spark基于不同模式下搭建集群及spark资源请求任务调度,广播变量和累加器
standalone模式搭建
1、上传解压,配置环境变量 配置bin目录 2、修改配置文件 conf mv spark-env.sh.template spark-env.sh添加以下代码
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
master相当于RM worker相当于NM,增加从节点配置
mv slaves.template slaves
node1
node2
3、复制到其它节点
scp -r spark-2.4.5 node1:`pwd`
scp -r spark-2.4.5 node2:`pwd`
4、在主节点执行启动命令 启动集群,在master中执行
./sbin/start-all.sh
http://master:8080/ 访问spark ui
-
standalone client模式 日志在本地输出,一班用于上线前测试(bin/下执行)
需要进入到spark-examples_2.11-2.4.5.jar 包所在的目录下执行
cd /usr/local/soft/spark-2.4.5/examples/jars
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100
-
standalone cluster模式 上线使用,不会再本地打印日志
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --driver-memory 512m --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100
spark-shell spark 提供的一个交互式的命令行,可以直接写代码
spark-shell --master spark://master:7077
运行自己写的代码 1、注释掉setMaster 2、将项目打包 3、上擦到服务器 4、提交任务 spark-submit --class com.shujia.spark.core.Demo18PI --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-1.0.jar
package sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object Demo18PI {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("PI").setMaster("local")
val sc = new SparkContext(conf)
val list: Range = 0 until 10000000
//构建一个很大的RDD
val listRDD: RDD[Int] = sc.parallelize(list)
//模拟生成点
val pointRDD: RDD[(Double, Double)] = listRDD.map(i => {
//模拟点
val x: Double = Random.nextDouble() * 2 - 1
val y: Double = Random.nextDouble() * 2 - 1
(x, y)
})
//取出园内的点
val yuanPointRDD: RDD[(Double, Double)] = pointRDD.filter {
case (x: Double, y: Double) =>
//计算点到圆心的距离
x * x + y * y <= 1
}
//计算PI值
val PI: Double = yuanPointRDD.count().toDouble / list.length * 4.0
println("PI:"+PI)
}
}
整合yarn搭建Spark集群
在公司一般不适用standalone模式,因为公司一般已经有yarn 不需要搞两个资源管理框架停止spark集群 在spark sbin目录下执行 ./stop-all.sh
spark整合yarn只需要在一个节点整合, 可以删除node1 和node2中所有的spark 文件
1、增加hadoop 配置文件地址
vim spark-env.sh
增加
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop
2、往yarn提交任务需要增加两个配置 yarn-site.xml(/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml)
先关闭yarn stop-yarn.sh
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4、同步到其他节点,重启yarn
scp -r yarn-site.xml node1:`pwd`
scp -r yarn-site.xml node2:`pwd`
启动yarn start-yarn.sh
cd /usr/local/soft/spark-2.4.5/examples/jars
3.spark on yarn client模式 日志在本地输出,一班用于上线前测试
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512M --num-executors 2 spark-examples_2.11-2.4.5.jar 100
4.spark on yarn cluster模式 上线使用,不会再本地打印日志 减少io
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 2 --executor-cores 1 spark-examples_2.11-2.4.5.jar 100
获取yarn程序执行日志 执行成功之后才能获取到 yarn logs -applicationId application_1626695992877_0001

运行自己写的代码 1、注释掉setMaster, 修改输入输出路径 2、将项目打包 3、上擦到服务器 4、提交任务
spark-submit --class com.shujia.spark.core.Demo20Submit --master yarn-cluster --executor-memory 512m --total-executor-cores 1 spark-1.0.jar
杀死yarn 任务 yarn application -kill application_1626660789491_0012
hdfs webui http://node1:50070
yarn ui http://node1:8088
Spark资源申请和任务调度
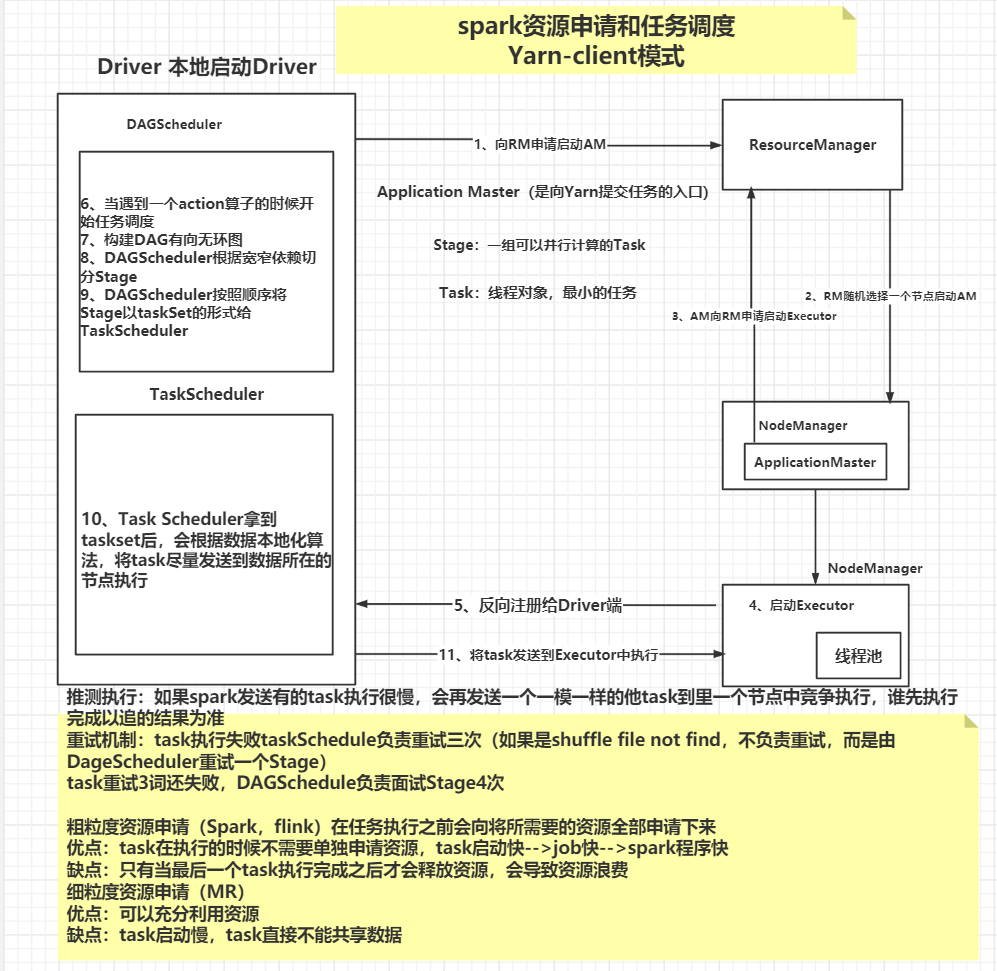
Spark运行流程
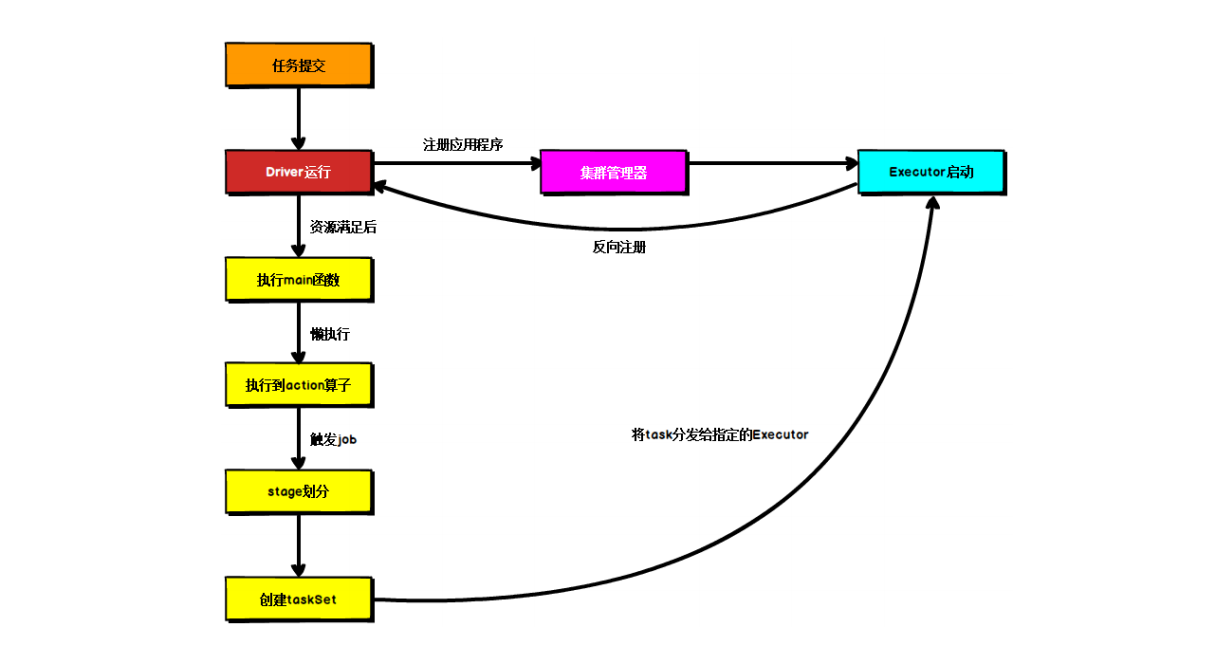
1) 任务提交后,都会先启动 Driver 程序;
2) 随后 Driver 向集群管理器注册应用程序;
3) 之后集群管理器根据此任务的配置文件分配 Executor 并启动;
4) Driver 开始执行 main 函数,Spark 查询为懒执行,当执行到 Action 算子时开始反向推算,根据宽依赖进行 Stage 的划分,随后每一个 Stage 对应一个 Taskset,Taskset 中有多个 Task,查找可用资源 Executor 进行调度;
5) 根据本地化原则,Task 会被分发到指定的 Executor 去执行,在任务执行的过程中,Executor 也会不断与 Driver 进行通信,报告任务运行情况。
累加器
package sparkcore
import java.lang
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object Demo21Accumulator {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("Accumulator")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(List(1,2,3,4,5,6,7,8,9))
/**
* 累加器,只能累加
*
* 累加器只能在Driver中定义
* 累加器只能在Executor累加
* 了假期只能在Driver读取
*/
//1、在Driver端定义累加器
val accumulator: LongAccumulator = sc.longAccumulator
rdd.foreach(i=>
//2、在Executor端进行累加
accumulator.add(i)
)
//3、在Driver带你去累加结果
val count: lang.Long = accumulator.value
println(count)
/**
* 累加器的使用
* 如果不使用累加器需要单独启动一个job计算总人数
* 使用了假期,乐嘉计算和班级人数的计算在一起计算出来
*/
val students: RDD[String] = sc.textFile("data/students.txt")
//定义累加器
val studentsNum: LongAccumulator = sc.longAccumulator
val KvRDD: RDD[(String, Int)] =students.map(stu=>{
//累加
studentsNum.add(1)
val clazz: String = stu.split(",")(4)
(clazz,1)
})
val clazzNumRDD: RDD[(String, Int)] = KvRDD.reduceByKey(_+_)
//学生总人数
val stuNum: lang.Long = studentsNum.value
clazzNumRDD.foreach(println)
}
}
package sparkcore
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo22Broadcast {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Broadcast").setMaster("local")
val sc = new SparkContext(conf)
val students: RDD[String] = sc.textFile("data/students.txt")
// val ids = List("1500100983","1500100911","1500100932","1500100915","1500100961")
//
// val studentfilter: RDD[String] =students.filter(stu=>{
// val id: String = stu.split(",")(0)
// ids.contains(id)
// })
// studentfilter.foreach(println)
/**
* 广播变量
*/
val ids = List("1500100983", "1500100911", "1500100932", "1500100915", "1500100961")
//1、在Driver端将一个变量广播出去
val broId: Broadcast[List[String]] = sc.broadcast(ids)
val filterRDD: RDD[String] = students.filter(student => {
val id: String = student.split(",")(0)
//2、在Executor使用广播变量
val value: List[String] = broId.value
value.contains(id)
})
filterRDD.foreach(println)
/**
* 广播变量的应用
*
* 实现map join
* 将小表加载到内存中,在map端进行关联
*/
val students1: RDD[String] = sc.textFile("data/students.txt")
val scores: RDD[String] = sc.textFile("data/score.txt")
/**
* collect:将RDD的数据拉取到RDriver端的内存中
*/
val list: Array[String] = students1.collect()
val studentMap: Map[String, String] = list.map(stu => {
val id: String =