
目标检测论文解读10——DSSD
背景
SSD算法在检测小目标时精度并不高,本文是在在SSD的基础上做出一些改进,引入卷积层,能综合上下文信息,提高模型性能。
理解
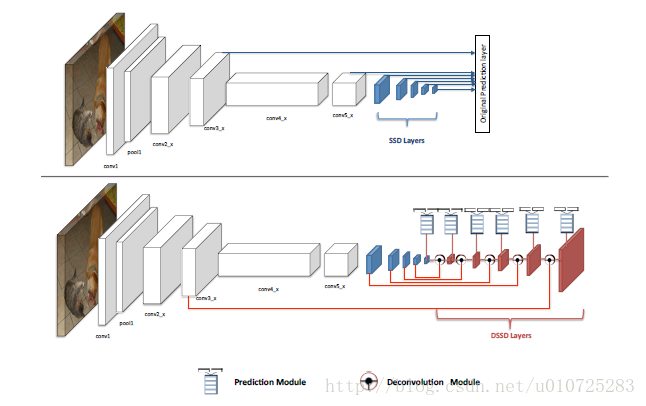
Q1:DSSD和SSD的区别有哪些?
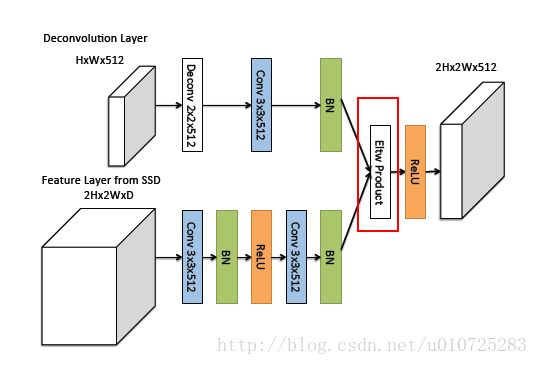
(1)SSD是一层一层下采样,然后分别在这些feature map上进行预测;而DSSD则是在后面加入了很多的Deconvolution Module,通过逆卷积算法feature map上采样,然后与前面的feature map通过点积产生新的feature map,包含上下文的信息。
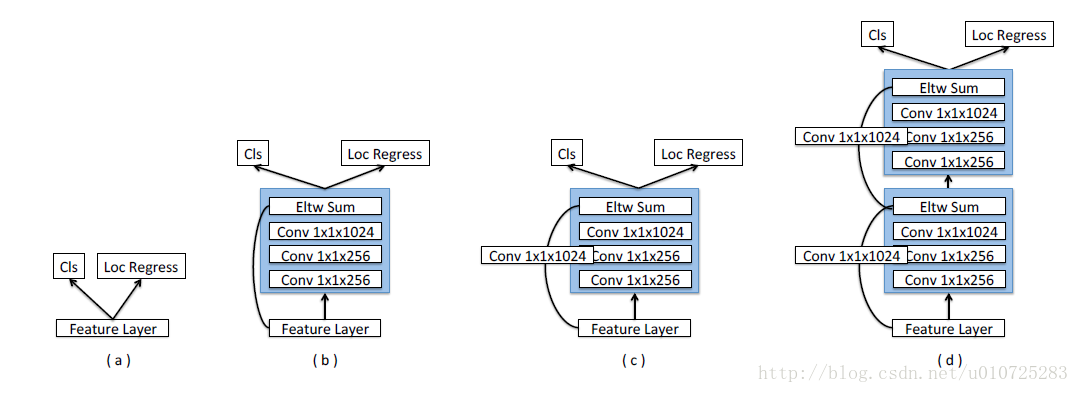
(2)除了逆卷积操作,DSSD还引入了新的Prediction Module,如下图,可以看到主要使用的还是ResNet的short cut思想。
Q2:为什么加入了Deconv层就能提高模型在小目标检测上的精度呢?
首先,我们都知道,随着Conv层加深,越往后feature map的分辨率越小,同时包含的语义信息越高。而小目标是在浅层检测的,因此feature map语义信息弱,分类不准也是正常的;
而文中通过Deconv层,将深层强语义的feature map放大,与浅层feature map结合,产生的新feature map语义也比浅层的强,分类自然更准一些。
总结
DSSD=Deconv+Predict Module+SSD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号