
hbase 预分区与自动分区
我们知道,HBASE在创建表的时候,会自动为表分配一个Region,
当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以此类推。
表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
所以,HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
假设我们初始给它10个Region,那么导入大量数据的时候,就会均衡到10个里面,显然比1个Region要好很多。
可是我们应该创建多少个Region呢?显然没有具体答案,要结合业务,根据表的rowkey进行设计。
一.强制拆分
预分区方法:
1.hbase shell 预分区
建立分区前,要先了解表的rowkey格式,rowkey为:两位随机数+时间戳+客户id
两位随机数的范围从00-99,划分范围:小于10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,90+
hbase(main):001:0> create 'log1', 'cf1', SPLITS => ['10','20','30','40','50','60','70','80','90']
启动webUI
vi hbase-site.xml
添加
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
浏览器中:
http://h201:60010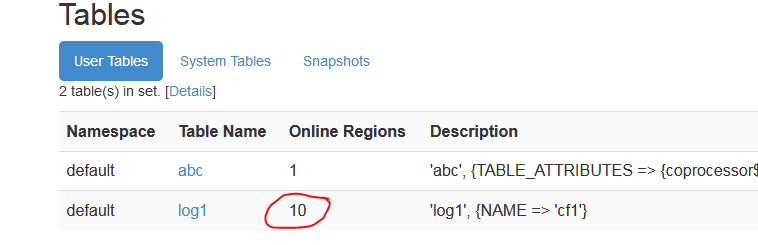
通过配置文件加载
[hadoop@h201 ~]$ cat rs.txt
10
20
30
40
50
60
70
80
90
hbase(main):003:0> create 'log2', 'cf1', SPLITS_FILE =>'/home/hadoop/rs.txt'
2.HBASE API 预分区
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.util.Bytes; public class Cp { public static void main(String[] args) { HBaseConfiguration config = new HBaseConfiguration(); config.set("hbase.zookeeper.quorum", "h201,h202,h203"); String tablename = new String("ctest1"); try{ HBaseAdmin admin = new HBaseAdmin(config); if (admin.tableExists(tablename)) { admin.disableTable(tablename); admin.deleteTable(tablename); } HTableDescriptor tableDesc = new HTableDescriptor(tablename); tableDesc.addFamily(new HColumnDescriptor("cf1")); byte[][] splitKeys = { Bytes.toBytes("10"), Bytes.toBytes("20"), Bytes.toBytes("30") }; admin.createTable(tableDesc, splitKeys); admin.close(); }catch(IOException e) { e.printStackTrace(); } } }
验证:
webUI查看
ctest1有4个 预分区
====================================================
二.自动拆分(Auto splitting)
1.
0.94 版本之前采用的是 ConstantSizeRegionSplitPolicy 策略。
这个策略非常简单,从名字上就可以看出这个策 略就是按照固定大小来拆分Region。它唯一用到的参数是: hbase.hregion.max.filesize, 默认值是 10G, 也就是当 Region 的大小达到 10G 的时候, 会自动拆分成两个 Region.
2.
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。并且默认使用的这种策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。
这种策略使用的最大store file size依据 Min(R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”),R代表同一台Region Server节点上的region的个数。比如,在默认memstore flush size为128MB且默认的max store size为10G时。(R为region的个数)
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
可以看到,只有在第四次之后的拆分大小才为10G
