计算机体系结构之一--体系结构【译】
说明
本文翻译自斯坦福开放课程【编程范式】的系列课件,有删改。
本系列会持续更新,预计一周发布1到2篇。
如有意见/建议或是存在版权问题,欢迎园友指正。
转载无需通知本人,但请注明出处,谢谢!
计算机体系结构
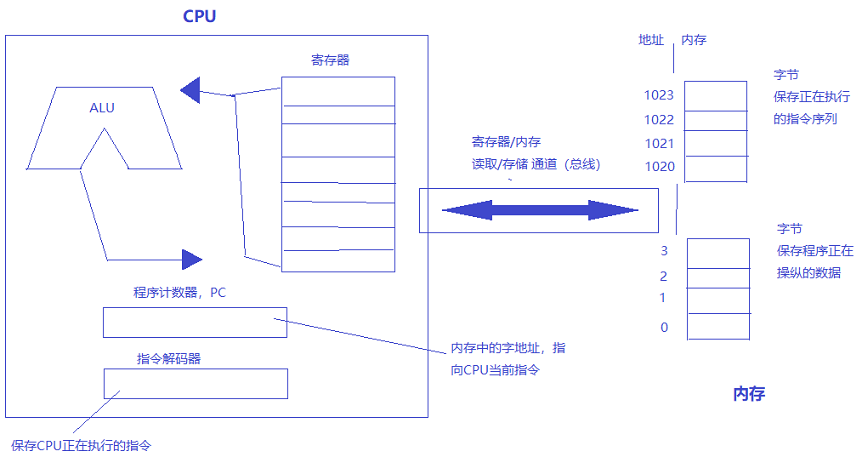
下面这个简明的图片描述了计算机原型的主要特征。CPU是执行所有工作的场所,内存是所有代码和数据存放的地方,连接这两者的通路叫做总线。
CPU
当内存保存程序和数据的时候,中央处理单元执行所有的工作。CPU有两个部分--寄存器和算数逻辑单元(ALU)。一个寄存器就像计算器中的临时内存--每个寄存器能存储一个值,这些值用于后边的计算。每个寄存器只能保存一个字。有的寄存器专用于保存特殊类型的数据--浮点数,地址,等等。寄存器存取速度比内存快得多,但是寄存器的可用数量相比内存来就小得多了。有一种很特殊的寄存器叫程序计数器,简称PC,保存着当前执行指令的地址。
ALU是CPU的一部分,负责执行加法、乘法等算数操作和比较等逻辑操作。大部分现代的、高性能的CPU实际除了ALU之外,还包括了若干特殊的逻辑单元,允许CPU执行并行计算。然而,这种复杂度只存在于CPU内部。我们只消把CPU抽象一下,假定它会按照指令在内存中出现的顺序,一次一条地执行下去。
为了这份讲义的平衡性,我们把注意力集中在一个精简指令集计算机(RISC)处理器的指令集上。相对来说,处理器指令集更简洁的就是RISC。精简指令集是处理器的好搭档,接着让我们关注下怎样最大程度地利用处理器的指令集。RISC处理器没有那些牛逼的指令,也没有那些用早期的复杂指令集(CISC)设计的寻址模式。RISC的好处是易于学习,因为指令集已经被很好地精简过了。
假设我们有一个内置32个寄存器的处理器,每个寄存器能放置一个4字节大小的字。处理器支持3类指令:Load/Store 指令能在寄存器和内存之间来回地移动字节,ALU指令作用于寄存器,Branch/Jump指令修改接下来要执行的指令。
Load指令
load指令把字节读到寄存器中。来源可能是一个常量值,另一个寄存器,或者是内存中的一个定位。在我们的简单语言里,一个内存定位被表达成Mem[address],address可能是一个数字常量,一个寄存器,或者一个寄存器加上一个常数偏移量。Load和Store从给定的地址开始搬动字节,通常是一次移动一整个字。如果要移动小于一个字的字节,可以用变体“=.1”(1字节)和“=.2”(2字节)。
把常量23搬运到寄存器4号 R4 = 23 把寄存器2号中的常量复制到寄存器3号 R3 = R2 从内存中地址是244的地方把一个字符(一个字节)搬运到寄存器6号 R6 = .1 Mem[244] 从寄存器1号读取一个地址,把保存在寄存器5号中的整个字搬运到内存中这个地址对应的地方 R5 = Mem[R1] 取出寄存器1号中存放的地址,在内存中找到这个地址,往后跳过8个字节,从这个新的地址开始,搬运一个字到寄存器4号。这被称“偏移量”模式,它是RISC处理器所支持的寻址模式中最奇怪的一个。 R4 = Mem[R1+8]
为了说明这一切是怎样和真实世界关联的,下面给出Motorola 68000编译器执行load指令时的情况:
把长常量(4个字节)15搬运到寄存器d2 move1 #15, d2 在内存中找到地址0x40x,从这个地址开始把一个长常量搬运到a0寄存器 move1 @#0x40c, a0
在Sparc编译器里,看起来是这个样子:
把寄存器o0存放的地址取出,加上常数偏移量20(跳过20个字节),作为开始地址从内存把一个字加载到到寄存器o1 ld [ %o0 + 20 ], %o1
我们设计的汇编语法易读又好学,只是和现代的RISC指令集比起来,它的基础功能还是太少了。
Store指令
store指令基本上和load指令相反--它把值从寄存器搬回到内存中。在RISC体系结构中,没办法把字节直接从内存的一个地方移动到内存的另一个地方。你只能使用load指令把字节搬到寄存器里,然后再用store指令把它们搬回到内存。
把数字37搬到(store)从位置400开始的字中 Mem[400] = 37 把存在寄存器R6中的字搬到(store)R1里 Mem[R1] = R6 把R2中低位置开始的半个字搬到(store)内存中从1024开始的两个字节 Mem[1024] = .2 R2 把寄存器R7中的字搬到(store)内存,开始地址比R1中的值多12 Mem[R1 + 12] = R7
ALU
算数逻辑单元(ALU)的指令很像计算器上的操作键。ALU的操作只会作用在寄存器和常量上。有的处理器甚至不允许ALU处理常量。(你需要先把常量装载到寄存器里)。
把R3的值加3,把结果搬到R1上 R1 = 6 + R3 用R2的值减去R3的值,把结果搬到R1上 R1 = R2 - R3
虽然我们会不加区分地滥用“+”号,但处理器通常持有两个不同的版本,一个给整数用另一个给浮点数用,调用时使用两条不同的指令,比如,Sparc使用add和fadd。整数计算通常比浮点计算更有效率,因为操作更简单(比如,不需要标准化)。除法是目前为止最昂贵的算术操作,对两种类型都是,而且通常不是一条单指令,而是一个“微代码”程序(可以当成一个非常快的、顺手执行的函数)。
分流
默认情况下,CPU按一定的顺序从内存接收和执行指令,从内存的低地址到高地址。branch指令修改这个默认规则。branch指令测试完一个条件,可能会通过修改PC寄存器的值来修改下一条要执行的指令。所有处理器都会大量使用的一种情形是,测试两个值是否相等,若不等,一个是否比另一个小(或比另一个大)。branch指令执行测试时操作的两个东西一定要是寄存器里的值或者常数。branch指令被用于实现控制结构,像if、switch、还有循环结构像for和while。
如果R1的值等于常数0,执行从内存地址344开始的指令,“branch判断是否相等” BEQ R1, 0, 344 如果R2的值小于R3的值,开始从当前指令地址加8的位置执行下一条指令,“branch判断是否小于” BLT R2, R3, PC+8
下面是全部的branch类指令:
BLT 判断第一个参数是否小于第二个
BLE 小于等于
BGT 大于
BGE 大于等于
BEQ 相等
BNE 不相等
所有的branch指令都会比较它前两个参数(都必须是常量或寄存器),然后把控制流强行转到第三个参数那里。目标地址可以被指定为一个绝对地址,比如356,或者是相对PC地址的偏移量,比如PC-8或者PC+12。后边的写法方便你跳过一些指令(包括向前跳),这和循环语句、条件判断的执行模式十分接近。
还有一种不需要判断的无条件跳转,仅仅是立即把执行流转移到一个新的地址。它有一点很像branch指令,支持绝对地址和PC偏移量。
无条件地从地址2000开使执行-像goto Jmp 2000 从当前地址之后12个地址开始执行 Jmp PC-12
数据转换
还有两个实用的指令能把值在整型和浮点型之间做转换。记住,浮点数1.0和整数1有着天差地别的位排列,所以需要一些指令来做转换。这些指令也会在寄存器结构不一致的计算机之间传递浮点数和整数时被用到。
拿出R3总存放的比特位,转成浮点型,存到R2中
R2 = ItoF R3
拿出R4中的比特位,从浮点型转成整型,存回R4,这种直接转化导致了信息丢失,小数部分被切去,然后丢失
R4 = FtoI R4
总结
虽然我们忽视掉了一些东西(算数逻辑单元中的逻辑部分,or/not,和一些用于支持函数调用/返回的操作),但这个小小的指令集给能你一种很好的想法:这些典型的CPU能用指令集来做些什么。编译器能提供像C一样丰富而复杂的编程语言,产生了和for循环、数组引用,函数调用很相似的东西,并且把它们转化成一个由简单指令组成的恰当的序列。
(全文终)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号