

Hadoop2.7.4 在 Windows 10(64位) 详细配置
网上查询资料,实际配置后整理记录。
一、下载安装配置 1.8.0 以上版本 java 环境
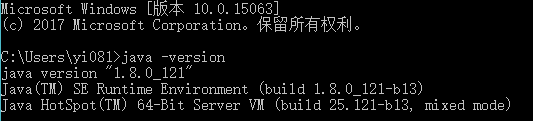
完成后,使用 java -version 命令查看是否成功。
二、下载 hadoop-2.7.4.tar.gz
地址:http://hadoop.apache.org/releases.html

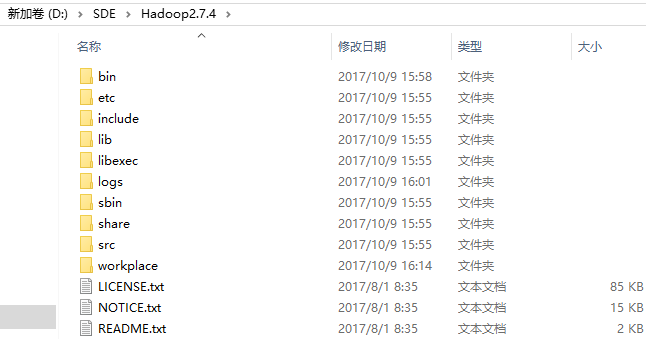
将文件解压至无空格目录下即可,下面是目录结构:
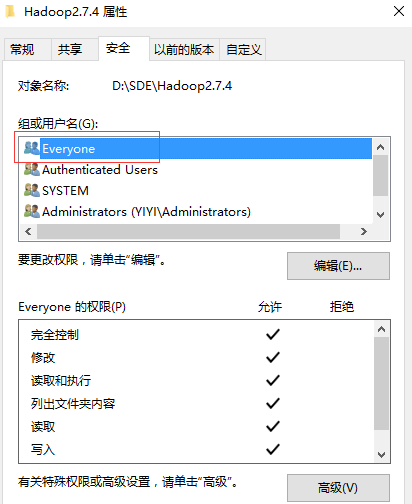
文件夹访问权限修改,添加(Everyone)完全控制权限
三、下载 Hadoop 2.7.4 Windows 64位 编译bin
网上提供的下载地址:http://download.csdn.net/download/a2728196/9966285
将压缩包里的 bin 目录下文件替换官网 hadoop 目录下的 bin 目录。
四、配置所需系统环境变量
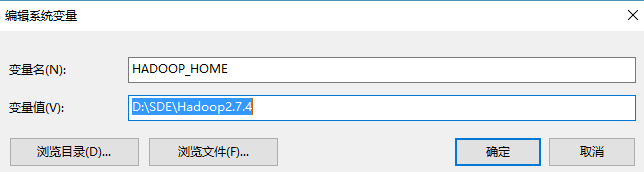
1、新建 HADOOP_HOME,如下图 :
2、Path 变量中 新建,如下图:

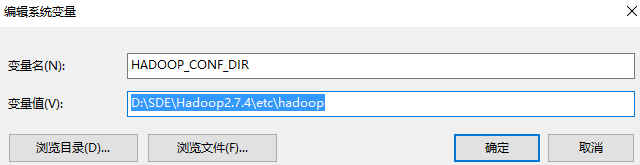
3、新建 HADOOP_CONF_DIR,如下图 :
4、测试是否配置成功
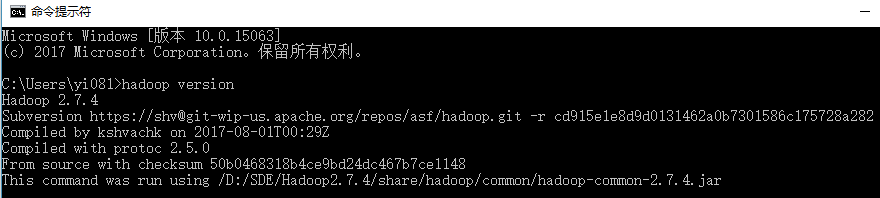
打开 cmd 窗口,执行 hadoop version,如下图:
五、修改 Hadoop 配置文件(namenode,datanode运行读取)
注意:
配置文件里windows所有盘符前要加/,比如: /D:/XXXXXXXXXX
编辑“ D:\SDE\Hadoop2.7.4\etc\hadoop ”下的配置文件,参考配置如下:
1、core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--指定namenode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:8010</value> <description>HDFS的URI,文件系统://namenode标识:端口号</description> </property> <!--用来指定使用hadoop时产生文件的存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/D:/SDE/Hadoop2.7.4/workplace/tmp</value> <description>namenode上本地的hadoop临时文件夹</description> </property> </configuration>
2、hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--指定hdfs保存数据的副本数量--> <property> <name>dfs.replication</name> <value>1</value> <description>副本个数,配置默认是3,应小于datanode机器数量</description> </property> <property> <name>dfs.name.dir</name> <value>/D:/SDE/Hadoop2.7.4/workplace/name</value> <description>namenode上存储hdfs名字空间元数据 </description> </property> <property> <name>dfs.data.dir</name> <value>/D:/SDE/Hadoop2.7.4/workplace/data</value> <description>datanode上数据块的物理存储位置</description> </property> </configuration>
3、mapred-site.xml:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--告诉hadoop以后MR运行在YARN上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4、yarn-site.xml
<?xml version="1.0"?> <configuration> <!--nomenodeManager获取数据的方式是shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定Yarn的老大(ResourceManager)的地址--> <!--****************--> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> </configuration>
六、启动
1、cmd 执行 hdfs namenode -format 指令格式化系统文件。
2、格式化完成后,到 hadoop/sbin 目录下执行 start-dfs 或 start-all 指令,启动hadoop
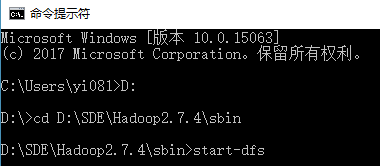
使用 start-dfs 会启动 namenode 和 datanode 进程,如下图:
使用 start-yarn 会启动 resourcemanager 和 nodemanager 进程,如下图:
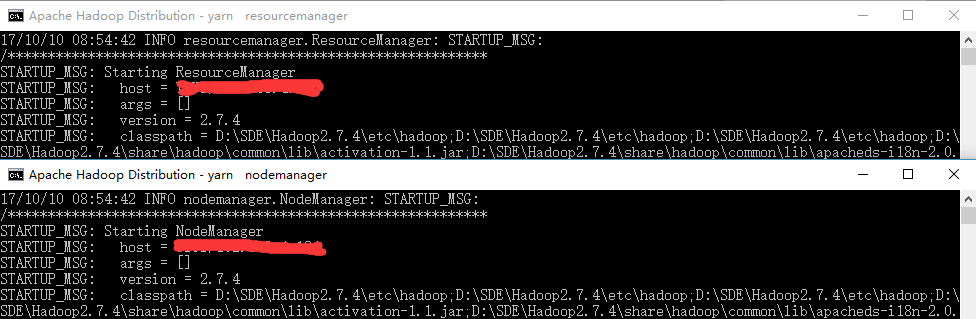
使用 start-all 会启动全部 4 个进程,如下图:
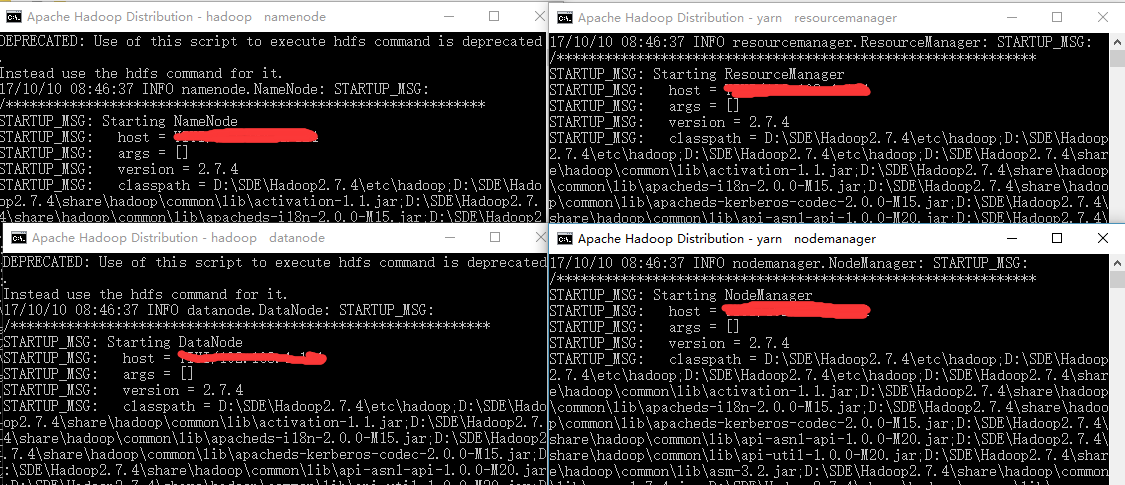
注意:This script is Deprecated(弃用). Instead use start-dfs.cmd and start-yarn.cmd starting yarn daemons
3、访问:http://localhost:50070,如图:
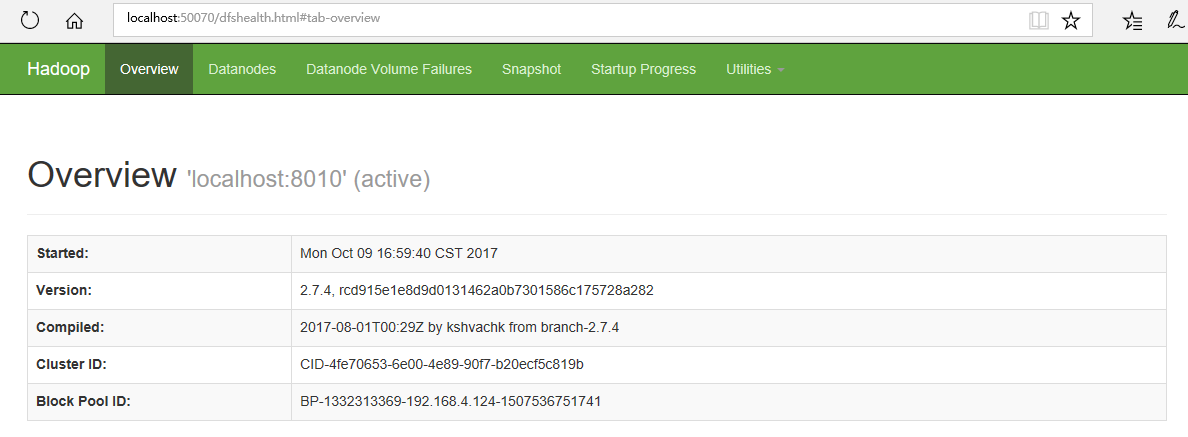
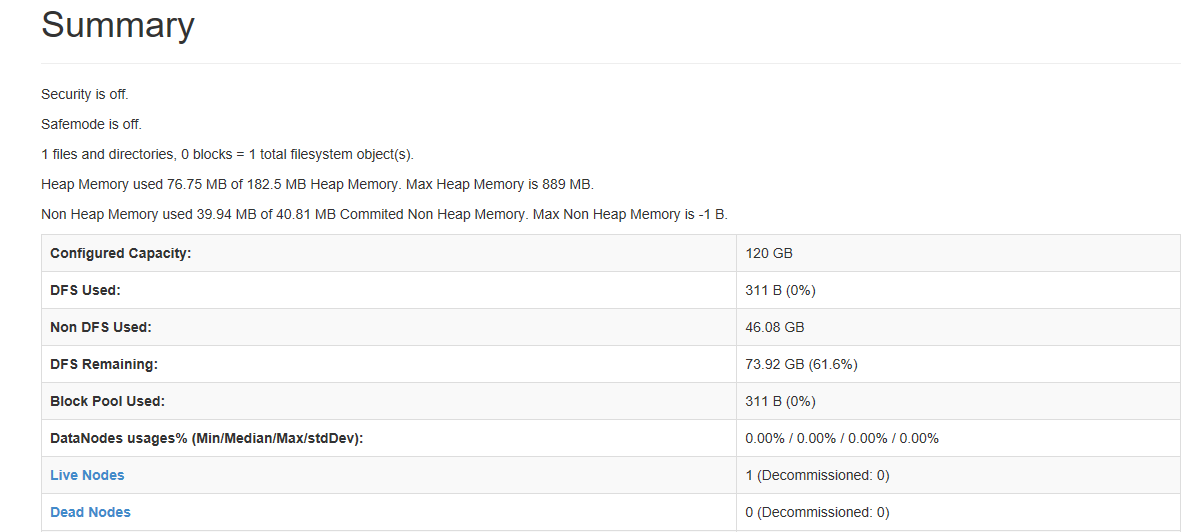
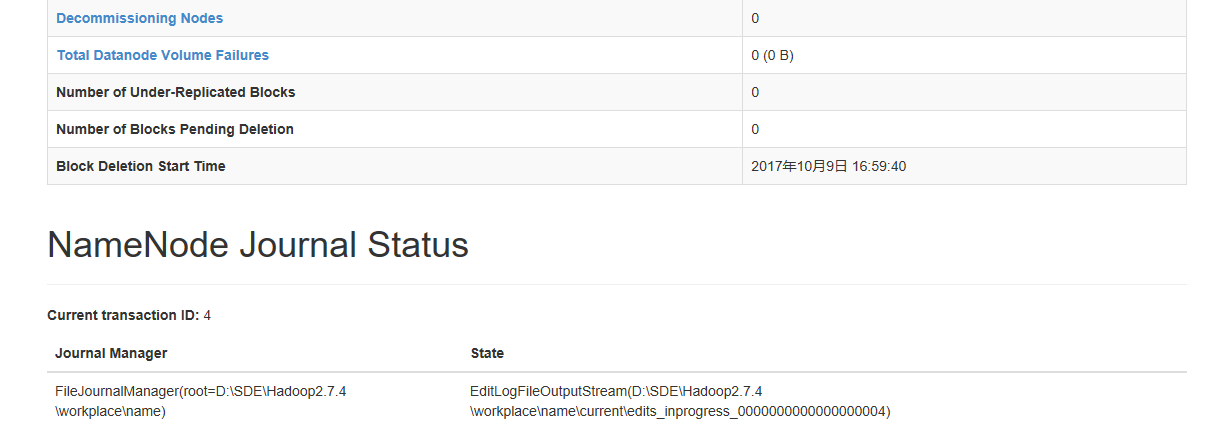
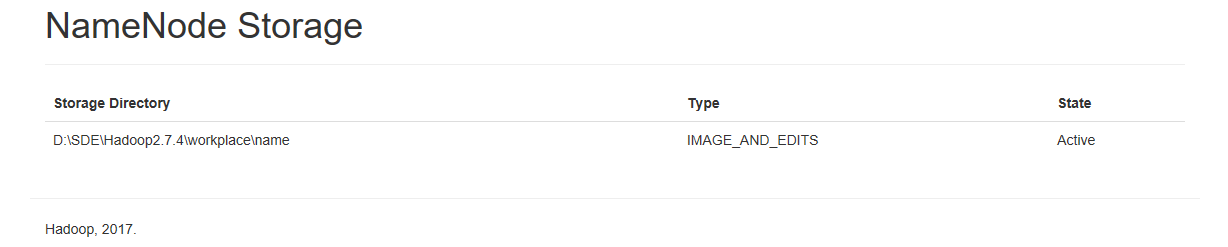
至此,hadoop 服务搭建完毕。

