Redis源码剖析之内存淘汰策略(Evict)
Redis作为一个成熟的数据存储中间件,它提供了完善的数据管理功能,比如之前我们提到过的数据过期和今天我们要讲的数据淘汰(evict)策略。在开始介绍Redis数据淘汰策略前,我先抛出几个问题,帮助大家更深刻理解Redis的数据淘汰策略。
- 何为数据淘汰,Redis有了数据过期策略为什么还要有数据淘汰策略?
- 淘汰哪些数据,有什么样的数据选取标准?
- Redis的数据淘汰策略是如何实现的?
何为Evict
我先来回答第一个问题,Redis中数据淘汰实际上是指的在内存空间不足时,清理掉某些数据以节省内存空间。 虽然Redis已经有了过期的策略,它可以清理掉有效期外的数据。但想象下这个场景,如果过期的数据被清理之后存储空间还是不够怎么办?是不是还可以再删除掉一部分数据? 在缓存这种场景下 这个问题的答案是可以,因为这个数据即便在Redis中找不到,也可以从被缓存的数据源中找到。所以在某些特定的业务场景下,我们是可以丢弃掉Redis中部分旧数据来给新数据腾出空间。
如何Evict
第二个问题,既然我们需要有淘汰的机制,你们在具体执行时要选哪些数据淘汰掉?具体策略有很多种,但思路只有一个,那就是总价值最大化。我们生在一个不公平的世界里,同样数据也是,那么多数据里必然不是所有数据的价值都是一样的。所以我们在淘汰数据时只需要选择那些低价值的淘汰即可。
所以问题又来了,哪些数据是低价值的?这里不得不提到一个贯穿计算机学科的原理局部性原理,这里可以明确告诉你,局部性原理在缓存场景有这样两种现象,1. 最新的数据下次被访问的概率越高。 2. 被访问次数越多的数据下次被访问的概率越高。 这里我们可以简单认为被访问的概率越高价值越大。基于上述两种现象,我们可以指定出两种策略 1. 淘汰掉最早未被访问的数据。2. 淘汰掉访被访问频次最低的数据,这两种策略分别有个洋气的英文名LRU(Least Recently Used)和LFU(Least Frequently Used)。
Redis中的Evict策略
除了LRU和LFU之外,还可以随机淘汰。这就是将数据一视同仁,随机选取一部分淘汰。实际上Redis实现了以上3中策略,你使用时可以根据具体的数据配置某个淘汰策略。除了上述三种策略外,Redis还为由过期时间的数据提供了按TTL淘汰的策略,其实就是淘汰剩余TTL中最小的数据。另外需要注意的是Redis的淘汰策略可以配置在全局或者是有过期时间的数据上,所以Redis共计以下8中配置策略。
| 配置项 | 具体含义 |
|---|---|
| MAXMEMORY_VOLATILE_LRU | 仅在有过期时间的数据上执行LRU |
| MAXMEMORY_VOLATILE_LFU | 仅在有过期时间的数据上执行LFU |
| MAXMEMORY_VOLATILE_TTL | 在有过期时间的数据上按TTL长度淘汰 |
| MAXMEMORY_VOLATILE_RANDOM | 仅在有过期时间的数据上随机淘汰 |
| MAXMEMORY_ALLKEYS_LRU | 在全局数据上执行LRU |
| MAXMEMORY_ALLKEYS_LFU | 在全局数据上执行LFU |
| MAXMEMORY_ALLKEYS_RANDOM | 在全局数据上随机淘汰 |
| MAXMEMORY_NO_EVICTION | 不淘汰数,当内存空间满时插入数据会报错 |
源码剖析
接下来我们就从源码来看下Redis是如何实现以上几种策略的,MAXMEMORY_VOLATILE_和MAXMEMORY_ALLKEYS_策略实现是一样的,只是作用在不同的dict上而已。另外Random的策略也比较简单,这里就不再详解了,我们重点看下LRU和LFU。
LRU具体实现
LRU的本质是淘汰最久没被访问的数据,有种实现方式是用链表的方式实现,如果数据被访问了就把它移到链表头部,那么链尾一定是最久未访问的数据,但是单链表的查询时间复杂度是O(n),所以一般会用hash表来加快查询数据,比如Java中LinkedHashMap就是这么实现的。但Redis并没有采用这种策略,Redis就是单纯记录了每个Key最近一次的访问时间戳,通过时间戳排序的方式来选找出最早的数据,当然如果把所有的数据都排序一遍,未免也太慢了,所以Redis是每次选一批数据,然后从这批数据执行淘汰策略。这样的好处就是性能高,坏处就是不一定是全局最优,只是达到局部最优。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
LRU信息如何存的? 在之前介绍redisObject的文章中 我们已提到过了,在redisObject中有个24位的lru字段,这24位保存了数据访问的时间戳(秒),当然24位无法保存完整的unix时间戳,不到200天就会有一个轮回,当然这已经足够了。
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK(); // 这里更新LRU时间戳
}
}
return val;
} else {
return NULL;
}
}
LFU具体实现
lru这个字段也会被lfu用到,所以你在上面lookupkey中可以看到在使用lfu策略是也会更新lru。Redis中lfu的出现稍晚一些,是在Redis 4.0才被引入的,所以这里复用了lru字段。 lru的实现思路只有一种,就是记录下key被访问的次数。但实现lru有个问题需要考虑到,虽然LFU是按访问频次来淘汰数据,但在Redis中随时可能有新数据就来,本身老数据可能有更多次的访问,新数据当前被访问次数少,并不意味着未来被访问的次数会少,如果不考虑到这点,新数据可能一就来就会被淘汰掉,这显然是不合理的。
Redis为了解决上述问题,将24位被分成了两部分,高16位的时间戳(分钟级),低8位的计数器。每个新数据计数器初始有一定值,这样才能保证它能走出新手村,然后计数值会随着时间推移衰减,这样可以保证老的但当前不常用的数据才有机会被淘汰掉,我们来看下具体实现代码。
LFU计数器增长
计数器只有8个二进制位,充其量数到255,怎么会够? 当然Redis使用的不是精确计数,而是近似计数。具体实现就是counter概率性增长,counter的值越大增长速度越慢,具体增长逻辑如下:
/* 更新lfu的counter,counter并不是一个准确的数值,而是概率增长,counter的数值越大其增长速度越慢
* 只能反映出某个时间窗口的热度,无法反映出具体访问次数 */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL; // LFU_INIT_VAL为5
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1); // server.lfu_log_factor可配置,默认是10
if (r < p) counter++;
return counter;
}
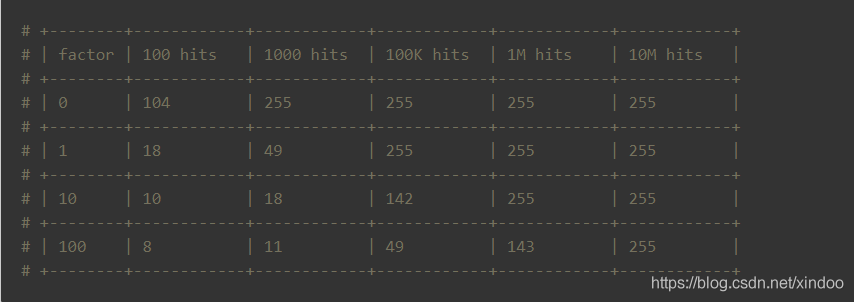
从代码逻辑中可以看出,counter的值越大,增长速度会越慢,所以lfu_log_factor配置较大的情况下,即便是8位有可以存储很大的访问量。下图是不同lfu_log_factor在不同访问频次下的增长情况,图片来自Redis4.0之基于LFU的热点key发现机制。
LFU计数器衰减
如果说counter一直增长,即便增长速度很慢也有一天会增长到最大值255,最终导致无法做数据的筛选,所以要给它加一个衰减策略,思路就是counter随时间增长衰减,具体代码如下:
/* lfu counter衰减逻辑, lfu_decay_time是指多久counter衰减1,比如lfu_decay_time == 10
* 表示每10分钟counter衰减一,但lfu_decay_time为0时counter不衰减 */
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
server.lfu_decay_time也是可配置的,默认是10 标识每10分钟counter值减去1。
evict执行过程
evict何时执行
在Redis每次处理命令的时候,都会检查内存空间,并尝试去执行evict,因为有些情况下不需要执行evict,这个可以从isSafeToPerformEvictions中可以看出端倪。
static int isSafeToPerformEvictions(void) {
/* 没有lua脚本执行超时,也没有在做数据超时 */
if (server.lua_timedout || server.loading) return 0;
/* 只有master才需要做evict */
if (server.masterhost && server.repl_slave_ignore_maxmemory) return 0;
/* 当客户端暂停时,不需要evict,因为数据是不会变化的 */
if (checkClientPauseTimeoutAndReturnIfPaused()) return 0;
return 1;
}
evict.c
evict代码都在evict.c中。里面包含了每次evict的执行过程。
int performEvictions(void) {
if (!isSafeToPerformEvictions()) return EVICT_OK;
int keys_freed = 0;
size_t mem_reported, mem_tofree;
long long mem_freed; /* May be negative */
mstime_t latency, eviction_latency;
long long delta;
int slaves = listLength(server.slaves);
int result = EVICT_FAIL;
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return EVICT_OK;
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
return EVICT_FAIL; /* We need to free memory, but policy forbids. */
unsigned long eviction_time_limit_us = evictionTimeLimitUs();
mem_freed = 0;
latencyStartMonitor(latency);
monotime evictionTimer;
elapsedStart(&evictionTimer);
while (mem_freed < (long long)mem_tofree) {
int j, k, i;
static unsigned int next_db = 0;
sds bestkey = NULL;
int bestdbid;
redisDb *db;
dict *dict;
dictEntry *de;
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
{
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL) {
unsigned long total_keys = 0, keys;
/* We don't want to make local-db choices when expiring keys,
* so to start populate the eviction pool sampling keys from
* every DB.
* 先从dict中采样key并放到pool中 */
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
if (!total_keys) break; /* No keys to evict. */
/* 从pool中选择最适合淘汰的key. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict,
pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires,
pool[k].key);
}
/* 从淘汰池中移除. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... Iterate again. */
}
}
}
}
/* volatile-random and allkeys-random 策略 */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
{
/* 当随机淘汰时,我们用静态变量next_db来存储当前执行到哪个db了*/
for (i = 0; i < server.dbnum; i++) {
j = (++next_db) % server.dbnum;
db = server.db+j;
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?
db->dict : db->expires;
if (dictSize(dict) != 0) {
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
}
}
}
/* 从dict中移除被选中的key. */
if (bestkey) {
db = server.db+bestdbid;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
/*我们单独计算db*Delete()释放的内存量。实际上,在AOF和副本传播所需的内存可能大于我们正在释放的内存(删除key)
,如果我们考虑这点的话会很绕。由signalModifiedKey生成的CSC失效消息也是这样。
因为AOF和输出缓冲区内存最终会被释放,所以我们只需要关心key空间使用的内存即可。*/
delta = (long long) zmalloc_used_memory();
latencyStartMonitor(eviction_latency);
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
latencyEndMonitor(eviction_latency);
latencyAddSampleIfNeeded("eviction-del",eviction_latency);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
signalModifiedKey(NULL,db,keyobj);
notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted",
keyobj, db->id);
decrRefCount(keyobj);
keys_freed++;
if (keys_freed % 16 == 0) {
/*当要释放的内存开始足够大时,我们可能会在这里花费太多时间,不可能足够快地将数据传送到副本,因此我们会在循环中强制传输。*/
if (slaves) flushSlavesOutputBuffers();
/*通常我们的停止条件是释放一个固定的,预先计算的内存量。但是,当我们*在另一个线程中删除对象时,
最好不时*检查是否已经达到目标*内存,因为“mem\u freed”量只在dbAsyncDelete()调用中*计算,
而线程可以*一直释放内存。*/
if (server.lazyfree_lazy_eviction) {
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
break;
}
}
/*一段时间后,尽早退出循环-即使尚未达到内存限制*。如果我们突然需要释放大量的内存,不要在这里花太多时间。*/
if (elapsedUs(evictionTimer) > eviction_time_limit_us) {
// We still need to free memory - start eviction timer proc
if (!isEvictionProcRunning) {
isEvictionProcRunning = 1;
aeCreateTimeEvent(server.el, 0,
evictionTimeProc, NULL, NULL);
}
break;
}
}
} else {
goto cant_free; /* nothing to free... */
}
}
/* at this point, the memory is OK, or we have reached the time limit */
result = (isEvictionProcRunning) ? EVICT_RUNNING : EVICT_OK;
cant_free:
if (result == EVICT_FAIL) {
/* At this point, we have run out of evictable items. It's possible
* that some items are being freed in the lazyfree thread. Perform a
* short wait here if such jobs exist, but don't wait long. */
if (bioPendingJobsOfType(BIO_LAZY_FREE)) {
usleep(eviction_time_limit_us);
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
result = EVICT_OK;
}
}
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return result;
}
执行的过程可以简单分为三步,首先按不同的配置策略填充evictionPoolEntry,pool大小默认是16,然后从这16个key中根据具体策略选出最适合被删掉的key(bestkey),然后执行bestkey的删除和一些后续逻辑。
总结
可以看出,Redis为了性能,牺牲了LRU和LFU的准确性,只能说是近似LRU和LFU,但在实际使用过程中也完全足够了,毕竟Redis这么多年也是经历了无数项目的考验依旧屹立不倒。Redis的这种设计方案也给我们软件设计时提供了一条新的思路,牺牲精确度来换取性能。
本文是Redis源码剖析系列博文,同时也有与之对应的Redis中文注释版,有想深入学习Redis的同学,欢迎star和关注。
Redis中文注解版仓库:https://github.com/xindoo/Redis
Redis源码剖析专栏:https://zxs.io/s/1h
如果觉得本文对你有用,欢迎一键三连。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号