
游戏编程模式-空间分区
写在前面
“将对象存储在根据位置组织的数据结构中来高效的定位它们。”
动机
游戏使我们能够探寻其它世界,但这些世界和我们的世界往往并无太大差异。其中的基本物理规则和确切性常常与我们的世界互通。这也正是这些由像素构成的世界看上去如此真实的原因。
我们在者虚拟现实中将要关注的一点就是位置。游戏世界具有空间感,对象则分布于空间中,这一点从多方面展现出了游戏世界:一个明显的粒子就是物理——对象的移动、碰撞和相互影响。但也有其它例子。比如音频引擎会考虑声源和角色的相对位置,因而更远的声音要相对安静点。在线聊天可能被限制在附近的玩家之间。
这意味者你的游戏引擎通常要解决这个问题:“对象的附近由什么物体?”。如果在每一帧中它不得不对此进行反复检测的话,那么它很容易成为性能的瓶颈。
战场上的部队
设想你在开发一个即时战略游戏。对立的阵营的上百个单位将在战场中厮杀,勇士们需要知道攻击那个最近的哪个敌人,最简单的方式就是查看每一对敌人的距离的远近:

void handleMelee(Unit* units[],int numUnits) { for(int i=0;i<numUnits-1;++i) { for(int j=i+1;j<numUnits;++j) { if(units[a]->postion() == units[b]->postion()) { handleAttack(units[i],units[j]); } } } }
这里我们使用了一个双重循环,也就是算法的复杂度为O(n^2),其中n表示战场单位数量。这对于我们来说并不是一个很好的处理方式,一旦战场中单位的数量增加,这个地方很容易成为性能的瓶颈。
绘制战场线
我们所处的困境在于单位数组无秩序可循。为了找到某个位置附近的单位,我们需要遍历全部数组。现在我们把它简化一下,我们将战场想象成一个一维的战场线,而不是二维的战场。如图:
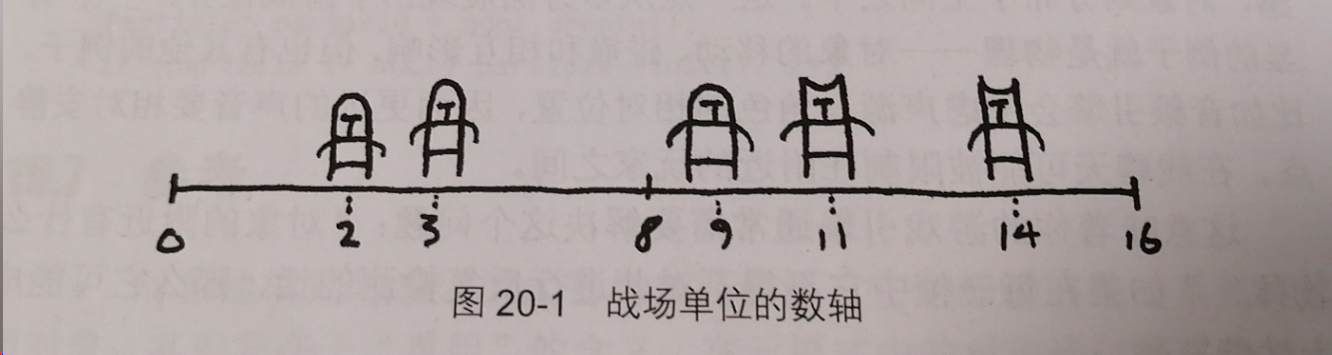
在这种情况下,我们将战场上单位按其位置排序,那么我们想找某个位置最近的单位时就可以使用二分查找法,这样复杂度就变成了O(lgn),这样就不要遍历整个数组了。鉴于此,我们可以把这种想法应用到1维以上的空间。
空间分区模式
对于一组对象而言,每一个对象在空间中都有一个位置。将对象存储在一个根据对象的位置来组织的数据结构中,该数据结构可以让你高效的查询位于或靠近某处的对象。当对象位置变化时,应该更新空间数据结构以便可以继续这样查找对象。
使用情境
这是一个用来存储活跃的、移动的游戏对象以及静态图像和游戏世界的几何形状等对等的常见模式。复杂的游戏常常有多个空间分区来应对不同类型的存储内容。
该模式的基本要求是你有一组对象,每个对象都具备某种位置信息,而你因为要根据位置做大量的查询来查找对象从而遇到了性能问题。
使用须知
空间分区将O(n)或者O(n^2) 复杂度的操作拆解为更易于管理的结构。对象越多,模式的价值就越大。相反,如果你的对象并不多,则可能不值得使用这个模式。
由于该模式要根据对象的位置来组织对象,故对象的位置改变就变得难以处理了。你必须重新组织数据结构来跟踪物体的新位置,这会增加代码的复杂性和额外的CPU周期开销。你必须确保这么做是值得的。
空间分区会使用额外的内存来保存数据结构。就像许多的优化一样,它是以空间换取速度的。如果你的内存比时钟周期更吃紧的话,这可能就得不偿失了。
示例代码
模式的本质在于它们的变化性——每一个实现都有所不同,当然本模式也不例外。虽然它不像其它的模式那样为各种变化都配备了丰富的文档。学术界喜欢发表论文来证明模式在性能上的提升空间。因为我们只关心模式背后的概念,所以我只提供最简单的一个空间分区:一个固定的网格。
一张方格纸
我们把战场的整个区域设想为一个矩形,然后把这个矩形等分为m*n块小的矩形区域,就像一张方格纸。其中网格中的每一个单元取代一维数组来存储对象。如图:
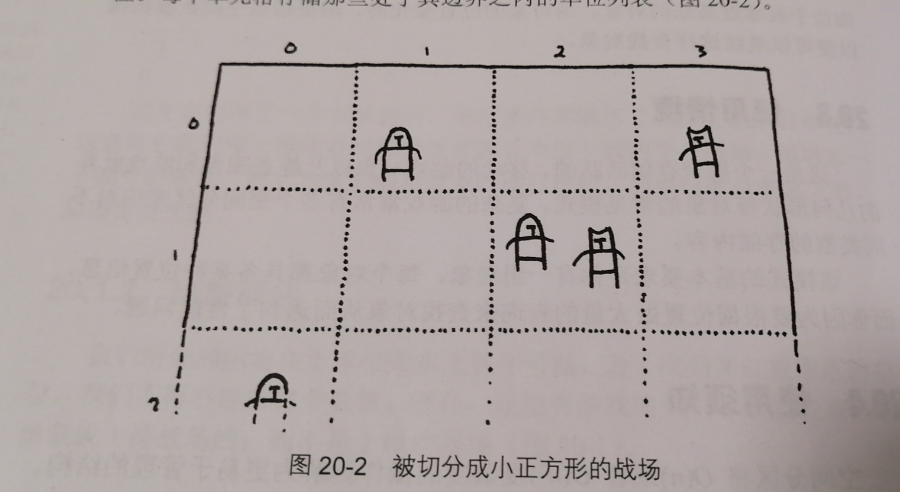
我们在处理战斗的时候,只考虑同一个单元格内的单位。我们不会将每个单位与游戏中其它单位一一比较,取而代之的是,我们已经将战场划分为一堆更小的战场,每一个战场里的单位要少很多。
相连单位的网格
首先我们做些准备工作。下面是Unit类:
class Unit { friend class Grid; public: Unit(Grid* grid,double x, double y): grid_(grid), x_(x), y_(y) {} void move(double x, double y); private: double x_,y_; Grid* grid_; };
每一个单元都有一个位置和一个指向其所处的Grid指针。我们将Grid作为友元类,就像我们看到的,当一个单位的位置发生改变时,我们不得不对网格进行处理确保一切都正常的更新。
下面是Grid类的大体实现:
class Grid { public: Grid() { //clear grid for(int x=0;x<NUM_CELLS;++x) { for(int y=0;y<NUM_CELLS;++y) { cells_[x][y] = NULL; } } } static const int NUM_CELLS = 10; static const int CELL_SIZE = 20; private: Unit* cells_[NUM_CELLS][NUM_CELLS]; };
注意到每一个单元格都有一个指向grid的指针,下面我们将用next和prev的指针来扩展Unit:
class Unit { //previous code... private: Unit* prev_; Unit* next_; };
这样我们就能够用一个双重链表来组织Unity以取代数组。网格中的每个单元格都会指向单元格之内的Units列表的第一个Unit。
进入战场
我们需要做的第一件事就是确保单位被创建时就被置入网格中。我们需要在Unit类的构造函数中处理:
Unit::Unit(Grid* grid,double x,double y) :grid_(grid), x_(x), y_(y), prev_(NULL), next_(NULL) { grid_->add(this); }
add方法实现如下:
void Grid::add(Unit* unit) { //Determine which grid cell it's in. int cellX = (int)(unit->x_/Grid::CELL_SIZE); int cellY = (int)(unit->y_/Grid::CELL_SIZE); //add to the front of list for the cell it's in. unit->prev_ = NULL; unit->next_ = cells_[cellX][cellY]; cells_[cellX][cellY] = unit; if(unit->next_ != NULL) { unit->next_->prev_ = unit; } }
代码很简单,就是一个双向链表添加节点的逻辑,每次把新的节点添加到链表的前面。
刀光剑影的战斗
当所有单位都被置入网格中后,我们便让它们相互攻击。在Grid类中,处理战斗函数如下:
void Grid::handleMelee() { for(int x=0;x<NUM_CELLS;++i) { for(int y=0;y<NUM_CELLS;++j) { handleCell(cells_[x][y]; } } }
上面的方法遍历了每一个单元格,并且注意调用其handleCell()方法。正如你所见,我们确实已经将大战场切分成了一些孤立的小规模冲突。每个单元格处理战斗的函数如下;
void Grid::handleCell(Unit* unit) { while(unit != NULL) { Unit* other = unit->next_; while(other != NULL) { if(unit->x_ == other->x_ && unit->y_ == other->y_) { handleAttack(unit,other); } other = other->next_; } unit= unit->next_; } }
只是一个简单的链表遍历。至此,我们不需要遍历所有的代码,只要遍历单元格内的对象即可。
冲锋陷阵
我们已经解决了在同一个单元格内战斗的问题,但却有另一个问题:单位现在都呆在单元格里面,如果单位移动到了其它的单元格中该如何处理?这个时候我们需要额外的一些处理工作:把这个单位从原先的单元格中移出并加入到新的单元格中。
首先,我们在Unit类中添加一个方法来改变它的位置:
void Unit::move(double x, double y) { grid_->move(this,x,y); }
这段代码很简单,它把移动的控制权交给了Grid类,Grid类中的移动代码如下:
void Grid::move(Unit* unit,double x, double y) { //see which cell it was in. int oldCellX = (int)(unit->x_ / Grid::CELL_SIZE); int oldCellY = (int)(unit->y_ / Grid::CELL_SIZE); //see which cell it's moving to. int cellX = (int)(x / Grid::CELL_SIZE); int cellY = (int)(y / Grid::CELL_SIZE); unit->x_ = x; unit->y_ = y; //if don't change cell, we're done. if(oldCellX == cellX && oldCellY == cellY) return; //Unlink it from the list of its old cell. if(unit->prev_ != NULL) { unit->prev_->next_ = unit->next_; } if(unit->next_ != NULL) { unit->next_->prev_ = unit->prev_; } //if it's the head of a list,remove it if(cells_[oldCellX][oldCellY] == unit) { cells_[oldCellX][oldCellY] == unit->next_; } //Add it back to the grid at its new cell. add(unit); }
很简单的逻辑,首先判断是否移动到了新的单元格,如果是则在原先的单元格中删除它,同时加入到新的单元格中,否则不做任何处理。这里就体现了我们使用双向列表来组织对象的价值——非常方便的添加和移除对象。
近在咫尺,短兵相接
这个似乎看起来简单,但我们在某些地方作弊了。在例子中,当单位出现在完全相同的位置时才会相互作用。这对于跳棋和国际象棋时没问题的,但是对于更逼真的游戏来说就不适用了,那些游戏通常要考虑攻击距离。对于这个问题,我们可以简单的修改一下代码让模式仍然工作良好。
if(distance(unit,other) < ATTACK_DISTANCE) { handleAttack(unit,other); }
当进入攻击范围时,我们需要考虑到一种边界情况:不同单元格中的单位也可以足够靠近从而相互作用。比如单元格共享边附近的单位。鉴于此,我们不仅要比较单元格内的对象,也要考虑相邻单元格中的单位。我们可以如下做:
void Grid::handleUnit(Unit* unit,Unit* other) { while(other != NULL) { if(distance(unit,other) < ATTACK_DISTANCE) { handleAttack(unit,other); } other = other->next_; } } void Grid::handleCell(int x,int y) { Unit* unit=cells_[x][y]; while(unit != NULL) { //Handle other units in this cell。 handleUnit(unit,unit->next_); //also try the neighboring cells. if(x > 0) handleUnit(unit,cells_[x-1][y]); if(y > 0) handleUnit(unit,cells_[x-1][y]); if(x > 0 && y > 0) handleUnit(unit,cells_[x-1][y-1]); if(x > 0 && y < NUM_CELLS-1) handleUnit(unit,cells_[x-1][y+1]); unit = unit->next_; } }
我们把原先的循环拆开,在handlecell中处理单元格内的战斗和相邻的4个单元格之间的战斗。在handleUnit中,我们只查看了一半的相邻的单元格,这么做的原因时避免重复战斗。设想一下,每个单位都查看自己左右的单位,那么就会出现这样的情况:A查看右侧发现B并与之战斗,而B查看左侧也会发现A从而有发生一次战斗,很明显这两次战斗是重复的,只检查一侧则可以避免这个问题。
这里要注意的是当前我们假定攻击范围小于一个单元格,所以只需要遍历相邻的单元格,如果攻击范围很大,那么我们可能需要横跨好几行(列)去检查。
设计决策
关于明确定义的空间分区的数据结构可以列个简表,这里本可逐一探讨。但我试图根据它们的本质特征来组织。我希望一旦你接触到四叉树和二叉空间分割(BSP)之类时,这将有助于你了解它们的工作过程和原理,并在它们之间择优使用。
分区时层级还是扁平的
在网格例子中,我们将网格分成了一个单一扁平的单元格集合。于此相反,层级空间分区是将空间分成几个区域。然后,如果这些区域中仍然包含着许多对象,就会继续划分。这个递归的过程持续到每个区域的对象数目都少于某个约定的最大对象数量为止。
- 如果它是扁平的,优点有:
- 相对简单。扁平的数据结构相对来说更易于推理和实现。
- 内存使用量恒定。由于添加新对象不需要创建新的分区,所以空间分区使用的内存通常可以提前确定。
- 当对象改变位置时可以更为快速的更新。当一个对象移动时,数据结构需要更新以便在新的位置找到对象。使用层级空间分区,这可能意味着调整层次结构中的若干层。
- 如果它是一个层级的分区
- 它可以更有效地处理空白的空间。想象一下,在我们前面的例子中,如果战场的一侧是空白的,那么就会产生大量空白的单元格,而我们不得不在每帧为它们分配内存并遍历它们。因为层级空间不会细分稀疏区域。所以一个大的空白空间仍然是一个单独的分区,而不是大量细小的分区。
- 它在处理稠密区域时更为有效。这是硬币的另一面:如果你有一堆对象成群则在一起,非层级分区时低效的。你最终会有一个包含着许多对象的,可能根本没有分区的分割。层级分区将会自适应地将其细分成更小地分区,使得你一次只需考虑少数几个对象。
分区依赖于对象集合吗
在我们地示例中,网格地间距时预先固定的,并且我们将单位放置进了单元格中。其它的分区方案是自适应的,它们根据实际的对象集合及其在世界中的位置来选择分区的边界。
我们的目标是实现一个均衡的分区,每一个分区都有着大致相同的对象个数以获得最佳的性能。以我们的网格为例考虑下,如果所有单位都集中在战场的一个角落,那么它们将会处在同一个单元格内,找寻单位间攻击的代码又会回到原来我们要试图解决的O(n^2)问题这一远点。
1)如果分区依赖于对象
- 对象可以被逐步地添加。添加一个对象意味着要找到正确地分区并且将对象放置进去。所以你可以在不影响性能地情况下一次性完成这个动作。
- 对象可以快速地移动。对于固定分区,移动一个单位意味着将一个单位从一个分区移出并添加到另一个单元格中。如果分区边界本身基于对象集合来改变,那么移动对象会引起边界的移动,从而可能要将大量的其它对象移动到其它分区。
- 分区可以不平衡。当然,这么做的硬伤在于你对最终呈现的非均匀分区的掌控力会很薄弱。如果对象拥挤到一起,那么你会因为在空白区域浪费了内存而令其性能变得很糟糕。
2)如果分区自适应于对象集合
像二叉空间分割(BSPs)和k-d树(k-d trees)这样的空间分区方式会递归的将世界分割开来,以使得每部分包含着数目几乎相同的对象。要左到这点,在选取要进行分区的层级前,你必须计算每个阵营包含的对象数目。边界体积层次结构(Bounding volume hierarchies)是空间分区中的另外一种类型,用于优化世界中的特定对象集合。
- 你可以确保分区间的平衡。着不仅仅带来优秀的性能表现,而且会是持续稳定的表现:如果每个分区有着相同数量的对象,你便可以确保对世界中的任意分区的查询时间开销均等。当需要维持稳定的帧速率时,这种稳定性比原始性能更为重要。
- 当整个对象集合进行一次性的分区时更为高效。当对象集合影响到边界时,最好在分区之前对所有对象进行审视。这就是为什么这种类型的分区越来越多地适用于游戏过程中保持不变的事物诸如美术和静态几何。
- 如果分区不依赖于对象,而层级却依赖于对象。有一个空间分区特别值得一提,因为它同时具备了固定分区和自适应性分区地优良性质:四叉树(quadtrees)。
四叉树从将整个空间作为一个单一地分区开始。如果空间中对象地数目超过了某一个阈值,则空间被切分成四个较小地正方形。这些正方形地边界是固定地:它们总是将空间对半切分。然后对于四个正方形中地每一个而言,我们重复同样地过程。递归下去知道每一个正方形内部只有少量对象。由于我们只是递归地将高密度对象区域分开,因此这个分区会自适应于对象集合,但分区是不会移动的。如下图,从左往右阅读,你可以看到分区的过程:
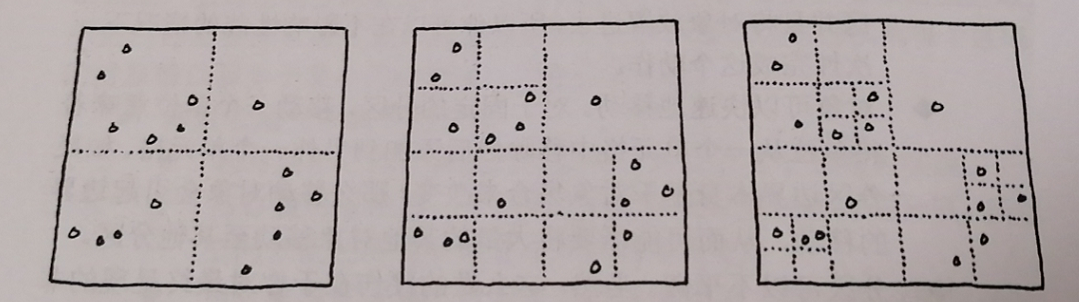
- 可以逐步的增加对象。添加一个新对象意味着要寻找何时的区域并且放置进去。如果对象放入区域时超过了最大数量,那么该区域会被继续细分。在区域中的其它对象也会被细分到更细小的区域中去。这需要一些工作,但工作量时固定的:你需要移动的对象的数量始终要比最大的对象数少。添加单个对象永远也不会触发一次以上的拆分动作。删除对象同样简单。你将对象从它所在区域中移出,如果它的父区域的对象总数低于了一个值,那么你就可以合并这些细分的区域。
- 对象可以快速地移动。这个当然,和上面一样。“移动”一个对象只是一次添加和一次删除,两者在四叉树模式下速度很快。
- 分区是均衡地。由于任何给定地区域中地对象数目都比最大对象数要小,因此即使对象聚集在一起,也不会存在容纳着大量对象地单一分区。
对象只存储在分区中吗
你可以将分区看作游戏中对象存货地地方,或者你可以只将它看作是二级缓存,相比直接持有对象列表地集合而言,查询能够更快速。
- 如果他是对象唯一存储的地方
这避免了两个集合的内存开销和复杂性。当然,将东西存成一份比两份的代价要小。另外,如果你有两个集合,你必须确保两个集合间的同步。每次当一个对象被创建或被删除时,将不得不从两者中对其进行添加或者删除。
- 如果存在存储对象的另外一个集合
遍历所有的对象会更为快速。如果问题中对象是“存货”的并且它们需要做一些处理,则你可能会发向自己要频繁地访问每一个对象,无论对象地位置在哪。试想一下,在我们前面地例子中,大部分单元格都是空的。遍历网格中所有单元格来找到那些非空单元格都是在浪费时间。第二个仅用于存储对象地集合令你可以直接对全部对象进行遍历。你有两个数据结构,其中一个针对每个用例进行了优化。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步