2.2.5 缓存内存【译】
历史上,CPU一直比内存快得多。虽然内存在进步,CPU也是,一直保持在不*衡状态。实际上,在芯片上放置越来越多的电路是可能的,CPU设计者对这些新设备应用流水线和超标量操作,使得CPU愈发快了。内存设计者通常使用新技术来增加芯片的能力而不是速度,所以这种速度不一致问题随着时间的流逝愈发严重。这种不*衡实际上意味着,在CPU发出内存请求后,它不能在少量的CPU周期内获取需要的字。内存速度越慢,CPU需要等待的周期就越多。
正如我们前面指出的,有两种方式结局这个问题。最简单的办法是,当遇到READ指令时直接从内存开始读,但是如果一条指令尝试在内存字抵达之前使用它,继续执行指令并暂停CPU。内存越慢,上述时间发生时带来的损害就越大。比如,如果一条指令操作内存5次,内存的存取时间是5个时钟周期,执行时间是用瞬时内存的两倍。但是如果内存存取时间是50个周期,执行时间会上升到原来的11倍(5个周期执行指令加上50个周期等待内存)。
另一种解决方案是不让机器暂停,取而代之的是令编译器在内存字抵达之前不产生代码。问题是这个方法说起来容易做起来难。为了让LOAD指令后面没有其他操作,编译器会强制插入NOP(no operation)指令,该指令啥也不干,占着位置浪费时间。实际上,虽然这个方法用软件暂停代替了硬件暂停,但是对性能的破坏是一样的。
实际上,不是技术上的问题,是钱的问题。工程师们知道怎样构建比CPU还快的内存,但若要它们全速运行,它们必须位于CPU芯片上(因为通过总线连接内存太慢了)。在CPU芯片上放置一个很大的内存会让CPU变得更大,它的造价也会更高,就算钱不是问题,造出的CPU芯片的体积是有限制的。这样就面临一个选择,是用少量的快速内存还是大量的慢速内存。大量的快速内存实在太贵。
有趣的是,有些技术能结合少量的快速内存和大量的慢速内存来达到接*快速内存的速度,大量内存提供的性能相比于它的价格也很不错。这种小而快的内存被称作缓存(cache,源自法语cacher,意思是隐藏,读音从“cash”)。下面我们会简要地说明缓存的使用方法和工作原理。更详细的描述将在第四章给出。
缓存背后的想法很简单:把最常用的内存字保存在缓存中。当CPU需要一个字时,首先从缓存里查找。只有当缓存里没有的时候才会去主存里找。如果大部分字都在缓存中,*均存取时间就会大大地减少。
成功或失败取决于把多少比例的字放在缓存中。多年以来,人们已经知道程序读取内存的时候并不是完全地随机。如果一个给定的内存引用指向地址A,下一个内存引用很可能在A附*。最简单的例证就是程序它自己。除了分支和过程调用之外,指令会从连续的内存地址中读取。此外,程序大部分执行时间花费在循环上,在循环中几个指令翻来覆去地执行。相似地,一个矩阵运算程序可能会在操作其他事物之前引用相同的矩阵多次。
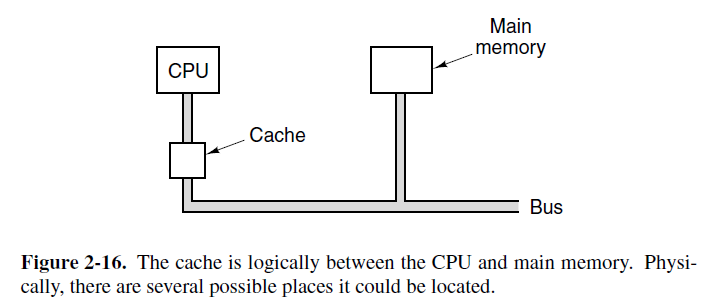
这种一小段时间内,只会使用总内存中一小部分内存的现象被称作局部性原则,它是缓存系统的基础。一般想法是,当一个字被引用,把它和它的某些邻居们从慢速内存带到缓存中,这样下次使用它时,可以很快地获取到。CPU,缓存和主存的通用安排如图2-16所示。如果一个字短时间内读写K次,计算机需要引用慢速内存1次,快速内存k-1次。k越大,整体性能就越好。
我们可以通过引入c来把计算过程形式化,c是缓存存取时间,m是主存存取时间,命中率h指的是使用缓存的引用占总引用的比例。在我们上图的小例子中,h=(k-1)/k。有些作者还定义了未中率,为1-h。
有了这些定义,我们按照以下方式计算*均存取时间:
*均存取时间=c+(1-h)m
当h->1时,所有的引用都命中缓存,存取时间*似于c。另一方面,假如h->0,每次引用都需要内存,连接时间*似于c+m,时间c用于检查缓存(就算没命中),时间m用于引用内存。在某些系统中,内存引用可以和缓存查找同时开始,所以如果缓存没有命中,内存周期已经开始了。然而,这个策略需要追踪到缓存命中后停止内存,实现起来更复杂些。
用局部性原则作为指导,主存和缓存被分割成固定尺寸的区块。当讨论缓存内的这些区块时,我们会把它们称作缓存线。如果缓存没有命中,整条缓存线从内存加载到缓存中,而不仅仅是要用到的字。比如,一条64字节的线,一个对内存地址260的引用将会拉出包括字节256到319的一条线。运气好一点的话,缓存线中的其他字也会被用到。这种方式要比读取单个字更有效率,因为一次请求k个字,比每次一个字请求k次更快。还有,持有超过一个字的整个缓存意味着这种缓存的数量很少,因此,花费的管理代价更小。最后,许多计算机能在一个总线周期上并行传输64位或128位,即使是32位机器。
在高性能CPU领域,内存设计是一个重要性逐渐增长的主题。第一个问题就是缓存大小。缓存越大,它的性能越好,但存取速度也越慢,造价越高。第二个问题是缓存线的大小。一块16KB的缓存可以被分割成1024条16字节的缓存线,2048条8字节的,或者其他组合。第三个问题是缓存的组织方式,确切的说,缓存怎样追踪当前保存的内存字的数量?我们将在第四章研究缓存的细节。
第四个设计问题是指令和数据该不该放在同一块缓存中。使用统一缓存(指令和数据使用同一块缓存)是一个更简单的设计,而且自动地对指令读取和数据读取做出权衡。这种设计也叫作哈佛结构,一切都起源哈佛Aiken的Mark 3计算机,它的指令和数据使用不同的内存。流水线CPU的广泛使用给予设计师以强烈驱动。指令请求单元需要访问指令,与此同时操作数请求单元需要访问数据。分离存储的换成允许并行访问;混合存储的不能。还有,因为指令在执行期间无法被修改,指令本身的缓存不用写回到内存中。
最后,第五个问题涉及到缓存块的数量。*来很*常的芯片有一个位于芯片上的主要缓存,一个远离芯片,但和芯片打包在一起的二级缓存,还有一个更远的三级缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号