

迭代器、生成器、内置函数
一,迭代器
1.1什么是可迭代对象?
字符串、列表、元组、字典、集合都可以被for循环,说明他们都是可迭代的。
使用dir来查看该数据包含了那些方法
可迭代对象: Iterable, 里面有__iter__()可以获取迭代器, 没有__next__()
迭代器: Iterator, 里面有__iter__()可以获取迭代器, 还有__next__()
迭代器特点:
1. 只能向前.
2. 惰性机制.
3. 省内存(生成器)
for循环的内部机制.
1. 首先获取到迭代器.
2. 使用while循环获取数据
3. it.__next__()来获取数据
4. 处理异常 try:xxx except StopIteration:
l = [1,2,3,4] l_iter = l.__iter__() while True: try: item = l_iter.__next__() print(item) except StopIteration: break
for循环就是基于迭代器协议提供了一个统一的可以遍历所有对象的方法,即在遍历之前,先调用对象的__iter__方法将其转换成一个迭代器,然后使用迭代器协议去实现循环访问,这样所有的对象就都可以通过for循环来遍历了,而且你看到的效果也确实如此,这就是无所不能的for循环,最重要的一点,转化成迭代器,在循环时,同一时刻在内存中只出现一条数据,极大限度的节省了内存~
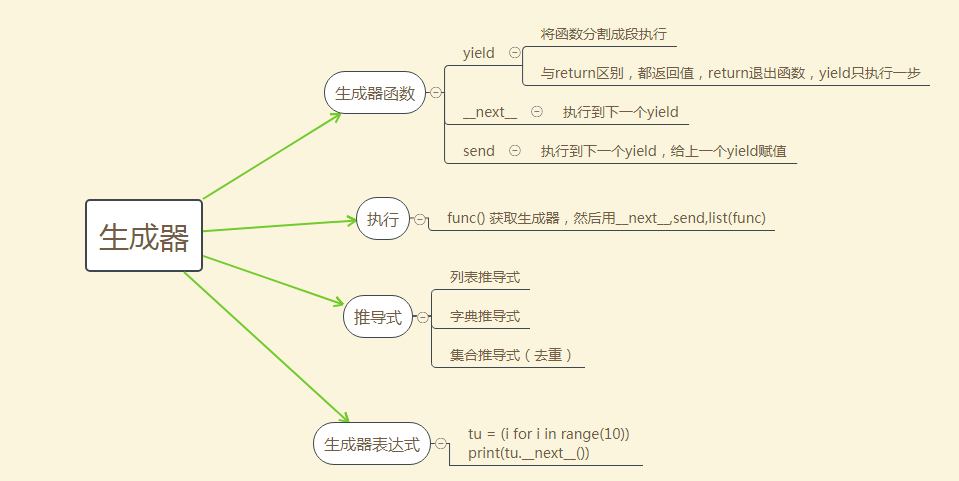
二,生成器
Python中提供的生成器:
生成器的本质就是迭代器
生成器的特点和迭代器一样.取值方式和迭代器一样(__next__(), send(): 给上一个yield传值).
生成器一般由生成器函数或者生成器表达式来创建
其实就是手写的迭代器
2. 生成器函数
和普通函数没有区别. 里面有yield的函数就是生成器函数.
生成器函数在执行的时候. 默认不会执行函数体. 返回生成器
通过生成器的__next__()分段执行这个函数.
send() 给上一个yield传值, 不能再开头(没有上一个yield), 最后一个yield也不可以用send()


def func(): print("娃哈哈") yield 1 # return和yield都可以返回数据 print("呵呵呵") gen = func() # 不会执行你的函数. 拿到的是生成器
函数中如果有yield 这个函数就是生成器函数. 生成器函数() 获取的是生成器. 这个时候不执行函数
yield: 相当于return 可以返回数据. 但是yield不会彻底中断函数. 分段执行函数.
gen.__next__() 执行函数. 执行到下一个yield.
gen.__next__() 继续执行函数到下一个yield.
def order(): lst = [] for i in range(10000): lst.append("衣服"+str(i)) return lst ll = order() def order(): for i in range(10000): yield "衣服"+str(i) g = order() # 获取生成器 mingwei = g.__next__() print(mingwei) zhaoyining = g.__next__() print(zhaoyining)
send() 和__next__()是一样的. 可以执行到下一个yield, 并可以给上一个yield位置传值
# def eat(): # print("我吃什么啊") # a = yield "馒头" # print("a=",a) # b = yield "鸡蛋灌饼" # print("b=",b) # c = yield "韭菜盒子" # print("c=",c) # yield "GAME OVER" # gen = eat() # 获取生成器 # # ret1 = gen. __next__() # print(ret1) # 馒头 # ret2 = gen.send("胡辣汤") # print(ret2) # # ret3 = gen.send("狗粮") # print(ret3) # ret4 = gen.send( "猫粮") # print(ret4)
最开始要先执行__next__, 第一个send 会执行图片圈住的代码
以此类推。next是不会给a赋值的,只有send获取下一个值时会给上一个yield赋值。最后一个yield不能接受外部的值
三,列表推导式和生成器表达式
推导式: 用一句话来生成一个列表
列表推导式
[结果 for 变量 in 可迭代对象 if 条件]
lst = [i for i in range(1,100) if i %2 ==0]
print(lst)
字典推导式
dic = {"jj": "林俊杰", "jay": "周杰伦", "zs": "赵四", "ln":"刘能"}
d = {v : k for k,v in dic.items()}
print(d)
[11,22,33,44] => {0:11,1:22,2:33}
lst = [11,22,33,44]
dic = {i:lst[i] for i in range(len(lst)) if i < 2} # 字典推导式就一行
print(dic)
语法:{k:v for循环 条件筛选}
集合推导式
可去除重复
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])
生成器表达式
# tu = (i for i in range(10)) # 没有元组推导式. 生成器表达式
# print(tu) # 生成器
# print(tu.__next__())
# print(tu.__next__())
# print(tu.__next__())
def add(a, b): return a + b # 生成器函数 # 0-3 def test(): for r_i in range(4): yield r_i # 0,1,2,3 g = test() # 获取生成器 for n in [2, 10]: g = (add(n, i) for i in g) print(g) print(list(g)) print(list(g))
output:
[20, 21, 22, 23]
[]
https://www.processon.com/mindmap/5b717e5ae4b0edb75106dc36
匿名函数 lambda 高阶函数 sorted filter map
lambda 函数:一句话概括一个函数 不需要def声明
语法:函数名 = lambda 参数:返回值
函数的参数可以有多个,用逗号隔开
f = lambda a:a**2
print(f(2))
sorted(iterable,key=None,reverse=False)
可迭代对象 排序函数 是否倒序
key: 排序方案, sorted函数内部会把可迭代对象中的每一个元素拿出来交给后面的key
后面的key计算出一个数字. 作为当前这个元素的权重, 整个函数根据权重进行排序
lst = [ {'name':"汪峰","age":48}, {"name":"章子怡",'age':38}, {"name":"xiaodong","age":39}, {"name":"张三","age":32}, {"name":"王五","age":28} ] ll = sorted(lst, key=lambda el: len(el['name']), reverse=True) print(ll)
lst=["麻花藤","马云","马宁儿","冈本五十六","1"] def func(s): return len(s) print(sorted(lst,key=func))
filter(function,iterable)
function 用来筛选的函数,在filter中会自动把iterable中的元素传递给function,然后根据function返回的True或者False来判断是否保留此项数据
lst = [ {"name":"汪峰", "score":48}, {"name":"章子怡", "score":39}, {"name":"赵一宁","score":97}, {"name":"石可心","score":90} ] f = filter(lambda el: el['score'] < 60 , lst) # 去16期的人 print(list(f))
map(function,iterable)
对可迭代对象中的每一个元素进行映射 分别取出执行function
ret = map(lambda x: x*x,[1,2,3,4,5]) print(list(ret))
lst1 = [1,2,3,4,5] lst2 = [2,4,6,8,10] print(list(map(lambda x,y:x+y,lst1,lst2)))
递归
在函数中调用函数本身 就是递归
def func(): print("我是谁") func() func()
递归的应用:
可以使用递归来遍历各种树形结构,比如我们的文件系统,可以使用递归来遍历文件夹中的所有文件
import os def read(filepath,n): files = os.listdir(filepath) for fi in files: fi_d = os.path.join(filepath,fi) if os.path.isdir(fi_d): print("\t"*n,fi) read(fi_d,n+1) else: print("\t"*n,fi) read('../',0)
二分查找
二分查找,每次能够排除掉一半的数据,查找的效率非常高。但局限性比较大,必须是有序序列才能使用二分查找
lst = [22, 33, 44, 55, 66, 77, 88, 99, 101 , 238 , 345 , 456 , 567 , 678 , 789] def func(n, left, right): if left <= right: # 边界 print("哈哈") mid = (left + right)//2 if n > lst[mid]: left = mid + 1 return func(n, left, right) # 递归 递归的入口 elif n < lst[mid]: right = mid - 1 # 深坑. 函数的返回值返回给调用者 return func(n, left, right) # 递归 elif n == lst[mid]: print("找到了") return mid # return # 通过return返回. 终止递归 else: print("没有这个数") # 递归的出口 return -1 # 1, 索引+ 2, 什么都不返回, None # 找66, 左边界:0, 右边界是:len(lst) - 1 ret = func(70, 0, len(lst) - 1) print(ret) # 不是None
