

One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL草读
One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL(增强学习,针对小样本鲁棒性场景)
NIPS-2020
abstract:reinforcement learning 在一些复杂任务场景下有较好的效果,但是即使在微小的任务变化下,这种方法有一定的脆弱性,尤其是微小的任务变化在训练过程中不能被明显提供的情况下。为了解决这个问题,自然的解决方法是在训练集中加入扰动,但是在不影响性能条件下在训练集中加入扰动是十分困难的,解决此问题的关键在于学习在不同环境下的行为能够使得模型能够适应不同的环境,这样就不需要在训练集中加入扰动。在训练过程中,针对一个场景获得多个解决方案,本文的方法能够在新的任务场景下,使用对这个新场景有效的解决方案,放弃无效的解决方案。从理论上描述了一组由算法产生的鲁棒的环境,实验说明算法模型具有鲁棒性。
内容:
1、点出RL的问题:即高性能但是偏向专门化。
2、目前的解决方法:在一个训练集的分布上进行训练,训练集环境分布代表环境发生的不同变化,但是这种方法会影响到性能条件。
3、本文方案:从一个训练集寻找到的多个解决方案,当一种解决方案不能使用时,可以采用其他的解决方案,这样自然具有鲁棒性。通过这种方法,构建了一个鲁棒性模型。
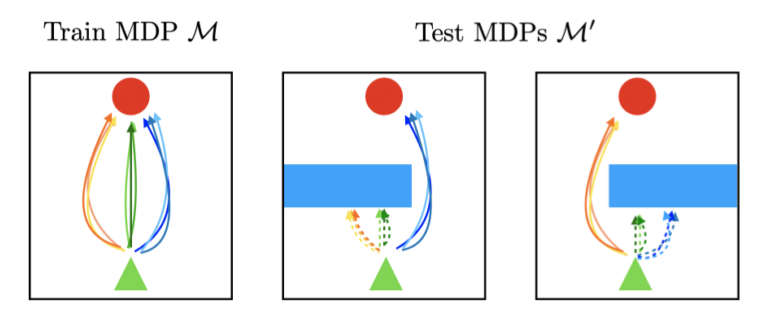
4、

