


线程
线程的出现
进程和线程的关系
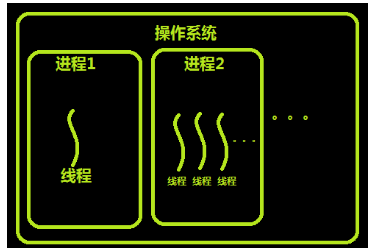
线程的特点
内存中的线程
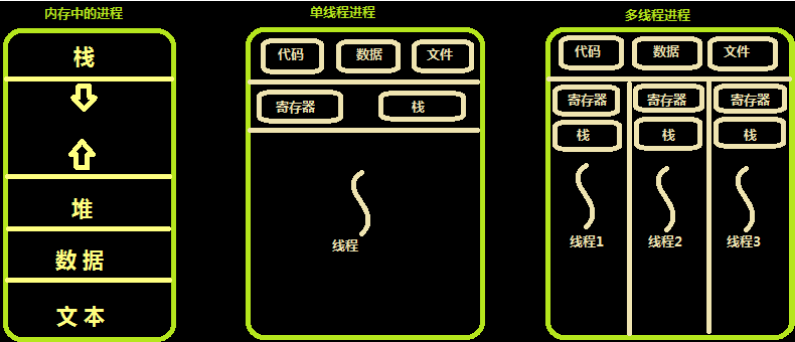
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。
不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程
2. 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢?
因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
用户级与内核级线程的对比


内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
用户级线程和内核级线程的区别
优点:当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:由内核进行调度
优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
允许每个进程定制自己的调度算法,线程管理比较灵活。
线程能够利用的表空间和堆栈空间比内核级线程多。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起。另外,页面失效也会产生同样的问题。
缺点:
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
用户级线程的优缺点
用户级与内核级的多路复用,内核同一调度内核线程,每个内核线程对应n个用户线程
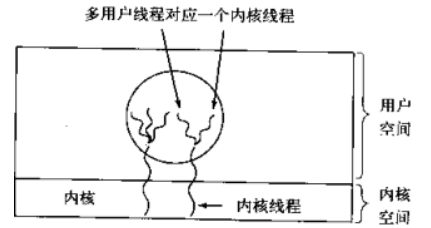
linux操作系统的 NPTL
历史 在内核2.6以前的调度实体都是进程,内核并没有真正支持线程。它是能过一个系统调用clone()来实现的,这个调用创建了一份调用进程的拷贝,跟fork()不同的是,这份进程拷贝完全共享了调用进程的地址空间。LinuxThread就是通过这个系统调用来提供线程在内核级的支持的(许多以前的线程实现都完全是在用户态,内核根本不知道线程的存在)。非常不幸的是,这种方法有相当多的地方没有遵循POSIX标准,特别是在信号处理,调度,进程间通信原语等方面。 很显然,为了改进LinuxThread必须得到内核的支持,并且需要重写线程库。为了实现这个需求,开始有两个相互竞争的项目:IBM启动的NGTP(Next Generation POSIX Threads)项目,以及Redhat公司的NPTL。在2003年的年中,IBM放弃了NGTP,也就是大约那时,Redhat发布了最初的NPTL。 NPTL最开始在redhat linux 9里发布,现在从RHEL3起内核2.6起都支持NPTL,并且完全成了GNU C库的一部分。 设计 NPTL使用了跟LinuxThread相同的办法,在内核里面线程仍然被当作是一个进程,并且仍然使用了clone()系统调用(在NPTL库里调用)。但是,NPTL需要内核级的特殊支持来实现,比如需要挂起然后再唤醒线程的线程同步原语futex. NPTL也是一个1*1的线程库,就是说,当你使用pthread_create()调用创建一个线程后,在内核里就相应创建了一个调度实体,在linux里就是一个新进程,这个方法最大可能的简化了线程的实现。 除NPTL的1*1模型外还有一个m*n模型,通常这种模型的用户线程数会比内核的调度实体多。在这种实现里,线程库本身必须去处理可能存在的调度,这样在线程库内部的上下文切换通常都会相当的快,因为它避免了系统调用转到内核态。然而这种模型增加了线程实现的复杂性,并可能出现诸如优先级反转的问题,此外,用户态的调度如何跟内核态的调度进行协调也是很难让人满意。 介绍
线程和python
全局解释器锁GIL
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python 虚拟机按以下方式执行:
a、设置 GIL;
b、切换到一个线程去运行;
c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0));
d、把线程设置为睡眠状态;
e、解锁 GIL;
d、再次重复以上所有步骤。
在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
threading模块
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍(官方链接)
线程的创建Threading.Thread类
线程的创建
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() print('主线程') 创建线程的方式1
from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print('%s say hello' % self.name) if __name__ == '__main__': t = Sayhi('egon') t.start() print('主线程') 创建线程的方式2
主线程默认等子线程执行完毕
import threading import time def func(arg): time.sleep(arg) print(arg) t1 = threading.Thread(target=func,args=(3,)) t1.start() t2 = threading.Thread(target=func,args=(9,)) t2.start() print(123)
setDaemon 主线程不再等,主线程终止则所有子线程终止
import time import threading def func(arg): time.sleep(2) print(arg) t1 = threading.Thread(target=func,args=(3,)) t1.setDaemon(True) t1.start() t2 = threading.Thread(target=func,args=(9,)) t2.setDaemon(True) t2.start() print(123)
开发者可以控制主线程等待子线程(最多等待时间)
import threading import time def func(arg): time.sleep(5) print(arg) print('创建子线程t1') t1 = threading.Thread(target=func,args=(3,)) t1.start() # 无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。 # 有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。 t1.join() print('创建子线程t2') t2 = threading.Thread(target=func,args=(9,)) t2.start() t2.join(2) # 让主线程在这里等着,等到子线程t2执行完毕,才可以继续往下走。 print(123)
创建子线程t1
3
创建子线程t2 t2睡5秒 只等两秒 所以先继续执行123 再打印9
123
9
设置线程名称 获取线程名称
def func(arg): # # 获取当前执行该函数的线程的对象 # t = threading.current_thread() # # 根据当前线程对象获取当前线程名称 # name = t.getName() # print(name,arg) # # t1 = threading.Thread(target=func,args=(11,)) # t1.setName('zhh') # t1.start() # # t2 = threading.Thread(target=func,args=(22,)) # t2.setName('zy') # t2.start() # # print(123)
zhh 11
zy 22
123
线程锁(Lock、RLock)
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,当多个线程同时修改同一条数据时可能会出现脏数据,所以,出现了线程锁 - 同一时刻允许一个线程执行操作。
#!/usr/bin/env python # -*- coding:utf-8 -*- import threading import time gl_num = 0 def show(arg): global gl_num time.sleep(1) gl_num +=1 print gl_num for i in range(10): t = threading.Thread(target=show, args=(i,)) t.start() print 'main thread stop' 未使用锁
import threading import time gl_num = 0 lock = threading.RLock() def Func(): lock.acquire() global gl_num gl_num +=1 time.sleep(1) print gl_num lock.release() for i in range(10): t = threading.Thread(target=Func) t.start()
信号量(Semaphore)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import time import threading lock = threading.BoundedSemaphore(3) def func(arg): lock.acquire() print(arg) time.sleep(1) lock.release() for i in range(20): t =threading.Thread(target=func,args=(i,)) t.start()
条件(Condition)
使得线程等待,只有满足某条件时,才释放n个线程
import time import threading lock = threading.Condition() def func(arg): print('线程进来了') lock.acquire() lock.wait() # 加锁 print(arg) time.sleep(1) lock.release() for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() while True: inp = int(input('>>>')) lock.acquire() lock.notify(inp) lock.release() 输入几 放行几个线程
def xxxx(): print('来执行函数了') input(">>>") # ct = threading.current_thread() # 获取当前线程 # ct.getName() return True def func(arg): print('线程进来了') lock.wait_for(xxxx) print(arg) time.sleep(1) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
事件(event)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
lock = threading.Event() def func(arg): print('线程来了') lock.wait() # 加锁:阻塞 print(arg) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() input(">>>>") lock.set() # 绿灯 lock.clear() # 再次变红灯 for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start() input(">>>>") lock.set()
GIL VS Lock
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果
既然是串行,那我们执行
t1.start()
t1.join
t2.start()
t2.join()
这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
threading.local
作用 : 内部自动为每个线程维护一个空间(字典),用于当前存取属于自己的值。保证线程之间的数据隔离。
v = threading.local() def func(arg): # 内部会为当前线程创建一个空间用于存储:phone=自己的值 v.phone = arg time.sleep(2) print(v.phone,arg) # 去当前线程自己空间取值 for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
import time import threading DATA_DICT = {} def func(arg): ident = threading.get_ident() DATA_DICT[ident] = arg time.sleep(1) print(DATA_DICT[ident],arg) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
import time import threading INFO = {} class Local(object): def __getattr__(self, item): ident = threading.get_ident() return INFO[ident][item] def __setattr__(self, key, value): ident = threading.get_ident() if ident in INFO: INFO[ident][key] = value else: INFO[ident] = {key:value} obj = Local() def func(arg): obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1) time.sleep(2) print(obj.phone,arg) for i in range(10): t =threading.Thread(target=func,args=(i,)) t.start()
线程池 一次指定开启线程个数,避免开启过多线程 增加cpu 上下文切换
from concurrent.futures import ThreadPoolExecutor import time def task(a1,a2): time.sleep(2) print(a1,a2) # 创建了一个线程池(最多5个线程) pool = ThreadPoolExecutor(5) for i in range(40): # 去线程池中申请一个线程,让线程执行task函数。 pool.submit(task,i,8)

