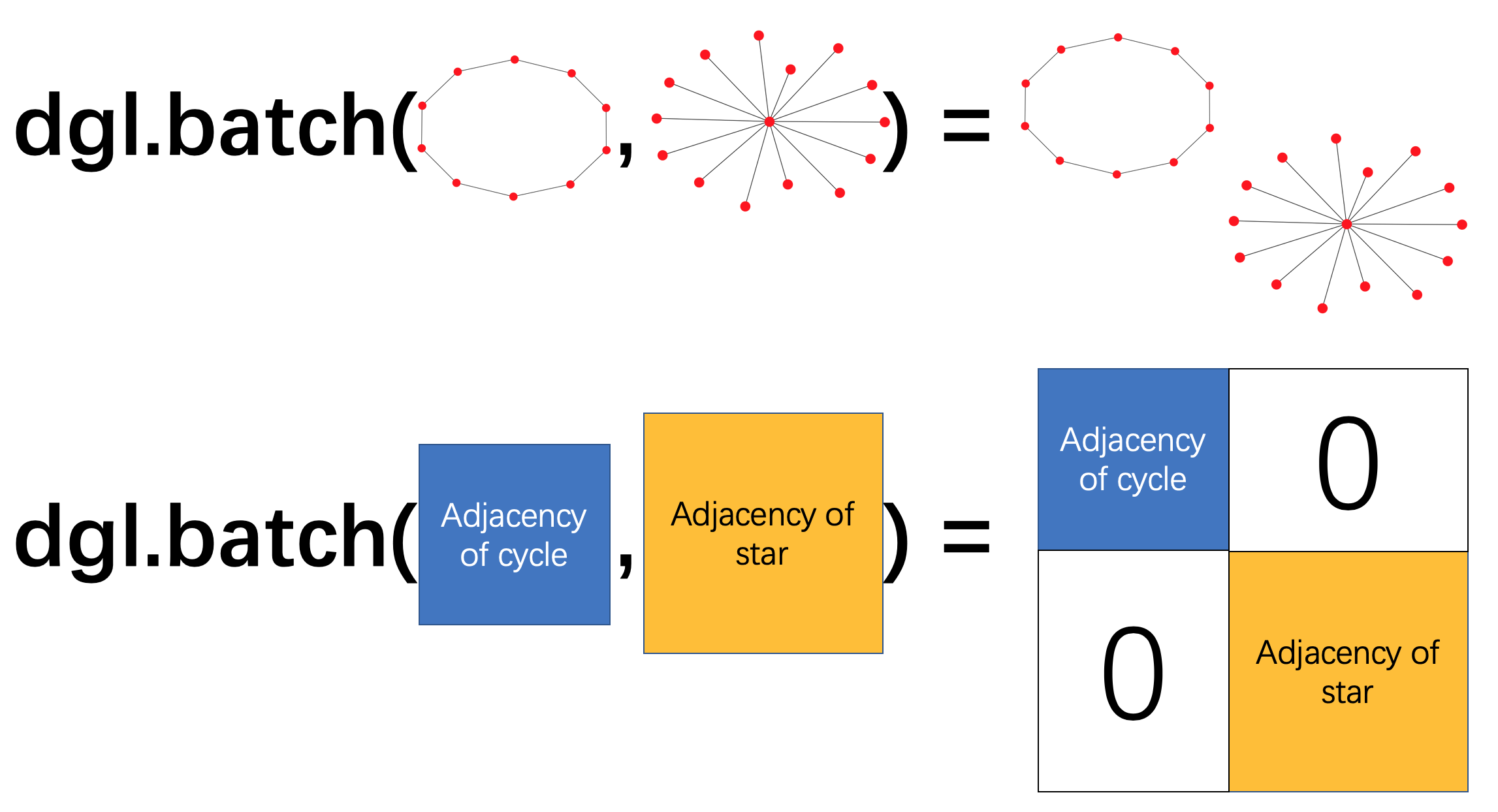
图读数
数据中的每个图都可能具有独特的结构以及节点和边特征。为了做出单个预测,通常会汇总可能的丰富信息。这种类型的操作称为读出。 常见的读出操作包括所有节点或边特征的求和,平均值,最大值或最小值。
给定一个图 \(𝑔\),可以将平均节点特征读数定义为
其中 \(ℎ_𝑔\) 是的表示形式,𝑔是𝑔中节点的集合,\(ℎ_𝑣\) 是节点的功能,DGL为常见的读取操作提供了内置支持。 例如,dgl.readout_nodes()实现了上述读出操作,一旦 \(ℎ_𝑔\) 可用,就可以将其传递给MLP层以进行分类输出。
编写神经网络模型
模型的输入是具有节点和边特征的批处理图。
批处理图上的计算
首先,一批不同图完全分开,即任何两个图之间没有边。
有了这个不错的属性,所有消息传递函数仍然具有相同的结果。
其次,将对每个图形分别进行批处理图形的读取功能。假设批次大小为𝐵,并且要聚合的特征的尺寸为𝐷,则读取结果的形状将为(𝐵,𝐷)。
import dgl
import torch
g1 = dgl.graph(([0, 1], [1, 0]))
g1.ndata['h'] = torch.tensor([1., 2.])
g2 = dgl.graph(([0, 1], [1, 2]))
g2.ndata['h'] = torch.tensor([1., 2., 3.])
dgl.readout_nodes(g1, 'h')
# tensor([3.]) # 1 + 2
bg = dgl.batch([g1, g2])
dgl.readout_nodes(bg, 'h')
# tensor([3., 6.]) # [1 + 2, 1 + 2 + 3]
最后,通过按顺序将所有图中的相应特征串联在一起,可以获得批处理图中的每个节点/边缘特征。
bg.ndata['h']
# tensor([1., 2., 1., 2., 3.])
模型定义
鉴于上述的计算规则,我们的模型可以定义为:
import dgl.nn.pytorch as dglnn
import torch.nn as nn
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
super(Classifier, self).__init__()
self.conv1 = dglnn.GraphConv(in_dim, hidden_dim)
self.conv2 = dglnn.GraphConv(hidden_dim, hidden_dim)
self.classify = nn.Linear(hidden_dim, n_classes)
def forward(self, g, h):
# Apply graph convolution and activation.
h = F.relu(self.conv1(g, h))
h = F.relu(self.conv2(g, h))
with g.local_scope():
g.ndata['h'] = h
# Calculate graph representation by average readout.
hg = dgl.mean_nodes(g, 'h')
return self.classify(hg)
循环训练
读取数据
一旦定义了模型,就可以开始训练。 由于图分类处理的是很多相对较小的图,而不是一个大图,因此人们可以在随机mini-gragh上进行有效的训练,而无需设计复杂的图采样算法。
假设有一个图分类数据集如Graph Data Pipeline中介绍的一样
import dgl.data
dataset = dgl.data.GINDataset('MUTAG', False)
图分类数据集中的每个项目都是一对图及其标签。 可以通过使用DataLoader,自定义collate函数来批量处理图形来加快数据加载过程
def collate(samples):
graphs, labels = map(list, zip(*samples))
batched_graph = dgl.batch(graphs)
batched_labels = torch.tensor(labels)
return batched_graph, batched_labels
然后,可以创建一个DataLoader,该数据在小批处理中迭代图的数据集。
from torch.utils.data import DataLoader
dataloader = DataLoader(
dataset,
batch_size=1024,
collate_fn=collate,
drop_last=False,
shuffle=True)
循环训练
训练循环仅涉及遍历DataLoader并更新Model。
import torch.nn.functional as F
# Only an example, 7 is the input feature size
model = Classifier(7, 20, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(20):
for batched_graph, labels in dataloader:
feats = batched_graph.ndata['attr'].float()
logits = model(batched_graph, feats)
loss = F.cross_entropy(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
有关图形分类的端到端示例,请参见DGL’s GIN example。 训练循环位于main.py中的功能训练中。 该模型实现位于gin.py中,具有更多组件,例如,使用dgl.nn.pytorch.GINConv作为图卷积层,批处理规范化等。
八:大图的随机训练
如果我们有一个包含数百万甚至数十亿个节点或边的大规模图形,那么通常无法训练图神经网络中所述的全图训练。
考虑一个在节点图上运行的,具有隐藏状态大小𝐻的𝐿层图卷积网络,存储中间隐藏状态需要𝑂(𝑁𝐿𝐻)显存,轻松超过一个GPU的容量N。
8-1、邻域采样方法概述
邻域采样方法通常按以下方式工作。 对于每个梯度下降步骤,我们选择小批量图的节点,其最终表示将在第 \(L\) 层进行计算。 然后我们将所有或部分邻居作为 \(𝐿-1\) 层的成员。这个过程一直持续到我们输入。 这个迭代过程将构建依赖关系图,从输出开始,一直到输入,如下图所示:
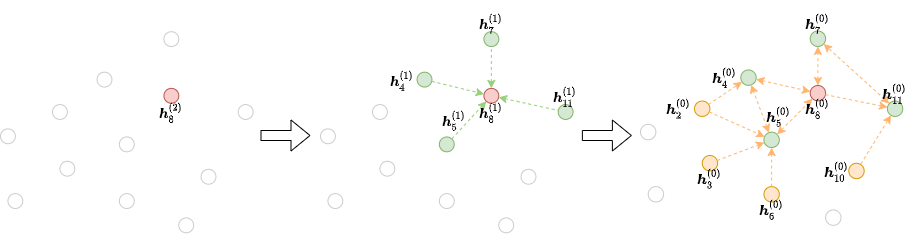
这样一来,可以节省用于在大型图上训练GNN的工作量和计算资源。DGL提供了一些邻域采样器和用于通过邻域采样训练GNN的管道,以及自定义采样策略的方式。
8-2、学习路线
本章从不同场景下随机训练GNN的部分开始。
- 8.1 Training GNN for Node Classification with Neighborhood Sampling
- 8.2 Training GNN for Edge Classification with Neighborhood Sampling
- 8.3 Training GNN for Link Prediction with Neighborhood Sampling
其余部分涵盖了更高级的主题,适合那些希望开发新的采样算法,与小批量培训兼容的新GNN模块并了解如何在小批量中进行评估和推断的人员。
- 8.4 Customizing Neighborhood Sampler
- 8.5 Implementing Custom GNN Module for Mini-batch Training
- 8.6 Exact Offline Inference on Large Graphs
九: 分布式训练
DGL采用完全分布式的方法,可将数据和计算同时分布在一组计算资源中。在本节的上下文中,我们将假设一个集群。 DGL将图划分为子图,并且群集中的每台计算机负责一个子图。
DGL在群集中的所有计算机上运行相同的训练脚本以并行化计算,并在同一计算机上运行服务器以将分区数据提供给训练程序。
对于训练脚本,DGL提供了类似于mini-batch训练的分布式API。这使得分布式培训仅需要对单个机器上的小批量培训进行少量代码修改即可。
下面显示了以分布式方式训练GraphSage的示例。唯一的代码修改位于4-7行:
- 初始化DGL的分布式模块。
- 创建一个分布式图形对象。
- 拆分训练集并计算本地过程的节点。
其余代码(包括采样器创建,模型定义,训练循环)与小批量训练相同。
import dgl
import torch as th
dgl.distributed.initialize('ip_config.txt', num_servers, num_workers)
th.distributed.init_process_group(backend='gloo')
g = dgl.distributed.DistGraph('graph_name', 'part_config.json')
pb = g.get_partition_book()
train_nid = dgl.distributed.node_split(g.ndata['train_mask'], pb, force_even=True)
# Create sampler
sampler = NeighborSampler(g, [10,25],
dgl.distributed.sample_neighbors,
device)
dataloader = DistDataLoader(
dataset=train_nid.numpy(),
batch_size=batch_size,
collate_fn=sampler.sample_blocks,
shuffle=True,
drop_last=False)
# Define model and optimizer
model = SAGE(in_feats, num_hidden, n_classes, num_layers, F.relu, dropout)
model = th.nn.parallel.DistributedDataParallel(model)
loss_fcn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# training loop
for epoch in range(args.num_epochs):
for step, blocks in enumerate(dataloader):
batch_inputs, batch_labels = load_subtensor(g, blocks[0].srcdata[dgl.NID],
blocks[-1].dstdata[dgl.NID])
batch_pred = model(blocks, batch_inputs)
loss = loss_fcn(batch_pred, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
在计算机集群中运行训练脚本时,DGL提供了一些工具,可将数据复制到集群的计算机上并在所有计算机上启动培训作业。
注意:当前的分布式培训API仅支持Pytorch后端。
注意:当前实现仅支持具有一种节点类型和一种边缘类型的图形。
DGL实现了一些分布式组件以支持分布式培训。 下图显示了组件及其相互作用。
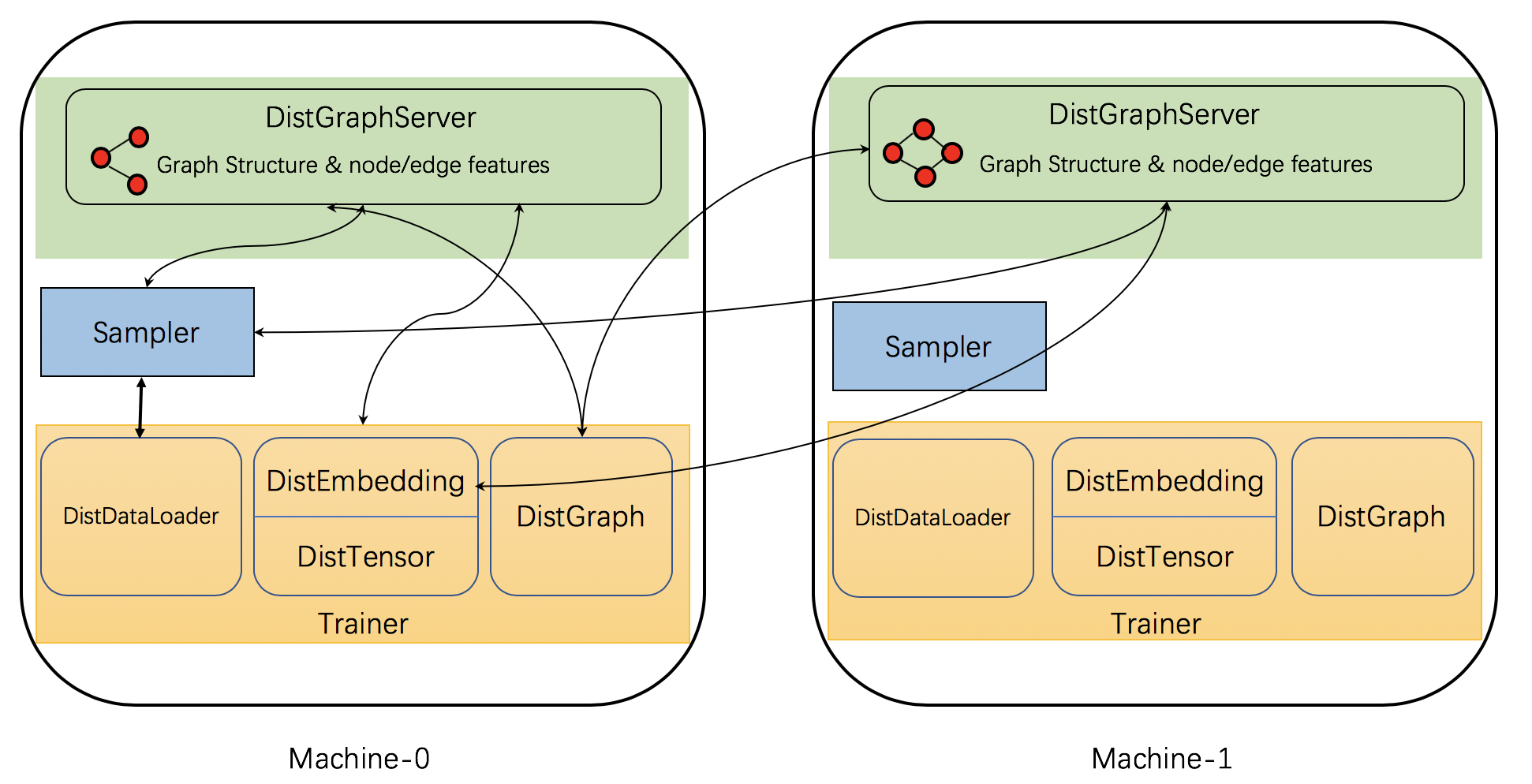
具体来说,DGL的分布式培训具有三种类型的交互过程:服务器,采样器和训练器。
-
服务器进程在存储图形分区(包括图形结构和节点/边缘功能)的每台计算机上运行。 这些服务器一起工作以将图形数据提供给培训师。 请注意,一台机器可以同时运行多个服务器进程,以并行化计算和网络通信。
-
采样器进程与服务器以及采样节点和边缘进行交互,以生成用于训练的迷你批次。
-
训练器包含多个与服务器交互的函数。 它具有
DistGraph来访问分区图形数据,并具有DistEmbedding和DistTensor来访问节点/边特征。 它具有DistDataLoader与采样器进行交互以获得mini-batch。
考虑到分布式组件,本节的其余部分将介绍以下分布式组件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号