spark学习
Spark定义
spark是一种基于内存的快速、通用、可扩展S的大数据分析计算引擎
Spark Core 中提供了Spark最基础核心的功能 Spark SQL是Spark用来操作结构化数据的组件 Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的ApI
Spark和Hadoop
Spark和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
Hadoop mapreduce在并行运行的苏剧可复用场景存在很多计算效率问题,Spark在Hadoop的MapReduce计算框架基础上而诞生,大大加快了数据分析,数据挖掘和读写速度,将计算单元缩小到更适合并行计算和重复使用的RDD计算模型
Spark是一个分布式数据快速分析项目,核心技术就是弹性分布式数据集RDD,提供了比MR丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图像计算算法
Spark只有在shuffle的时候会将数据写入磁盘当中,而Hadoop的MR作业需要依赖磁盘交互,Spark的缓存机制比HDFS的更高效
Spark核心模块

Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,
Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
➢ Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL
或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
➢ Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理
数据流的 API。
➢ Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等
额外的功能,还提供了一些更底层的机器学习原语。
➢ Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
Spark运行环境
本地模式
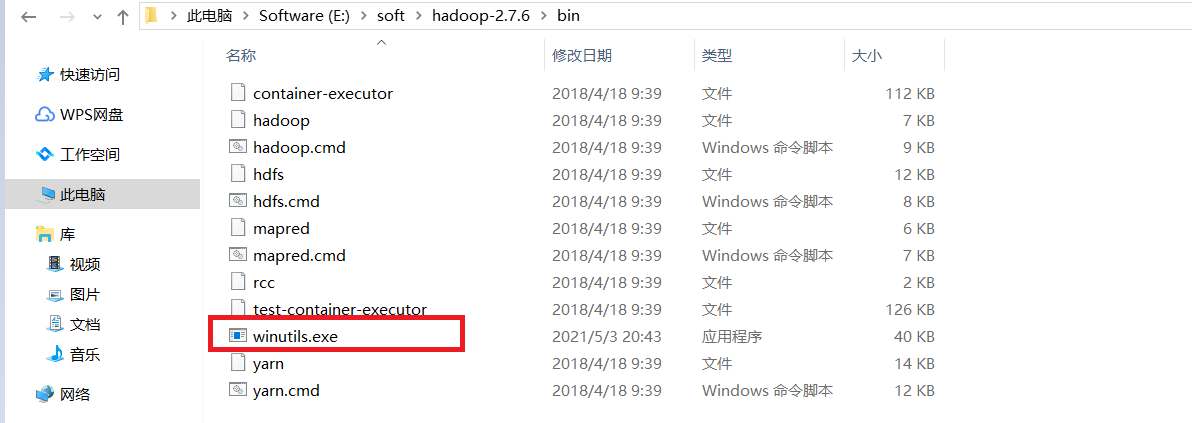
将Hadoop2.7.6的压缩包解压到指定目录文件夹,在bin文件下添加winutils.exe
在idea添加依赖,Scala相应的插件也要下载,下载后重启idea就好了
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<