
Spring Boot + Spring Cloud 实现权限管理系统 后端篇(二十二):链路追踪(Sleuth、Zipkin)
在线演示
演示地址:http://139.196.87.48:9002/kitty
用户名:admin 密码:admin
技术背景
在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个看似简单的前端请求可能最终需要调用很多次后端服务才能完成,那么当整个请求出现问题时,我们很难得知到底是哪个服务出了问题导致的,这时就需要解决一个问题,如何快速定位服务故障点,于是,分布式系统调用链追踪技术就此诞生了。
ZipKin
Zipkin 是一个由Twitter公司提供并开放源代码分布式的跟踪系统,它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告定时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示了多少跟踪请求经过了哪些服务,该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可非常方便的监测系统中存在的瓶颈。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。我们可以跟根据需求选择不同的存储方式,生成环境一般都需要持久化。我们这里采用elasticsearch作为zipkin的数据存储器。
Spring Cloud Sleuth
一般而言,一个分布式服务追踪系统,主要有三部分组成:数据收集、数据存储和数据展示。
Spring Cloud Sleuth为服务之间的调用提供链路追踪,通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外,Sleuth还可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时。
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到。
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
实现案例
在早前的Spring Cloud版本里是需要自建zipkin服务端的,但是从SpringCloud2.0 以后,官方已经不支持自建Server了,改成提供编译好的jar包供用户使用。因为我用的是2.0以后的版本,自建Servcer的方式请自行百度。这里我们是使用docker方式部署zipkin服务,并采用elasticsearch作为zipkin的数据存储器。
下载镜像
此前请先安装好docker环境,使用以下命令分别拉取zipkin和elasticsearch镜像。
docker pull openzipkin/zipkin
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.3.0
通过 docker images 查看下载镜像。

编写启动文件
在本地创建如下文件夹结构, data目录用来存放elasticsearch存储的数据。
dockerfile |- elasticsearch | |- data |- docker-compose.yml
编写docker-compose文件,主要作用是批量启动容器,避免在使用多个容器的时候逐个启动的繁琐。
docker-compose.yml

version: "3" services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:6.3.0 container_name: elasticsearch restart: always networks: - elk ports: - "9200:9200" - "9300:9300" volumes: - ../elasticsearch/data:/usr/share/elasticsearch/data zipkin: image: openzipkin/zipkin:latest container_name: zipkin restart: always networks: - elk ports: - "9411:9411" environment: - STORAGE_TYPE=elasticsearch - ES_HOSTS=elasticsearch networks: elk:
关于docker-compose.yml 文件格式及相关内容请自行百度了解。
启动服务
命令模式进入dockerfile目录,执行启动命令如下。
docker-compose up -d
执行过程如下图所示。

执行完成之后,通过 docker ps 命令查看,发现zipkin和elasticsearch确实启动起来了。
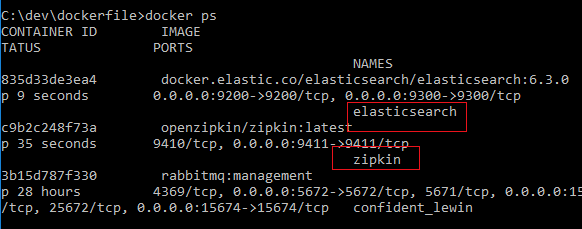
到这里,zipkin服务端就搭建起来了,访问 http://localhost:9411,效果如下,因为还没有客户端,所以还没有数据。

注意:
这里我们采用了elasticsearch作为存储方式,如果想简单通过内存方式启动,无须安装elasticsearch,直接启动一个zipkin容器即可。
docker run -d -p 9411:9411 openzipkin/zipkin
如果想使用其他如数据库等方式存储,请查询相关配置文档。
zipkin服务端已经搭建完成了,接下来我们来实现客户端。
添加依赖
修改 kitty-consumer 项目Maven配置,添加zipkin依赖。
pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置文件
修改配置文件,添加如下zipkin配置。
spring: zipkin: base-url: http://localhost:9411/ sleuth: sampler: probability: 1 #样本采集量,默认为0.1,为了测试这里修改为1,正式环境一般使用默认值。
application.yml
server: port: 8005 spring: application: name: kitty-consumer cloud: consul: host: localhost port: 8500 discovery: serviceName: ${spring.application.name} # 注册到consul的服务名称 boot: admin: client: url: "http://localhost:8000" zipkin: base-url: http://localhost:9411/ sleuth: sampler: probability: 1 #样本采集量,默认为0.1,为了测试这里修改为1,正式环境一般使用默认值。 # 开放健康检查接口 management: endpoints: web: exposure: include: "*" endpoint: health: show-details: ALWAYS #开启熔断器 feign: hystrix: enabled: true
测试效果
先后启动注册中心、服务监控、服务提供者、服务消费者。
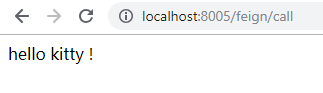
反复访问几次 http://localhost:8005/feign/call,产生zipkin数据。
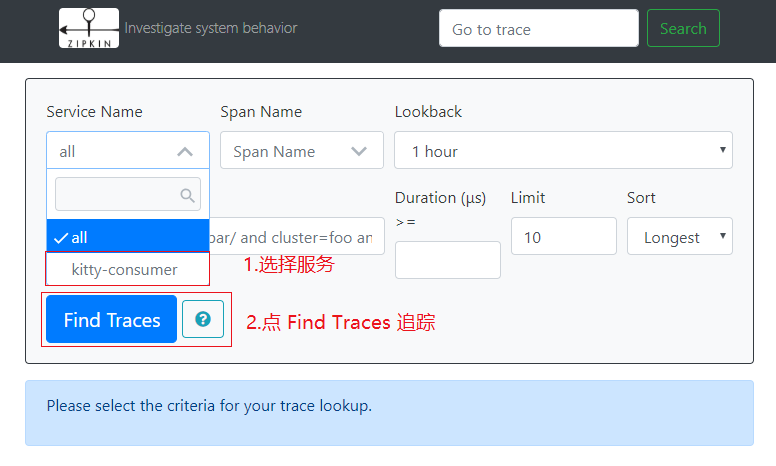
再次访问 http://localhost:9411, 发现出现了我们刚刚访问的服务,选择并点击追踪。
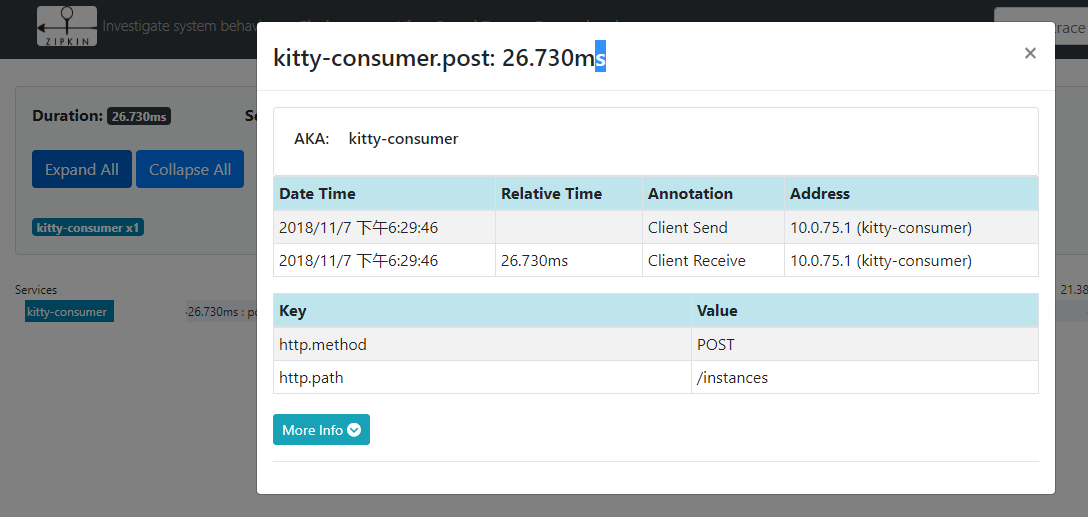
点击追踪之后,页面显示了相关的服务调用信息。

点击调用记录查看详情页面,可以看到每一个服务所耗费的时间和顺序。
源码下载
后端:https://gitee.com/liuge1988/kitty
前端:https://gitee.com/liuge1988/kitty-ui.git
作者:朝雨忆轻尘
出处:https://www.cnblogs.com/xifengxiaoma/
版权所有,欢迎转载,转载请注明原文作者及出处。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?