
游戏编程模式-类型对象
写在前面
“通过创建一个类来支持新类型的灵活创建,其每个实例都代表一个不同的对象类型。“
动机
在RPG游戏中,我们通常会创建很多的怪物来作为我们主角的敌人,比如说恶龙、野狼等。怪物具有一系列的属性:生命值、攻击力、图形效果、声音表现等。每一种怪物的属性不同,比如生命值,龙具有比野狼跟多的初始生命值,这使得龙更难被杀死。这个时候,我们需要在游戏中来实现它们。那么怎么来做了?
我们第一时间的就会想到使用继承。首先声明一个Monster的基类:
class Monster { public: virtual ~Monster() {} virtual const char* getAttack()=0; protected: Monster(int startingHealth):health_(startingHealth) { } private: int health_; //current health };
接下来我们实现子类:
class Dragon:public Monster { public: Dragon():Monster(230) {} virtual const char* getAttack() { return "The dragon breathes fire!"; } };
每个派生类都传入初始生命值,并重写getAttack()函数。我们通过这种方式不断的实现新的子类。但随着子类的增多,事情很快就陷入了泥沼。设计师设计了上百个种族,我们发现我们的大部分时间都投入到了编写那短短的7行代码和重新编译上,而且一旦设计师要改动某个数值,我们又要重新编译。这个设计师和程序员都带来的巨大烦恼。我们需要一种无需程序员接入设计师就能创建并调试种族属性的方法。
现在让我们站在高一些的层次上看,我们要解决的问题非常简单。游戏中有一堆不同的怪物,我们想让它们共享一些特性,比如一些怪物具有相同的攻击属性。我们可以通过将它们定义成相同的“种类”来实现,而这个种类就决定了其攻击的伤害表现。由于这样的情况很容易让人联想到类,因此我们自然而然的就使用派生类来实现这个概念。龙是一种怪物,游戏中的每头龙是这个龙“类”的实例。将每个种族定义成抽象基类Monster的派生类,让游戏中的每个怪物称为派生类的实例来反映这一关系。
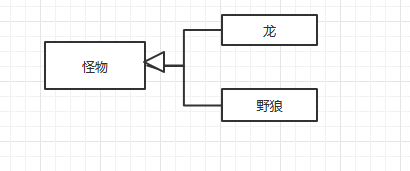
每个怪物都属于某一个种族,种族越多,继承树就越大。所以就慢慢出现了我们上述的问题:不断的写重复代码和编译。这种做法能达到我们的目的,但还有另外的选择。就是让每个怪物都有一个种类,也就是声明一个表示怪物类型的类Breed,然后怪物中有一个成员表示怪物所属类型。也就是如下图这样:
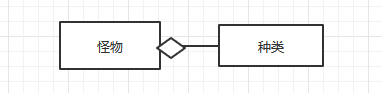
Breed类包含同一种族的所有怪物之间共享的信息:初始生命值和攻击力。这样,我们只需要两个类,就能创建出各种各样类型的怪物。这种设计模式就是:类型对象。这个模式的强大之处就在于它允许我们在不是代码库复杂化的情况下添加新的类型。我们已经基本上将一部分类型系统从硬编码的类继承中解放出来,并转化为可在运行时定义的数据。我们可以通过实例化更多的Breed实例来创建数以千计的种族。如果我们通过某些配置文件里的数据来初始化种族,那么我们就能完全在数据里定义新的怪物类型,这可以完全让设计师搞定。
类型对象模式
定义一个类型对象类和一个持有类型对象类。每个类型对象的实例表示一个不同的逻辑类型。每个持有类型对象类的实例引用一个描述其类型的类型对象。实例数据被存储在持有类型对象的实例中,而所有同概念类型所共享的数据和行为被存储在类型对象中。引用同一个类型对象的对象之间能表现出“同类”的表现。这让我们可以在相似对象集合中共享数据和行为。这于派生类的作用有几分相似,但却无需硬编码出一批派生类。
使用情境
当你需要定义一系列不同“种类”的东西,但有不想把那些种类硬编码进你的类型系统时,本模式都适用。尤其时当下面任何一项成立的时候。
- 你不知道将来会有什么类型
- 你需要在不重新编译或修改代码的情况下,修改或添加新的类型。
使用须知
这个类型旨在将“类型”的定义从严格生硬的代码语言转移到灵活却弱化了行为的内存对象中。灵活性是好的,但是把类型移动到数据里仍有所失。
- 类型对象必须手动跟踪
一个使用类似c++的类型系统的好处就是编译器自动处理的所有类的注册。定义类的数据自动编译到可执行程序的静态内存中,它就运转了起来。使用类型对象模式,我们不但要负责管理内存中的怪物,同时还要管理怪物的类型,也就是如果怪物存在,则需要保证表示该怪物类型的对象也必须存在,而创建新的怪物时,我们也要保证以一个有效的种族实例的引用来初始化它。我们自己从编译器的一些限制解放出来,但代价就是要重新实现以前编译器为我们提供的一些功能。
- 为每个类型定义行为更困难
通过派生类,我们可以重写一个方法,它可以实现你想要做的任何事情,无拘无束。而当我们使用类型对象的时候,我们使用成员变量代替了重写,这使得通过类型对象去定义类型相关的数据非常容易,但定义类型的行为却很难。比如不同怪物有不同的AI算法,我们如何在类型对象中实现这个行为了?这里有几个方法可以跨越这个限制:
最简单的方法就是固定一个预定义的行为集合,然后类型对象中有一个成员指向其中的一种行为。另外一种更强大更彻底的解决方案就是支持在数据中定义行为。解释器模式和字节码模式都可以编译代表行为的对象。如果我们能读取数据文件并提供给上述任意一种模式来实现,行为定义就完全从代码中脱离出来了。
示例
class Breed { public: Breed(int health,const char* attack):health_(health),attack_(attack) {} int getHealth() { return health_; } const char* getAttack() { return attack_; } private: int health_; const char* attack_; };
在Monster中使用它:
class Monster { public: Monster(Breed& breed):health_(breed.getHealth()),breed_(breed) {} const char* getAttack() { return breed_.getAttack(); } private: int health_; Breed& breed_; };
当我们构造一个怪物时,我们给它一个种族对象的引用。由此定义怪物的种族,取代之前的派生关系。这段简单的代码时这个模式的核心思想。以下都是额外的好处。
构造函数:让类型对象更加像类型
以上的过程先构建一个怪物,然后再赋予它类型。这与大多数面向对象语言实例化对象的过程相反——我们通常不会分配一段空内存然后给它一个类型。面向对象思想是调用类自身的构造函数,由它负责为我们创建新的实例。所以我们改一下上面的代码:
class Breed { public: Monster* newMonster() { return new Monster(*this); } //previous Breed code... }; class Monster { friend class Breed; public: const char* getAttack() { return attack_; } private: Monster(Breed& breed):health_(breed.getHealth()),breed_(breed) Breed& breed_; };
对比一下前后创建怪物的过程:
//before Monster* monster = new Monster(someBreed); //after Monster* monster = someBreed.newMonster();
这样做的好处是什么了?创建一个对象分为两步:分配内存和初始化。Monster的构造函数让我们能够做所有的初始化操作,在本例子中我们只是保存了一个类型的引用,但在完整的游戏中,可能还需要加载图形、初始化怪物AI等其它设定工作。但这些都是发生在内存分配之后。也就是说我们在怪物的构造函数调用之前就已经获得一段用于容纳它的内存,这一步是语言的运行时为我们做好的。但在游戏里,我们也希望能控制对象创建这一环节:通常使用一些自定义内存分配器或者对象池模式。在Breed里定义一个“构造函数”让我们有地方实现这套逻辑。取代简单的new操作,newMonster函数能在控制权被移交至初始化函数前,从一个池或者自定义堆栈里获取内存。把此逻辑放进唯一能创建怪物的Breed里,就保证了所有怪物都由我们预想的内存管理体系经手。
通过继承共享数据
我们现在已经实现了一个完全可用的对象系统,但是它还很基础,如果我们的游戏由上千个种族,每个都包含大量的属性,这对设计师来说会非常的难受。一个有效的办法是仿照多个怪物通过种族共享特性的方式,让种族之间也能够共享特性。就像面向对象那样,我们可以通过派生类来实现。这里我们需要自己实现它。简单起见,我们仅支持单继承。种族都有一个基种族类:
class Breed { public: Breed(Breed* parent,int health,const char* attack) :parent_(parent),health_(health),attack_(attack) {} int getHealth(); const char* getAttack(); private: Breed* parent_; int health_; const char* attack_; };
构造种族时,我们传入一个基种族(传入一个NULL表示没有祖先)。为了更实用,子种族需要明确那些特性从父类中继承,那些特性由自己重写和特化。在本例子中,我们可以让子种族只继承基种族中非0生命值以及非NULL的攻击字符串。实现方式由两种:一种就是每次被请求时执行代理调用,就像下面这样:
int Breed::getHealth() { //override if(health_ != 0 || parent_ == NULL) { return health_; } return parent_->getHealth(); } const char* getAttack() { if(attack_ != NULL || parent_ == NULL) { return attack_; } return parent_->getAttack(); }
这样做的好处就是即便在运行时修改了种类,它也能够正常运行。但缺点就是慢,而且占用更多内存。如果确定种族属性不会改变,那么一个更快的解决方案就是构造时复制。
Breed(Breed* parent,int health,const char* attack) :health_(health),attack_(attack) { if(parent != NULL) { if(health == 0) health_ = parent->getHealth(); } if(attack == NULL) { attack_ = parent->getAttack(); } }
这样我们不用保留父种族,因为属性已经复制下来。接下来如果访问属性我们只要返回自己的属性值即可。
假设游戏引擎从json文件创建种族,数据示例如下:
{ "Troll":{ "health":25, "attack":"the troll hits you" }, "Troll Archer":{ "parent":"Troll", "health":0, "attack":"the troll archer hits you" }, "Troll wizard":{ "parent":"Troll", "health":0, "attack":"the troll wizard hits you" } }
清晰明了。
设计决策
类型对象设计模式让我们像在设计自己的编程语言一样设计一个类型系统,设计空间非常广阔,可以让我么尝试非常多的有趣的事情。但在实际的操作中,我们可能会遇到一些问题,比如时间开销和可维护性,而且最重要的是类型系统是给其他人用的,比如设计师,我们需要把它做的足够简单,越简单的东西其可用性越高。所以这里需要有一些点需要我们做出决策。
类型对象应该封装还是暴露
不管是封装还是暴露,都有其优点。如果把类型对象封装,我们得到的好处是:类型对象的复杂性对外部不可见;持有类型对象的类可以选择性的重写类对象的行为;但带来的缺点就是我们需要提供很多的内容转发函数(这些内容都是类型对象的),而且如果类型对象包含行为,也必须为这些行为提供相应的方法。
如果把类型对象暴露,那么外部代码在没有持有类型对象的实例的情况下就能访问类型对象,这样我们就能使用类型对象做一些事,比如创建一个新的怪物,同时类型对象现在是对象公共API一部分,通常窄接口比宽接口更容易维护,因为你暴露给代码库的越少,你要面对的复杂性和维护工作就越少。
持有类型对象如何创建
通过这种模式,其实现在的一个怪物对象是一对对象:主对象和它的类型对象。那现在如何把它们绑定起来了?
- 通过构造函数传入类型对象。这样外部代码可以控制内存分配,因为外部代码自己负责构造这两个对象,所以能控制其创建时间。
- 在类型对象上调用“构造函数”。也就是让类型对象来控制内存的分配,而好处就是之前描述的如果我们希望确保所有的对象都来自同一个特定的对象池或者内存分配器,那这么做就很方便。
类型能否改变
在上面的例子中,我们没有改变对象的类型。当然,我们可以在游戏中设计对象的类型不可改变,这样做的优点就是:
- 无论编码和理解都更简单;
- 同时也易于调试,因为类型始终不变,在调试bug的时候,事前就相对的简单,因为我们要处理的情况少了;
也可以让对象的类型可以改变,比如我们杀死了一个怪物,然后想让这个怪物变成一个僵尸,这个时候如果类型不可变,那么我们就需要创建一个新的“僵尸”对象,否则,我们就只需要改变其类型即可。所以,如果对象类型可以改变,则
- 将减少对象的创建
- 但代价就是做约束时更小心。因为对象和类型之间存在相对紧的耦合。比如一个怪物的当前血量永远不会超过该种族的初始血量,那么类型改变的时候,我们就需要执行一些验证来保证当前的状态符合新种族类型。
支持何种类型派生
我们可以选择:不派生、单继承、多重继承。
没有派生
- 简单;
- 可能会导致重复劳动,因为派生就是回了减少重复劳动。
单继承
- 相对仍然简单;
- 属性查找会更慢。因为一旦我们没有在当前对象中获取到属性,则需要在派生链中向上查找,直到找到或到达最上层。
多重派生
- 能避免绝大多数数据重复,甚至可以创建一个没有冗余的继承体系;
- 但代价就是复杂,而且很不幸的是,它的优点更多停留在理论上而不是实践上。根据现实的情况——c++的标准倾向于禁用多重派生,java和c#则完全不支持多重派生,我们不得不承认一个事实,让它正确工作太难了,以至于干脆设其它。

