
3.浏览器及工作方式
浏览器及工作方式
1.我们将会讨论的浏览器
Internet Explorer, Firefox, Safari, Chrome Opera,

我将会解释一些半开源的浏览器的工作方式:
Firefox(火狐),Chrome(谷歌) Safari(苹果)。根据 W3C 的统计,这3中浏览器的使用已经接近 60% 浏览器的主要功能: 浏览器的主要功能是呈现你选择的资源内容,从服务器获取资源并展现在浏览器中。 资源的主要形式是HTML, 或者 PDF , 图片或者其他的。客户使用URI找到这些资源。 浏览器按照W3C的规范解析HTML和CSS。但浏览器厂商仅仅实现了规范的一部分并增加了他们自己的扩展,这为开发者们造成了不少的麻烦,但如今,大部分的浏览器厂商都会或多或少的遵守W3C的规范。
浏览器的UI非常相似,大多都有如下功能: 地址栏用于URI的输入 前进和后退按钮 书签 刷新或停止加载 回到首页按钮 这非常奇怪,因为浏览器的UI并不是规范的一部分,这是经年累月的用户实践造成的相似。H5 的标准并没有定义浏览器必须要有哪些UI元素,但列出了一些常用的UI元素:地址栏、状态栏和工具栏。当然,也有一些比较特殊的功能比如Firefox的下载管理功能
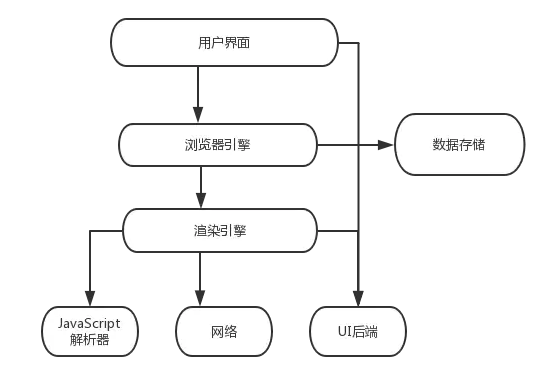
2.浏览器的主要结构:
UI。包括地址栏、前进后退按钮、书签管理器等等,除了你用来看请求资源的窗口以外的其他,都算是浏览器的UI。 browser engine 。 用于查询和操作渲染引擎。 rendering engine. rendering engine。 负责展示资源。 比如如果请求了HTML, 它将会负责将HTML 、CSS编译和展现在屏幕上。 Networking。 用于处理网络请求。是一个独立的部分。 UI backend。 用于绘制一些基础组件,例如组合框和窗口。暴露了一些非特定平台使用的通用接口,内部使用了操作系统的一些接口和方法。 JavaScript interpreter. 用于解释执行JS 。 Data storage. 用于持久化数据的层,一些需要储存到硬盘的数据,例如 cookies 。 是一个浏览器上的小型数据库。和所有其他浏览器不同,Chrome 拥有 多个渲染引擎实例 - 每个标签页都有一个实例。每个选项卡是一个单独的过程 以下将会详述各个部分。
就是以下流程了:
渲染引擎从解析HTML并将标签转译成DOM节点开始,这种节点树通常被叫做 "content tree"(内容树)。 它会解析无论是内连还是外链样式文件。样式信息同HTML的架构信息将会建立一种新的树形系统,'render tree' (渲染树)。 'render tree' (渲染树)包含许许多多的带视觉信息的矩形,这些视觉信息包括颜色、大小等等。然后这些矩形将会以一定的顺序被呈现在屏幕上。在'render tree' (渲染树)建造完成后,将会进行一个叫 'layout' 的过程。这个过程将会给每个node节点详细的坐标。下一步是 'painting' ,'render tree' (渲染树)将会与节点穿插然后使用UI backend层渲染。 非常重要的是这个过程是逐步推进的。为了更好的用户体验,渲染引擎尝试尽快地渲染内容。所以它不会等待所有HTML文件被解析就开始着手搭建layout和渲染树。剩余的内容持续不断的从互联网获得,与此同时部分内容已经被转译并展现在页面上。
Figure 3: Webkit main flow
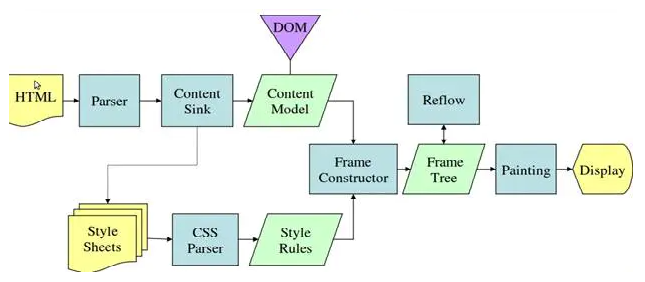
Figure 4: Mozilla's Gecko rendering engine main flow
从上述两张图片可以看出,Webkit 和 Gecko 用了稍微不同的术语,但主要流程是基本相似的。 Gecko 将视觉上格式化的元素集合叫做 ‘Frame tree’(框架树),每一个元素都是一个框架。Webkit 叫它 render tree, render tree 中的每一个元素都是一个 ‘ render objects'. webkit 将放置元素到相应地点的过程叫做 ' layout ' 而 Gecko 叫他叫做 'reflow' 。Webkit 将链接DOM节点和视觉信息用于构建render tree 的过程叫做 'Attachment'. 还有一个叫法的小不同在 Gecko 在HTML和DOM树之间有一个附加的层 ‘content sink’, 它实际上是一个制作DOM 元素的工厂。我们下面对每一个部分进行详细叙述
3.Parsing -通用
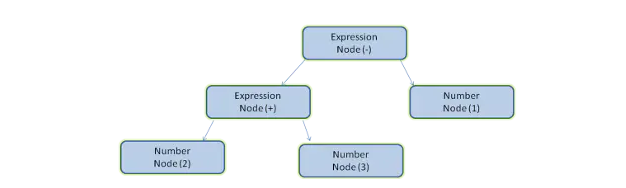
由于解析HTML这个过程在渲染中是非常重要的,我们稍微深入一些。下面稍微介绍一下什么是解析。 解析是将一个文档转译成程序可以理解的某种结构,他的结果通常是代表了文档结构的节点树(Node tree),我们叫他 解析树或语法树(parse tree or a syntax tree) 例如, 解析"2 + 3 - 1"将会返回:
Grammars - 语法 解析文档依靠确定的词汇和句法规则,这叫做上下文无关语法。人类的语言不符合这种可译的结构所以无法被这种技术解析。 Parser - 语法分析程序 解析分为两部分:句法分析和词法分析。 词法分析是将输入变成记号的过程。这些记号是一种有效集合,就像人类语言的字典一样。 句法分析就是应用语言的句法规则。 解析器通常分为两个部分,词法分析器和解析器。词法分析器将输入的内容符号化,解析器依照语言句法规范分析文档来建立解析树(parse tree)词法分析器知道怎么跳过无关紧要的东西比如恐吓和换行。
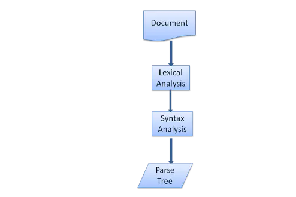
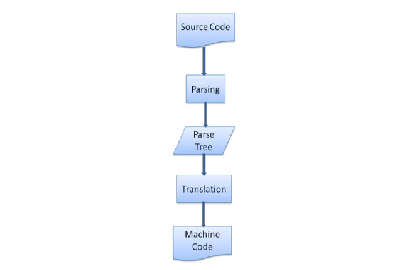
Figure 6: from source document to parse trees 解析过程是迭代进行的。解析器项词法分析器要来新的需要分析的项(token)然后尝试用它来匹配句法规则,如果符合了,一个新节点就会产生并悬挂到解析树上,然后解析器会去要下一个需要分析的项。 如果有一个项没有规则可以匹配,解析器会将这个项储存在内部,然后继续下一个项一直到某一个规则可以适用内部储存的项。如果没有可适用的项,那么解析器将会抛出一个语法错误(syntax errors) Translation 大多时候解析树并不是最后的产物,解析常常用于将某种语言转换为另一种格式,比如汇编。编译器将远吗先解析成解析树而后转译成汇编语言。
Figure 7: compilation flow
一个解析的例子: 如图5所示,我们建立了一颗解析树,我们尝试定义一种简单的数学语言然后看看解析的过程。 词汇表: 数字、加号、减号 句法: 构建块为表达式、项和操作符。 表达式中可包含任何数字。 一个表达式的定义形如:项 操作符 项 操作符是指加号和减号 项 是指一个数字或者一个表达式 由此,我们可以分析 "2 + 3 - 1" 第一个符合规则的是 '2', 根据句法规则5,它是一个项。而后符合规则的是 "2+3", 它符合句法规则2. 而后符合规则的是 "2 + 3 - 1",因为它也符合规则5, 因为 “2+3”是一个项。而 "2 + + "是不符合上述任何一个条件的,所以是一个无效的输入。
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步