游戏编程模式-数据局部性
“通过合理组织数据利用CPU的缓存机制来加快内存的访问速度。”
动机
现今硬件设备发展极快,曾今一度符合摩尔定律,这很容易让人产生一个错觉,好像软件开发者不需要再花费很大的力气就能使程序飞奔起来。但现实是,芯片确实是快了,这让我们能更快的处理数据,但获取数据的速度却没有很大的改变。也就是说,虽然CPU能快速的进行计算,但计算所需的数据确是要从主存中获取,而RAM的存取速度远远低于CPU的速度(甚至从未接近过),那么也就是说,在获取数据的过程中,CPU是在空转,这非常的糟糕,幸运的是我们有一些缓解的措施,让我们从一个比喻开始……
数据仓库
设想你是一个办公室的会计,你的工作是采集一盒子的单子并对它们进行一些核查统计或其它的计算。你需要根据一些晦涩的会计专业逻辑来对这些打了特定标签的盒子进行处理。得益于你的努力工作,你可以在很短的时间内完成一个盒子的所有工作。但这里有个问题就是,盒子都放置于一栋楼的不同位置,为了获取盒子,你需要询问仓储人员,他会开着叉车到某个位置取出盒子并送到你的办公室。你可以很快的处理一个盒子,但仓储人员找到这个盒子并把这个盒子运送到你的办公室却没那么快,所以造成的情况就是不管你的效率有多高,你也只能处理仓储人员能送过来的那么多盒子,其他的时间只能慢慢的思考人生……
这个时候,一群工业设计师来了,它们的任务就是提高工作效率。比如提高流水线效率之类的工作。经过观察他们发现几点:
通常情况下,在你完成某个盒子任务之后,你所需要处理的下一个盒子就在同一架子上;
使用叉车来取一个小盒子是在太蠢了;
其实你的办公室角落里还有一些空闲的空间。
他们想到了一个聪明的办法。当你向仓储人员提出需要盒子的请求时,他将取来一托盘的盒子。这些盒子中不只有你想要的盒子,也有与这个盒子相邻的其它盒子。当然,他并不知道你是否需要这些盒子,他只是尽可能的往托盘上装盒子。装好后,他会把这些盒子放到你办公室的空闲位置。这样,当你需要一个新盒子的时候,你先在这个位置查看是否有你需要的盒子,如果有,那就太好了,你可以直接拿到箱子继续工作,你的工作效率将极大的提高,当然盒子也可能不在,那么这个时候,你需要把一个处理完的盒子退回去,因为办公室的空间有限,然后再然仓储人员为你带来一个新的盒子(注意,这里退回去一个并不是真的一个,应该理解为退回这个盒子和与相邻的处理完的盒子)。
CPU的托盘
尽管很奇怪,但上面的过程与当今计算机的CPU工作原理很类似。也许这不太明显,你扮演着CPU的角色,你的桌面式CPU的寄存器,装着单子的盒子式你想要的数据,仓库式机器的RAM,那个恼人的仓管员式从主存往寄存器读取数据的总线。随着芯片速度的加快(以及RAM速度的落后),硬件工程师开始寻找解决方案。而他们想到的就是CPU缓存技术。
当代计算机在其芯片内部的内存十分有限。CPU从芯片中读取的速度要快于它它从主存中读取数据的速度。芯片内存很小,以便嵌入到芯片上,而且由于它使用了更快的内存类型(静态RAM或称“SRAM"),所以更加昂贵。这块小内存被称为缓存(特别一提的是,芯片上那块内存变时L1缓存),在上面的比喻中,它的角色就是那个装满盒子的托盘。任何时候当芯片需要RAM中的数据时,它会自动将一整块连续的内存(通常在64到128字节之间)取出来并置入缓存中。这块内存被称为缓存线(cache line)。
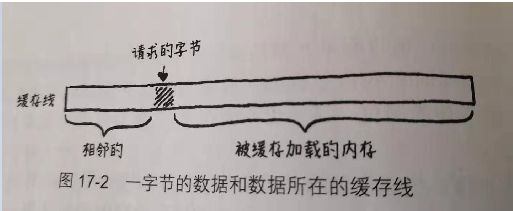
假如你需要的下一个数据恰巧在这个块中,那么CPU直接从缓存中读取数据,要比从RAM中取快的多。成功的在缓存中找到数据被称为一次命中。假如没找到而需要访问主存,则称为未命中。当缓存未命中时,CPU就停止运转——它因为缺少数据而无法执行下一条指令。CPU进行着几百次的循环直到取得数据。我们的任务就是避免这样的情况发生。设想你正试图通过改进一些关键性的游戏代码来提高性能,比如下面这样:
for(int i=0;i<NUM_THINGS;++i) { sleepFor500Cycles(); things[i].doStuff(); }
对于这段代码我们有什么可改进的呢?是的,首先循环里的函数调用开销很大,这样的调用等价于缓存未命中带来的性能你损失。每次跳入主存中,就意味着往你的代码里加入了一段延时。
数据即性能
通过整理一些类似游戏的小程序——这些程序可以触发最好和最坏的缓存使用情况,我想测试一下缓存失效时的性能,以便第一时间知晓缓存失效究竟造成多少性能损失。而结果差别非常的大,两段代码进行相同的计算,二者唯一的差别就是它们造成缓存的命中次数不同,慢的程序比另一个程序慢了50倍。这真是出乎我的意料,我一直意味代码关乎性能,而现在,因为缓存机制的存在,你组织数据的方式会直接影响性能。需要注意的是,指令也是要缓存的,也就是说代码也是在内存中,需要被载入到CPU中才能执行,这属于更精通于这个课题的人的领域。
在这里,我介绍一些基本的技巧,以便你在关于数据结果如何影响程序性能这一问题上展开思考。这些都可以归结为一件简单的事情:不论芯片何时读取多少内存,它都整块的获取缓存线。你能够在缓存线中使用的数据越多,程序就跑的越快。所以优化的目标就是将你的数据结构进行组织,以使需要处理的数据对象在内存中两两相邻。
数据局部性模式
当代CPU带有多级缓存以提高内存访问速度。这一机制加快了对最近访问过的数据的邻近内存的访问速度。通过增加数据局部性并利用这一点可以提高性能——保持数据位于连续内存中以供程序进行处理。
使用情境
如同多数优化措施,指导我们使用数据局部性模式优化的对一条准则就是找到出现性能问题的地方。不要在那些代码库里非频繁执行的部分浪费时间,它们不需要本模式。由于此模式的特殊性,因此你可能希望确定你的问题是否是由于缓存未命中引起的,否则这个模式也帮不上什么忙。
最简单的方式就是人为的添加一些测量工具以计量一段代码执行所花费的时间,最好能够使用一些精确的计时器。为了获取到更精确缓存使用情况,你需要一些更复杂的手段——你需要精确知道有多少缓存未命中,并对它们进行定位。幸运的是有一些现成的工具可以做这些工作,只不过你需要花费一些时间来学习如何使用这些工具。
如上所述,缓存未命中将影响到你的游戏性能。由于你无法花费大量时间预先对缓存的使用进行优化,因此是该想想在设计的过程中如何让你的数据结构变得对缓存更加的友好。
使用须知
软件架构的一大特征就是抽象化。之前讲述的很多模式都是如何将代码进行分块解耦,以使它们易于修改。在面向对象的语言中,这意味着接口化。在C++中,使用接口意味着要通过指针或引用来访问对象。而使用指针访问内存意味着要在内存中跳来跳去,这就会引发本模式在极力规避的缓存未命中的现象。
为了做到缓存友好,你可能需要牺牲一些之前做的抽象化工作。你越是在数据局部性上下功夫,你就要越牺牲继承、接口以及这些手段来的好处。这里没有高招,只有利弊的权衡。
示例代码
假如你真的钻研到数据局部性优化的深处,你将发现有无数种方法将你的数据拆解成片段以供cpu更好的进行处理。下面,我们将从一个简单的实例入手。
连续的数组
class GameEntity { public: GameEntity(AIComponent* ai, PhysicsComponent* physics, RenderComponent* render) :ai_(ai),physic_(physics),render_(render) { } AIComponent* ai() {return ai_;} PhysicsComponent* physics() {return physics;} RenderComponent* render() {return render_;} private: AIComponent* ai_; PhysicsComponent* physics_; RenderComponent* render_; }; class AIComponent { public: void update() { //work with and modify state... } private: //Goals,mood }; class PhysicsComponent { public: void update() { //work with and modify state... } private: //properties... }; class RenderComponent { public: void update() { //work with and modify state.. } private: //mesh,textures };
每个组件都包含一些相对小量的状态,如一些向量或矩阵,且组件包含一个更新这些状态的方法。游戏维护着一个很大的指针数组,它们包含了游戏世界中所有实体的引用。每次游戏循环都要更新所有的组件,所以很直接的实现就是:
while(!gameOver) { for(int i=0;i<numEntities;++i) { entities[i]->ai()->update(); } for(int i=0;i<numEntities;++i) { entities[i]->physics()->update(); } for(int i=0;i<numEntities;++i) { entities[i]->render()->update(); } }
在听闻CPU缓存机制之前,看上面的代码没什么毛病。但现在,很明显,这样的代码引起了缓存的抖动,甚至可以说是把缓存搞的一团糟。让我们看看它是怎么运行的:
1.数组存储着指向游戏实体的指针,因此对于数组中的每个元素而言,我们需要遍历这些指针(所指向的内存)——这就是引发了缓存未命中;
2.然后我们的实体又维护着所指向组件的指针,再一次缓存未命中;
3.接着我们更新组件;
4.现在我们回到步骤1,对游戏里的每个实体的每个组件都这么干。
最可怕的是我们不知道这些对象再内存中的布局情况,完全任由内存管理器摆布。由于实体随着时间被分配、释放,因此堆空间变得随机离散化。在这样的情况下,游戏的效率将变得非常的低下。现在让我们来做一些改进,可以发现,我们追踪游戏实体的指针是为了找到这个实体内指向其组件的指针以便访问这些组件。GameEntity类本身并没有什么要紧的状态或方法。游戏循环仅关心这些组件。
为了对这一堆游戏实体以及散乱在地址空间各个角落的组件做改进,我们将从头来过——我们构造一个容纳着各类组件的大数组——存放所有AI组件的一维数组,当然还有存放物理和渲染组件的数组,如下:
AIComponent* aiComponents = new AIComponent[MAX_ENTITIES]; PhysicsComponent *physicsComponents = new PhysicsComponents[MAX_ENTITIES]; RenderComponent *renderComponents = new RenderComponent[MAX_ENTITIES];
这里需要强调一下,这些是存储组件的数组而非组件指针的数组,也就是说数组中直接包含组件的实际数据,这些数据在内存中逐个字节地进行分布,游戏循环可以这样遍历它们:
while(!gameOver) { //process AI for(int i=0;i<numEntities;++i) { aiComponents[i].update(); } //update physics for(int i=0;i<numEntities;++i) { pysicsComponents[i].update(); } //update render for(int i=0;i<numEntities;++i) { renderComponents[i].update(); } //other game loop }
这一方法往空闲的CPU中输入了一块连续的字节。这一改进在我的测试中,它为更新循环带来了比之前的版本快50倍的速度。有趣的是,我们这么做并没有放弃太多的封装性。当然,现在游戏循环直接对组件进行遍历更新而不是遍历游戏实体,但在此之前遍历游戏实体来确保它们是按照正确的顺序被更新。尽管如此,每个组件本身依然具有很好的封装性。它们保持自身的数据和方法。我们只是改变了使用的它的方式而已。着也并不意味着我们需要放弃GameEntity类。我们可以将它放在一边,并保持对组件指针的持有。它们只是指向这三个数组而已。而当你在游戏其它部分需要一个类似游戏实体概念的对象及其所有内容时依然可以使用它们。重要的时减少了性能开销的游戏循环避开了这些游戏实体而直接访问了其内部数据。
包装数据
假设我们要制作一个例子系统,顺着上一部分的思路,我们将所有的粒子置入一个大的连续数组中,我们也将它封装成一个管理类来看看:
class Particle { public: void update() { /*gravity,etc....*/ } }; class ParticleSystem { public: ParticleSystem():numParticles_(0) {} void update(); private: static const int MAX_PARTICLES = 100000; int numParticles_; Particle particles_[MAX_PARTICLES]; }; void ParticleSystem::update() { for(int i=0;i<numParticles_;++i) { particles_[i].update(); } }
但实际上,我们并不是总需要更新所有的粒子,所以如下的方法更加合适:
void ParticleSystem::update() { if(particles_[i].isActive) { particles_[i].update(); } }
给Particle类一个标致来表示其是否处于激活状态,在循环中挨个检查其标志。这使得该标志随着对应粒子的其他数据一起被加载到缓存中。假如粒子并未被激活,那么我们就跳向下一个,这时将该粒子的其他数据加载到缓存中就是一种浪费。活跃的粒子越少,我们就会越多次地在内存中跳转。假如粒子数据太大而活跃粒子有太少,我们又会抖动缓存。
当我们实际处理地对象并不连续时,将对象存入连续存入地数组,这个办法就无效了。假如为了这些非活跃地粒子而要在内存中跳来跳去,那么我们就回到了问题的起点。那么这里的一个解决方案就是根据激活标志来对粒子进行排序。而不是去判断这些标志。我们总是在将那些被激活的粒子维持在列表的前端,这样我们就不必去检测标志,就像这样:
for(int i=0;i<numActive_;++i) { particles[i].update(); }
现在我们不略过任何数据,每个塞进缓存的粒子都是被激活的,也是我们要处理的。当然我可没说你得在每帧对整个粒子集合进行快速排序,这样得不偿失,我们希望时刻保持数组有序。
假设数组排好序——并且一开始所有得粒子都处于非激活状态。数组仅当某个粒子被激活或者反激活时处于乱序状态。我们很容易就能对这两种情况进行处理:当粒子被激活时,我们通过把它与数组得第一个未激活得粒子进行交换来将其移动到所有激活粒子得末端:
void ParticleSystem::activateParticle(int index) { //shuldn't already be active assert(index >= numActive_); //swap it with the first inactive particle right //after the active ones particle tmp = particles_[numActive_]; particles_[numActive_] = particles_[index]; particles_[index] = tmp; numActive_++; }
反激活粒子则以相反得方式处理:
void ParticleSystem::deactivateParticle(int index) { //shuldn't alreay be inactive assert(index <= numActive); numActive__; //swap ti ithe the last active particle right //before the inactive ones. Particle tmp = particles_[numActive_]; particles_[numActive_] = particles_[index]; particles_[index] = tmp; }
许多程序员都很厌恶在内存中移动数据,把内存中得字节移来移去让人觉得比为指针分配内存开销更大。但当你加上遍历指针的开销时,会发现这种感觉有时会失灵。假如你能保持缓存数据盈满,在内存中移动数据的开销是很小的。结论就是,我们可以保持粒子依照其激活状态有序排列,而无需保存激活状态本身。这可以通过保存一个num_active_的计数器来实现,这样也就意味着缓存线上能存储更多的数据,从而提高速度。
当然,这并不是十全十美的。从API中可以看到,我们为此放弃了许多面向对象的思想。Paritcle类不再控制其自身的状态,你也无法对粒子对象调用诸如active()之类的方法,因为它无法确定自身在数组中的索引。所有的激活操作都有粒子系统来执行。对于这样的情况,我倒是不介意ParticleSystem和Particle之间的紧密关联,概念上我将它们视为两个物理类组成的一个整体。
热/冷分解
这是最后一个帮助你将代码变得缓存友好的的技术案例。假设我们为游戏实体配置了AI组件,其中包含了一些状态:它当前所播放的动画,它当前所走向的目标位置,能量值等。这些状态都是每一帧需要检查和修改的变量。如下:
class AIComponent { public: void update(); private: Animation* animation_; double energy_; Vector goalPos_; };
它还存储着一些并非每一帧都用到的处理意外情况的变量。比如存储一些游戏实体死亡后掉落的物品数据,这些数据仅在实体死亡时才被使用。如下:
class AIComponent { public: void update(); private: //prievious fields... LootType drop_; int minDrops_; int maxDrops_; double chanceOfDrop_; };
假设我们采用前述的方法,当更新这些组件的时候,我们遍历一个已经包装好且连续的数组中的数据,现在因为AI组件变大了(增加了掉落数据)而导致缓存线上能放入的组件更少,这样会导致缓存未命中的概率加大。而实际上类似掉落物品的数据我们只有实体死亡的时候用的上。
对于这个问题的解决方法我们称之为“热/冷分解“。其思路就是我们的数据分为两部分,一部分称之为”热数据”,也就是我们每一帧都会用到的数据,另一部分称之为“冷数据”,也就是那么些我们不那么频繁使用的数据。在这里,热数据主要是AI需要的那些数据,它是AI组件的关键数据,所以我们不希望通过指针来访问它,所以直接存储到AI组件中,而其他类似掉落物品的数据我们可以提炼为一个冷组件放到一边,因为我们还是需要访问它,所以为它分配一个指针,如下:
class AIComponent { public: //other methods.. private: Animation* animation_; double energy_; Vector goalPos_; LootDrop* loot_; }; class LootDrop { friend class AIComponent; LootType drop_; int minDrops_; int maxDrops_; double chanceOfDrop_; };
这样改进之后,每次遍历更新AI组件之时,载入到缓存中的那些数据就是我们实际要处理的了(指向冷数据的指针除外)。这里也有方法不维护这个指向冷数据的指针,就是通过维护两个平行的数组分别存放冷热数据,我们可以使两个数组中同一组件的索引一致,这样就可以通过热数组的索引来访问对应的冷数据。
当然,在我们的例子中,冷热数据的区分很明显,但在实际的游戏中却很少会有这样鲜明的划分,这就需要我们对数据进行细致的分解和测试,这些努力是值得的,因为你会获得收获的。
设计决策
这种设计模式更适合叫做一种思维模式。它提醒着你,数据的组织方式是游戏性能的一个关键部分。这一块的实际扩展空间很大,你可以让你的数据局部性影响到游戏的整个架构,或者它只是应用在一些核心模块的数据结构上。对这一模式的应用,你最需要关心的即使何时何地使用它?随着这个问题我们也会看到一些顾虑。
如何处理多态
就这一点,我们之前避开了子类进程和虚方法,然而多态和方法的动态调用是非常有用的工具,我们如何在二者间进行协调?
避开继承
最简单的方法就是避开子类化,或者说在你进行缓存优化的地方避开继承。软件工程中也较为排斥重度继承。这样做之后:
- 安全而容易。你知道自己正在处理什么类,而且显然所有的对象其大小都一样。
- 速度更快。方法的动态调用因为这在vtable中寻找实际需要调用方法,并通过指针来访问实际代码。由此在不同的硬件平台呈现较大的性能差异,故动态调用意味着一些开销。
- 灵活性差。当然,我们使用动态调用的原因正式在于它能够给予我们强大的对象多态能力,让对象表现出不同的行为。假如你希望游戏中的不同实体拥有各自的渲染风格或者特殊的移动与攻击表现,那么虚方法正是为此而准备的。若想要避免使用虚方法而做到这一点,那你可能需要维护一个庞大的switch逻辑块,并且很快陷入混乱。
为不同的对象类型使用相互独立的数组
我们使用多态来实现在对象类型未知的情况下调用其行为。换句话说,我们有个装着一堆对象的包,我们希望一声令下时它们能够各做各的事情。但这带来的问题是,为什么要从一个龙蛇混杂的背包开始,而不是维护一系列按照类型分放的集合呢?
- 这样一系列集合让对象紧密的封包。由于每个数组仅包含一个类型的对象。也就不存在填充或者其他古怪了。
- 你可以进行静态的调用分发。你可以按照类型将对象划分,也就不再需要多态了。你可以进行常规的,非虚方法调用。
- 你必须时刻追踪这些集合。假如你有许多不同类型的对象,那么维护单独数据集合的开销和复杂性将是件苦差事。
- 你必须注意每一个类型。由于你要维护每个类型的对象集合,因此无法从这些类型集合中解耦它们。多态的一个神奇作用就在于它是可扩展的,通过使用接口来进行外部操作。多态将调用这些接口的代码从潜在的那些类型(它们均实现这一接口)中完全解耦出来。
使用指针集合
假如你不担心缓存,那么这自然是个好办法。你只需要执行基类或接口的指针数组。你可以很好的利用多态性,而且对象的大小也无须一致。
- 这样做的灵活性搞。只要能适配接口,访问这个集合的代码就能处理你关心的任何类型的对象。这是完全可扩展的。
- 这样做并不缓存友好。我们在此讨论其他方案的原因就在于解决这样的指针间访问数据的缓存不友好的局面。然而请记住,如果这些代码对性能并不苛求,那么使用多态是完全没问题的。
游戏实体是如何定义的
假如你将本模式与组件模式一起使用,则会拥有一系列相邻的组件数组来组成你的游戏实体。这个时候,游戏实体本身并不重要,当然在游戏的其他模块代码中,你还是可能需要这些概念性的实体。
接下来的问题是这该如何表现?实体如何跟踪自己的组件?
假如游戏实体通过类中的指针来索引其组件
我们的第一个例子看起来就是如此。 这是相对普通的面向对象的办法。你有一个GameEntity类,而它内部有指向其组件的指针。由于它们只是指针,故它们并不知道哪些组件在内存中的确切位置或者它们在内存中是如何组织的。
- 你可以将组件存于相邻的数组中。由于游戏实体并不关心组件的存储,因此你可以将它们组织到一个封包过的数组中来对迭代过程进行优化。
- 对于给定实体,你可以很容易获取它的组件。只需要通过指针访问即可。
- 在内存中移动组件很困难。当组件被启用或禁用时,你可能希望将这些组件移动以保持那些激活的组件总排在数组的前端并彼此相邻。假如你移动一个与某个实体通过原始指针关联的组件,则可能一不小心破坏了这一指针关联。你必须确保同时对实体的相应指针进行更新。
假如游戏实体通过一系列ID来索引其组件
在内存中移动指向组件的原始指针式一大挑战,你可以使用更抽象的表示来取代指针,一个能够检索到指定组件的ID或索引。ID的实际语义和索引过程完全取决于你。可能式简单的为每个组件存储一个唯一ID进行数组遍历,也可能式在一个哈希表上将ID对组件所在的数组索引进行映射。
- 这更加复杂。你的ID系统也许无需过度复杂,但总得比直接使用指针要麻烦。你需要实现并调试它,当然使用ID记录也需要额外的存储空间。
- 这样做更慢。要想比遍历原始指针速度更快是很难的。通过实体获取其组件的过程涉及到哈希查找等问题。
- 你需要访问组件管理器。最简单的想法就是用一些抽象的来定义组件。你可以通过它来获取实际的组件对象。但为了做到正确的素引,你必须让这些ID有办法对应到组件上。这也正是存储着你组件数组的那个管理类所要做的。
使用原始指针,假如你有一个游戏实体,你就可以找到其组件。而使用ID的方法,你则需要同时对游戏实体和组件进行注册。
假如游戏实体本身就只是个ID
这是一些新的游戏引擎所采用的风格。一旦你将游戏实体的所有行为和状态从主类移动到组件中。那么游戏实体还剩什么呢?结果是剩下不了什么,游戏实体唯一做的就是将自己与其组件绑定。它的存在就意味着其AI、物理、渲染组件构成了这个游戏世界中的实体。这一点很重要,因为组件之间需要交互。渲染组件需要知道实体位置信息,而这个位置信息很可能位于其物理组件中,AI希望移动实体,于是它需要对物理组件施加一个力。在一个实体内,需要为每个组件提供一个访问其兄弟组件的办法。某些聪明人意识到我们所需要的就是个ID。这使得组件能够知道它所属的实体是哪个,而不是让实体来确定其组件位置。当AI组件需要其同属实体的物理组件时,它只需要访问与自身实体ID的那个物理组件即可。
- 你的游戏实体类完全消失了,取而代之的是一个优雅的数值包装。实体变得很小。当你需要传入一个实体的引用时,你只需要传入一个数值。
- 实体类本身是空的。当然这一方法的弊端是你必须把所有的东西都扫出游戏实体。你不再有地方来存放那些非组件构成的实体状态和行为。这样做更加依赖于组件模式。
- 你无需管理器其生命周期。由于现在实体只是某些内置类型的值,因此它们无需进行显式的分配和释放。实际上当某个实体的所有组件都被销毁时,这个实体也就随之隐式的“消亡”了。
- 检索一个实体的所有组件会很慢。这与前一个方案的问题类似,但处于相反的一面。为某个实体寻找其组件,你需要对一个对象进行ID映射,这个过程带来开销。
这一次性能反面也存在问题。组件在更新过程中频繁与其兄弟组件交互,于是你需要频繁的检索组件。一个解决方案是将实体的对应为其组件所在数组的索引。假如所有的实体都包含相同的组件集,那么你的组件数组之间是完全平行的。AI组件数组中的第三个组件将与物理组件数组中的第三个组件对应着同一个实体。
请牢记,这个办法迫使你保持这些数组平行。当你希望对数组进行排序或者按照某种规则进行封包时就很难做到平行了。你的某些实体可能禁用了物理引擎,而其他实体不可见。在保持它们平行的情况下,你无法兼顾物理组件和渲染组件来同时满足这两种情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号